
Построим конвейер данных с их приемом в ClickHouse через Kafka и агрегированием автоматически обновляемых данных. Возьмем набор данных о мировых ценах на продовольствие, хоть и неидеальный для Kafka из-за отсутствия критериев скорости.
Сначала создадим на Python скрипт для выдачи сообщений — строк набора данных. Затем настроим ClickHouse для их получения и обработки, а после поэкспериментируем с представлением в реальном времени и удалением данных.
Что потребуется
- Кластер Kafka: запускаем в
docker-compose -f <file> upфайл docker-composezk-single-kafka-single.ymlиз этого репозитория GitHub. - Python 3.x.
- Официальный двоичный файл для сервера ClickHouse.
Производитель сообщений
В производственной среде возможно несколько извлекаемых и отправляемых в Kafka источников, мы ограничимся чтением CSV-файла, преобразованием строк в JSON и их отправкой.
В ClickHouse довольно строгий парсинг форматов, поэтому поверх CSV используем JSON, например двойная запятая, чтобы данные не потреблялись.
Вот производитель Python:
import csv
import json
import kafka
producer = kafka.KafkaProducer()
with open('global_food_prices.csv', 'r', encoding='iso-8859-1') as f:
r = csv.DictReader(f)
for row in r:
producer.send('food', json.dumps(row).encode('utf-8', 'replace'))
producer.close()
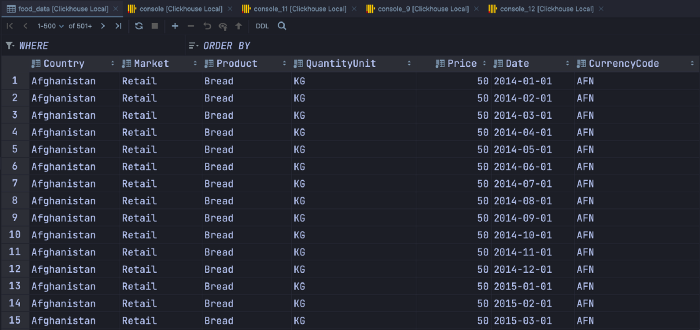
Мы читаем global_food_prices.csv, передаем буфер в csv.DictReader и отправляем каждую строку в JSON.
Можно просто вставить данные в ClickHouse с помощью Python driver, но у Kafka еще много преимуществ. С кодировкой у меня была проблема, которая с iso-8859–1 разрешилась.
Потребление сообщений из ClickHouse
Запустив сервер ClickHouse и Kafka, входим в консоль ClickHouse через CLI или графический интерфейс, например DataGrip.
Настроим три таблицы.
queueсо всеми столбцами CSV и движком Kafka для получения данных из определенной выше темыfood.- Итоговая таблица только со столбцами, которые нужно сохранить, лучшими именами и типизацией. Несогласованный тип данных, такой как CSV, — больше не проблема.
- Материализованное представление для переноса данных из первой таблицы во вторую. Это оператор
SELECTв SQL, туда поместим приведение типов.
Вот первая таблица:
CREATE TABLE queue (
adm0_id String,
adm0_name String,
adm1_id String,
adm1_name String,
mkt_id String,
mkt_name String,
cm_id String,
cm_name String,
cur_id String,
cur_name String,
pt_id String,
pt_name String,
um_id String,
um_name String,
mp_month String,
mp_year String,
mp_price String,
mp_commoditysource String
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'localhost:9092',
kafka_topic_list = 'food',
kafka_group_name = 'clickhouse_reader',
kafka_format = 'JSONStringsEachRow';
В CSV нет типизации: зададим всем столбцам тип String, а преобразуем позже.
Вот итоговая таблица:
CREATE TABLE food_data (
Country String, -- from: adm0_name
Market String, -- from: pt_name
Product String, -- from: cm_name
QuantityUnit String, -- from: um_name
Price Float32, -- from: mp_price
Date Date, -- computed from: mp_month, mp_year
CurrencyCode String -- from: cur_name
) ENGINE = MergeTree()
ORDER BY (Country, Product);
Создадим материализованное представление:
CREATE MATERIALIZED VIEW food_processing TO food_data AS
SELECT
adm0_name as Country,
pt_name as Market,
cm_name as Product,
um_name as QuantityUnit,
toFloat32OrZero(mp_price) as Price,
toDate(format('{0}-{1}-01', mp_year, mp_month)) as Date,
cur_name as CurrencyCode
FROM queue
В нем сразу начинается обработка данных. Запускаем производитель Python:
Как изменить и удалить данные
Вносить изменения в базы данных OLAP проблематично: они оптимизированы для записи и чтения, а не перезаписи и удаления.
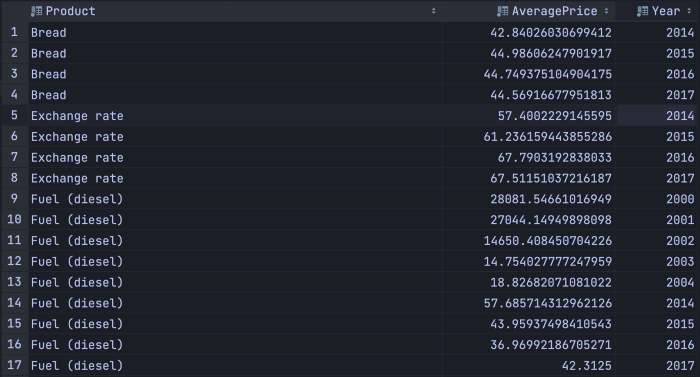
В этом запросе высчитывается средняя цена по продукту и году для Афганистана:
SELECT Product,
avg(Price) as AveragePrice,
toYear(Date) as Year
FROM food_data
WHERE Country = 'Afghanistan'
GROUP BY Product, Year
ORDER BY Product, Year
Рассмотрим конкретные варианты и проблемы.
Маленький набор данных
Если food_data невелик, делаем прямой запрос или используем VIEW.
Если строки из исходной таблицы удаляются, запрос просто выполнится во VIEW повторно.
Набор данных большой, но неизменяемый
Если строки никогда не удаляются, но запрос на стороне конечного пользователя выполняется слишком медленно, используем SummingMergeTree:
CREATE TABLE afghanistan_products (
Product String,
AveragePrice Float32,
Year UInt16
) ENGINE = SummingMergeTree([Product, Year])
-- Every row is unique on Product and Year.
CREATE MATERIALIZED VIEW afghanistan_processing TO afghanistan_products AS
SELECT Product,
avg(Price) as AveragePrice,
toYear(Date) as Year
FROM food_data
WHERE Country = 'Afghanistan'
GROUP BY Product, Year
ORDER BY Product, Year
Когда в food_data добавляются данные, запускается afghanistan_processing и запрос выполняется. Вместо того чтобы простого добавлять данные в afghanistan_products, сравниваются столбцы Product и Year и содержимое заменяется.
Это решение не стоит применять, когда данные можно изменить и удалить: при выполнении ALTER TABLE <table> [UPDATE/DELETE] обновления материализованных представлений не происходит.
Набор данных большой и изменяемый
Итак, материализованные представления не обновляются при изменениях, которые в ClickHouse, похоже, не прослушиваются.
Применим представление Live View, аналогичное заданиям cron из пакетной обработки, где данные обычно агрегируются каждые N часов по программе cron:
CREATE LIVE VIEW afghanistan_products WITH REFRESH 120 AS (
SELECT
Product,
avg(Price) as AveragePrice,
toYear(Date) as Year
FROM food_data
WHERE Country = 'Afghanistan'
GROUP BY Product, Year
ORDER BY Product, Year
)
SETTINGS allow_experimental_live_view = 1
Здесь запрос обновляется каждые 120 секунд, данные записываются в памяти, ускоряя запросы конечных пользователей.
Это экспериментальный функционал ClickHouse, который в любой момент могут убрать. Данные записываются в памяти, поэтому применять его — не лучшая идея, если результат запроса огромен.
Наличие изменяемых данных в сценарии OLAP может быть антипаттерном, но иногда это неизбежно. Например, изменения цен часто отражаются в платежных данных.
Переходя к Live View, проверьте, можно ли использовать в вашем наборе данных CollapsingMergeTree и ReplacingMergeTree.
Читайте также:
- Потоки Kafka: как обрабатывать CSV-файлы для выполнения вычислений
- ClickHouse + Kafka = ❤
- Автоматизируем создание отчета о расходах с помощью Python
Читайте нас в Telegram, VK и Дзен
Перевод статьи Victor Lourme: Real-time data pipeline using Kafka and ClickHouse





