
Tick Tok стремительно завоёвывает мир. Согласно данным Sensor Tower, это приложение для коротких видео было загружено более 2 миллиардов раз с App Store и Google Play. Что же за магия стоит за этим сенсационным приложением, вызывающим такое пристрастие со стороны пользователей? Не удивительно, что ответ кроется в рекомендательном движке на основе ML.
Содержание
- Знакомство с рекомендательным движком TikTok.
- Модель рекомендательной системы TikTok (данные, признаки, ориентиры, алгоритмы и механизмы обучения).
- Рабочий процесс формирования рекомендаций TikTok (реализация в реальном времени, читать обязательно).
Итак, давайте будем честны. Кому не нравятся собачьи выходки и забавные видео с кошками? Особенно это было (а где-то до сих пор) актуально в период глобальной самоизоляции.
Но это лишь отчасти объясняет беспрецедентную историю успеха TikTok. Менее чем за 2 года этот сервис вырос из приложения по “синхронизации движения губ со звуком” с небольшим сообществом поклонников в вирусное приложение с примерно 800 миллионами активных пользователей в месяц в 2020 году. В общей сложности видео TikTok с тегом #coronavirus были просмотрены 53 миллиарда раз.
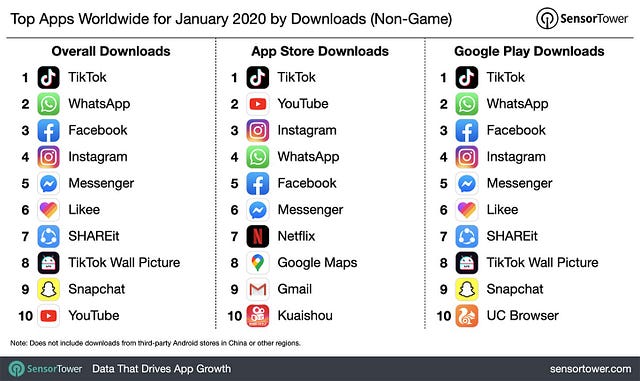
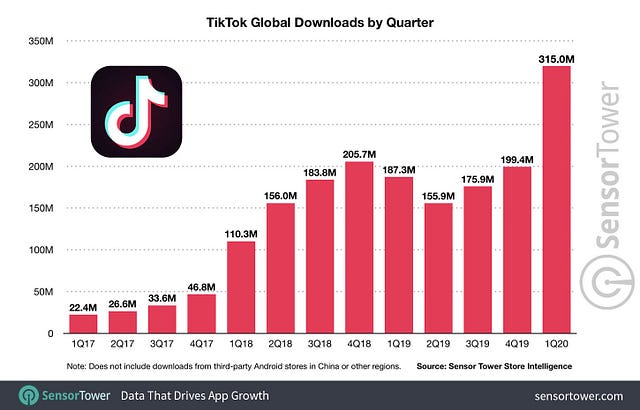
Это приложение хорошо известно благодаря создаваемым в нём вирусным песням и смешным видео-мемам.
Как правило, люди проводят в TikTok около 52 минут в день, что можно сравнить с 26/29/37 минутами для Snapchat/Instagram/Facebook соответственно.
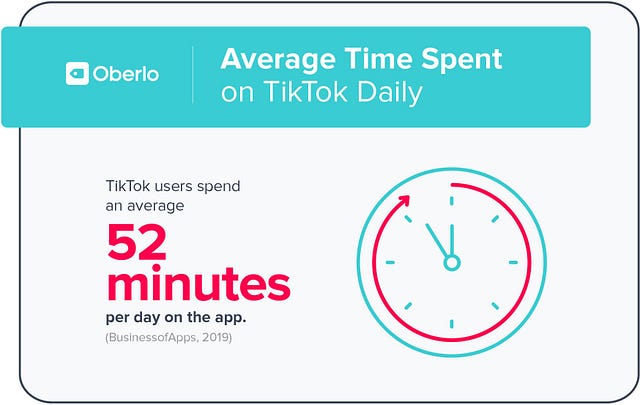
Помимо стратегии масштабного развития это приложение по созданию 60-секундных видео наполнено мемами, комедией, танцами и талантами. Благодаря наличию одного из лучших рекомендательных движковв индустрии, вам не приходится знать или искать, что бы посмотреть. С помощью всего одного клика вы можете получить персональную подборку рекомендаций.
Этот вид скорейшего получения нескончаемых положительных эмоций не даёт вам покинуть TikTok. Некоторые люди называют его мощнейшим убийцей времени, который вытягивает всё ваше свободное время и каким-то образом создаёт обманчивое ощущение, что “5 минут в TikTok равняются 1 часу в реальной жизни”.
Сегодня мы рассмотрим, как TikTok использовал машинное обучение для анализа интересов и предпочтений пользователей на основе их действий, в итоге предоставляя персонализированную подборку.
Рекомендательный движок не нов для сообщества науки о данных. Наоборот, некоторые считают его старым поколением систем ИИ в связи с отсутствием таких крутых возможностей, как распознавание изображений или генерация текста.
Тем не менее рекомендации по-прежнему являются одной из преобладающих систем ИИ, имеющей наиболее обширную реализацию практически во всех онлайн-сервисах и платформах. Например, предложение видео на YouTube, электронные письма от Amazon во время кампаний или рекомендация книг во время просмотра магазина Kindle.
На самом деле, согласно данным исследования, опубликованным Гомесом-Урибе и главой продукта Netflix Нилом Хантом, совместный эффект персонализации и рекомендаций экономят Netflix более $1 миллиарда в год. Более того, 80% подписчиков выбирают видео именно из списка предложений рекомендательного движка.
Теперь же давайте взглянем на то, что именно TikTok делает иначе.
1. Знакомство с рекомендательным движком
(Если вы уже знакомы с этой темой, можете перескочить сразу к следующему разделу).
Существует огромное множество полезных статей и онлайн-курсов, посвящённых рекомендательным движкам, и я не хочу заново изобретать колесо.
Кроме всего основного, промышленный рекомендательный движок для интеграции нуждается в надёжном бэкенде и архитектурном дизайне. Ниже приведён основной пример:
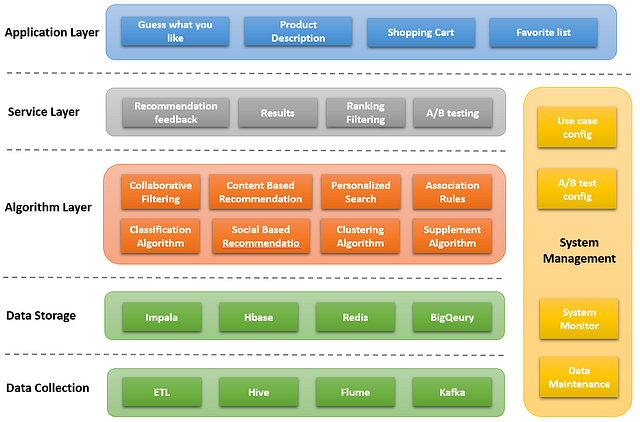
Система реального времени должна иметь прочное основание из данных (для сбора и хранения), чтобы поддерживать над собой несколько абстрактных слоёв (слой алгоритма, обслуживающий слой и слой приложения), которые будут решать различные бизнес-задачи.
2. Структура дизайна рекомендательной системы TikTok
Ядром структуры остаётся ‘дизайн, ориентированный на пользователя’. Говоря простыми словами, TikTok будет рекомендовать только тот материал, который вам должен понравиться, начиная с пробных предположений для начинающих и заканчивая явными рекомендациями для активных пользователей.
Если вы кликаете по видео с танцами, то ваша подборка будет изначально настроена на категорию развлечений, затем механизм отслеживания проследит за вашим дальнейшим выбором для дополнительного анализа, что в конечном итоге приведёт к формированию точных индивидуальных рекомендаций.
Рабочий процесс высокого уровня.
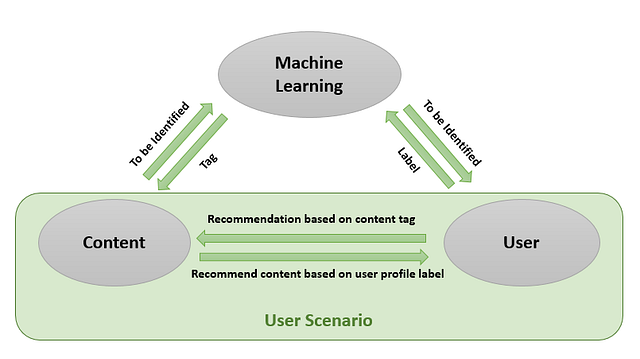
В структуре TikTok существует три основных строительных блока:
- Снабжение контента тегами.
- Создание пользовательских профилей и сценариев.
- Обучение и обслуживание алгоритмов рекомендаций.
Далее мы рассмотрим каждый из этих пунктов.
2.1 Данные и признаки
Во-первых, данные. Если бы мы описывали рекомендательную модель формально, то назвали бы её функцией, удовлетворяющей интерес пользователя с помощью сгенерированного другими пользователями контента. Для предоставления этой функции требуется ввод данных из трёх измерений.
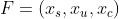
Данные контента — TikTok является платформой с огромным количеством пользовательского контента. Каждый тип этого контента имеет свои особенности, и система должна быть способна распознавать и различать их, чтобы предоставить надёжные рекомендации.
Данные пользователя — сюда входят метки интересов, карьера, возраст, пол, демографические признаки и т.д. Они также включают скрытые признаки кластеризации пользователя на основе машинного обучения.
Данные сценария — эти данные отслеживают сценарий использования и смену предпочтений пользователя в зависимости от разных сценариев. Например, какой тип видео пользователь любит смотреть, когда он находится на работе, едет на/с неё или путешествует.
Как только относительные данные собраны, из них получают четыре типа критических инженерных признаков, которые передаются в рекомендательный движок.
- Признаки соответствия представляют соответствие между атрибутами контента и тегами пользователя, включая сопоставление ключевых слов, источников, тегов темы и классификации, а также скрытые признаки вроде векторных расстояний между пользователем и контентом.
- Признаки пользовательского сценария получаются из данных сценария, включающих географическое положение, время дня, теги событий и т.д.
- Признаки тренда основываются на пользовательском взаимодействии и представляют глобальный тренд, горячую тему, актуальные темы, самые популярные ключевые слова и т.д.
- Коллаборативные признаки основываются на технике фильтрации групп. В них балансируются узкая рекомендация (предубеждение) и коллаборативная (обобщение). Говоря точнее, здесь будут учтены не только история одного пользователя, но и анализ коллективного поведения схожей группы пользователей (клики, интересы, ключевые слова, темы).
Модель будет прогнозировать, является ли контент подходящим пользователю в сценарии, основываясь на описанных выше признаках.
2.2 Неосязаемые ориентиры
В рекомендательной модели частота прокликивания, время чтения, лайки, комментарии и репосты — всё это относится к количественным ориентирам. Вы можете использовать модель или алгоритмы, чтобы их заполнить и затем сделать окончательный прогноз.
Однако другие неосязаемые ориентиры не могут быть вычислены этими исчислимыми показателями.
Например, в целях поддержания здорового сообщества и экосистемы, TikTok стремится подавлять контент, содержащий насилие, мошенничество, порнографию, флатуленцию и перегруженный фактами высококачественный контент вроде новостей.
Для достижения этой задачи фрейм пограничного контроля должен быть определён за гранью исчислимых ориентиров модели. (Система аудита контента).
2.3 Алгоритмы
Ориентиры рекомендаций можно сформулировать в классическую задачу машинного обучения. Затем эту задачу можно разрешить с помощью алгоритмов, включающих модель коллаборативной фильтрации, модель логистической регрессии, машины факторизации, GBD и глубокое обучение.

Рекомендательная система промышленного уровня требует гибкую и расширяемую платформу ML, на основе которой можно создать экспериментальный конвейер для быстрого обучения различных моделей. А затем уже собрать их для использования в реальном времени (например, совместить LR и DNN, SVM с CNN).
Помимо основного рекомендательного алгоритма TikTok нуждается в обучении алгоритма классификации контента и алгоритма обработки профилей пользователей. Ниже показана иерархическая архитектура классификации для анализа контента.
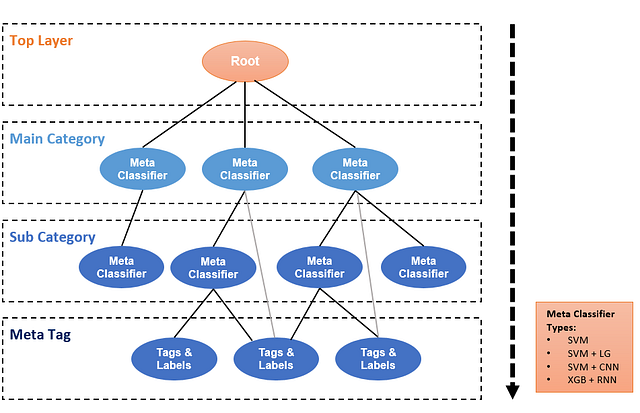
Спускайтесь вниз из корня. Нижеследующие слои представляют Main Category (основную категорию) и Sub Category (подкатегорию). В сравнении с раздельным классификатором использование механизма иерархической классификации может лучше решать проблему расфазировки данных.
2.4 Механизм обучения
TikTok использует онлайн-протокол обучения в реальном времени, который требует меньше вычислительных ресурсов и предоставляет быструю обратную связь. Это важно для продуктов с потоковой передачей данных, в том числе информационных.
Поведение пользователей и их действия можно фиксировать моментально, а затем отправлять в модель, чтобы увидеть эффект уже в следующей подборке (например, когда вы кликаете по новому видео, ваша подборка быстро изменяется на основе последних действий).
Скорее всего, TikTok использует Strom Cluster, чтобы в реальном времени обрабатывать образцы данных, включающих клики, показы, коллекции, лайки, комментарии и рекомендации.
Они также создают свою высокопроизводительную систему в виде сервера параметров и признаков модели (хранилище признаков и хранилище моделей). Хранилище признаков может сохранять и обслуживать десять миллионов оригинальных признаков и спроектированных векторов. А хранилище моделей будет поддерживать и вводить в действие модели и настроенные параметры.
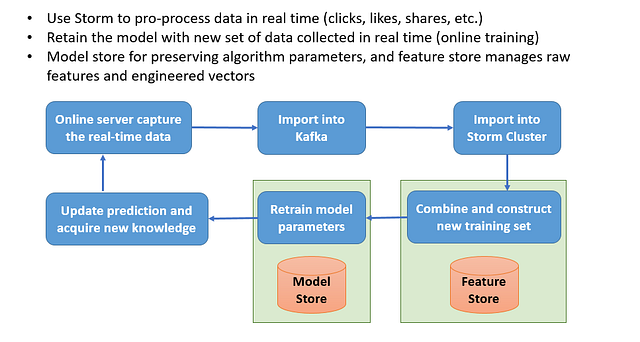
Весь процесс обучения выглядит так:
- Онлайн-сервер фиксирует данные в реальном времени, а затем сохраняет их в Kafka.
- Кластер Storm получает данные Kafka и признаки продукта.
- Хранилище признаков собирает новые признаки и рекомендательные метки, чтобы построить новый обучающий набор.
- Обучающий онлайн-конвейер переобучает параметры модели, сохраняя их в хранилище моделей.
- Обновляется клиентский список рекомендаций, фиксируется новая обратная связь (действия пользователя) и цикл повторяется.
3. Рабочий процесс рекомендаций в TikTok
TikTok никогда не раскрывает свой ключевой алгоритм для общественности или tech-сообщества. Но, основываясь на фрагментированной информации, размещённой через компанию, а также следах, обнаруженных энтузиастами при помощи реверсивных инженерных техник, я составила следующее заключение.
(Дисклеймер — это моя личная интерпретация и экстраполяция, которая может отличаться от того, что на самом деле делает TikTok).
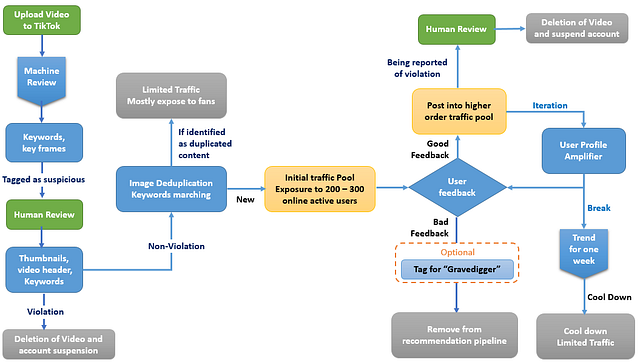
Шаг 0: Система двойного аудита пользовательского контента (UGC)
В TikTok существуют миллионы различных материалов, загружаемых пользователями ежедневно. Вредоносным материалам было бы легче найти лазейки в системе только машинной проверки, а ручная проверка в данном случае просто нереальна. Поэтому алгоритм двойного ревью стал в TikTok основным для оценки видео-контента.
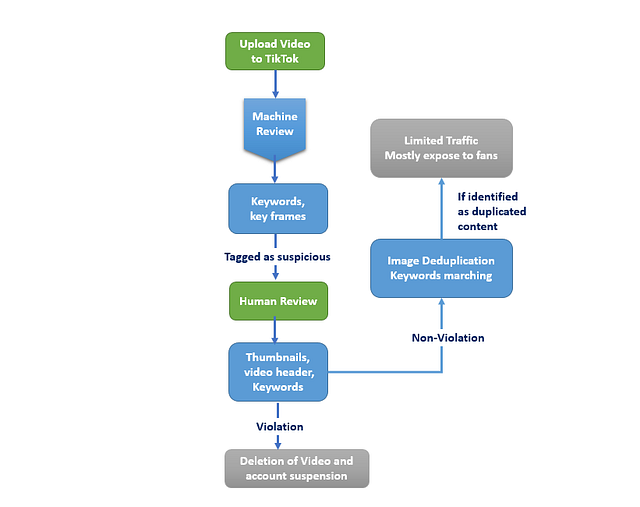
Машинное ревью: по существу, модель двойного аудита (основанная на компьютерном зрении) может распознать ваши видеоизображения и ключевые слова. В ней есть две главные функции:
- Определять наличие разрывов в клипах и проверять авторские права. Если возникает подозрение в нарушении, содержимое будет отвергнуто моделью и помечено жёлтым или красным для просмотра людьми.
- Извлекая картинки и ключевые кадры из видео, алгоритм двойного аудита сопоставляет их с массивной базой контента в архиве. Повторы отбираются, для них занижается стартовый трафик и весомость в рекомендательном движке.
Ревью человеком главным образом фокусируется на 3 областях: заголовок видео, миниатюра обложки и ключевые кадры видео. Контент, получивший в модели двойного аудита тег “подозрительный”, техники просматривают лично. Если материал определяется как нарушающий правила, то видео удаляется, а действие аккаунта приостанавливается.
Шаг 1: Холодный старт
Сердцем рекомендательного механизма TikTok является воронка информационного потока. Когда контент проходит двойной аудит, он помещается в пул трафика холодного старта. Например, после того как ваше новое видео пройдёт ревью, TikTok присвоит ему начальный траффик из 200–300 активных пользователей, откуда вы можете получить вплоть до нескольких тысяч показов.
В этом механизме новый создатель может соревноваться с любимцами публики (людьми с десятками тысяч последователей), поскольку у них обоих одинаковая стартовая точка.
Шаг 2: Взвешивание, основанное на метриках
Находясь в пуле начального траффика, видео может получить тысячи просмотров, и эти данные будут собраны и проанализированы. Метрики, рассматриваемые в этом анализе, включают: лайки, просмотры, полные просмотры, комментарии, последователей, репосты, публикации в сети и т.п.
Затем рекомендательный движок взвесит ваш контент на основе этих метрик, а также общего балла аккаунта (показывающего ваш уровень качества как создателя).
На основе этого взвешивания лучшие 10% контента получат по 10 000–100 000 дополнительных показов.
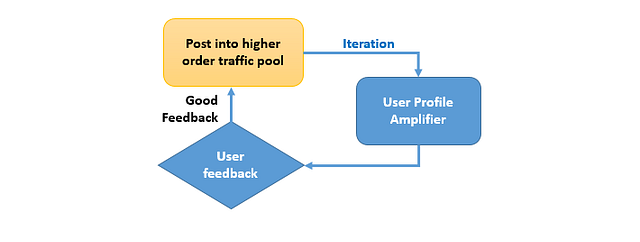
Шаг 3: Усилитель профиля пользователя
Обратная связь из шага 2 далее будет также проанализирована для принятия решения об использовании усилителя пользовательского профиля. На этом шаге выдающийся контент будет усилен и сакцентирован для определённой группы (например, поклонники спорта, моды и т.п.).
Это аналогично принципу функции “угадай, что тебе нравится”. Рекомендательный движок создаст базу профилей пользователей, чтобы иметь возможность найти наилучшее соответствие между контентом и группой пользователей.
Шаг 4: Пул эксклюзивных трендов
Менее 1% контента в конечном счёте попадут в трендовый пул. Количество показов контента в этом пуле может в разы превысить другие пулы. Т.к. трендовый контент будет рекомендован всем пользователям без разбора (независимо от того, кто вы, вам может быть интересно посмотреть видео с актуальными событиями в мире).
Отдельный шаг: позднее зажигание
Некоторые пользователи TikTok замечают, что их контент внезапно получает огромную популярность спустя недели его размещения со средним откликом.
Это возможно по двум причинам:
- Во-первых, TikTok имеет алгоритм под псевдонимом “могильщик”, который просматривает старый контент и выискивает высококачественных претендентов для показа. Если ваш контент был выбран этим алгоритмом, то это признак того, что ваш аккаунт имеет достаточно вертикальных видео для получения чёткой метки. Эта метка повысит видимость вашего контента в могильщике.
- Во-вторых, возможен “эффект тренда”. Это означает, что если один из ваших материалов получает миллионы просмотров, то через него пойдёт трафик на вашу главную страницу, тем самым повышая просмотры старого контента. Это зачастую случается у создателей вертикалей (например, у создателя смешных видео с кошками). Одно популярное видео активизирует все остальные высококачественные материалы (люди хотят посмотреть и другой контент с вашими милыми кошками).
Ограничение: пики трафика
Если одно облако контента проходит воронку информационного потока (двойной аудит, итерации взвешивания и усилители), то аккаунт создателя получает расширенную экспозицию, взаимодействие с пользователями и поклонников.
Однако, судя по исследованиям, это окно повышенной экспозиции достаточно невелико. Как правило, оно сохраняется около недели. Спустя этот промежуток времени контент и аккаунт остывают и даже последующие видео вряд ли станут популярными.
Почему?
Главная причина в том, что TikTok стремиться ввести в этом алгоритме разнообразие и удалять непреднамеренную предвзятость. Согласно такому дизайну, рекомендательный движок не будет предрасположен к конкретному виду контента, тем самым обеспечивая новому контенту равные возможности для попадания в трендовый пул.
Читайте также:
- Лучшие фреймворки для ИИ и машинного обучения в веб-разработке
- Анализ моделей машинного обучения при помощи Imandra
- Глубокие нейросети: руководство для начинающих
Перевод статьи Catherine Wang: Why TikTok made its user so obsessive? The AI Algorithm that got you hooked.





