
Обработка данных в реальном времени и бесперебойное взаимодействие различных частей приложения очень важны. Одна из технологий, которая стала особенно популярной для обеспечения таких возможностей, — Apache Kafka. Разберемся, что такое Kafka, каков ее ключевой функционал и как она вписывается в экосистему Spring Boot.
Что такое Apache Kafka?
Apache Kafka — это Open Source платформа для распределенной потоковой передачи событий и обработки потоков. Изначально разработана инженерами LinkedIn, позже ее исходный код выложили в открытый доступ как часть Apache Software Foundation. Kafka предназначена для решения задач обработки огромных объемов данных в реальном времени, а значит, она идеальна для приложений, которым требуются высокая пропускная способность, отказоустойчивость и потоковая передача данных в реальном времени.
Для чего нужна Apache Kafka?
Благодаря своей архитектуре и функционалу Kafka является мощным инструментом для различных сценариев:
- Обработка данных в реальном времени. Kafka превосходно справляется с потоками данных в реальном времени, она идеальна для приложений, в которых требуются мгновенные обновления данных и обработка, управляемая событиями.
- Масштабируемость. Распределенным характером Kafka обеспечивается плавная масштабируемость с возможностью обрабатывать большие объемы данных без снижения производительности.
- Отказоустойчивость. Механизмом репликации Kafka гарантируется целостность данных даже в случае сбоев брокера.
- Порождение событий. Kafka — фундаментальный компонент архитектур порождения событий, где изменения состояния приложения фиксируются в виде последовательности событий.
- Агрегация логов. Kafka принадлежит важнейшая роль в упрощении фиксации и сохранения изменений состояния приложения в виде последовательности событий.
Ключевые понятия Kafka
- Темы: в Kafka данные организуются по темам, то есть категориям или каналам, в которых публикуются записи.
- Отправители: занимаются передачей данных в темы, это источники потоков данных.
- Получатели: подписываются на темы и обрабатывают передаваемые отправителями записи, это получатели потоков данных.
- Брокеры: кластеры Kafka состоят из брокеров, которыми сохраняются данные и контролируется распределение записей по темам.
- Разделы: каждая тема разбивается на разделы, чем обеспечиваются параллельная обработка и распределение данных по кластеру.
Ядро архитектуры Kafka
В архитектуре Kafka сердцевина системы — это сообщения. Они создаются отправителями и отправляются по определенным темам-категориям. Для эффективной параллельной обработки эти темы разбиваются на разделы.
Получатели подписываются на темы, извлекая сообщения из разделов. Каждый раздел назначается только одному получателю, чем обеспечивается балансировка нагрузки. Сообщения обрабатываются получателями исходя из их потребностей: аналитика, хранение, другие задачи.
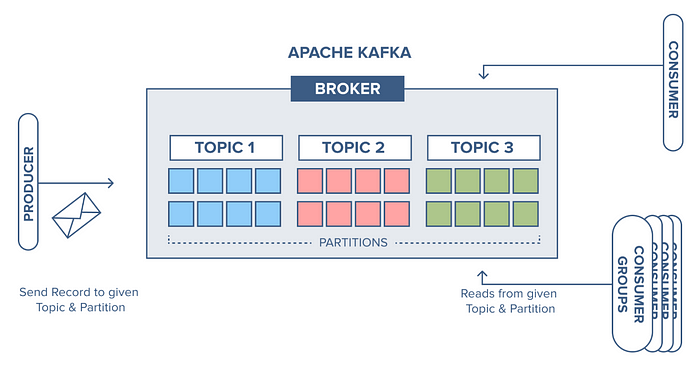
Такой архитектурой Kafka обеспечивается эффективная обработка огромных потоков данных, отказоустойчивость и масштабируемость. Это надежная основа для конвейеров данных в реальном времени, событийно-ориентированных приложений и многого другого.
С работой Kafka разобрались, переходим к коду.
Настройка Kafka в Spring Boot: реализация кода
Прежде всего важно иметь рабочий сервер Kafka в локальной среде. Быстро запускаем и настраиваем его на компьютере.
Добавляем в файл pom.xml зависимость для Maven spring-kafka:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
Настройка отправителя
Для создания сообщений сначала настраиваем фабрику ProducerFactory — основу для формирования экземпляров отправителей Kafka.
Затем задействуем KafkaTemplate, которым обертывается экземпляр отправителя и предлагаются простые методы для отправки сообщений по определенным темам Kafka.
Экземпляры отправителя потокобезопасны, а значит, от использования в контексте приложения одного экземпляра производительность повышается. Это относится и к экземплярам KafkaTemplate.
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(
ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
bootstrapAddress);
configProps.put(
ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
configProps.put(
ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
В этом фрагменте кода мы настраиваем отправитель с помощью свойств ProducerConfig. Разберем ключевые свойства:
BOOTSTRAP_SERVERS_CONFIG: этим свойством указываются адреса брокеров Kafka, то есть список разделенных запятыми пар хост-порт.- Свойствами
KEY_SERIALIZER_CLASS_CONFIGиVALUE_SERIALIZER_CLASS_CONFIGопределяется, как ключ и значение сообщения сериализуются перед отправкой в Kafka. В этом примере для сериализации ключей и значений используемStringSerializer.
Итак, в файле свойств должно быть значение bootstrap-server:
spring.kafka.bootstrap-servers=localhost:9092
Все службы предполагается запускать через порт по умолчанию.
Создание тем Kafka
Отправим сообщение в тему, поэтому сначала создадим ее:
@Configuration
public class KafkaTopic {
@Bean
public NewTopic topic1() {
return TopicBuilder.name("topic-1").build();
}
@Bean
public NewTopic topic2() {
return TopicBuilder.name("topic-2").partitions(3).build();
}
}
Новые темы в брокере создаются компонентом KafkaAdmin, который со Spring Boot регистрируется автоматически.
Здесь мы создали тему-1 с одним разделом по умолчанию и тему-2 с тремя разделами — с TopicBuilder темы создаются по-разному.
Отправка сообщений
У KafkaTemplate различные методы отправки сообщений в темы:
@Component
@Slf4j
public class KafkaSender {
@Autowired
private KafkaTemplateString, String> kafkaTemplate;
public void sendMessage(String message, String topicName) {
log.info("Sending : {}", message);
log.info("--------------------------------");
kafkaTemplate.send(topicName, message);
}
}
Нам же, чтобы опубликовать сообщение, нужно только вызвать метод send(), указав в параметрах это сообщение и название темы.
Настройка получателя
Все сообщения из всех тем получаются фабрикой KafkaMessageListenerContainerFactory в одном потоке. Настроим для этого еще consumerFactory:
@Configuration
@EnableKafka
public class KafkaConsumer {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public ConsumerFactoryString, String> consumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
bootstrapServers);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(props);
}
}
Затем, чтобы с помощью аннотации @KafkaListener получать сообщения, задействуем аннотацию @EnableKafka в конфигурации получателя. Так Spring выполняется поиск аннотаций @KafkaListener в компонентах и настраивается необходимая инфраструктура обработки сообщений Kafka:
@Component
@Slf4j
public class KafkaListenerExample {
@KafkaListener(topics = "topic-1", groupId = "group1")
void listener(String data) {
log.info("Received message [{}] in group1", data);
}
groupId — это строка, однозначно идентифицирующая группу процессов получателя, к которой этот получатель принадлежит.
В одной группе получателей может указываться несколько прослушиваемых тем, а одна тема — прослушиваться несколькими методами:
@KafkaListener(topics = "topic-1,topic-2", groupId = "group1")
void listener(@Payload String data,
@Header(KafkaHeaders.RECEIVED_PARTITION) int partition,
@Header(KafkaHeaders.OFFSET) int offset) {
log.info("Received message [{}] from group1, partition-{} with offset-{}",
data,
partition,
offset);
}
Аннотацией @Header() извлекаются метаданные получаемого сообщения.
Получение сообщений из конкретного раздела с начальным смещением
Чтобы повторно обработать конкретные сообщения или иметь детализированный контроль над тем, откуда начинать их получение, сообщения получают из конкретного раздела темы Kafka, начиная с определенного смещения:
@KafkaListener(
groupId = "group2",
topicPartitions = @TopicPartition(topic = "topic-2",
partitionOffsets = {
@PartitionOffset(partition = "0", initialOffset = "0"),
@PartitionOffset(partition = "3", initialOffset = "0")}))
public void listenToPartition(
@Payload String message,
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition) {
log.info("Received Message [{}] from partition-{}",
message,
partition);
}
С initialOffset, равным 0, в Kafka сообщения получаются с начала раздела.
Раздел без initialOffset указывается так:
@KafkaListener(groupId = "group2", topicPartitions
= @TopicPartition(topic = "topicName", partitions = { "0", "3" }))
KafkaListener на уровне класса
Аннотация на уровне класса используется при объединении логики обработки связанных сообщений. Сообщения из этих тем распределяются на методы внутри класса по их параметрам:
@Component
@Slf4j
@KafkaListener(id = "class-level", topics = "multi-type")
class KafkaClassListener {
@KafkaHandler
void listenString(String message) {
log.info("KafkaHandler [String] {}", message);
}
@KafkaHandler(isDefault = true)
void listenDefault(Object object) {
log.info("KafkaHandler [Default] {}", object);
}
}
Так группируются методы, которыми получаются данные из конкретных тем. Методами, аннотированными @KafkaHandler, собираются различные типы данных. Параметрами методов определяется способ получения данных; если среди типов данных нет подходящих, применяется метод по умолчанию.
Разобрав работу отправителей и прослушивателей со строковыми сообщениями, перейдем к различным сценариям и вариантам использования.
RoutingKafkaTemplate
Когда имеется несколько отправителей с различными конфигурациями и нужно выбрать одного по названию темы во время выполнения, применяется RoutingKafkaTemplate:
@Bean
public RoutingKafkaTemplate routingTemplate(GenericApplicationContext context) {
// «ProducerFactory» с сериализатором байтов
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class);
DefaultKafkaProducerFactory<Object, Object> bytesPF = new DefaultKafkaProducerFactory<>(props);
context.registerBean(DefaultKafkaProducerFactory.class, "bytesPF", bytesPF);
// «ProducerFactory» с сериализатором строк
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
DefaultKafkaProducerFactory<Object, Object> stringPF = new DefaultKafkaProducerFactory<>(props);
Map<Pattern, ProducerFactory<Object, Object>> map = new LinkedHashMap<>();
map.put(Pattern.compile(".*-bytes"), bytesPF);
map.put(Pattern.compile("strings-.*"), stringPF);
return new RoutingKafkaTemplate(map);
}
Классом RoutingKafkaTemplate сообщения направляются в первый экземпляр фабрики, который соответствует заданному названию темы из карты регулярных выражений и экземпляров ProducerFactory. Шаблон strings-.* должен быть первым из двух: str-.* и strings-.*. Иначе «переопределится» шаблоном str-.*.
В примере выше мы создали два шаблона: .*-bytes и strings-.*. Сериализация сообщений зависит от названия темы во время выполнения. Названиями тем с окончанием -bytes применяется сериализатор байтов, с началом strings-.* — StringSerializer .
Фильтрация сообщений
Любые сообщения, соответствующие критериям фильтра, отбрасываются, даже не успев добраться до прослушивателя. Здесь, например, отбрасываются сообщения со словом ignored:
@Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setRecordFilterStrategy(record -> record.value().contains("ignored"));
return factory;
}
Прослушиватель инкапсулируется адаптером FilteringMessageListenerAdapter, основанном на реализации RecordFilterStrategy, где определяется метод фильтрации. Фильтр вызывается добавлением всего одной строки в фабрику получателей.
Пользовательские сообщения
Рассмотрим, как на Java отправляются или получаются объекты, например User:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
String msg;
}
Конфигурирование отправителя и получателя
Значение отправителя настраиваем сериализатором JSON:
@Bean
public ProducerFactory<String, User> userProducerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, User> userKafkaTemplate() {
return new KafkaTemplate<>(userProducerFactory());
}
А значения получателей — десериализатором JSON:
public ConsumerFactory<String, User> userConsumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
return new DefaultKafkaConsumerFactory<>(props, new StringDeserializer(), new JsonDeserializer>(User.class));
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, User> userKafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, User> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(userConsumerFactory());
return factory;
}
Сериализатором и десериализатором JSON в spring-kafka объекты Java преобразуются в байты и наоборот с помощью библиотеки Jackson:
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.12.7.1</version>
</dependency>
Эта зависимость необязательная, используйте ту же версию, что и spring-kafka.
Отправка объектов Java
Отправим объект User с помощью созданного нами userKafkaTemplate():
@Component
@Slf4j
public class KafkaSender {
@Autowired
private KafkaTemplate<String, User> userKafkaTemplate;
void sendCustomMessage(User user, String topicName) {
log.info("Sending Json Serializer : {}", user);
log.info("--------------------------------");
userKafkaTemplate.send(topicName, user);
}
Получение объектов Java
@Component
@Slf4j
public class KafkaListenerExample {
@KafkaListener(topics = "topic-3", groupId = "user-group",
containerFactory = "userKafkaListenerContainerFactory")
void listenerWithMessageConverter(User user) {
log.info("Received message through MessageConverterUserListener [{}]", user);
}
Из нескольких контейнеров прослушивателей выбираем фабрику контейнеров.
Если не указать атрибут containerFactory, то к kafkaListenerContainerFactory применятся значения по умолчанию, в нашем случае это StringSerializer и StringDeserializer.
Заключение
В этом руководстве по Apache Kafka мы начали с азов, основных концепций Kafka, описали настройку Kafka в приложении Spring Boot, отправку и получение сообщений с помощью шаблонов и прослушивателей Kafka, обработку различных типов сообщений, их маршрутизацию и фильтрацию, преобразование форматов пользовательских данных.
Kafka — это универсальный и мощный инструмент для создания конвейеров данных в реальном времени и событийно-ориентированных приложений. И теперь вы вооружены знаниями и навыками для эффективного использования его возможностей.
Продолжайте экспериментировать, учиться, созидать, ведь возможности Kafka безграничны. Остается только практиковаться.
Читайте также:
- Как интегрировать Kafka со Spring Boot
- Конвейер данных в реальном времени с Kafka и ClickHouse
- Кэширование в связке Spring Boot + Redis + PostgreSQL
Читайте нас в Telegram, VK и Дзен
Перевод статьи Avinash Hargun: Kafka Integration Made Easy with Spring Boot





