
Введение
ИИ уже успел достаточно нашуметь — о нейросетях сейчас знают и в научной среде, и в бизнесе. Вам наверняка случалось читать, что совсем скоро ваши рабочие процессы уже не будут прежними из-за какой-нибудь формы ИИ или нейросети. И вы, я уверен, слышали (пусть и не всё) о глубоких нейронных сетях и глубоком обучении.
В этой статье я приведу самые короткие, но эффективные способы понять, что такое глубокие нейронные сети, а также расскажу о том, как внедрить их с помощью библиотеки PyTorch.
Определение глубоких нейросетей (глубокого обучения) для новичков
Попытка 1
Глубокое обучение — это подраздел машинного обучения в искусственном интеллекте (ИИ), алгоритмы которого основаны на биологической структуре и функционировании мозга и призваны наделить машины интеллектом.
Сложно звучит? Давайте разобьём это определение на отдельные слова и составим более простое объяснение. Начнём с искусственного интеллекта, или ИИ.
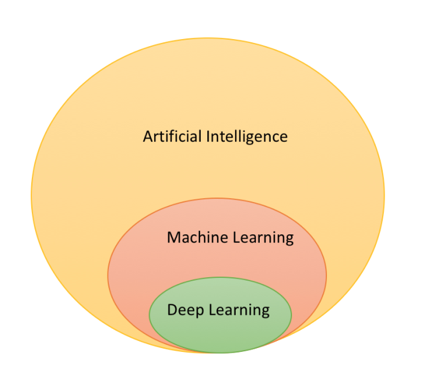
Artificial Intelligence - Искусственный интеллект
Machine Learning - Машинное обучение
Deep Learning - Глубокое обучениеИскусственный интеллект (ИИ) в наиболее широком смысле — это разум, встроенный в машину. Обычно машины глупые, поэтому, чтобы сделать их умнее, мы внедряем в них интеллект — в результате машина может самостоятельно принимать решения. К примеру, стиральная машина определяет необходимый объём воды, а также требуемое время для замачивания, стирки и отжима. Таким образом, она принимает решение, основываясь на конкретных вводных условиях, а значит делает свою работу разумнее. Или, например, банкомат, который выдаёт нужную вам сумму, составляя правильную комбинацию из имеющихся в нём банкнот. Такой интеллект внедряется в машины искусственным путём — отсюда и название “искусственный интеллект”.
Важно отметить, что интеллект здесь запрограммирован явно, то есть создан на основе подробного списка правил вида “если…, то…”. Инженер-проектировщик тщательно продумал все возможные комбинации и создал систему, которая принимает решения, проходясь по цепочке правил. А что если нам нужно внедрить интеллект в машину без явного программирования, то есть, чтобы машина училась сама? Здесь-то мы и подходим к теме машинного обучения.
Машинное обучение — это процесс внедрения интеллекта в систему или машину без явного программирования.
— Эндрю Ын, адъюнкт-профессор Стэнфордского университета
Примером машинного обучения могла бы стать система, предсказывающая результат экзамена на основе предыдущих результатов и характеристик студента. В этом случае решение о том, сдаст студент экзамен или нет, основывалось бы не на подробном списке всех возможных правил — напротив, система обучалась бы сама, отслеживая паттерны в предыдущих наборах данных.
Так где же в этом контексте место глубокого обучения? Машинное обучение успешно решает многие вопросы, но порой не может справиться с задачами, которые кажутся людям очень простыми. К примеру, оно не может отличить кошку от собаки на картинке или мужской голос от женского на аудиозаписи и т. п. Результаты применения машинного обучения чаще всего плохие при обработке изображений, аудио и других типов неструктурированных данных. При поиске причин таких результатов пришло озарение — идея скопировать биологические процессы человеческого мозга, который состоит из миллиардов нейронов, связанных и скоординированных между собой особым образом для изучения нового. Изучение нейронных сетей шло одновременно с этим уже несколько лет, но прогресс был небольшим из-за ограничений в данных и вычислительных мощностях того времени. Когда машинное обучение и нейросети были достаточно изучены, появилось глубокое обучение, которое предполагало создание глубоких нейронных сетей, то есть произвольных нейросетей с гораздо большим количеством слоёв.
Теперь давайте вновь взглянем на определение глубокого обучения.
Попытка 2
Глубокое обучение — это раздел машинного обучения и искусственного интеллекта с алгоритмами, основанными на деятельности человеческого мозга и призванными внедрить интеллект в машину без явного программирования.
Стало гораздо понятнее, правда? 🙂
Там, где машинное обучение не справлялось, глубокое обучение применялось успешно. С течением времени проводились дополнительные исследования и эксперименты, позволившие понять, для каких ещё задач мы можем задействовать глубокое обучение и получать качественные результаты при достаточном объёме данных. Глубокое обучение стали широко использовать для решения прогностических задач, не ограничивая его применение машинным распознаванием образов, речи и т. п.
Какие задачи глубокое обучение решает сегодня?
С появлением экономически эффективных вычислительных мощностей и накопителей данных глубокое обучение проникло во все цифровые аспекты нашей повседневной жизни. Вот несколько примеров цифровых продуктов из обычной жизни, в основе которых лежит глубокое обучение:
- популярные виртуальные помощники Siri/Alexa/Google Assistant;
- предложение отметить друга на только что загруженной фотографии в Facebook;
- автономное вождение в автомобилях Tesla;
- фильтр с кошачьими мордами в Snapchat;
- рекомендации в Amazon и Netflix;
- недавно выпущенные, но получившие вирусную популярность приложения для обработки фото — FaceApp и Prisma.
Возможно, вы уже пользовались приложениями с применением глубокого обучения и просто не знали об этом.
Глубокое обучение проникло буквально во все отрасли. К примеру, в здравоохранении с его помощью диагностируют онкологию и диабет, в авиации — оптимизируют парки воздушных судов, в нефтегазовой индустрии— проводят профилактическое техобслуживание оборудования, в банковской и финансовой сферах — отслеживают мошеннические действия, в розничной торговле и телекоммуникациях — прогнозируют отток клиентов и т. д. Эндрю Ын верно назвал ИИ новым электричеством: подобно тому, как электричество в своё время изменило мир, ИИ также изменит практически всё в ближайшем будущем.
Из чего состоит глубокая нейронная сеть?
Упрощённая версия глубокой нейросети может быть представлена как иерархическая (слоистая) структура из нейронов (подобно нейронам в мозге), связанных с другими нейронами. На основе входных данных одни нейроны передают команду (сигнал) другим и таким образом формируют сложную сеть, которая обучается с помощью определённого механизма обратной связи. На диаграмме ниже изображена глубокая нейронная сеть с количеством слоёв N.
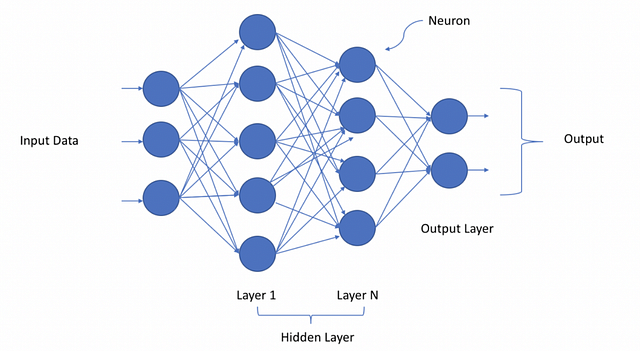
Neuron - Нейрон
Input Data - Входные данные
Output - Выход
Layer - Слой
Output Layer - Выходной слой
Hidden Layer - Скрытый слойКак видно на рисунке выше, входные данные передаются нейронам на первом (не скрытом) слое, они в свою очередь передают выходные данные нейронам на следующем слое и так далее до финального выхода. Выход может представлять собой прогноз (вроде “Да”/“Нет”), представленный через вероятность. На каждом слое может быть один или множество нейронов, каждый из которых вычисляет небольшую функцию, функцию активации. Эта функция имитирует передачу сигнала последующим, связанным с предыдущими, нейронам. Если результат входных нейронов превышает порог, выходное значение просто игнорируется и передаётся дальше. Связь между двумя нейронами соседних слоёв имеет вес. Вес определяет влияние входных данных на выход для следующего нейрона и последующий финальный выход. Начальные веса нейросети случайные, однако в процессе обучения модели они постоянно обновляются и обучаются предсказывать верное выходное значение. В процессе анализа нейросети можно обнаружить несколько логических структурных элементов (нейрон, слой, вес, вход, выход, функция активации и наконец механизм обучения, или оптимизатор), которые помогают ей постепенно заменять веса (изначально со случайными значениями) на более подходящие для точного прогноза выхода.
Для более ясного понимания давайте рассмотрим, как человеческий мозг учится различать людей. Когда вы встречаете человека во второй раз, то узнаёте его. Как так получается? У всех людей схожее строение: два глаза, два уха, нос, губы и т. д. Все одинаково устроены, и, тем не менее, различать людей нам довольно легко, не так ли?
Природа процесса обучения человеческого мозга довольно очевидна. Вместо того чтобы для узнавания людей изучать структуру лица, мы изучаем отклонения от типичного лица, то есть то, насколько сильно отличаются глаза конкретного человека от типичного глаза. Далее эта информация преобразуется в электрический сигнал определённой силы. Подобным же образом изучаются отклонения всех остальных частей лица от типичных. Все эти отклонения в итоге собираются в новые признаки и дают выходное значение. Всё описанное происходит за доли секунды, и мы просто не успеваем понять, что произошло в нашем подсознании.
Как показано выше, нейросеть пытается имитировать тот же процесс, используя математический подход. Входные данные принимаются нейронами первого слоя, и в каждом нейроне вычисляется функция активации. На основе простого правила нейрон передаёт выходное значение следующему нейрону, подобно тому, как человеческий мозг изучает отклонения. Чем больше выход нейрона, тем большее значение имеет соответствующий входной признак. На последующем слое эти признаки объединяются в новые, которые имеют пока непонятную для нас форму, но система обучается им интуитивно. Повторённый множество раз этот процесс приводит к формированию сложной сети со связями.
Теперь, когда структура нейросетей понятна, давайте разберёмся, как происходит обучение. Из входных данных, которые мы предоставляем сети, на выходе получается прогноз (с серией матричных умножений), который может быть верным или неверным. В зависимости от выхода мы можем потребовать от сети более точных прогнозов, и система будет обучаться, меняя значения весов для нейронных связей. Чтобы правильно дать сети обратную связь и определить следующий шаг для внесения изменений, мы используем элегантный математический алгоритм “обратного распространения ошибок”. Повторение процесса шаг за шагом несколько раз с нарастающим объёмом данных позволяет нейросети обновлять веса соответствующим образом и создаёт систему, в которой сеть может делать прогноз на основе созданных ею через веса и связи правил.
Название “глубокие нейронные сети” пошло от использования множества скрытых слоёв, которые и делают нейросеть “глубокой”, способной обучаться более сложным паттернам. Истории успешного применения глубокого обучения только-только начали появляться в последние годы, ведь процесс обучения нейронной сети сложный по части вычислений и требует больших объёмов данных. Эксперименты наконец увидели свет, только когда возможности вычисления и хранения данных стали более доступными.
Какие есть популярные фреймворки для глубокого обучения?
Учитывая то, что внедрение глубокого обучения прошло быстрыми темпами, прогресс экосистемы для него также стал феноменальным. Благодаря множеству крупных технологических компаний и проектов с открытым исходным кодом вариантов для выбора более чем достаточно. Эти фреймворки глубокого обучения предоставляют блоки кода для многократного использования, из которых можно составить описанные выше логические блоки, а также несколько удобных дополнительных модулей для создания модели глубокого обучения.
Все доступные варианты фреймворков глубокого обучения можно разделить на низкоуровневые и высокоуровневые. Пусть такая терминология и не принята в этой области, но мы можем использовать это разделение, чтобы облегчить себе понимание фреймворков. Низкоуровневые фреймворки предлагают более базовый функционал для абстракции, который в то же время даёт массу возможностей для кастомизации и трансформации. Высокоуровневые фреймворки упрощают нам работу своей более продвинутой абстракцией, но ограничивают нас во внесении изменений. Высокоуровневые фреймворки используют низкоуровневые на бэкенде и в процессе работы конвертируют источник в желаемый низкоуровневый фреймворк для выполнения. Ниже приведены несколько вариантов популярных фреймворков для глубокого обучения.
Низкоуровневые фреймворки:
- TensorFlow
- MxNet
- PyTorch
Высокоуровневые фреймворки:
- Keras (использует TensorFlow на бэкенде)
- Gluon (использует MxNet на бэкенде)
Самый популярный сейчас фреймворк — TensorFlow от Google. Keras также довольно популярен благодаря быстрому прототипированию моделей глубокого обучения и, следовательно, упрощению работы. PyTorch от Facebook — ещё один фреймворк, который стремительно догоняет конкурентов. PyTorch может стать прекрасным выбором для многих специалистов по ИИ: он затрачивает меньше времени на обучение, чем TensorFlow, и может легко применяться на всех этапах создания модели глубокого обучения — от прототипирования до внедрения.
В этом руководстве для внедрения небольшой нейросети мы предпочтём именно PyTorch. Но прежде чем сделать свой выбор фреймворка изучите и другие варианты. В этой статье (eng) приводится отличное сравнение и детальное описание разных фреймворков — это поможет вам в выборе. Однако в ней нет введения в PyTorch — для этого я рекомендую ознакомиться с официальной документацией.
Создание небольшой нейронной сети с PyTorch
Вкратце изучив тему, мы можем приступить к созданию простой нейронной сети с помощью PyTorch. В этом примере мы генерируем набор фиктивных данных, которые имитируют сценарий классификации с 32 признаками (колонки) и 6000 образцов (строки). Набор данных обрабатывается с помощью функции randn в PyTorch.
Этот код вы также можете найти на Github.
#Импорт требуемых библиотек
import torch as tch
import torch.nn as nn
import numpy as np
from sklearn.metrics import confusion_matrix
#Создание 500 результатов с помощью randn | Присвоен тег 0
X1 = tch.randn(3000, 32)
#Создание ещё 500 немного отличающихся от X1 результатов с помощью randn | Присвоен тег 0
X2 = tch.randn(3000, 32) + 0.5
#Комбинирование X1 и X2
X = tch.cat([X1, X2], dim=0)
#Создание 1000 Y путём комбинирования 50% 0 и 50% 1
Y1 = tch.zeros(3000, 1)
Y2 = tch.ones(3000, 1)
Y = tch.cat([Y1, Y2], dim=0)
# Создание индексов данных для обучения и расщепления для подтверждения:
batch_size = 16
validation_split = 0.2 # 20%
random_seed= 2019
#Перемешивание индексов
dataset_size = X.shape[0]
indices = list(range(dataset_size))
split = int(np.floor(validation_split * dataset_size))
np.random.seed(random_seed)
np.random.shuffle(indices)
#Создание индексов для обучения и подтверждения
train_indices, val_indices = indices[split:], indices[:split]
#Создание набора данных для обучения и подтверждения
X_train, x_test = X[train_indices], X[val_indices]
Y_train, y_test = Y[train_indices], Y[val_indices]
#Отрисовка формы каждого набора данных
print("X_train.shape:",X_train.shape)
print("x_test.shape:",x_test.shape)
print("Y_train.shape:",Y_train.shape)
print("y_test.shape:",y_test.shape)
#Создание нейронной сети с 2 скрытыми слоями и 1 выходным слоем
#Скрытые слои имеют 64 и 256 нейронов
#Выходные слои имеют 1 нейрон
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(32, 64)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(64, 256)
self.relu2 = nn.ReLU()
self.out = nn.Linear(256, 1)
self.final = nn.Sigmoid()
def forward(self, x):
op = self.fc1(x)
op = self.relu1(op)
op = self.fc2(op)
op = self.relu2(op)
op = self.out(op)
y = self.final(op)
return y
model = NeuralNetwork()
loss_function = nn.BCELoss() #Бинарные потери по перекрёстной энтропии
optimizer = tch.optim.Adam(model.parameters(),lr= 0.001)
num_epochs = 10
batch_size=16
for epoch in range(num_epochs):
train_loss= 0.0
#Начало явного обучения модели
model.train()
for i in range(0,X_train.shape[0],batch_size):
#Извлечение пакета обучения из X и Y
input_data = X_train[i:min(X_train.shape[0],i+batch_size)]
labels = Y_train[i:min(X_train.shape[0],i+batch_size)]
#Установление градиентов на 0 перед применением алгоритма обратного распространения ошибок
optimizer.zero_grad()
#Дальнейшая передача данных
output_data = model(input_data)
#Подсчёт потерь
loss = loss_function(output_data, labels)
#Применение алгоритма обратного распространения ошибок
loss.backward()
#Обновление весов
optimizer.step()
train_loss += loss.item() * batch_size
print("Epoch: {} - Loss:{:.4f}".format(epoch+1,train_loss/X_train.shape[0] ))
#Прогнозирование
y_test_pred = model(x_test)
a =np.where(y_test_pred>0.5,1,0)
confusion_matrix(y_test,a)Заключение
Целью этой статьи было вкратце познакомить новичков с глубокими нейросетями, объяснив тему простым языком. Упрощение математических расчётов и полное сосредоточение на функциональности позволит максимально эффективно использовать глубокое обучение для современных бизнес-проектов.
Читайте также:
- Подробное руководство по свёрточным нейронным сетям
- Рекуррентная нейронная сеть с головы до ног
- Заставляем глубокие нейронные сети рисовать, чтобы понять, как они работают
Перевод статьи Jojo John Moolayil: A Layman’s Guide to Deep Neural Networks





