
Подробно расскажем о фундаментальных столпах языка JavaScript и его движков, таких как интерпретация, JIT-компиляция, ссылки, стек, куча, управление памятью и сборка мусора.
Прежде чем приступить к рассмотрению этих тем, разберемся с важными понятиями, знание которых поможет глубже погрузиться в мир JavaScript и других языков.
Типы языков программирования
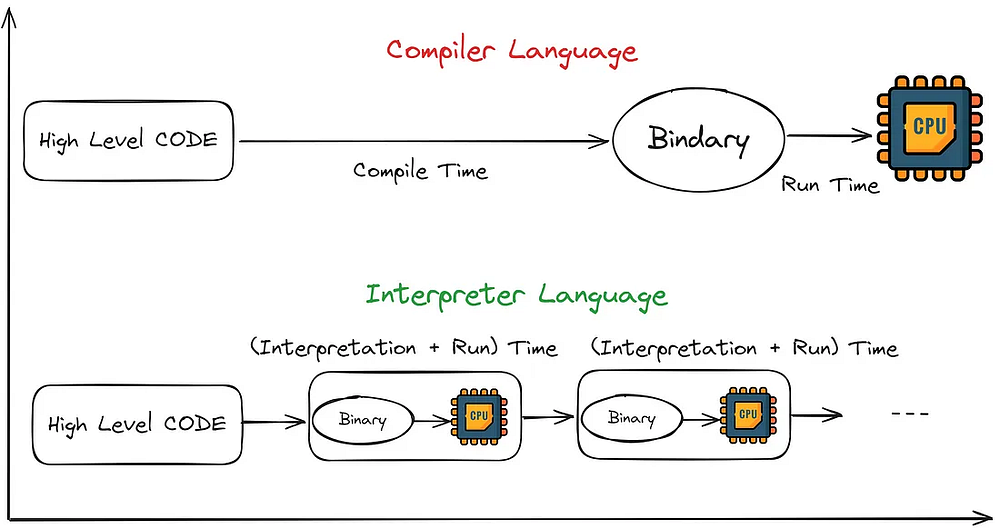
Существует два распространенных типа языков программирования: компилируемый и интерпретируемый. Но когда речь идет о JavaScript, все оказывается не так просто. JavaScript использует смешанный способ работы с кодом — что-то среднее между интерпретацией и компиляцией, о чем мы поговорим чуть ниже.
Компиляция и интерпретация
Процесс перевода высокоуровневого кода, написанного программистом, в исполняемый набор двоичных инструкций, понятный процессору компьютера, называется компиляцией. Это довольно сложный и долгий процесс. В результате получаем двоичный код.
Процесс перевода написанного программистом высокоуровневого кода в исполняемый набор двоичных инструкций, которые процессор компьютера может понимать построчно в процессе выполнения, называется интерпретацией. Он относительно быстрее, поскольку объем компилируемого кода меньше, но из-за дополнительного времени, затрачиваемого на компиляцию, он выполняется медленнее по сравнению с компилируемыми языками.
Движки JavaScript
JavaScript — это скриптовый язык программирования, отвечающий за преобразование кода, который мы пишем в формате текстовых сценариев, в двоичный исполняемый набор инструкций для процессора компьютера.
JavaScript имеет несколько движков, разработанных технологическими компаниями-гигантами и интегрированных в современные браузеры:
- V8 от компании Google.
- SpiderMonkey от Mozilla Firefox.
- JavaScriptCore: разработан компанией Apple для Safari.
- Rhino: разработан и написан на Java компанией Mozilla Foundation.
- Chakra: разработан Microsoft и используется в Edge.
- JerryScript: движок JavaScript для IoT (Интернета вещей).
JavaScript не является интерпретируемым или компилируемым языком. Он совмещает в себе интерпретацию и компиляцию благодаря компилятору Just-In-Time (или JIT), который используется “под капотом”.
Компиляторы JavaScript Just-in-Time (JIT) работают путем динамической компиляции кода JavaScript во время выполнения в нативный машинный код, что позволяет ему выполняться быстрее, чем интерпретируемый код. Общая идея заключается в том, чтобы компилировать код, который выполняется часто или требует много времени для выполнения.
Ниже перечислены этапы работы движка JavaScript с использованием JIT-компилятора:
- Парсинг. Когда новый фрагмент кода попадает в движок JavaScript, первым шагом является парсинг кода в структуру данных, называемую абстрактным синтаксическим деревом (AST).
- Профилирование. Далее JIT-компилятор определяет участки кода, которые выполняются чаще всего. Они подлежат оптимизации.
- Оптимизация. JIT-компилятор применяет различные методы оптимизации к часто выполняемому коду, такие как встраивание функций, удаление избыточного кода и генерация специализированного машинного кода.
- Генерация кода. После завершения процесса оптимизации JIT-компилятор генерирует двоичный код, который может быть выполнен непосредственно центральным процессором.
- Выполнение. Наконец, оптимизированный двоичный код быстро и эффективно выполняется центральным процессором.
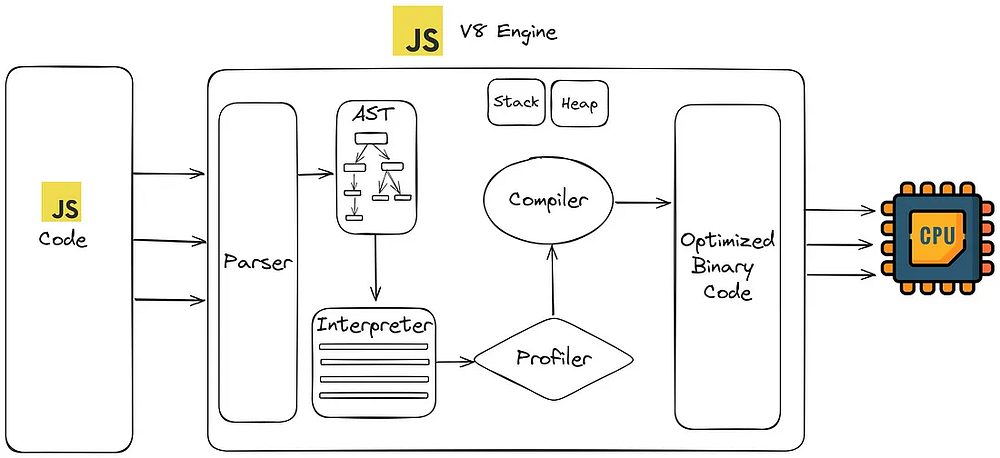
Все эти процессы парсинга, компиляции и оптимизации происходят в специальных потоках внутри движка, к которому нельзя получить доступ из кода, то есть отдельно от основного потока, который осуществляется в стеке вызовов, выполняя код. В разных движках этот механизм реализован по-разному, но в общих чертах современная компиляция Just-in-time для JavaScript выглядит именно так.
Структуры данных JavaScript
Мы уже многое обсудили, поговорили о компилируемых и интерпретируемых языках, о том, как устроен язык JavaScript, почему он называется JIT-компилируемым и как он работает. Теперь пришло время перейти к основной теме. Для тех, кто уже знаком с JavaScript, и для тех, кто только начинает это знакомство, я расскажу о структурах данных JavaScript и типах данных.
Как вы все, наверное, знаете, JavaScript — это динамический язык с динамическими типами. Это слабо типизированный язык, потому что он допускает преобразование типов (coercion) при выполнении операций. Он позволяет преобразовывать типы данных, если они не сопоставимы, а не выбрасывать ошибки. Когда мы выделяем данные для переменных, мы в явном виде не указываем языку типы данных, которые собираемся использовать для конкретной переменной; она также может быть изменена во время создания кода и выполнения в зависимости от того, как она объявлена.
Как правило, в JavaScript различают две структуры данных:
- Примитивные типы (Value).
- Ссылочные типы (Object).
К примитивным типам относятся:
- Null.
- Undefined.
- Булево значение.
- Строка.
- Число.
- Символ.
- BigInt.
Ссылочные типы охватывают все, что не относится к примитивным типам, например объекты, функции и массивы, и их также называют объектами. Ссылочными типами они называются потому, что на них может ссылаться идентификатор в памяти, и когда мы изменяем их, мы изменяем ссылку в памяти.
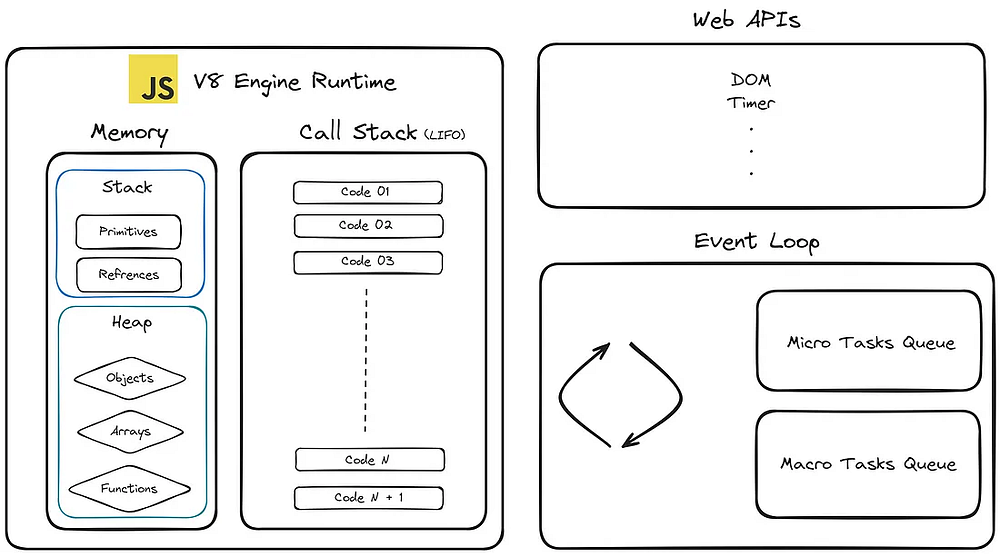
При этом управление памятью в движке JavaScript опирается на два компонента, которые называются Heap (куча) и Stack (стек). Дадим им определения и посмотрим, каковы их обязанности и задачи.
- Стек (распределитель статической памяти)
Стек — это структура данных, которую движок JavaScript использует “под капотом” для хранения статических данных. Статические данные — это данные, размер которых движок JavaScript знает во время компиляции. В JavaScript это примитивные значения и ссылки, которые являются идентификаторами объектов в памяти. В стек помещаются фреймы стека, размер которых фиксирован и изменить его невозможно.
- Куча (распределитель динамической памяти)
Куча — это другое пространство памяти для хранения данных. Здесь JavaScript хранит объекты в памяти компьютера. В отличие от стека, движок не выделяет фиксированный объем памяти под эти объекты. Вместо этого по мере необходимости просто будет выделяться больше места.
Важное замечание по стеку вызовов и стеку: стек вызовов отличается от стека (или стека потока). Стек вызовов и стек потока — это структуры данных, но их назначение и принцип работы отличаются.
Стек вызовов в JavaScript — это механизм, используемый для отслеживания вызовов функций в программе. Каждый раз, когда в JavaScript вызывается функция, создается новый фрейм, который помещается в стек вызовов. Этот фрейм содержит аргументы и локальные переменные функции.
Стек вызовов представляет собой структуру данных типа Last In, First Out (LIFO). Таким образом, первым удаляется последний добавленный фрейм. Когда функция завершает выполнение, ее фрейм “сбрасывается” с вершины стека, и выполнение программы возобновляется с предыдущей точки стека.
Важное замечание (передача по значению и передача по ссылке): когда мы передаем примитивные значения в функции или присваиваем их другим переменным, движок JavaScript копирует значение и передает его новой переменной. Поэтому мы и называем этот механизм pass-by-value (передача по значению). Однако когда мы присваиваем ранее созданный объект новой переменной, он передается по ссылке; при этом ссылка не копируется, так как иначе потребуется огромное количество памяти, что плохо скажется на эффективности.
Вот хороший пример для понимания описанного:
// Первый пример
const num1 = 1;
const num2 = num1; // Передано по значению (скопировано)
const num3 = 1;
console.log(num1 === num2); // true
console.log(num3 === num1); // true
console.log(num3 === num2); // true
// Второй пример
const obj1 = {age: 30};
const obj2 = {age: 30 };
console.log(obj1 === obj2); // false (указывает на другое распределение памяти)
// Третий пример
const obj3 = {name: "max"};
const obj4 = obj3; // Передано по ссылке (указывает на то же распределение памяти)
console.log(obj3 === obj4); // true
Здесь представлен фрагмент кода и соответствующая схема. Ниже я объясню, как происходит выделение памяти и выполнение кода.
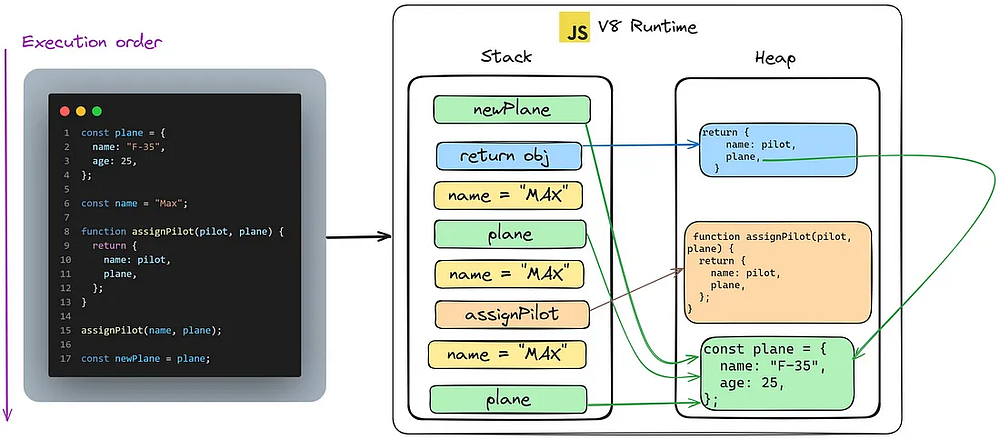
Как мы уже говорили, JavaScript выполняет и компилирует код построчно, поскольку соединяет в себе черты как интерпретируемого, так и компилируемого языка. Когда основной поток достигнет константы plane (plane — это объект), куча выделит ему область памяти, и plane будет в стеке ссылаться на эту область памяти в куче. Однако name = «max» — это примитивный тип (строка), поэтому он имеет фиксированный размер данных; место ему будет выделено в памяти самим стеком. Так будет продолжаться и дальше, и когда мы переназначим plane для новой plane, новое распределение памяти не создастся; вместо этого ссылка будет вести на пространство памяти, созданное раньше.
Это очень важно знать, потому что при работе в JavaScipt с объектами или в более современных фреймворках и библиотеках, таких как Next.js и React.js, нужно помнить о мутабельности и ссылках, поскольку мы часто будем иметь дело с состояниями, свойствами, оптимизацией рендеринга и сравнением данных. В конце концов, в React все сравнивается с помощью Object.is, что, в свою очередь, предусматривает проверку ссылки в памяти. Помните: когда мы хотим изменить состояние, нам нужно создать новую ссылку в куче памяти, чтобы заставить наблюдателя React/любой другой библиотеки/фреймворка или инструмент быть в курсе изменений. Нужно обратить внимание на неизменяемость значений ссылок.
type Props = {
plane: {
name: string;
age: number;
}
}
function ShowPlane({plane}: Props){
return (
<div>
<h1>{plane.name}</h1>
<p>{plane.age}<p>
</div>
);
}
Возьмем приведенный выше компонент React. Если мы передадим объект plane компоненту ShowPlane от родителя, то при каждом повторном рендеринге родителя будет происходить новое выполнение функции и в результате будет создан новый объект plane. Поэтому распределение памяти для объекта plane в куче будет изменено и ShowPlane будет повторно отображен независимо от наличия совершенно одинакового компонента и свойств в плане значений данных. Так что в версиях React 18 и ниже нужно их передавать в память.
Клонирование (глубокое и поверхностное копирование)
В JavaScript существует два способа копирования объектов: поверхностное и глубокое. При поверхностном копировании создается новый объект со ссылками на те же области памяти, что и у исходного объекта. При глубоком копировании образуется новый объект с новыми областями памяти для всех его свойств и вложенных объектов или массивов.
Такие методы, как map, slice, filter, spread operator, Object. assign и т. д., создают поверхностную копию исходного объекта, а методы типа JSON.parse(JSON.stringy()) и structureClone создают глубокую копию в памяти из исходного объекта.
Если исходный объект глубоко вложен в другие объекты, перечисленные методы создадут поверхностную копию, как и оператор rest, так что имейте это в виду, чтобы не допускать ошибок!
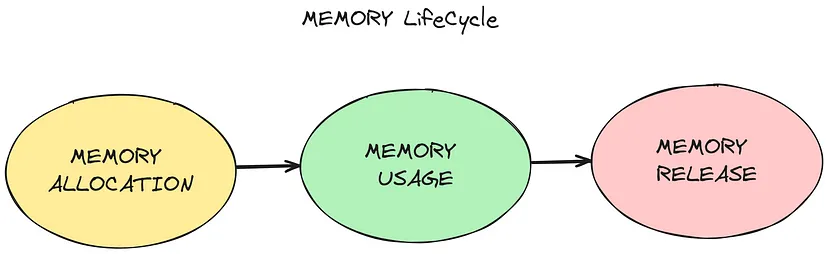
Жизненный цикл памяти
Независимо от языка программирования, жизненный цикл памяти практически всегда одинаков:
- Выделение необходимой памяти.
- Использование выделенной памяти (чтение, запись).
- Освобождение выделенной памяти, когда она больше не нужна.
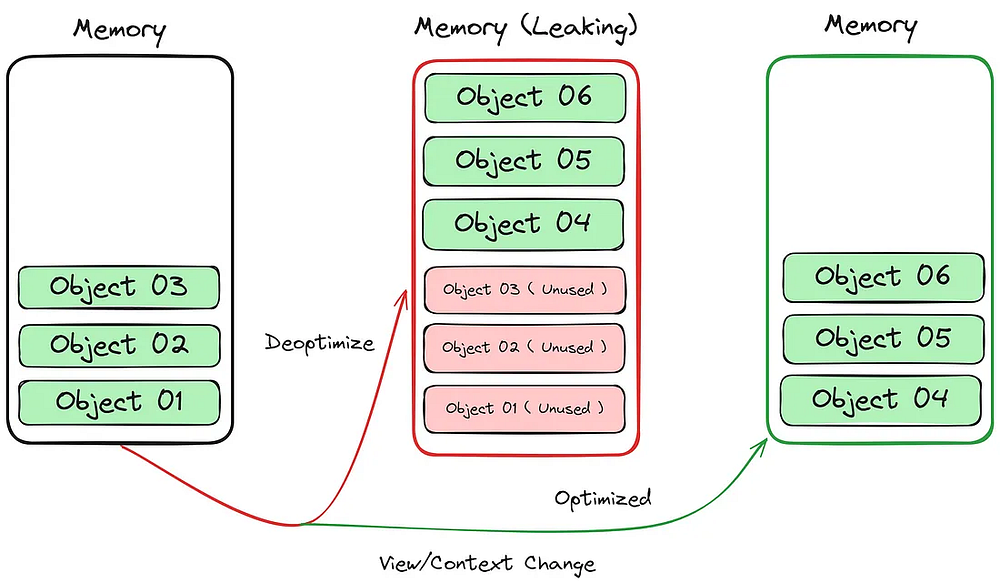
Утечка памяти
Важно помнить, что память — это ограниченный ресурс. В JavaScript память хранится в двух местах: стеке вызовов и куче памяти. Учитывая факт ограниченного доступа к этим ресурсам, очень важно писать эффективный код, который может предотвратить такие проблемы, как переполнение стека или утечка памяти, а также эффективно управлять использованием памяти.
Утечка памяти происходит в JavaScript, когда программа продолжает выделять память, не освобождая ее. В таком случае уменьшается количество доступной памяти в системе, что в конечном итоге может привести к аварийному завершению работы программы.
Перечислим распространенные причины утечек памяти в JavaScript и способы их предотвращения.
- Забытые слушатели событий. Когда к элементу прикрепляется слушатель событий, функция слушателя остается в памяти до тех пор, пока она не будет удалена в явном виде. Если элемент с прикрепленным слушателем событий удаляется из DOM, но сам слушатель не удаляется, это может привести к утечке памяти. Чтобы избежать такой проблемы, всегда удаляйте слушатели событий, когда они больше не нужны.
- Замыкания. Замыкания — мощная функция JavaScript, которая также может вызывать утечки памяти. Когда функция создает замыкание, все переменные внешней функции, которые используются во внутренней функции, остаются в памяти до тех пор, пока замыкание не будет освобождено. Во избежание такой проблемы не создавайте лишних замыканий и обязательно освобождайте замыкания, когда они больше не нужны.
- Большие структуры данных. Большие структуры данных, такие как массивы или объекты, могут занимать много памяти, если ими не управлять должным образом. Чтобы не допустить утечек, освобождайте ссылки на большие структуры данных, когда они больше не нужны.
- Забытые таймеры или обратные вызовы. Если setTimeout или setInterval ссылаются на некоторый объект в обратном вызове, это чаще всего приводит к предотвращению сборки объекта в мусор. Если в коде мы установим повторяющийся таймер, то ссылка на объект из обратного вызова таймера будет активна до тех пор, пока этот обратный вызов будет доступен.
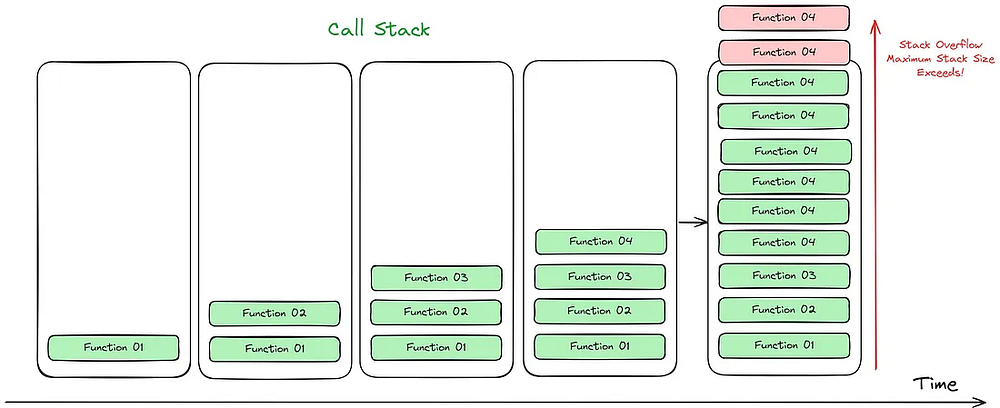
Переполнение стека
Переполнение стека происходит в JavaScript в случае превышения максимального размера стека. Стек вызовов — это структура данных, используемая в JavaScript для отслеживания вызовов функций. Каждый раз, когда вызывается функция, в верхнюю часть стека вызовов добавляется новая запись. Когда функция завершает свою работу, ее запись удаляется из верхней части стека вызовов.
Если функция вызывает сама себя (рекурсивная функция) или если цепочка вызовов функции становится слишком длинной, стек вызовов может переполниться. Это происходит в случае бесконечного цикла или тогда, когда функция вызывает сама себя слишком много раз.
Чтобы предотвратить переполнение стека в JavaScript, выполняйте следующие рекомендации:
- Избегайте бесконечных циклов. Код не должен застревать в бесконечном цикле.
- Используйте хвостовую рекурсию. Если без рекурсии не обойтись, используйте хвостовую рекурсию. Эта техника позволяет движку JavaScript оптимизировать код и предотвращать переполнение стека.
- Увеличивайте размер стека. Некоторые движки JavaScript позволяют увеличивать максимальный размер стека вызовов. Однако делать это не рекомендуется, так как вы можете столкнуться с другими проблемами, связанными с производительностью.
- Выполняйте рефакторинг кода. Переполненный стек может быть признаком того, что код нуждается в рефакторинге. Рассмотрите возможность разбиения больших функций на более мелкие, оптимизируйте код и удалите ненужные рекурсивные вызовы.
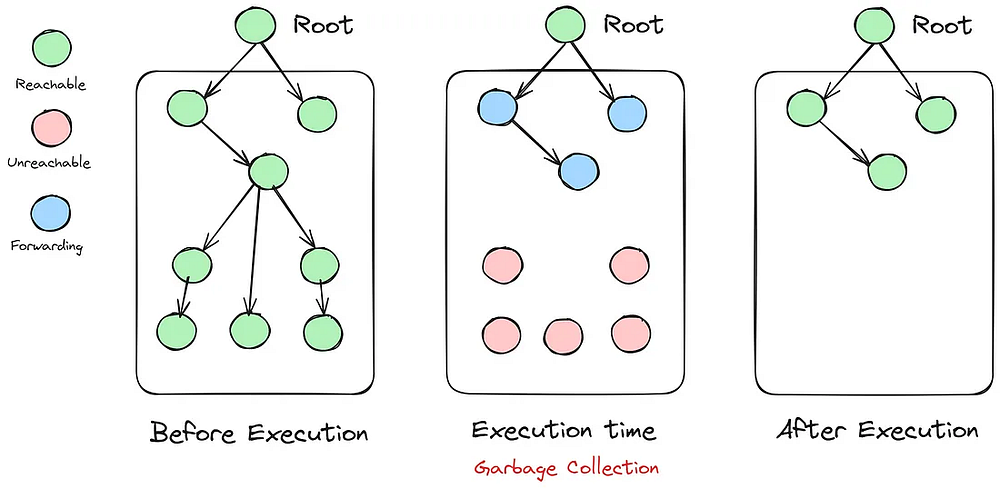
Сборка мусора
Сборка мусора в JavaScript — это автоматический процесс освобождения памяти, которая больше не используется приложением. JavaScript обладает встроенным сборщиком мусора, который управляет памятью автоматически. Таким образом, разработчикам не нужно беспокоиться о ручном управлении памятью, как в других языках программирования, таких как C и C++.

Для управления памятью используются различные алгоритмы, включая mark-and-sweep, подсчет ссылок и сбор по поколениям. Наиболее же распространенным алгоритмом для современных браузеров является mark-and-sweep.
Алгоритм mark-and-sweep начинает работу с набора корневых (root) объектов, таких как глобальные переменные или объекты в текущем стеке выполнения. Затем сборщик мусора обходит граф объектов, помечая объекты, доступные из корневых объектов. Объекты, которые не помечены как доступные, считаются мусором и могут быть удалены.
Заключение
Надеюсь, что помог вам узнать больше о движке JavaScript и о том, как он работает “под капотом”. Все, что мы обсудили здесь — это лишь общая и упрощенная картина внутренних механизмов JavaScript. Конечно, есть много чего еще по этой теме, стоит только углубиться в детали. Однако я думаю, что приведенных знаний достаточно для пользователей JavaScript, которые хотят создавать интересные и масштабируемые программы на JavaScript. Если же вы хотите больше узнать о создании среды выполнения для JavaScript (например, Bun.js), тогда вам, вероятно, стоит глубже погрузиться в эту тему.
Читайте также:
- 18 советов по созданию чистого и эффективного кода JavaScript
- Менеджеры пакетов NPM, PNPM и YARN
- 7 полезных методов объектов JavaScript
Читайте нас в Telegram, VK и Дзен
Перевод статьи Max Shahdoost: JavaScript Engine, JIT compiler, Stack, Heap, Memory, Primitives, References, and Garbage Collection





