
Вместе Apache Kafka, Flink и Druid формируют архитектуру данных реального времени. Разберемся в этом подробнее на примере создания приложений.
Разработка приложений с обработкой данных в реальном времени
Приложение с обработкой данных в режиме реального времени — это любое API, использующее для анализа или принятия решений постоянно обновляемые реальные данные. Такие приложения выполняют функции оповещения, мониторинга и аналитики, предлагают персонализированные рекомендации.
Для реализации подобных задач нужны специализированные инструменты, способные обрабатывать весь канал передачи данных от события к приложению. Именно здесь востребована архитектура KFD (Kafka-Flink-Druid).
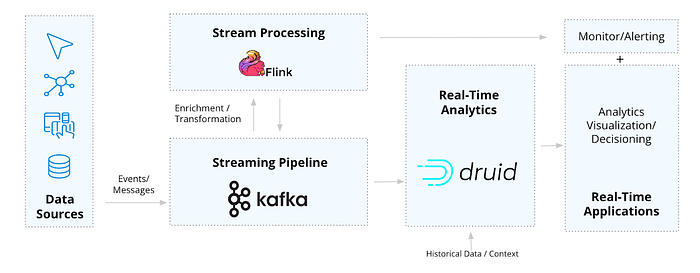
Такие крупные компании, как Lyft, Pinterest, Reddit и Paytm, которым нужны функции реального времени, используют эти три инструмента вместе. Каждый из них построен на основе взаимодополняющих потоковых технологий, способных непрерывно обеспечивать актуальность, масштабируемость и надежность данных, что необходимо в сценариях использования в реальном времени.
Эта архитектура упрощает создание приложений реального времени для наблюдения, Интернета вещей/анализа телеметрии, обнаружения/диагностики в системах безопасности и клиентской телеметрии с высокой пропускной способностью и множеством запросов в секунду (QPS, Queries Per Second).
Рассмотрим составляющие архитектуры по отдельности и совместно.
Конвейер потоковой передачи Apache Kafka
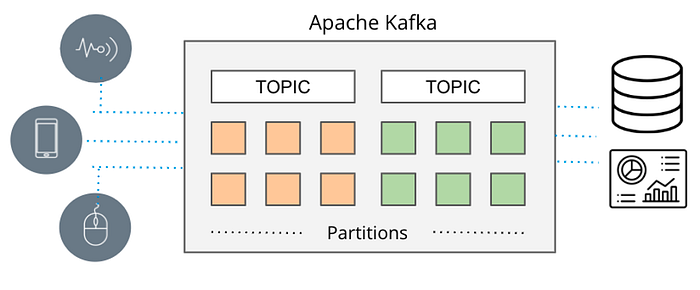
Apache Kafka — сегодня стандарт де-факто для потоковой передачи данных. Ранее для обмена сообщениями между источником и потребителем использовались RabbitMQ, ActiveMQ и другие инструменты массовой передачи сообщений с ограниченной производительностью.
Сегодня в США Kafka используют более 80% компаний из списка Fortune 1001. Причиной тому стала универсальность инструмента с архитектурой, явно превосходящей простой обмен сообщениями. Kafka оптимален для потоковой передачи данных в масштабах интернета благодаря отказоустойчивости и согласованности данных для поддержки наиболее критичных в этом отношении приложений. Расширенный набор соединителей Kafka Connect интегрируется с любыми источниками данных.
Потоковая обработка: Apache Flink
Воспользоваться преимуществами быстродействия и масштабируемости Kafka в реальном времени позволяют подходящие потребители сообщений. Один из них — Apache Flink.
Унифицированный механизм пакетной и потоковой обработки Flink отличает высокая производительность при работе с большими и непрерывными объемами данных. Flink оптимален в качестве потокового процессора для Kafka. Он легко интегрируется и поддерживает семантику “только один раз”, гарантируя однократную обработку события даже при системных сбоях.
Использовать Flink просто: подключитесь к теме Kafka, определите логику запроса, а затем непрерывно выдавайте результат. Работает принцип “установил и забыл”. Поэтому Flink довольно универсален там, где важна оперативная обработка потоков и надежность.
Распространенные варианты использования Flink:
- извлечение и обработка данных;
- непрерывный мониторинг и оповещение.
Извлечение и обработка данных
Если для данных необходима какая-либо предварительная обработка (модификация, улучшение или реструктуризация), Flink — идеальный движок для внесения изменений и дополнений в эти потоки, который позволяет непрерывно обновлять обрабатываемые данные.
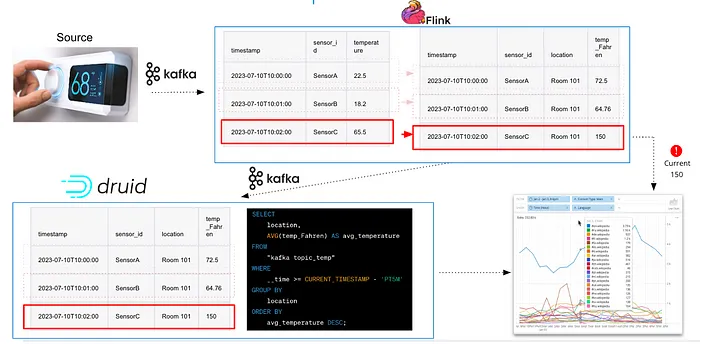
Допустим, имеется поток данных типа интернета вещей/телеметрии от датчиков температуры, установленных на смарт-объекте. Каждое событие, поступающее в Kafka, имеет следующую структуру JSON:
{
"sensor_id": "SensorA",
"temperature": 22.5,
"timestamp": "2023-07–10T10:00:00"
}
Если необходимо каждому идентификатору датчика сопоставить местоположение, а температуру указать в градусах Фаренгейта, Flink может обновить структуру JSON так.
{
"sensor_id": "SensorA",
"location": "Room 101",
"temperature_Fahreinheit": 73,4,
"timestamp"
},
Передача данных непосредственно в приложение или отправка обратно в Kafka.

В данном случае преимуществом Flink является производительность при работе в реальном времени с огромными потоками от Kafka (миллионы событий в секунду). Кроме того, извлечение/преобразование — это часто процесс без сопровождения состояния. При этом каждая запись данных может быть эффективно и с минимальными усилиями изменена без сопровождения персистентного состояния.
Непрерывный мониторинг и оповещение
Непрерывная (поточная) обработка данных и отказоустойчивость в режиме реального времени делают Flink идеальным решением для обнаружения и реагирования в ответственных приложениях.
При высокой оперативности обнаружения (менее секунды) и большой частоте дискретизации, поточная технология Flink эффективна в качестве сервиса обработки данных и мониторинга с запуском исходя из этого оповещений и действий.
Преимуществом Flink является и то, что он может поддерживать оповещения как без сохранения состояния, так и с отслеживанием состояния. Пороги или триггеры событий (например, “уведомить пожарную службу, когда температура достигнет X”) реализуются просто, но не всегда достаточно интеллектуально. Таким образом, если оповещение должно управляться сложными шаблонами, требующими памяти состояния (или даже обобщения метрик, например sum, avg, min, max, count и др.) в непрерывном потоке данных, Flink может отслеживать и обновлять состояние, чтобы идентифицировать отклонения и аномалии.
Известно, что использование Flink для мониторинга и оповещения постоянно загружает центральный процессор (требует постоянных затрат и занимает ресурсы) для сравнения текущих условий с предельными и шаблонными значениями. Тогда как база данных (БД) использует центральный процессор только в процессе запроса. Поэтому следует учитывать реальную востребованность непрерывной обработки.
Аналитика в реальном времени: Apache Druid
Дополнением рассматриваемой архитектуры данных является Apache Druid, объединяющий Kafka и Flink в качестве потребителя потоков для аналитики в реальном времени. Это аналитическая БД, но блок обработки и принцип действия значительно отличают ее от других баз и хранилищ данных.
Начнем с того, что Druid — ориентированный на поток инструмент (как Kafka и Flink). Фактически, здесь не нужен соединитель, поскольку он подключается непосредственно к разделам (topic) Kafka и поддерживает семантику “только один раз”. Druid разработан для быстрого приема массива потоковых данных и последующего немедленного запроса событий в памяти.
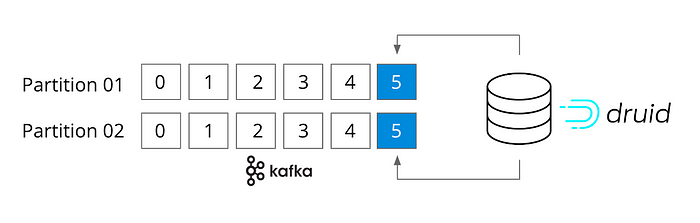
Что касается обработки запросов, Druid — это высокопроизводительная аналитическая БД реального времени, выполняющая под нагрузкой массовые запросы за доли секунды. Druid — идеальная БД, поскольку стабильно выполняет молниеносные запросы и может легко масштабироваться от одного ноутбука до кластера из 1000 узлов, если нужна повышенная производительность и обработка данных объемом от терабайт до петабайт (например, агрегации, фильтры, группировки, сложные объединения и т. д.) с большим объемом запросов.
Поэтому Druid известна как аналитическая БД реального времени, обрабатывающая запросы в режиме РВ.
Druid дополняет Flink за счет:
- обработки высокоинтерактивных запросов;
- работы в режиме реального времени с историческими (прежними) данными.
Высокоинтерактивные запросы
Разработчики используют Druid в аналитических приложениях, обрабатывающих большие объемы данных и включающих как внутренние (т. е. функциональные), так и внешние (т. е. ориентированные на клиента) сценарии использования для наблюдения, безопасности, аналитики продуктов, Интернета вещей/телеметрии, технологических операций и т. д.
Приложения на базе Druid обычно обладают следующими особенностями:
- Масштабируемая производительность. Приложения с субсекундной скоростью чтения и расширенной аналитикой запросов к большим наборам данных, без предварительных вычислений. Druid отличает высокая производительность, даже если пользователи приложения произвольно группируют, фильтруют и разделяют множество случайных запросов в масштабе от терабайт до петабайт.
- Большой объем запросов. Аналитические приложения с множественными запросами в секунду. Например, любое внешнее приложение для обработки данных с рабочей нагрузкой от 100 до 1000 разных запросов одновременно, требующее субсекундных SLA (соглашения об уровне обслуживания).
- Синхронизируемые по времени данные. Приложения предоставляют данные с привязкой по времени (преимущество Druid, но не предел возможностей). Druid может очень быстро обрабатывать массивы синхронизируемых по времени данных благодаря их разделению по времени и формату. Что делает временные фильтры
WHEREневероятно быстрыми.
Благодаря быстродействию Druid, такие приложения имеют либо очень интерактивную визуализацию данных/пользовательский интерфейс с синтезированным результирующим набором данных и с очень гибким изменением запросов «на лету», либо для ускоренного выполнения массовых запросов они часто используют API Druid, обеспечивающий процесс принятия решений.
Пример аналитического приложения на базе Apache Druid:
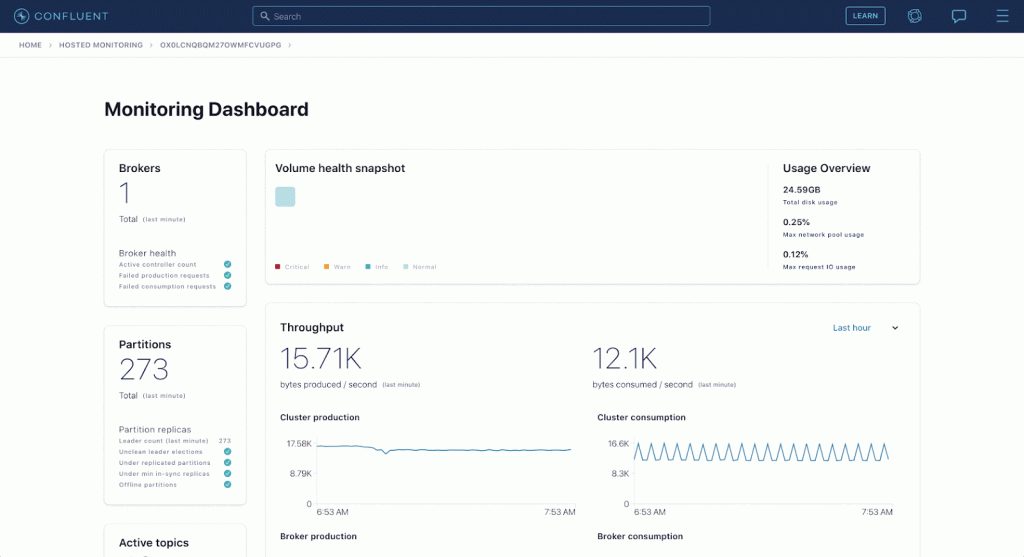
Изначально, в Confluent создатели Apache Kafka обеспечили клиентам аналитику через приложение Confluent Health+, представленное выше. Оно отличается отличной интерактивностью и содержит информацию о среде Confluent. События транслируются в Kafka и Druid со скоростью 5 миллионов событий в секунду, а приложение обслуживает 350 запросов в секунду (QPS).
Работа в реальном времени с историческими данными
Хотя в приведенном примере Druid поддерживает довольно интерактивное аналитическое приложение, возникает вопрос: “А какое отношение к этому имеет потоковая передача?”. Это верное замечание, поскольку Druid, не ограничиваясь потоковой передачей данных, способен также обрабатывать и большие пакетные файлы.
Востребованность Druid в архитектуре данных реального времени обеспечивает также интерактивное совместное взаимодействие с актуальными и архивными (историческими) данными, расширяющее функциональные возможности.
Flink отлично отвечает на вопрос “что происходит сейчас” (т.е. выдает текущий статус задания). Тогда как Druid способен реализовать и более сложные запросы типа “что происходит сейчас, как это соотносится с предыдущим состоянием и какие факторы/условия повлияли на этот результат”. В комплексе эти вопросы весьма действенны. Например, они помогут устранить ложные срабатывания, обнаружить новые тренды и привести к более обоснованным решениям в режиме реального времени.
Для обработки условия “как это соотносится с предыдущим состоянием” нужен исторический контекст (день, неделя, год или другой период времени) для корреляции. А вопрос “какие факторы/условия повлияли на результат” требует интеллектуального анализа и полного набора данных. Поскольку Druid — это аналитическая БД реального времени, она не только принимает потоки данных для извлечения актуальной информации, но и сохраняет данные, чтобы впоследствии запрашивать их и все другие метрики для изучения по ситуации.
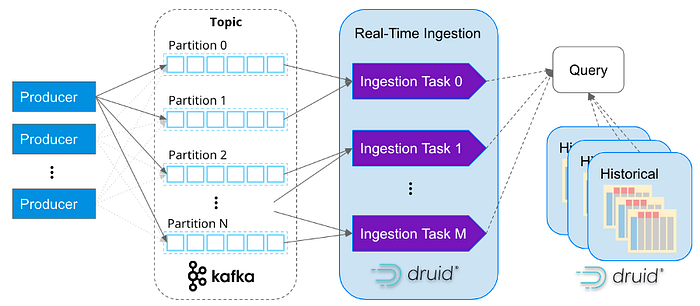
Допустим, создается приложение для отслеживания подозрительного поведения логинов безопасности. Можно установить пороговое значение в 5-минутном окне: т. е. обновлять и генерировать состояние попыток входа. Это просто сделать и с Flink. Но с Druid текущие попытки входа в систему могут быть еще и сопоставлены с историческими данными, чтобы выявить прежние аналогичные всплески активности при входе в систему без нарушений безопасности. Таким образом, исторический контекст помогает идентифицировать текущий всплеск активности как проблему или же как нормальное поведение.
Итак, Druid нужен для очень гибкого приложения с множеством анализируемых данных (например, текущее состояние, различные агрегации, группирование, временные окна, сложные объединения и др.) о быстро меняющихся событиях, включая их исторический контекст.
Выбираем Flink или Druid
Flink и Druid ориентированы на обработку поточно передаваемых данных. У них есть некоторые общие черты верхнего уровня. Оба инструмента работают в памяти, оба могут масштабироваться, оба могут распараллеливаться. Но, как отмечено выше, их архитектуры в действительности ориентированы на совершенно разные исходные условия использования.
Выбор инструмента в зависимости от загрузки приложения
- При обработке потоковых данных в режиме реального времени нужно преобразовать или объединить данные?
Рассматриваем Flink, поскольку это его повседневные задачи, этот инструмент предназначен для обработки данных реального времени. - Нужно поддерживать много разных запросов одновременно?
Обратите внимание на Druid, поскольку он поддерживает аналитику при множестве запросов в секунду (QPS) без необходимости управлять запросами/заданиями. - Есть необходимость в постоянном обновлении или агрегировании исходных параметров?
Обратите внимание на Flink, потому что он поддерживает сложную обработку событий с сохранением состояния. - Нужна сложная аналитика данных с учетом исторических значений для сравнения?
Рассматриваем Druid, поскольку он способен в режиме реального времени легко и быстро запрашивать данные с учетом их прежних значений. - Имеется ориентированное на пользователя приложение или визуализация данных?
Используйте Flink для извлечения данных, затем отправьте их в Druid на уровень использования данных.
Чаще всего выбором является не Druid или Flink, а скорее Druid и Flink. Каждый из этих инструментов обладает специфическими особенностями, которые пригодятся для поддержки широкого спектра приложений обработки данных реального времени.
Заключение
Обработка данных в режиме реального времени становится для бизнеса насущной потребностью. В результате необходимо пересматривать все этапы обработки данных.
Поэтому многие компании обращают особое внимание на связку инструментов Kafka-Flink-Druid. Это идеальное трио фактически становится архитектурой данных с открытым исходным кодом для создания приложений реального времени.
Читайте также:
- Проект инженерии данных «от и до» с Apache Airflow, Postgres и GCP
- Событийно-ориентированная архитектура
- Получение одного события разными группами получателей в Kafka с Spring Boot
Читайте нас в Telegram, VK и Дзен
Перевод статьи David Wang: Building a Real-Time Data Architecture with Apache Kafka, Flink, and Druid





