
Сейчас в каждом приложении лента с содержимым персонализируется в зависимости от интересов пользователя. Например, введите что-либо в поиске YouTube, и за минуты временна́я шкала заполнится видео, релевантными вашему запросу. Создадим подобное приложение — простую реплику Twitter с временно́й шкалой для каждого пользователя. Исходя из взаимодействия с твитами, определим предпочтения пользователей, чтобы показать им еще больше твитов.
Создание простого Twitter
Сначала необходимо сделать простой Twitter, твиты будем сохранять не в БД постоянного хранения, а в экземпляре Redis:
type Redis[T models.Keyer] struct {
rdb *redis.Client
}
func NewRedis[T models.Keyer](rdb *redis.Client) Redis[T] {
r := Redis[T]{rdb: rdb}
return r
}
func (r Redis[T]) Save(ctx context.Context, k T) error {
b, _ := json.Marshal(k)
return r.rdb.Set(ctx, k.Key(), b, 0).Err()
}
func (r Redis[T]) Get(ctx context.Context, key string) (T, error) {
var t T
b, err := r.rdb.Get(ctx, key).Bytes()
if err != nil {
return t, err
}
json.Unmarshal(b, &t)
return t, nil
}
Для облегчения сериализации мы создали простую обертку Redis, которой применяются дженерики Golang, и определили новый интерфейс Keyer:
type Keyer interface {
Key() string
}
type Tweet struct {
UID string `json:"UID"`
Author string `json:"author"`
Tweet string `json:"tweet"`
}
func (t Tweet) Key() string {
return "tweet:" + t.UID
}
Использована простая реализация, и даже без аутентификации и авторизации: фокус на Kafka и Redis.
Применяя обыкновенный HTTP-маршрутизатор, запускаем простейшую реплику Twitter:
func main() {
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
})
tweetService := services.NewSaveTweet(repositories.NewRedis[models.Tweet](rdb))
e := echo.New()
e.POST("/tweet", func(c echo.Context) error {
content := c.Request().PostFormValue("tweet")
author := c.Request().PostFormValue("author")
tweet := models.Tweet{Tweet: content, Author: author}
tweet, err := tweetService.Save(c.Request().Context(), tweet)
if err != nil {
return c.String(500, err.Error())
}
return c.String(201, tweet.UID)
})
e.GET("/tweet/:uid", func(c echo.Context) error {
uid := c.Param("uid")
tweet, err := tweetService.Get(c.Request().Context(), uid)
if errors.Is(err, redis.Nil) {
return c.String(404, "tweet not found")
} else if err != nil {
return c.String(500, err.Error())
}
return c.String(200, tweet.Author+" : "+tweet.Tweet)
})
e.Logger.Fatal(e.Start(":1323"))
}
Протестируем ее:
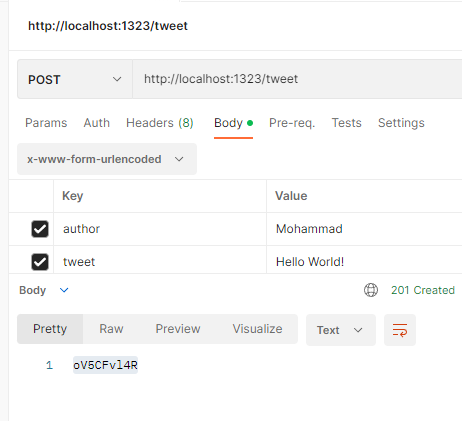
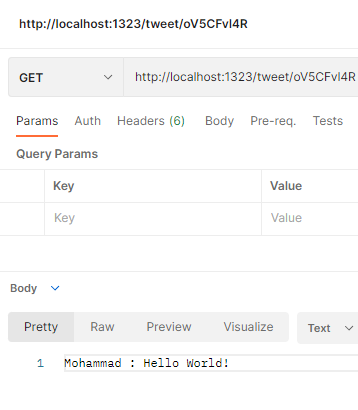
Работа корректная, но упущен важнейший аспект Twitter: временна́я шкала.
Возьмем сервис подписчиков, которым сохраняются отношения между пользователями. Вот простая заглушка:
type Follower struct {
followers map[string][]string
}
func NewFollower() Follower {
return Follower{
followers: map[string][]string{
"mohammad": []string{"john", "maria", "hanna"},
"john": []string{"hanna"},
},
}
}
func (f Follower) Followers(ctx context.Context, user string) ([]string, error) {
return f.followers[user], nil
}
Все захардкодено, эти отношения сохраняются в любой БД.
Для временно́й шкалы используем список в Redis, где у каждого пользователя имеется ключ timeline:uid, то есть список идентификаторов твитов:
type Timeline struct {
rdb *redis.Client
}
func NewTimeline(rdb *redis.Client) Timeline {
return Timeline{rdb: rdb}
}
func (t Timeline) Push(ctx context.Context, user string, tweet ...interface{}) error {
return t.rdb.RPush(ctx, "timeline:"+user, tweet...).Err()
}
func (t Timeline) Latest(ctx context.Context, user string, count int64) ([]string, error) {
return t.rdb.LRange(ctx, "timeline:"+user, -1*count, -1).Result()
}
Заполнение временно́й шкалы: наивный подход
Самый наивный подход для заполнения временно́й шкалы — добавление твитов во временну́ю шкалу каждого подписчика. Вот код:
timelineService := services.NewTimeline(rdb)
followerService := services.NewFollower()
tweetService := services.NewSaveTweet(repositories.NewRedis[models.Tweet](rdb))
...
e.POST("/tweet", func(c echo.Context) error {
ctx := c.Request().Context()
content := c.Request().PostFormValue("tweet")
author := c.Request().PostFormValue("author")
tweet := models.Tweet{Tweet: content, Author: author}
tweet, err := tweetService.Save(ctx, tweet)
// добавление твита во временну́ю шкалу подписчиков.
followers, _ := followerService.Followers(ctx, author)
for _, follower := range followers {
if err := timelineService.Push(ctx, follower, tweet.UID); err != nil {
return c.String(500, err.Error())
}
}
if err != nil {
return c.String(500, err.Error())
}
return c.String(201, tweet.UID)
})
А вот простой маршрут для получения временно́й шкалы:
e.GET("/timeline/:user", func(c echo.Context) error {
ctx := c.Request().Context()
user := c.Param("user")
tweetIDs, err := timelineService.Latest(ctx, user, 10)
if errors.Is(err, redis.Nil) {
return c.String(404, "timeline not found")
} else if err != nil {
return c.String(500, err.Error())
}
tweets, err := tweetService.MGet(ctx, tweetIDs...)
if err != nil {
return c.String(500, err.Error())
}
timeline := ""
for i := len(tweets) - 1; i >= 0; i-- {
tweet := tweets[i]
timeline += fmt.Sprintf("%s: %s\n________________\n", tweet.Author, tweet.Tweet)
}
return c.String(200, timeline)
})
В обертку Redis и tweetService добавлена поддержка MGet:
func (r Redis[T]) MGet(ctx context.Context, key ...string) ([]T, error) {
bb, err := r.rdb.MGet(ctx, key...).Result()
if err != nil {
return nil, err
}
result := make([]T, len(key))
for i, b := range bb {
json.Unmarshal([]byte(b.(string)), &result[i])
}
return result, nil
}
func (st SaveTweet) MGet(ctx context.Context, uid ...string) ([]models.Tweet, error) {
ids := make([]string, len(uid))
for i, s := range uid {
ids[i] = "tweet:" + s
}
return st.r.MGet(ctx, ids...)
}
Что такое MGet? Используя новейший метод сервиса временно́й шкалы, вместо содержимого твита мы получаем идентификаторы. С MGet все эти твиты извлекаются одним запросом, что серьезно сказывается на производительности приложения.
Протестируем его:
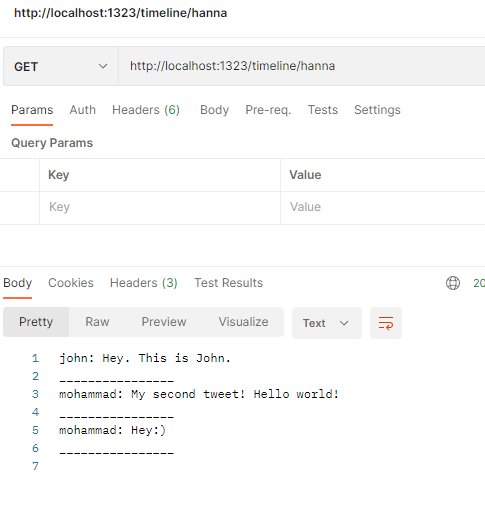
Пока работа корректная. У @Cristiano 100 млн подписчиков в Twitter. Что бы случилось, воспользуйся он нашей платформой для твитов? Аварийное завершение ее работы. Но почему и как?
- Извлечение всех 100 млн подписчиков существенно скажется на базе данных.
- Цикл
forдля 100 млн элементов чреват длительным прерыванием работы системы. - Что бы случилось после добавления твита в 53 млн временны́х шкал и аварийного завершения системы? Как продолжить этот процесс?
Увеличим число подписчиков и посмотрим, как это скажется на системе:
- Для трех подписчиков требуется 2,9 мс.
- Для 100 — 83,7 мс.
- Для 1000 — 809,6603 мс.
- Для 10 000 — 6,3 мс.
Соответственно, для 100 млн потребуется примерно 22 часа. Основная проблема заключается в том, что вместо конвейера в Redis отправляются отдельные запросы. Но вряд ли CR7 будет ждать 10 минут, пока мы распространяем твит среди его подписчиков. Эта система не масштабируется, у нее нет защиты от ошибок. Имеется лишь один узел, и для отказоустойчивости это опасно.
Введем в приложение Kafka
Сейчас структура приложения такова:
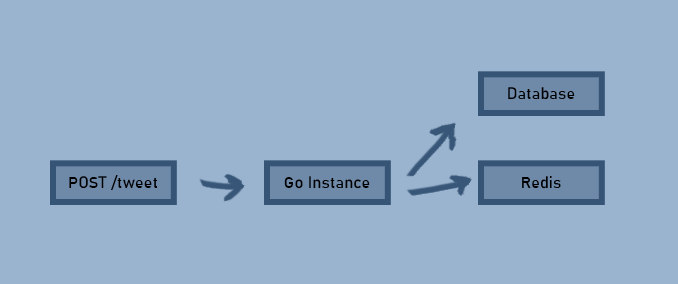
Все в этой системе взаимосвязано. Что, если добавить службу машинного обучения для выполнения алгоритма по выявлению предпочтений пользователей?
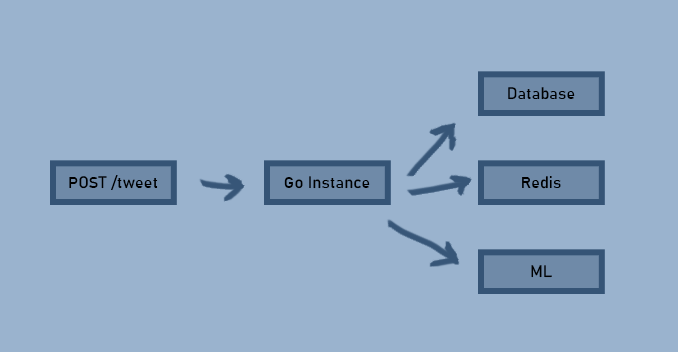
Казалось бы, ничего сложного. Сложности появляются при масштабировании. Допустим, у нас стало в пять раз больше пользователей и нужно масштабировать приложение. Вот так:
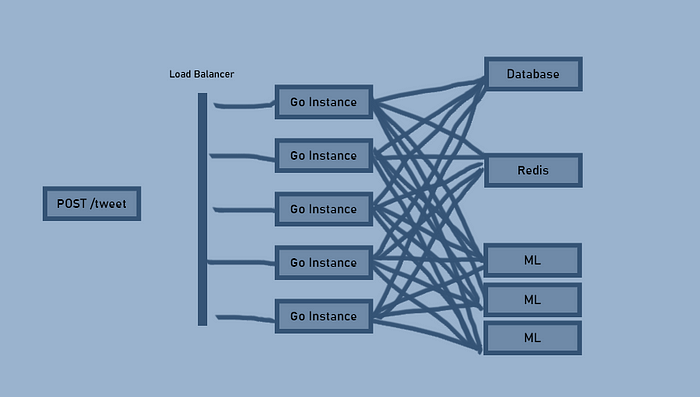
Из-за жирных линий и моего неумения рисовать эти сложности только увеличиваются. Полная неразбериха. О добавлении еще одного ML-алгоритма для какой-либо другой цели не может быть и речи.
С помощью Kafka отделим отправителей от получателей
Каково назначение экземпляра Go? Авторизация, аутентификация, бизнес-логика и валидация. Определяем тему Kafka для новых твитов и пишем другую систему, в которой она получается для сохранения новых твитов в базе данных:
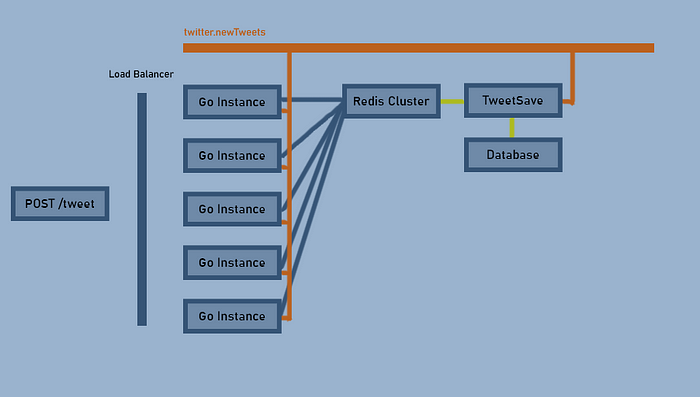
Отправители и получатели не знают друг друга и никак не связаны. Скажете, для этого конкретного примера это максимум? Добавим ML-алгоритмы:
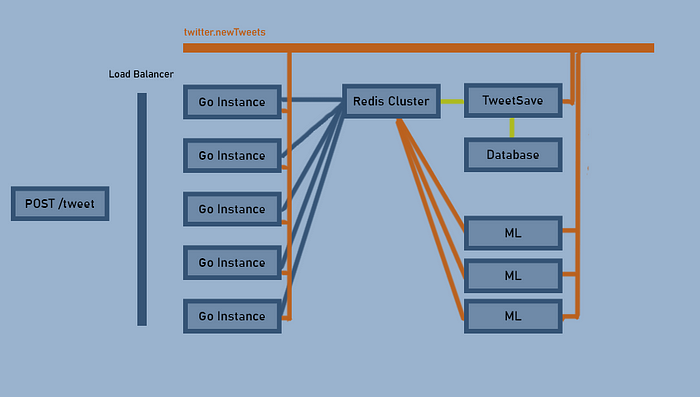
Добавим еще ML-экземпляр для отслеживания соответствия твитов рекомендациям:
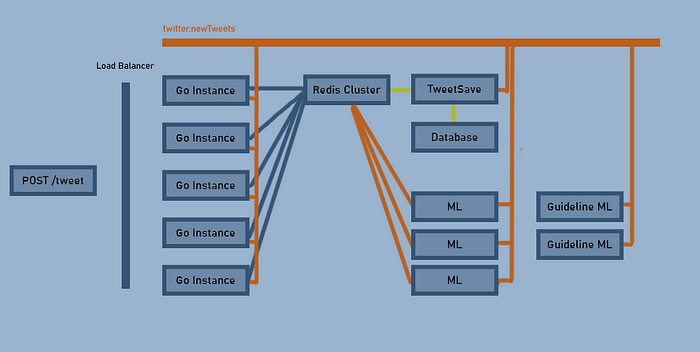
Каждая часть системы легко масштабируется без увеличения сложностей. Добавим последний ML-алгоритм для определения предпочтений пользователей на основе их кликов, для которых создадим новую тему:
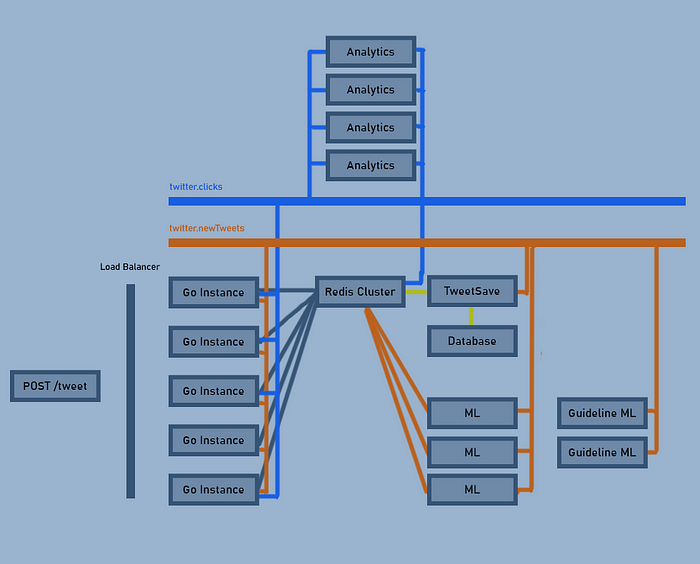
Чтобы показать, насколько проще стало разделять сервисы, специально перемещаем службы аналитики наверх:
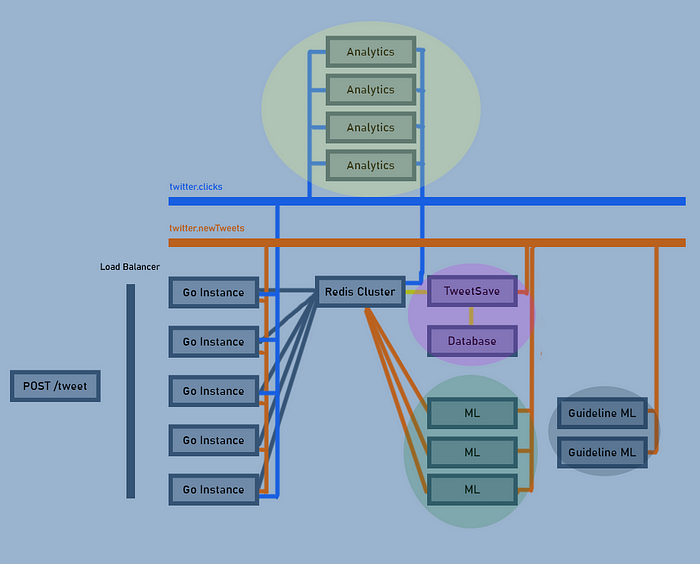
Каждый из этих цветных кружков — отдельная группа получателей, благодаря чему в Kafka возможно эффективное масштабирование.
Создадим тему «NewTweets»
Переходим к Kafka, минуя настройку, с помощью бесплатного сервиса Upstash.
Запускаем Kafka локально с помощью этого файла docker-compose:
version: '3'
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: localhost
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
Затем подключаемся к экземпляру Kafka:
docker exec -it kafka bash
root@da9985351043:/# переходим в каталог /opt/kafka/bin/
root@da9985351043:/opt/kafka/bin# ls
connect-distributed.sh kafka-dump-log.sh kafka-storage.sh
connect-mirror-maker.sh kafka-features.sh kafka-streams-application-reset.sh
connect-standalone.sh kafka-leader-election.sh kafka-topics.sh
kafka-acls.sh kafka-log-dirs.sh kafka-verifiable-consumer.sh
kafka-broker-api-versions.sh kafka-metadata-shell.sh kafka-verifiable-producer.sh
kafka-cluster.sh kafka-mirror-maker.sh trogdor.sh
kafka-configs.sh kafka-preferred-replica-election.sh windows
kafka-console-consumer.sh kafka-producer-perf-test.sh zookeeper-security-migration.sh
kafka-console-producer.sh kafka-reassign-partitions.sh zookeeper-server-start.sh
kafka-consumer-groups.sh kafka-replica-verification.sh zookeeper-server-stop.sh
kafka-consumer-perf-test.sh kafka-run-class.sh zookeeper-shell.sh
kafka-delegation-tokens.sh kafka-server-start.sh
kafka-delete-records.sh kafka-server-stop.sh
В Kafka имеются полезные инструменты для работы с bash, но сейчас нужно создать тему:
kafka-topics.sh --zookeeper zookeeper:2181 --create --topic twitter.newTweets --replication-factor 1 --partitions 10
Что такое ZooKeeper, «коэффициент репликации», «разделы»? Все это основы Kafka, на их описание потребовалась бы целая статья. Вот краткие определения:
- ZooKeeper — приложение для прямого взаимодействия с узлами Kafka, назначения ведущих узлов в кластере, обеспечения их работоспособности. В целом здесь узлы Kafka управляются в распределенной среде.
- Коэффициент репликации: для обеспечения отказоустойчивости в Kafka определяется ведущий узел темы, его данные копируются в числе других узлов. Этим параметром определяется, сколько копий темы нужно.
- Разделы: это посложнее. Раздел — наименьший метод конкурентности. В группе получателей данные одного раздела считываются только одним получателем.
С клиентами Kafka на Go — полная неразбериха. Тем не менее начать можно с простейшей библиотеки github.com/segmentio/kafka-go. В продакшене отлично справляется confluent-kafka-go, но в ней применяется CGo:
package mq
package mq
import (
"context"
"encoding/json"
"github.com/segmentio/kafka-go"
)
type Writer[T any] struct {
w *kafka.Writer
}
func NewWriter[T any](addr, topic string) (Writer[T], func() error) {
w := &kafka.Writer{
Addr: kafka.TCP(addr),
Topic: topic,
Balancer: &kafka.LeastBytes{},
}
return Writer[T]{w: w}, w.Close
}
func (w *Writer[T]) WriteBatch(ctx context.Context, items ...T) error {
messages := make([]kafka.Message, len(items))
for i, item := range items {
b, _ := json.Marshal(item) // использование наивного подхода для сериализации
messages[i] = kafka.Message{
Value: b,
}
}
return w.w.WriteMessages(ctx, messages...)
}
Сначала создали эту простую обертку поверх библиотеки kafka-go, для сериализации использовали наивный подход. В Kafka данные не сериализуются, а просто принимаются байты: большие двоичные объекты, JSON или буферы протокола. Понимание метода сериализации — задача получателя и отправителя. В продакшене предпочтительно отделять это от оберток отправителей и получателей:
e.POST("/tweet", func(c echo.Context) error {
ctx := c.Request().Context()
content := c.Request().PostFormValue("tweet")
author := c.Request().PostFormValue("author")
tweet := models.Tweet{UID: shortid.MustGenerate(), Tweet: content, Author: author}
err := writer.WriteBatch(ctx, tweet)
if err != nil {
return c.String(500, err.Error())
}
return c.String(201, tweet.UID)
})
Идентификатор твита здесь назначили заранее. В распределенной системе, где в приложении передаются миллионы данных, традиционные последовательные идентификаторы несовместимы. Чтобы решить эту проблему, в 2010 году в Twitter анонсировали SnowFlake. Воспользуемся простым генератором идентификаторов пользователя.
Протестируем его, получаем из темы с помощью инструмента kafka-console-consume.sh:
./kafka-console-consumer.sh - bootstrap-server 127.0.0.1:9092 - topic twitter.newTweets
Опубликовав новый твит, получим такое сообщение:
{"UID":"oOjVldlVg","author":"mohammad","tweet":"Hey. This is John."}
Теперь нужна задача для получения твитов из темы newTweets и их сохранения:
package mq
import (
"context"
"encoding/json"
"github.com/segmentio/kafka-go"
)
type Reader[T any] struct {
r *kafka.Reader
onError func(item T)
}
func NewReader[T any](addr, topic, group string, onError func(T)) (Reader[T], func() error) {
r := kafka.NewReader(kafka.ReaderConfig{
Brokers: []string{addr},
GroupID: group,
Topic: topic,
})
return Reader[T]{r: r, onError: onError}, r.Close
}
func (r Reader[T]) Read(handler func(items T) error) error {
for {
message, err := r.r.FetchMessage(context.TODO())
if err != nil {
return err
}
var t T
json.Unmarshal(message.Value, &t)
err = handler(t)
if err != nil {
r.onError(t)
}
r.r.CommitMessages(context.TODO(), message)
}
}
Сначала создали простой ридер с FetchMessage во избежание автофиксаций. Определили поддержку обратного вызова, когда при обработке сообщения в системе появляется ошибка.
Для обработки ошибок создается новая тема или применяются другие подходы. Мы же просто отправляем эти сообщения в тему newTweets повторно:
func main() {
writer, closeWriter := mq.NewWriter[models.Tweet]("127.0.0.1:9092", "twitter.newTweets")
defer closeWriter()
reader, closeReader := mq.NewReader[models.Tweet]("127.0.0.1:9092", "twitter.newTweets", "saver", func(tweet models.Tweet) {
// повторяем процесс
fmt.Println("error, retrying ...")
writer.WriteBatch(context.TODO(), tweet)
})
defer closeReader()
go reader.Read(func(items models.Tweet) error {
fmt.Println("received a message: ", items.Tweet)
if rand.Intn(100) > 50 {
return errors.New("a random error")
}
return nil
})
exit := make(chan os.Signal, 1)
signal.Notify(exit, os.Interrupt, syscall.SIGTERM)
<-exit
fmt.Println("Closing Kafka connections ...")
}
Механизм сохранения пока не реализован. Надо посмотреть на обработку ошибок в действии. Для половины запросов выдается сообщение об ошибке.
Стоит упомянуть о нормальном завершении работы. В Kafka важны получатели. Рабочие они или нет, проверяется по их работоспособности. Ненормальное завершение работы чревато значительной задержкой в теме всякий раз, когда получатель отключается:
received a message for Hello World.
error, retrying ...
received a message for Hello World.
error, retrying ...
received a message for Hello World.
Повторив дважды, мы не получили ошибок, сработано корректно. В Kafka имеется несколько подходов к обработке ошибок получателя, но разбирать их мы не будем.
Сохраняем твиты, поменяв эту строку кода:
go reader.Read(func(items models.Tweet) error {
return tweetSaverService.Save(context.TODO(), items)
})
Помните о задержке. В Kafka ошибки не появляются сразу: имеется задержка между отправкой твита и его сохранением в базе данных и обновлением кеша. ЭТУ ЗАДЕРЖКУ НЕОБХОДИМО ОТСЛЕЖИВАТЬ. Я видел системы для базовой плохой конфигурации с примерно минутными задержками, которые составляли бы менее пяти секунд, будь их разбиение на разделы совершеннее. Чтобы отслеживать эту задержку, добавляем метку времени в сообщения, а по их завершении — время задержки в метрику Prometheus.
Проанализируем твиты
Вторая часть системы — тегирование твитов. Это не хештеги. Помечая твиты тегами, мы «информируем» систему о содержании твита для определения предпочтений пользователей.
Не будем углубляться в машинное обучение. Сначала сгенерируем пять случайных твитов, для их тегирования в ChatGPT определится 50 распространенных тегов:
I want to write a system that tags tweets and understands the users' tastes based on those tags, suggest me 50 tags in snake case format:
1. movie_lovers
2. sports_fans
3. music_lovers
4. fashion_lovers
5. foodies
6. gamers
7. wanderlust
8. tech_savvy
9. bookworms
10. drama_lovers
11. art_lovers
12. finance_fanatics
13. social_media_junkies
14. culture_vultures
15. pet_lovers
16. family_oriented
17. health_enthusiasts
18. history_lovers
19. DIY_crafts
20. photography_fanatics
21. outdoors_adventurers
22. car_lovers
23. green_living
24. nature_lovers
25. fashion_followers
26. culture_aficionados
27. travel_bugs
28. comic_book_buffs
29. eco-friendly
30. cycling_enthusiasts
31. vegan_advocates
32. music_aficionados
33. eco_warriors
34. entrepreneurs
35. movie_buffs
36. adventure_seekers
37. tech_geeks
38. TV_show_lovers
39. fitness_freaks
40. outdoor_enthusiasts
41. gamers_tribe
42. wine_connoisseurs
43. home_decor_lovers
44. sports_enthusiasts
45. social_media_geeks
46. comic_lovers
47. food_fanatics
48. plant_lovers
49. interior_design_lovers
50. nature_aficionados
Затем создадим с этими тегами подсказку:
Select 5 relative tags to the content of this tweet. Only use the provided tags.
Tags: movie_lovers | sports_fans | music_lovers | fashion_lovers | foodies | gamers | wanderlust | tech_savvy | bookworms | drama_lovers | art_lovers | finance_fanatics | social_media_junkies | culture_vultures | pet_lovers | family_oriented | health_enthusiasts | history_lovers | DIY_crafts | photography_fanatics | outdoors_adventurers | car_lovers | green_living | nature_lovers | fashion_followers | culture_aficionados | travel_bugs | comic_book_buffs | eco-friendly | cycling_enthusiasts | vegan_advocates | music_aficionados | eco_warriors | entrepreneurs | movie_buffs | adventure_seekers | tech_geeks | TV_show_lovers | fitness_freaks | outdoor_enthusiasts | gamers_tribe | wine_connoisseurs | home_decor_lovers | sports_enthusiasts | social_media_geeks | comic_lovers | food_fanatics | plant_lovers | interior_design_lovers | nature_aficionados
Tweet: Just finished a new novel. Can't wait to talk about it with my book club #nerdalert
Selected Tags:
Вот результат: «bookworms | drama_lovers | culture_vultures | social_media_junkies | book_club».
func main() {
openaiClient := openai.NewClient("")
reader, closeReader := mq.NewReader[models.Tweet]("127.0.0.1:9092", "twitter.newTweets", "analyzer", func(tweet models.Tweet) {
fmt.Println("error analyzing ", tweet.Tweet)
})
defer closeReader()
go reader.Read(func(items models.Tweet) error {
resp, err := openaiClient.CreateCompletion(
context.Background(),
openai.CompletionRequest{
Model: openai.GPT3TextDavinci003,
Prompt: fmt.Sprintf(`Select 5 relative tags to the content of this tweet. Only use the provided tags.
Tags: movie_lovers | sports_fans | music_lovers | fashion_lovers | foodies | gamers | wanderlust | tech_savvy | bookworms | drama_lovers | art_lovers | finance_fanatics | social_media_junkies | culture_vultures | pet_lovers | family_oriented | health_enthusiasts | history_lovers | DIY_crafts | photography_fanatics | outdoors_adventurers | car_lovers | green_living | nature_lovers | fashion_followers | culture_aficionados | travel_bugs | comic_book_buffs | eco-friendly | cycling_enthusiasts | vegan_advocates | music_aficionados | eco_warriors | entrepreneurs | movie_buffs | adventure_seekers | tech_geeks | TV_show_lovers | fitness_freaks | outdoor_enthusiasts | gamers_tribe | wine_connoisseurs | home_decor_lovers | sports_enthusiasts | social_media_geeks | comic_lovers | food_fanatics | plant_lovers | interior_design_lovers | nature_aficionados
Tweet: %s
Selected Tags:
`, items.Tweet),
},
)
if err != nil {
return err
}
fmt.Println(strings.TrimSpace(resp.Choices[0].Text))
return nil
})
exit := make(chan os.Signal, 1)
signal.Notify(exit, os.Interrupt, syscall.SIGTERM)
<-exit
fmt.Println("Closing Kafka connections ...")
}
Сделали этот новый получатель, группа получателей отличается от предыдущей: нам не нужно одинаковое смещение для saver и analyzer. Предыдущий подход к обработке ошибок несовместим с несколькими группами получателей. Ведь если твит не сохраняется в базе данных, повторно отправляем его в тему. Однако это могло быть проанализированное свойство, и повторно анализировать его не нужно.
Проверим: для твита «Just had an epic chill session with my squad listening to some of our favorite tunes #goodvibesonly» получаем «music_lovers | social_media_junkies | goodvib».
Что дальше?
Сохранить эти теги в задаче или создать новую тему и опубликовать их в ней. Преимущество последнего: если другим командам или службам понадобится этот поток данных, они его используют.
Дальше эта архитектура продолжается созданием новой темы для кликов, данные о кликах и твитах объединяются, осуществляется персонализация.
Заключение
Несмотря на все сложности, в Kafka интересно решать проблемы, применяя новый подход, интересно достичь такого этапа в карьере, когда понимаешь, что традиционные методы больше не актуальны.
Не нужно этого бояться, Kafka не единственный вариант. По моему опыту, работать с RabbitMQ просто, особенно при реализации двух шаблонов: «веерообразное увеличение получателей» и «издатель-подписчик» — и в других случаях, а с Kafka экономится много времени и сил при масштабировании.
Читайте также:
- Создание оркестратора для событийно-ориентированного приложения с Golang и RabbitMQ
- Не заблудитесь при работе с кластерами Kafka — возьмите компас
- Набор инструментов Go для работы с микросервисами
Читайте нас в Telegram, VK и Дзен
Перевод статьи Mohammad Hoseini Rad: Building a Data-Driven application with Golang and Kafka — Personalization




