
Логистическая регрессия — это алгоритм классификации машинного обучения, используемый для прогнозирования вероятности категориальной зависимой переменной. В логистической регрессии зависимая переменная является бинарной переменной, содержащей данные, закодированные как 1 (да, успех и т.п.) или 0 (нет, провал и т.п.). Другими словами, модель логистической регрессии предсказывает P(Y=1) как функцию X.
Условия логистической регрессии
- Бинарная логистическая регрессия требует, чтобы зависимая переменная также была бинарной.
- Для бинарной регрессии фактор уровня 1 зависимой переменной должен представлять желаемый вывод.
- Использоваться должны только значимые переменные.
- Независимые переменные должны быть независимы друг от друга. Это значит, что модель должна иметь малую мультиколлинеарность или не иметь её вовсе.
- Независимые переменные связаны линейно с логарифмическими коэффициентами.
- Логистическая регрессия требует больших размеров выборки.
Держа в уме все перечисленные условия, давайте взглянем на наш набор данных.
Данные
Набор данных взят с репозитория машинного обучения UCI и относится к прямым маркетинговым кампаниям (телефонный обзвон) португальского банковского учреждения. Цель классификации в прогнозировании успеха подписки клиента (1/0) на срочный депозит (переменная y). Загрузить этот набор данных можно здесь.
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
plt.rc("font", size=14)
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import seaborn as sns
sns.set(style="white")
sns.set(style="whitegrid", color_codes=True)Эти данные предоставляют информацию о клиентах банка, которая включает 41,188 записей и 21 поле.
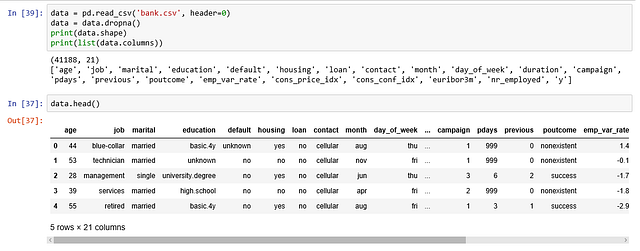
Вводные переменные
- age — возраст (число);
- job — вид должности (категории: “admin” (администратор), “blue-collar” (рабочий), “entrepreneur” (мелкий предприниматель), “housemaid” (горничная), “management” (руководитель), “retired” (на пенсии), “self-employed” (самозанятый), “services” (сфера услуг), “student” (учащийся), “technician” (техник), “unemployed” (не трудоустроен), “unknown” (неизвестно));
- marital — семейное положение (категории: “divorced” (разведён), “married” (замужем/женат), “single” (холост/не замужем), “unknown” (неизвестно));
- education — образование (категории: “basic.4y”, “basic.6y”, “basic.9y” (базовое), “high.school” (высшая школа), “illiterate” (без образования), “professional.course” (профессиональные курсы), “university.degree” (университетская степень), “unknown” (неизвестно));
- default — имеет ли просроченные кредиты (категории: “no” (нет), “yes” (да), “unknown” (неизвестно));
- housing — имеет ли жилищный кредит (категории: “no” (нет), “yes” (да), “unknown” (неизвестно));
- loan — имеет ли личный кредит (категории: “no” (нет), “yes” (да), “unknown” (неизвестно));
- contact — вид связи (категории: “cellular” (мобильный), “telephone” (стационарный));
- month — месяц последнего обращения (категории: “jan” (январь), “feb” (февраль), “mar” (март), …, “nov” (ноябрь), “dec” (декабрь));
- day_of_week — день недели последнего обращения (категории: “mon” (понедельник), “tue” (вторник), “wed” (среда), “thu” (четверг), “fri” (пятница));
- duration — продолжительность последнего обращения в секундах (число). Важно: этот атрибут оказывает сильное влияние на вывод (например, если продолжительность=0, тогда y=’no’). Продолжительность не известна до момента совершения звонка, а по его завершению y будет, очевидно, известна. Следовательно этот вводный параметр должен включаться только в целях эталонного тестирования, для получения же реалистичной модели прогноза его следует исключать.
- campaign — число обращений, установленных в процессе этой кампании и для этого клиента (представлено числом и включает последнее обращение);
- pdays — число дней, прошедших с момента последнего обращения к клиенту во время предыдущей кампании (число; 999 означает, что ранее обращений не было);
- previous — число обращений, совершённых до этой кампании (число);
- poutcome — итоги предыдущей маркетинговой кампании (категории: “failure” (провал), “nonexistent” (несуществующий), “success” (успех));
- emp.var.rate — коэффициент изменения занятости (число);
- cons.price.idx — индекс потребительских цен (число);
- cons.conf.idx — индекс потребительского доверия (число);
- euribor3m — 3-х месячная европейская межбанковская ставка (число);
- nr.employed — количество сотрудников (число).
Прогнозируемая переменная (желаемая цель):
y —подписался ли клиент на срочный вклад (двоично: “1” означает “Да”, “0” означает “Нет”).
Колонка образования в наборе данных имеет очень много категорий, и нам нужно сократить их для оптимизации моделирования. В этой колонке представлены следующие категории:

Давайте сгруппируем “basic.4y”, “basic.9y” и “basic.6y” и назовём их “basic” (базовое).
data['education']=np.where(data['education'] =='basic.9y', 'Basic', data['education'])
data['education']=np.where(data['education'] =='basic.6y', 'Basic', data['education'])
data['education']=np.where(data['education'] =='basic.4y', 'Basic', data['education'])После группировки мы получим следующие колонки:

Изучение данных
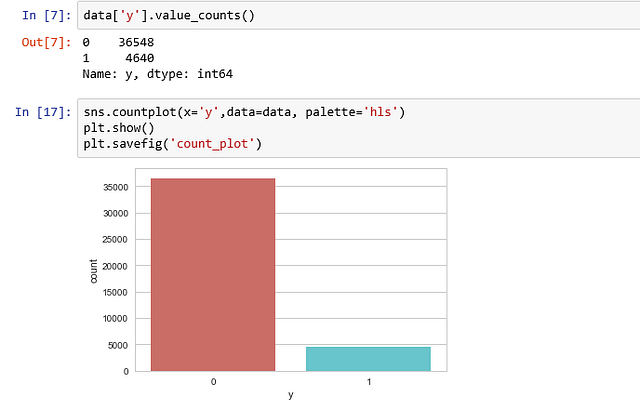
count_no_sub = len(data[data['y']==0])
count_sub = len(data[data['y']==1])
pct_of_no_sub = count_no_sub/(count_no_sub+count_sub)
print("percentage of no subscription is", pct_of_no_sub*100)
pct_of_sub = count_sub/(count_no_sub+count_sub)
print("percentage of subscription", pct_of_sub*100)- Процент не подписавшихся — 88,73458288821988;
- Процент подписавшихся — 11,265417111780131.
Наши классы не сбалансированы, и соотношение не подписавшихся к подписавшимся составляет 89:11. Прежде чем мы перейдём к балансировке, давайте проведём дополнительное исследование.

Наблюдения:
- Средний возраст потребителей, купивших срочный депозит, выше, чем тех, кто его не купил.
- pdays (дни, прошедшие с момента последнего обращения к клиенту) по понятным причинам ниже для тех, кто купил депозит. Чем меньше показатель pdays, тем лучше память о последнем звонке и выше шансы успешной продажи.
- На удивление, показатель campaigns (число обращений или звонков, сделанных во время текущей кампании) меньше для потребителей, купивших срочный депозит.
Мы можем вычислить средние категориальные значения для других категориальных переменных, вроде образования и семейного положения, чтобы получить более точное представление о данных.
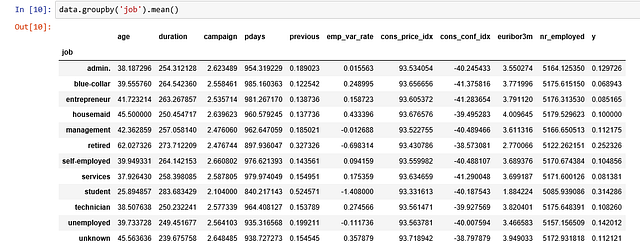
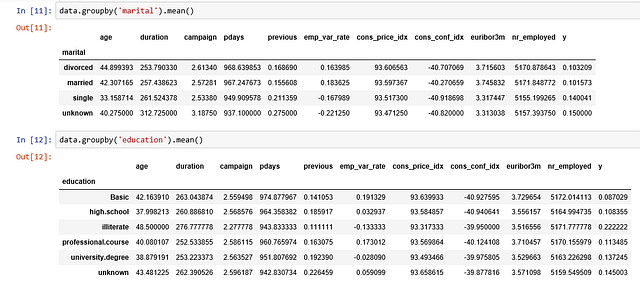
Визуализации
%matplotlib inline
pd.crosstab(data.job,data.y).plot(kind='bar')
plt.title('Purchase Frequency for Job Title')
plt.xlabel('Job')
plt.ylabel('Frequency of Purchase')
plt.savefig('purchase_fre_job')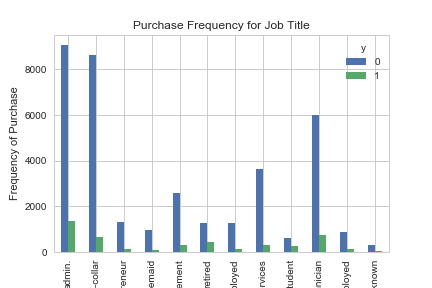
Частота покупки депозита во многом зависит от должности клиента. Следовательно этот показатель может послужить хорошим фактором прогноза итоговой переменной.
table=pd.crosstab(data.marital,data.y)
table.div(table.sum(1).astype(float), axis=0).plot(kind='bar', stacked=True)
plt.title('Stacked Bar Chart of Marital Status vs Purchase')
plt.xlabel('Marital Status')
plt.ylabel('Proportion of Customers')
plt.savefig('mariral_vs_pur_stack')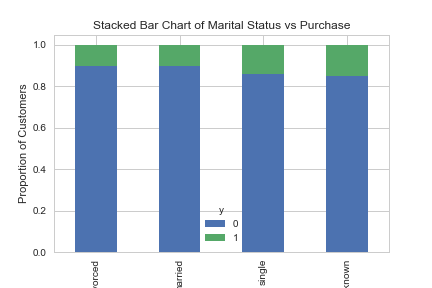
Семейное же положение не является существенным прогнозирующим фактором.
table=pd.crosstab(data.education,data.y)
table.div(table.sum(1).astype(float), axis=0).plot(kind='bar', stacked=True)
plt.title('Stacked Bar Chart of Education vs Purchase')
plt.xlabel('Education')
plt.ylabel('Proportion of Customers')
plt.savefig('edu_vs_pur_stack')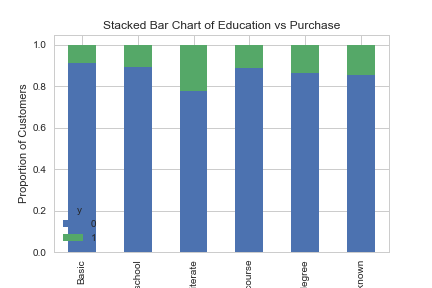
Образование выглядит хорошим фактором для прогноза итоговой переменной.
pd.crosstab(data.day_of_week,data.y).plot(kind='bar')
plt.title('Purchase Frequency for Day of Week')
plt.xlabel('Day of Week')
plt.ylabel('Frequency of Purchase')
plt.savefig('pur_dayofweek_bar')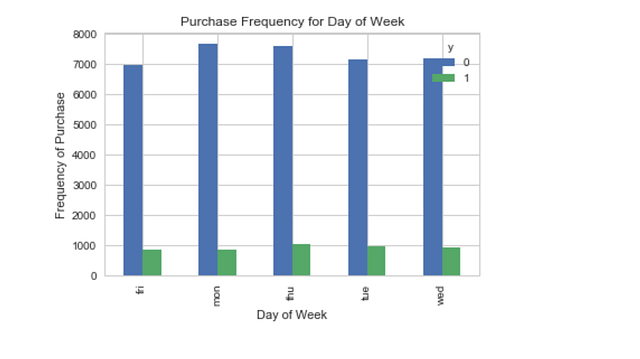
День недели может не являться хорошим прогнозирующим фактором.
pd.crosstab(data.month,data.y).plot(kind='bar')
plt.title('Purchase Frequency for Month')
plt.xlabel('Month')
plt.ylabel('Frequency of Purchase')
plt.savefig('pur_fre_month_bar')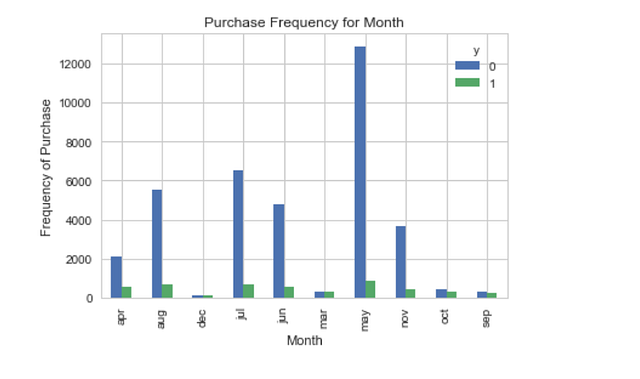
Месяц может оказаться хорошим прогнозирующим фактором.
data.age.hist()
plt.title('Histogram of Age')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.savefig('hist_age')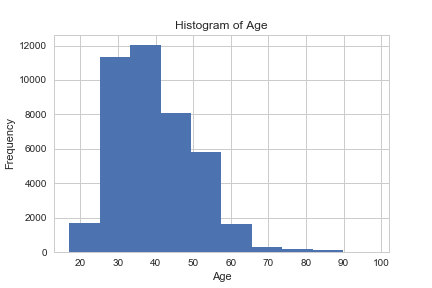
Большинство клиентов банка в этом наборе данных находятся в возрасте от 30 до 40 лет.
pd.crosstab(data.poutcome,data.y).plot(kind='bar')
plt.title('Purchase Frequency for Poutcome')
plt.xlabel('Poutcome')
plt.ylabel('Frequency of Purchase')
plt.savefig('pur_fre_pout_bar')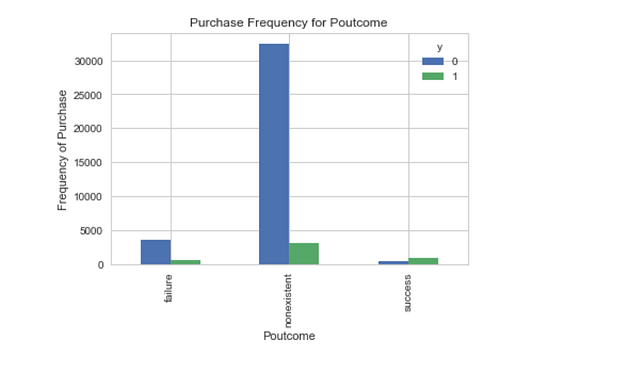
Poutcome (итоги предыдущей маркетинговой кампании) кажется хорошим прогнозирующим фактором.
Создание индикаторных переменных
Это переменные со всего двумя значениями — ноль и единица.
cat_vars=['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome']
for var in cat_vars:
cat_list='var'+'_'+var
cat_list = pd.get_dummies(data[var], prefix=var)
data1=data.join(cat_list)
data=data1cat_vars=['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome']
data_vars=data.columns.values.tolist()
to_keep=[i for i in data_vars if i not in cat_vars]Наши итоговые колонки данных будут:
data_final=data[to_keep]
data_final.columns.values
Over-Sampling при помощи SMOTE
После создания наших обучающих данных я увеличу частоту выборки не подписавшихся, используя алгоритм SMOTE (синтетическая техника дублирования примеров миноритарного класса). На высоком уровне SMOTE:
- создаёт синтетические образцы на основе выборок минорного класса (не подписавшихся) вместо создания их копий;
- случайно выбирает одного из ближайших k-соседей и использует его для создания схожих, но случайно изменённых новых сведений.
Мы будем реализовывать SMOTE в Python.
X = data_final.loc[:, data_final.columns != 'y']
y = data_final.loc[:, data_final.columns == 'y']
from imblearn.over_sampling import SMOTE
os = SMOTE(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
columns = X_train.columns
os_data_X,os_data_y=os.fit_sample(X_train, y_train)
os_data_X = pd.DataFrame(data=os_data_X,columns=columns )
os_data_y= pd.DataFrame(data=os_data_y,columns=['y'])
# Мы можем проверить числа наших данных
print("length of oversampled data is ",len(os_data_X))
print("Number of no subscription in oversampled data",len(os_data_y[os_data_y['y']==0]))
print("Number of subscription",len(os_data_y[os_data_y['y']==1]))
print("Proportion of no subscription data in oversampled data is ",len(os_data_y[os_data_y['y']==0])/len(os_data_X))
print("Proportion of subscription data in oversampled data is ",len(os_data_y[os_data_y['y']==1])/len(os_data_X))
Теперь у нас есть идеально сбалансированные данные. Вы могли заметить, что я выполнил over-sampling только для обучающих данных, поскольку в таком случае информация из тестовых данных не используется для создания синтетических сведений, и, следовательно, не произойдёт её утечки в обучающую модель.
Рекурсивное устранение признаков
Рекурсивное устранение признаков (RFE) основывается на повторяющемся конструировании модели и выборе лучше всех или хуже всех выполняемого признака, отделения этого признака и повторения цикла с оставшимися. Этот процесс применяется, пока в наборе данных не закончатся признаки. Цель RFE заключается в отборе признаков посредством рекурсивного рассмотрения всё меньшего и меньшего их набора.
data_final_vars=data_final.columns.values.tolist()
y=['y']
X=[i for i in data_final_vars if i not in y]
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
rfe = RFE(logreg, 20)
rfe = rfe.fit(os_data_X, os_data_y.values.ravel())
print(rfe.support_)
print(rfe.ranking_)

При помощи RFE мы выбрали следующие признаки: “euribor3m”, “job_blue-collar”, “job_housemaid”, “marital_unknown”, “education_illiterate”, “default_no”, “default_unknown”, “contact_cellular”, “contact_telephone”, “month_apr”, “month_aug”, “month_dec”, “month_jul”, “month_jun”, “month_mar”, “month_may”, “month_nov”, “month_oct”, “poutcome_failure”, “poutcome_success”.
cols=['euribor3m', 'job_blue-collar', 'job_housemaid', 'marital_unknown', 'education_illiterate', 'default_no', 'default_unknown',
'contact_cellular', 'contact_telephone', 'month_apr', 'month_aug', 'month_dec', 'month_jul', 'month_jun', 'month_mar',
'month_may', 'month_nov', 'month_oct', "poutcome_failure", "poutcome_success"]
X=os_data_X[cols]
y=os_data_y['y']Реализация модели
import statsmodels.api as sm
logit_model=sm.Logit(y,X)
result=logit_model.fit()
print(result.summary2())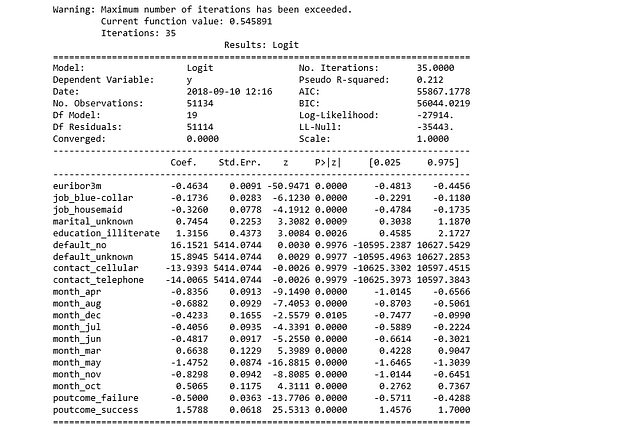
p-значения для большинства переменных меньше 0.05, за исключением всего четырёх, следовательно мы их удалим.
cols=['euribor3m', 'job_blue-collar', 'job_housemaid', 'marital_unknown', 'education_illiterate',
'month_apr', 'month_aug', 'month_dec', 'month_jul', 'month_jun', 'month_mar',
'month_may', 'month_nov', 'month_oct', "poutcome_failure", "poutcome_success"]
X=os_data_X[cols]
y=os_data_y['y']
logit_model=sm.Logit(y,X)
result=logit_model.fit()
print(result.summary2())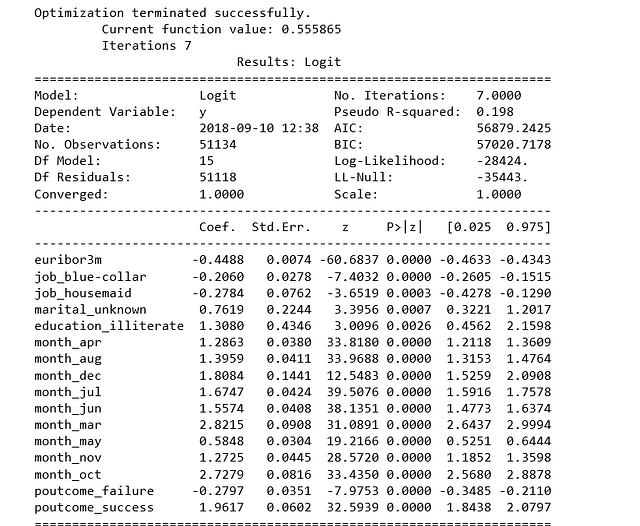
Подгонка модели логистической регрессии
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
Прогнозирование результатов тестового набора и вычисление точности.
y_pred = logreg.predict(X_test)
print('Accuracy of logistic regression classifier on test set: {:.2f}'.format(logreg.score(X_test, y_test)))Точность классификатора логистической регрессии для тестового набора: 0,74.
Матрица ошибок
from sklearn.metrics import confusion_matrix
confusion_matrix = confusion_matrix(y_test, y_pred)
print(confusion_matrix)[[6124 1542]
[2505 5170]]
Результат показывает, что у нас 6124+5170 верных прогнозов и 2505+1542 ошибочных.
Вычисление точности, полноты, F-меры и поддержки
Приведу цитату из Scikit Learn:
Точность является соотношением tp/(tp + fp), где tp является числом верно-положительных, а fp — числом ложно-положительных. Точность — это интуитивно понятная способность классификатора не помечать выборку как положительную, если она отрицательна.
Полнота— это пропорция tp/(tp +fn), где tp представляет число верно-положительных результатов, а fn — число ложно-отрицательных. Полнота является интуитивно понятной способностью классификатора находить все положительные выборки.
Показатель F-бета можно интерпретировать как взвешенное гармоническое среднее точности и полноты, где лучшим значением этого показателя будет 1, а худшим 0.
Показатель F-бета определяет, насколько значимость полноты больше, чем точности, опираясь на фактор бета. Например, beta = 1.0 означает, что полнота и точность равно важны.
Поддержка — это число вхождений каждого класса в y_test.
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))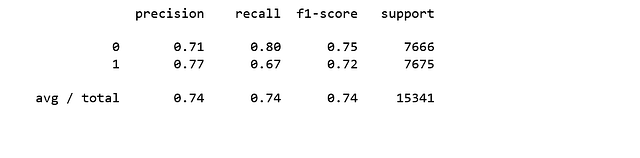
Интерпретация: из всего тестового набора 74% рекламируемых срочных депозитов понравились клиентам. Из всего тестового набора 74% клиентов предпочли рекламируемые срочные депозиты.
ROC-кривая
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
logit_roc_auc = roc_auc_score(y_test, logreg.predict(X_test))
fpr, tpr, thresholds = roc_curve(y_test, logreg.predict_proba(X_test)[:,1])
plt.figure()
plt.plot(fpr, tpr, label='Logistic Regression (area = %0.2f)' % logit_roc_auc)
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic')
plt.legend(loc="lower right")
plt.savefig('Log_ROC')
plt.show()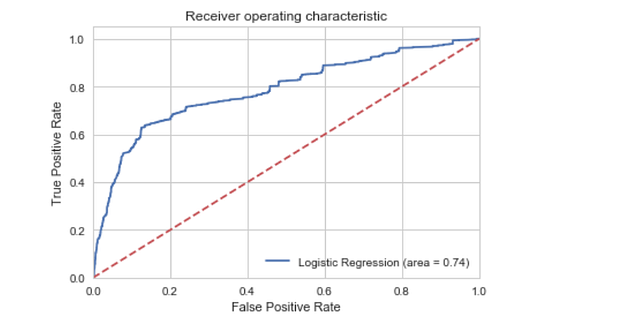
Кривая рабочей характеристики приёмника (ROC) является ещё одним популярным инструментом, используемым с бинарными классификаторами. Пунктирная линия представляет ROC-кривую полностью случайного классификатора. Хороший классификатор остаётся от неё максимально далеко (по направлению к верхнему левому углу).
Jupyter notebook, использованный для написания этой статьи, доступен здесь.
Читайте также:
- 7 ошибок Python, от которых стоит немедленно избавиться
- 15 Python пакетов, которые нужно попробовать
- Избегайте этих нелепых ошибок при работе с Python
Перевод статьи Susan Li: Building A Logistic Regression in Python, Step by Step.





