
Введение
Раньше на рынке не было сложных управляемых служб Kafka. Поэтому мы в Zendesk построили с помощью Chef собственную инфраструктуру, развернув ее на экземплярах AWS EC2.
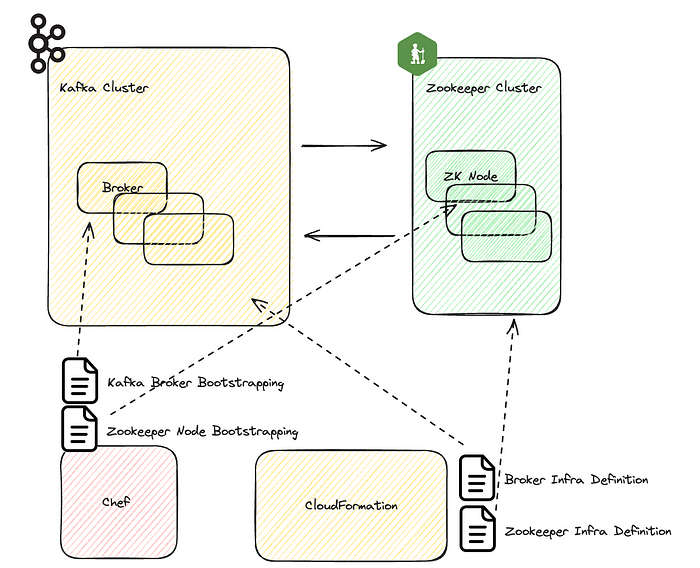
Кластер Kafka состоит из двух частей: набора брокеров Kafka и узлов Zookeeper. Брокер ― это сервер в кластере Kafka, в котором хранятся и контролируются данные, ведется работа по публикации сообщений и подписке на них. Кластер Zookeeper ― это кворум, которым координируются и контролируются брокеры Kafka, выполняются задачи вроде выбора лидера, принадлежности к кластеру, поддержания метаданных.
Мы перенесли инфраструктуру с виртуальной машины в Kubernetes, или K8s. Поддержка инструментария Chef сократилась, поэтому потребовалась миграция инфраструктуры Kafka.
Определение плавной миграции
Плавная миграция для кластера Kafka ― прозрачный процесс с нулевым простоем, поддержкой целостности и согласованности данных, минимальными изменениями со стороны клиентов и минимальным ручным вмешательством.
Это репликация конфигурации и данных старого кластера, перевод клиентов на новый, обеспечение непрерывности работы и эквивалентной производительности.
Сложность плавной миграции напрямую связана с масштабом кластера и его клиентами. Миграция кластера, используемого нечасто или для обработки в основном автономных рабочих нагрузок, относительно проста. А вот миграция кластера, в котором обслуживаются серьезные рабочие нагрузки в реальном времени и значительный объем данных, намного сложнее.
Кластеры Kafka в Zendesk относятся ко второй категории. В них осуществляется управление существенным объемом данных более чем 100 служб.
Подробное состояние кластера Kafka:
- 12 кластеров Kafka;
- немногим менее 100 брокеров во всех средах;
- 300 ТБ данных в хранилище;
- 30 млрд сообщений в день;
- более 1000 тем;
- более 100 подключенных служб.
Основные проблемы
Миграцию такого большого и важного кластера требуется тщательно продумать, уделив внимание деталям, а главное, обеспечить:
- целостность данных и доступность кластера на этапе репликации,
- плавность перехода клиентов на этапе переключения.
Важно понимать: нет одномоментного переключения, когда после полной репликации всех данных клиенты массово перемещаются на новый кластер. Миграция потому и плавная, что на этапе переключения данные реплицируются непрерывно и одновременно с переходом клиентов.
Проект миграции
Однонаправленная миграция из кластера в кластер
Проект первой версии ― однонаправленная миграция из кластера в кластер. Здесь данные и конфигурации реплицируются из старого кластера в новый с помощью MirrorMaker2. После того как начальная загрузка данных перенесена между кластерами, данные остаются синхронизированными и каждый клиент осуществляет переходный процесс, отключаясь от старого кластера и подключаясь к новому:
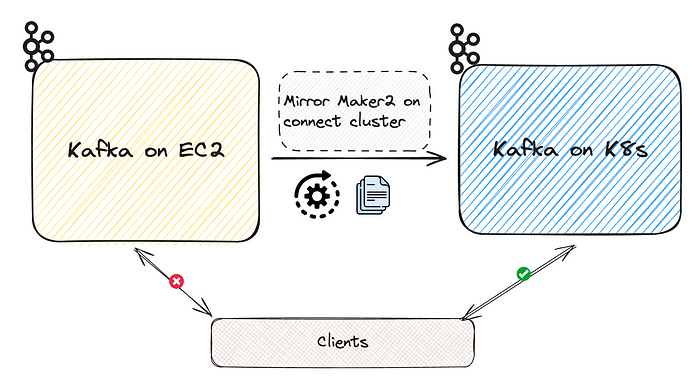
Проблема: сложность миграции перекладывается на клиентов
Этот подход изначально кажется простым и надежным, однако сложность миграции перекладывается им на управляющие клиентами Kafka команды. От каждого клиента требуется разработать и осуществить собственную стратегию перехода потенциально с несколькими развертываниями, исходя из их реализации.
Например, в простейшем сценарии, когда одна команда контролирует и отправителя, и получателя темы, сопровождаемый изменениями кода и неоднократными развертываниями перенос клиентов происходит так:
- в новый кластер перемещаются все получатели;
- отправка в старый кластер прекращается;
- в новом кластере данные полностью синхронизируются;
- запускается отправитель, указывая на новый кластер.
В сценарии посложнее, когда различные команды контролируют разные группы получателей темы, необходима скоординированная миграция с участием всех команд. Если получатель ― это еще и отправитель для другой темы, сложность возрастает. В итоге получается разветвленный, многоуровневый процесс миграции.
Дополнительные накладные расходы
Для этого конкретного проекта миграции имеются дополнительные накладные расходы:
- Единая точка отказа ― кластер подключения MirrorMaker2. Когда все получатели темы мигрировали в новый кластер, но окончательные данные в процессе выполнения синхронизировать из старого кластера не удается из-за сбоя MirrorMaker2.
- Косвенность в обнаружении сбоев и отработке отказа. Хотя сбой MirrorMaker2 неподконтролен каждой из команд, процесс отработки отказа клиента полностью зависит от них, поскольку при этом требуются изменения кода или повторное развертывание предыдущей версии.
- Проблема длинного хвоста. Полное завершение миграции зависит от скорости самого медленного клиента. Из-за упомянутой выше сложности ряду клиентов требуется значительно больше времени на завершение миграции, в итоге реализация проекта в целом замедляется.
- Затраты. На этом этапе затраты брокеров на вычисление и хранение удваиваются, а на передачу данных ― их перемещение от старых брокеров в кластер подключения, а затем к новым брокерам ― утраиваются.
Межкластерная миграция достижима, но мы стремимся к большему
Этот подход ― ни плавная миграция с точки зрения клиента, ни практическая реализация в таком масштабе по операциям и экономической эффективности.
Миграция на уровне брокеров в объединенном кластере Kafka
Основная проблема межкластерной миграции заключается в том, что в какой-то момент клиенты должны указывать на другой кластер. Время перехода ― для обеспечения целостности данных ― у получателей и отправителей различается.
Чтобы решить проблему, поставим вопрос радикальнее: «Могут ли клиенты не зависеть от переключения кластера?»
Повторим, миграция кластера ― это репликация конфигураций и данных из старого кластера в новый, а также переход клиентов.
Но что, если исключить из уравнения переход клиентов? Создадим не новый кластер, а набор брокеров в K8s и зарегистрируем их с имеющимся кластером. Так, клиентам уже не нужно менять кластеры. Остается только перенести данные от старых брокеров к новым в этом объединенном кластере Kafka.
В самом деле, новые брокеры присоединятся к имеющемуся кластеру, поэтому в переносе конфигурации нет необходимости. Нужные конфигурации уже в кластере, так что процесс упрощается.
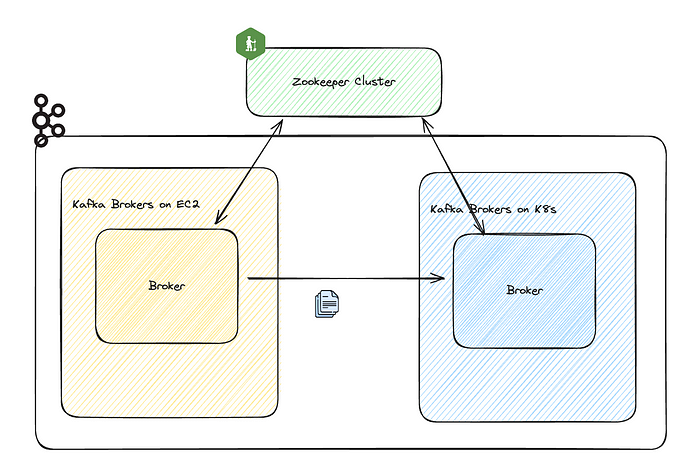
Почему передача данных между брокерами приводит к переключению клиентов?
Этот процесс обусловлен механизмом взаимодействия клиента Kafka. Тема Kafka состоит из разделов, у каждого из которых имеются реплики. В большинстве случаев клиенты взаимодействуют с репликами-лидерами.
Когда данные тем переносятся от одного брокера к другому, фактически переносятся реплики. Как только реплика полностью перенесена и выбрана лидером, это изменение обнаруживается клиентом, и начинается взаимодействие с новой репликой-лидером. В итоге начинается взаимодействие клиента с новым брокером.
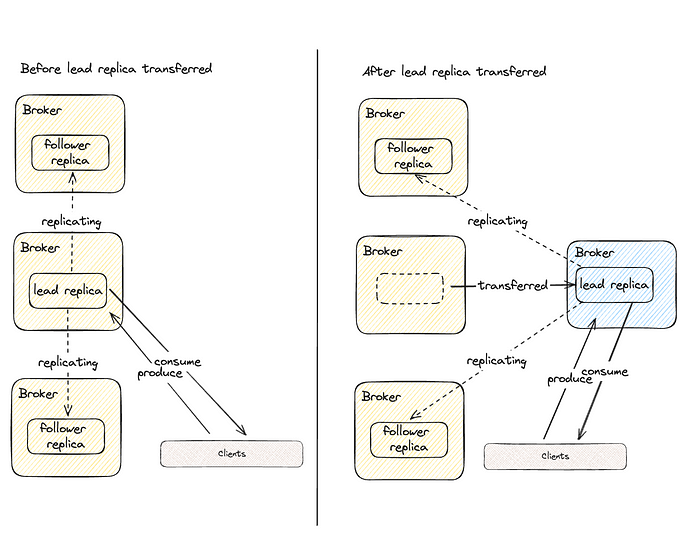
Согласно этой схеме, как только все реплики перенесены к новым брокерам, все клиенты взаимодействуют с новыми брокерами, а старыми важных задач больше не выполняется.
Разложим этот подход на этапы
- Разворачиваем столько же брокеров в K8s и регистрируем их в том же кластере Kafka в ZooKeeper. На этом этапе брокеры EC2 и K8s принадлежат одному кластеру, но в брокерах EC2 остаются все данные и обрабатывает весь клиентский трафик. Брокеры K8s неактивны, с ZooKeeper только поддерживается их работоспособность.
- Реплики разделов тем начинают мигрировать из брокеров EC2 к брокерам K8s. Как только реплика полностью перенесена, брокеры K8s начинают обслуживать актуальные темы клиентов, исходя из того, имеется ли в них реплика-лидер.
- Все реплики разделов тем перенесены от брокеров EC2 к брокерам K8s. В брокерах EC2 больше нет данных, и запросы клиентов не обрабатываются.
- Количество брокеров EC2 сокращается, в кластере остаются лишь брокеры K8s. Миграция завершена.
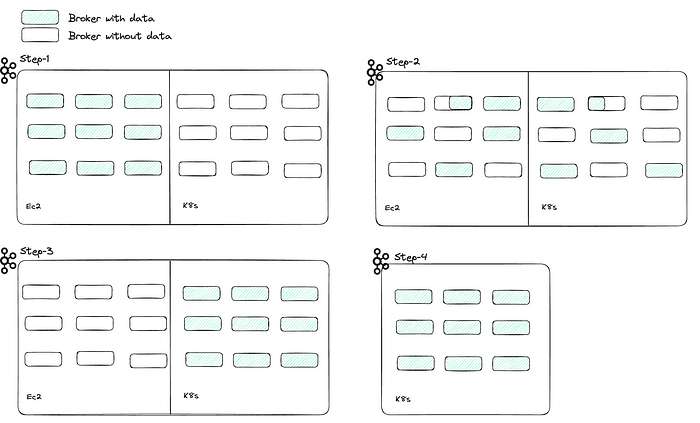
Следуя этапам миграции, мы избавились от необходимости перехода клиента. Поскольку клиенты все это время взаимодействуют с одним кластером, миграция становится для них абсолютно плавной.
Подробный разбор
От общей картины перейдем к конкретной настройке:
- Настройка сети. Важно объединить два разных набора брокеров, облегчить их обнаружение клиентами в этом гибридном кластере Kafka.
- Реализация и оркестрация миграции. Важна не только реализация переноса реплик к новым брокерам, но и эффективная оркестрация, которой должны учитываться и сценарии аварийного восстановления, например откаты.
- Показатели и мониторинг. Эффективный мониторинг гибридного кластера — когда брокерами EC2 и K8s обрабатывается трафик — важен для выявления проблем, отладки и тонкой настройки производительности.
- Контроль за перебоями в работе брокеров. Для высокой доступности нужны безостановочные брокеры или не допускать, чтобы брокеры из разных зон доступности отключались даже во время миграции.
Настройка сети для взаимодействия между брокерами, а также клиентом и брокером
Важная предпосылка миграции на уровне брокера ― взаимодействие обоих наборов брокеров с кластером ZooKeeper при относительно низкой задержке. А также возможность обнаружения клиентами обоих наборов брокеров и взаимодействия с ними при низкой задержке.
Первый вопрос решается сетевой архитектурой. Брокеры EC2, кластеры Zookeeper и K8s развернуты хоть и в разных подсетях, но взаимосвязанных, и в одной учетной записи AWS.
Чтобы брокеры EC2 и K8s обнаруживались клиентами, придется еще немного повозиться. Сначала разберемся в механизме обнаружения клиентами брокеров.
Механизм обнаружения брокеров клиентами
Для корректной работы, исходя из количества разделов в целевой теме и распределения реплик этих разделов, клиенту Kafka нужно «знать» почти каждого брокера. Типичный подход:
- Для извлечения метаданных о том, каким брокером какие разделы обслуживаются, клиентом выбирается брокер начальной загрузки.
- Клиентом запрашивается установка подключения с каждым из этих брокеров.
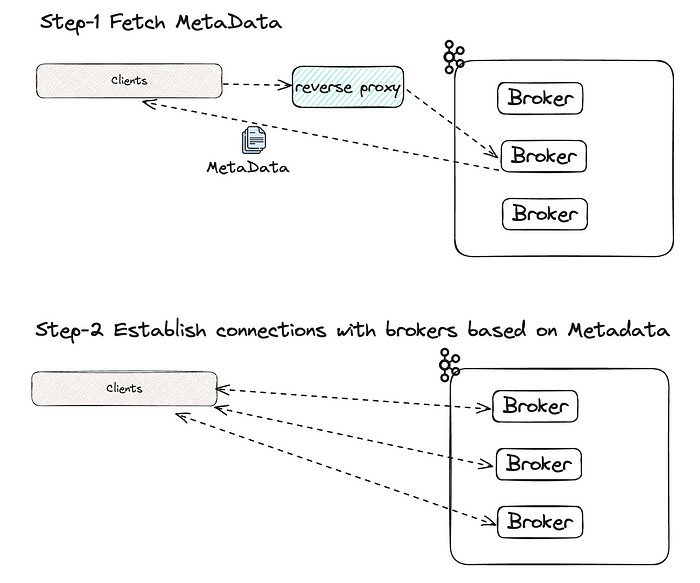
Следовательно, клиентам должен быть доступен обратный прокси-сервер, определенный для брокеров EC2, и такой же для брокеров K8s. Поскольку все брокеры находятся в одном кластере, любым из них клиенту предоставляются полные метаданные ― будь то EC2 или K8s.
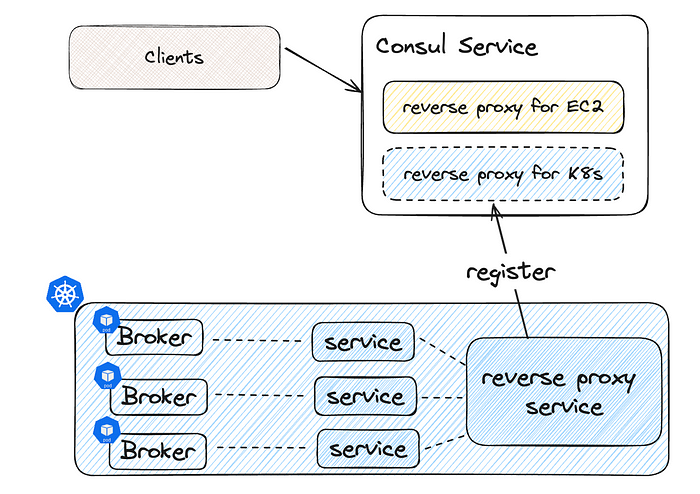
Службы обнаруживаются HashiCorp-службой Consul. Чтобы обнаружить оба набора брокеров, в имеющейся в Kafka службе Consul клиентами регистрируется новый IP-адрес службы обратного прокси-сервера. В K8s объявленный прослушиватель для каждого брокера и обратный прокси-сервер этих прослушивателей ― K8s Service.
Реализация и оркестрация миграции
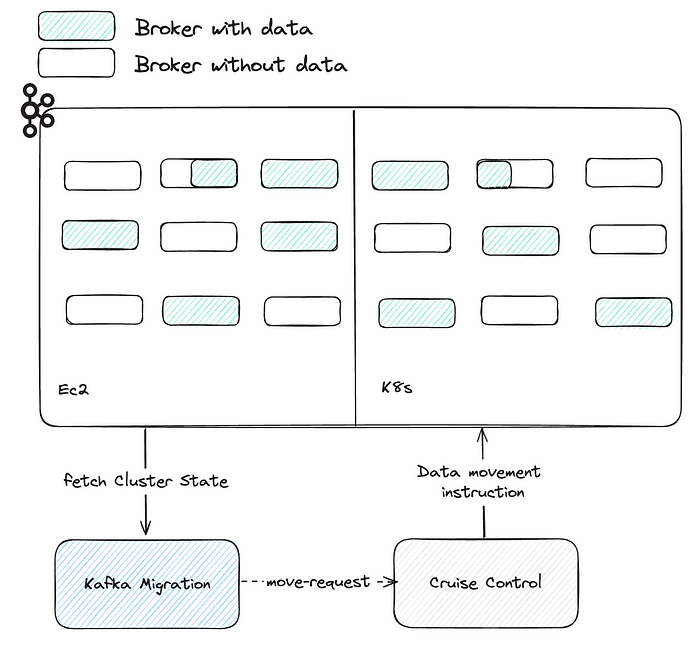
Пока все хорошо, кластер Kafka со взаимосвязанными брокерами ― будь то EC2 или K8s ― настраивается. Клиентами обнаруживается любой брокер, они подключаются к нему. Но как реплики перемещаются от одного брокера к другому?
Перемещение реплики осуществляется с помощью Cruise Control, где имеются полнофункциональные API-интерфейсы для управления кластером Kafka в больших масштабах. remove_broker ― одна из конечных точек для перемещения реплик, в которой брокер сворачивается, а все его реплики перемещаются к целевому брокеру.
curl -X POST "$CRUISE_CONTROL_SERVICE/remove_broker?brokerid=11&concurrent_partition_movements_per_broker=25&destination_broker_ids=31&replication_throttle=100000000"
Это запрос к Cruise Control на перемещение всех реплик из «broker-11» в «broker-31». То, что нужно. Им также определяется что в каждый конкретный момент времени разрешено перемещение всего 25 одновременно выполняемых реплик, а общая скорость репликации ― ~100 Mбит/с.
Оркестрация
Вызывать конечную точку Cruise Control вручную нецелесообразно, небезопасно и неэффективно. Поэтому и создали систему оркестрации Kafka-Migration для:
- Проверки условий миграции. Например, перед выполнением любых вызовов перемещения реплик ею проверяется, в работоспособном ли состоянии кластер и находятся ли цель и конечный брокер в одной зоне доступности.
- Полнофункциональных режимов миграции. В системе имеются различные режимы миграции: в режиме конкретных брокеров данные перемещаются от конкретного набора брокеров к другому; в режиме зон доступности перемещение данных от имеющихся брокеров к целевым в пределах одной зоны доступности упрощается; в режиме полной миграции контролируется полное перемещением данных в новый набор брокеров, обеспечивается корректное присвоение реплик, оркестрируется перемещение в каждой зоне доступности. С установкой этих режимов и правил системой гарантируется перемещение реплики в безопасной и управляемой области. В итоге последствия минимизируются, а реакция на любые инциденты во время перемещения быстрая.
- Детализированного контроля миграции. Кроме однонаправленной миграции, поддерживаются операции остановки, возобновления и отмены. Например, во время неожиданного всплеска, чтобы увеличить пропускную способность рабочего трафика, миграцию останавливают, а после затухания — возобновляют.
Показатели и мониторинг
Сбор показателей и создание инструментов важны для выявления проблем и понимания функционирования кластера во время миграции. Имеется три различных источника показателей, собираемых для Kafka: JMX-метрики брокера Kafka, метрики системного уровня брокера, метрики AWS EBS.
Метрики JMX и EBS в целом согласованы между EC2 и K8s, поэтому во время миграции остаются практически неизменными. Различаются они лишь тегами для метрик брокеров EC2 и K8s. Повторно сопоставить эти теги с имеющейся системой мониторинга несложно.
Метрики системного уровня брокера поинтереснее, ведь EC2 — это виртуальная машина, а под K8s — группа контейнеров. Метрики виртуальных машин иногда не обнаруживаются в контейнерных метриках. Так, у показателя средней нагрузки, которым измеряется рабочая нагрузка на центральный процессор хоста с течением времени и указывается, насколько загружена система, нет прямого эквивалента на уровне контейнеров. Пожалуй, ближайший аналог — показатель регулируемой частоты процессора, но это не совсем то же.
Оптимальнее для выявления проблем высокоуровневые метрики. Скажем, JMX-метриками брокера Kafka неплохо указывается на проблему исчерпания ресурсов: задержка отправителя, емкость сетевого пула, емкость обработчика запросов, задержка репликации.
Контроль за перебоями в работе брокера
Наконец, во время миграции нужно тщательно контролировать перебои в работе брокера, то есть любые проблемы или события, из-за которых он функционирует некорректно или становится недоступным. Различают перебои непроизвольные, например из-за аппаратного сбоя, и произвольные, например из-за перезапуска брокеров без остановки.
Плохой контроль за перебоями чреват низкой доступностью
Для кластера Kafka, состоящего из брокеров трех зон доступности, где большинство тем настроены с тремя репликами и минимум двумя синхронизированными репликами, потеря брокеров в одной зоне доступности приемлема. А вот потеря двух брокеров из двух разных зон доступности чревата проблемами «отключенных разделов», так как минимальное количество синхронизированных реплик ― две:
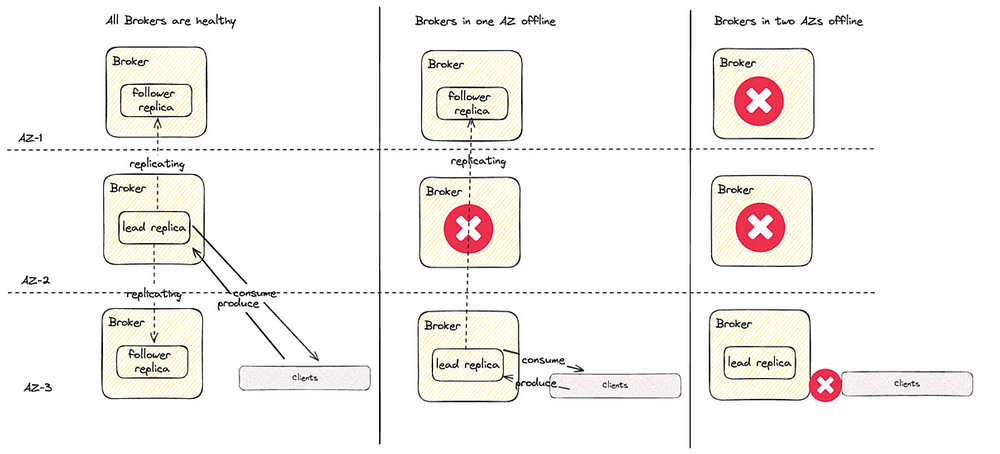
Нужно создать систему для максимально возможного предотвращения этого сценария. Непроизвольные перебои неизбежны, а значит, нужно предотвратить произвольные, которые случаются во время инцидента с непроизвольным перебоем.
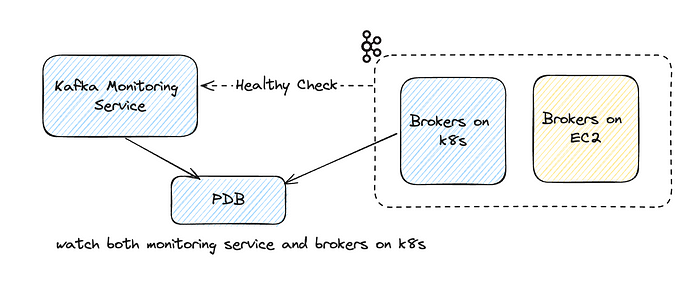
Бюджет перебоев в работе подов со службой мониторинга Kafka
Чтобы отслеживать разворачиваемые в K8s поды брокеров, создан бюджет перебоев в работе подов на K8s. После обнаружения отключенного брокера бюджетом перебоев подов, чтобы предотвратить вытеснение других брокеров в K8s, бюджет перебоев нарушается.
Однако в экземплярах EC2 для бюджета перебоев нет нативного способа определения состояния брокеров. Поэтому, чтобы включить в область мониторинга состояние брокеров на EC2, мы настроили дополнительную службу мониторинга Kafka. Ею проверяется наличие недореплицированных разделов, и так отслеживается общая работоспособность кластера Kafka. Если такие разделы обнаружены, служба переводится в состояние неготовности.
Бюджет перебоев подов настраивается для мониторинга службы Kafka Monitoring Service и разворачиваемых в K8s брокеров. Им обнаруживаются отключенные брокеры K8s и EC2, первые ― непосредственным отслеживанием подов брокеров, вторые ― через службу мониторинга Kafka.
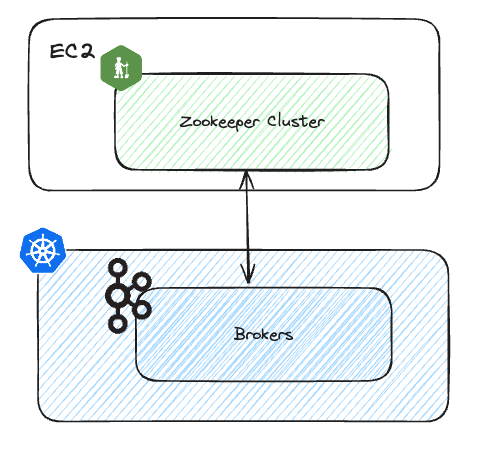
Миграция Zookeeper
Мы перенесли брокеры Kafka из экземпляров EC2 в K8s. Однако кластер Zookeeper по-прежнему запускается в экземплярах EC2.
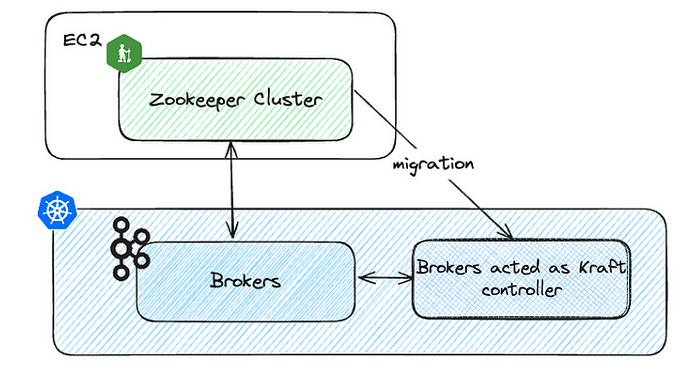
Конечно, кластер Zookeeper переносится аналогично брокерам Kafka. Но имеется и другой способ. В Kafka версии 3.6 наконец стал общедоступным Kraft, с помощью которого Zookeeper заменяется брокерами с ролью контроллера. Брокеры уже запускаются в K8s, поэтому с ролью контроллера легко настроить новый набор брокеров.
Заключение
Применив стратегию миграции на уровне брокеров в объединенном кластере Kafka, мы перенесли все кластеры Kafka на K8s. С точки зрения клиентов, этот процесс абсолютно плавный и без инцидентов, вызванных миграцией.
Управлять Kafka в K8s намного проще, чем на EC2, благодаря надежной, масштабируемой, гибкой платформе K8s, на которой автоматизируются многие рабочие задачи: от развертывания до мониторинга, масштабирования и самовосстановления. Благодаря четко определенным объектам K8s и определениям специальных ресурсов, на основе Kafka создаются операторы для дальнейшей автоматизации рабочих задач.
С усовершенствованной автоматизацией и уменьшенными накладными расходами работа команды в экосистеме Kafka ускоряется, время разработки высвобождается на новые задачи.
Читайте также:
- Секрет производительности Kafka
- Spring Boot, Kafka и WebSocket для отправки сообщений в реальном времени
- Как создать свой Twitter или управляемое данными приложение с Golang и Kafka
Читайте нас в Telegram, VK и Дзен
Перевод статьи Frankie: Seamless Transition: Migrating Kafka Cluster to Kubernetes





