
Введение
ETL расшифровывается как Extract, Transform, Load — извлекать, преобразовывать, загружать. Это один из самых востребованных процессов дата-инженеров в рабочем потоке конвейера данных: извлечение данных из источника, преобразование в подходящий для последующих задач формат, а затем их загрузка в единый репозиторий — как правило, в хранилище данных. Это простейшая форма ETL.
Подходящие данные отсутствовали, поэтому их пришлось сгенерировать под вариант применения этого проекта. Зато имеется проектная документация.
Подробно расскажем об использовании Apache Airflow в контейнерах Docker, оркестрации ETL-конвейеров, работе с облачными технологиями, настройке рабочей среды для ETL-проектов с Apache Airflow. В конце этой немаленькой, но определенно полезной статьи поделимся нужными командами.
Содержание
- Постановка задачи и решение
- Инструменты и среды проекта
- Настройка среды
- ETL-конвейер
- Задача Big Query и Looker Studio
Постановка задачи и решение
В транзакционной онлайн-базе данных интернет-платформы по продаже модной одежды и электронных гаджетов постоянно генерировались и со временем накопились данные. Но они не использовались из-за незнания, как это делать. После обсуждений заинтересованные стороны определились с инструментарием, в который они готовы вложиться, чтобы задействовать мощь этих данных для принятия бизнес-решений. Вас, как дата-инженера, привлекли к работе над ETL-конвейером данных.
Инструменты и среды проекта
- База данных PostgreSQL
- Учетная запись Gmail
- Учетная запись Google Cloud
- Контейнер Bucket в Google Cloud Storage
- Google Big Query
- Google Looker Studio
- Apache Airflow
- VS Code
- Docker Desktop
- Виртуализация и включаемая подсистема Windows для Linux
Настройка среды
1. PostgreSQL
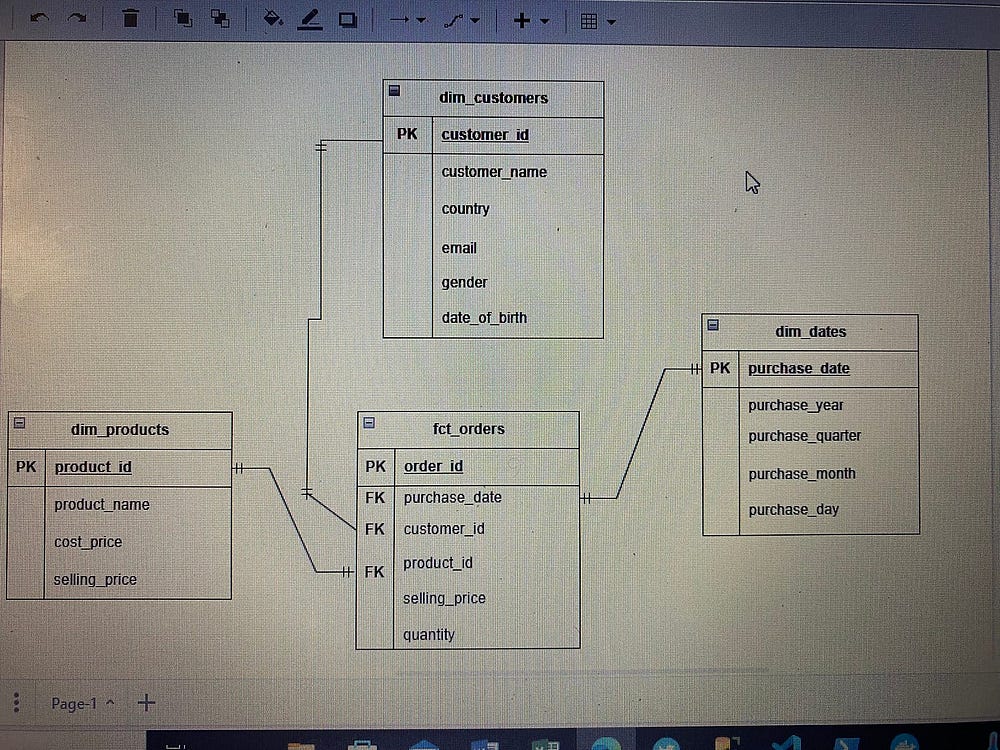
В базе данных PostgreSQL настраиваем две схемы для двух направлений интернет-магазина: модной одежды в БД Merch_Store_Fashion и электроники в БД Merch_Store_Electronics.
В этих БД и схемах пишем SQL-запрос, которым в созданные схемы копируются данные из источника — общедоступной схемы соответственных баз данных:
Схема модной одежды:
-- создается схема
CREATE SCHEMA fashion;
--чтобы загружать необработанные данные из общедоступных, создаются таблицы.
-- таблицы измерений
CREATE TABLE fashion.dim_products(
product_id INTEGER NOT NULL PRIMARY KEY,
product_name VARCHAR (200),
cost_price NUMERIC,
selling_price NUMERIC
);
CREATE TABLE fashion.dim_customers(
customer_id INTEGER NOT NULL PRIMARY KEY,
customer_name VARCHAR(200),
country VARCHAR(200),
email VARCHAR(200),
gender VARCHAR(20),
date_of_birth TIMESTAMP
);
CREATE TABLE fashion.dim_dates(
purchase_date TIMESTAMP PRIMARY KEY,
purchase_year INTEGER,
purchase_quarter INTEGER,
purchase_month INTEGER,
purchase_day INTEGER
);
-- создается таблица фактов
CREATE TABLE fashion.fct_orders(
order_id NUMERIC NOT NULL PRIMARY KEY,
purchase_date TIMESTAMP,
customer_id INTEGER,
product_id INTEGER,
selling_price NUMERIC,
quantity INTEGER
FOREIGN KEY (purchase_date) REFERENCES fashion.dim_dates(purchase_date),
FOREIGN KEY (customer_id) REFERENCES fashion.dim_customers(customer_id),
FOREIGN KEY (product_id) REFERENCES fashion.dim_products(product_id)
);
-- в эти таблицы загружаются данные из исходных таблиц в общедоступной схеме
INSERT INTO fashion.dim_products(product_id, product_name, cost_price, selling_price)
SELECT product_id, product_name, cost_price, selling_price
FROM Merch_Store_Fashion.public.fashion_product_table;
INSERT INTO fashion.dim_customers(customer_id, customer_name, country, email, gender,date_of_birth)
SELECT customer_id, customer_name, country, email, gender,date_of_birth
FROM Merch_Store_Fashion.public.customer_table_f;
INSERT INTO fashion.dim_dates(purchase_date, purchase_year, purchase_quarter,purchase_month,purchase_day)
SELECT DISTINCT purchase_date,
EXTRACT(YEAR FROM purchase_date) AS purchase_year,
EXTRACT(QUARTER FROM purchase_date) AS purchase_year,
EXTRACT(MONTH FROM purchase_date) AS purchase_month,
EXTRACT(DAY FROM purchase_date) AS purchase_day
FROM Merch_Store_Fashion.public.fashion_purchase_table;
INSERT INTO fashion.fct_orders(order_id, purchase_date, customer_id, product_id, selling_price, quantity)
SELECT order_id, purchase_date, customer_id, product_id, selling_price, quantity
FROM Merch_Store_Fashion.public.fashion_purchase_table;
Схема электроники:
-- создается схема
CREATE SCHEMA electronics;
--чтобы загружать необработанные данные из общедоступных, создаются таблицы.
-- таблицы измерений
CREATE TABLE electronics.dim_products(
product_id INTEGER NOT NULL PRIMARY KEY,
product_name VARCHAR (200),
cost_price NUMERIC,
selling_price NUMERIC
);
CREATE TABLE electronics.dim_customers(
customer_id INTEGER NOT NULL PRIMARY KEY,
customer_name VARCHAR(200),
country VARCHAR(200),
email VARCHAR(200),
gender VARCHAR(20),
date_of_birth TIMESTAMP
);
CREATE TABLE electronics.dim_dates(
purchase_date TIMESTAMP PRIMARY KEY,
purchase_year INTEGER,
purchase_quarter INTEGER,
purchase_month INTEGER,
purchase_day INTEGER
);
-- создается таблица фактов
CREATE TABLE electronics.fct_orders(
order_id NUMERIC NOT NULL PRIMARY KEY,
purchase_date TIMESTAMP,
customer_id INTEGER,
product_id INTEGER,
selling_price NUMERIC,
quantity INTEGER
FOREIGN KEY (purchase_date) REFERENCES electronics.dim_dates(purchase_date),
FOREIGN KEY (customer_id) REFERENCES electronics.dim_customers(customer_id),
FOREIGN KEY (product_id) REFERENCES electronics.dim_products(product_id)
);
-- в эти таблицы загружаются данные из исходных таблиц в общедоступной схеме
INSERT INTO electronics.dim_products(product_id, product_name, cost_price, selling_price)
SELECT product_id, product_name, cost_price, selling_price
FROM Merch_Store_Electronics.public.electronic_products;
INSERT INTO electronics.dim_customers(customer_id, customer_name, country, email, gender,date_of_birth)
SELECT customer_id, customer_name, country, email, gender,date_of_birth
FROM Merch_Store_Electronics.public.customer_table_e;
INSERT INTO electronics.dim_dates(purchase_date, purchase_year, purchase_quarter,purchase_month,purchase_day)
SELECT DISTINCT purchase_date,
EXTRACT(YEAR FROM purchase_date) AS purchase_year,
EXTRACT(QUARTER FROM purchase_date) AS purchase_year,
EXTRACT(MONTH FROM purchase_date) AS purchase_month,
EXTRACT(DAY FROM purchase_date) AS purchase_day
FROM Merch_Store_Electronics.public.electronic_purchase_table;
INSERT INTO electronics.fct_orders(order_id, purchase_date, customer_id, product_id, selling_price, quantity)
SELECT order_id, purchase_date, customer_id, product_id, selling_price, quantity
FROM Merch_Store_Electronics.public.electronic_purchase_table;
2. Настройка Google Cloud Platform
Обзаводимся учетной записью Gmail.
Регистрируемся на GCP: просто вводим в браузере Google Cloud Console, переходим в нее, подключаемся и создаем учетную запись GCP.
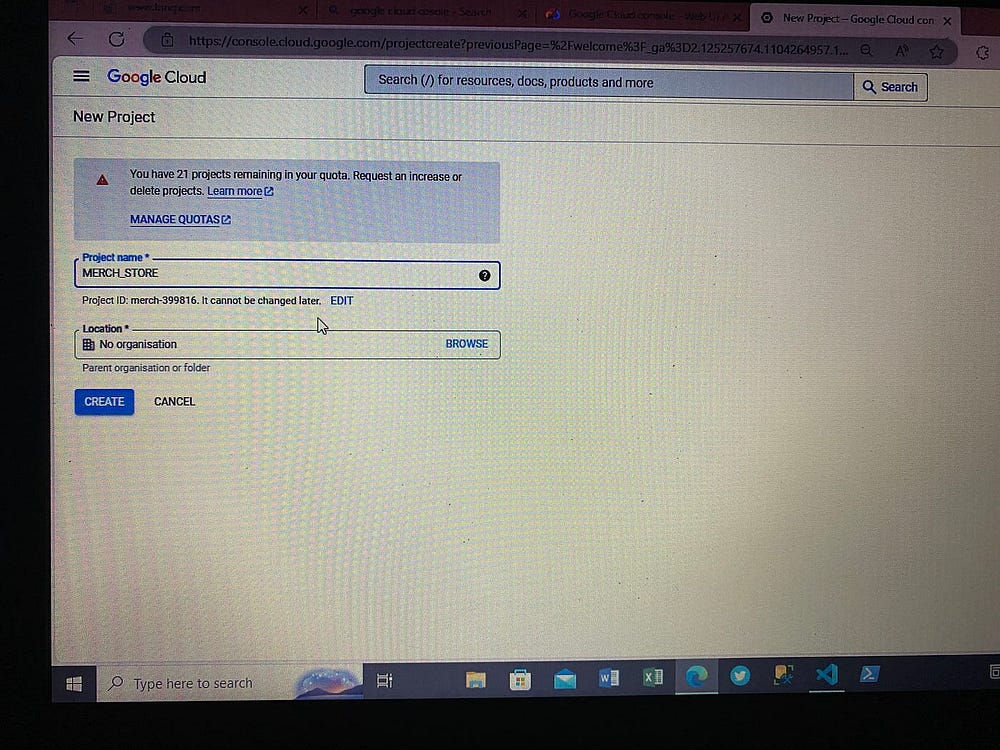
Создаем название проекта:
Настраиваем Big Query и Cloud Storage.
Big Query — это хранилище данных проекта. Здесь на домашней странице GCP создаем наборы данных и таблицы. Это будет местом назначения таблиц из источника, а именно базы данных PostgreSQL:
В консоли GCP нажимаем на Cloud Storage:
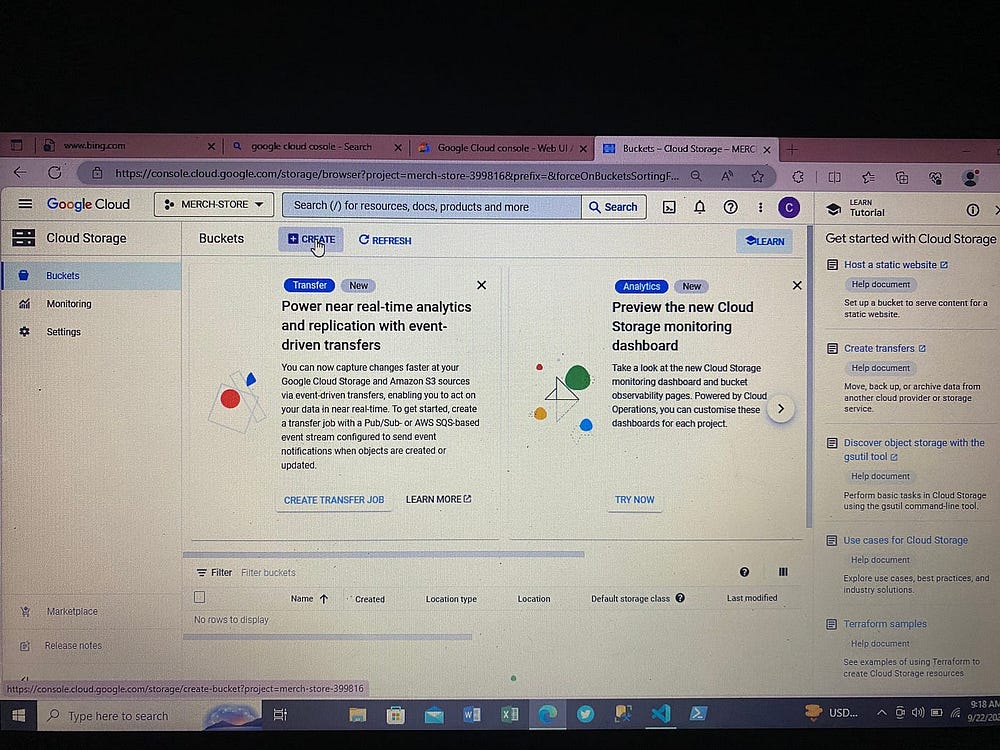
Создаем здесь контейнер bucket — озеро данных проекта:
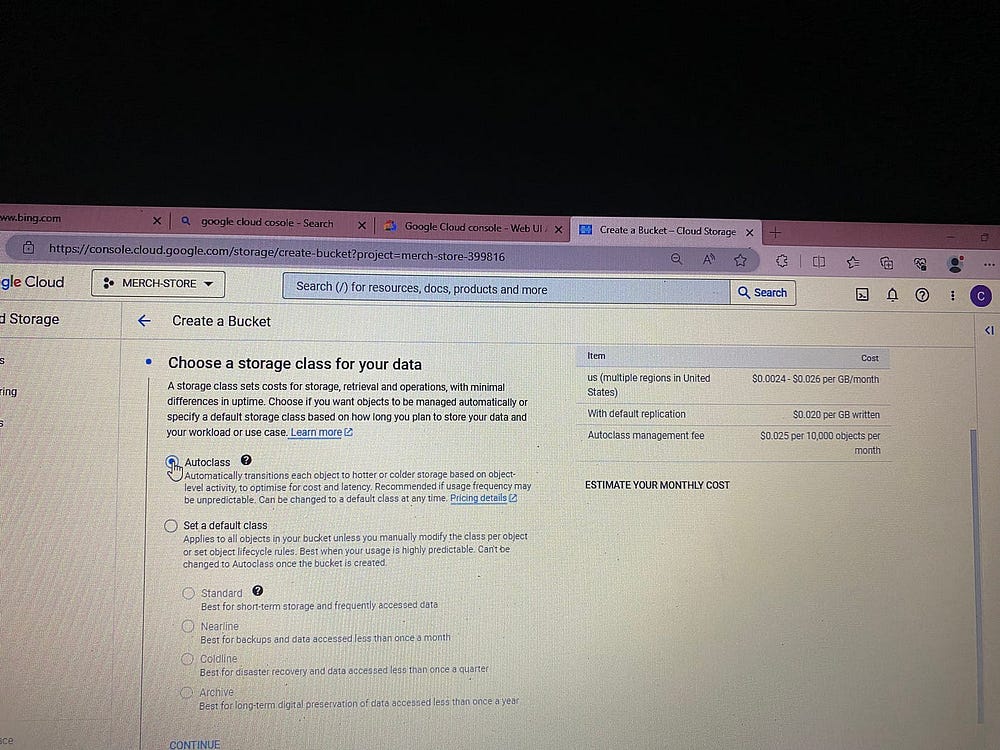
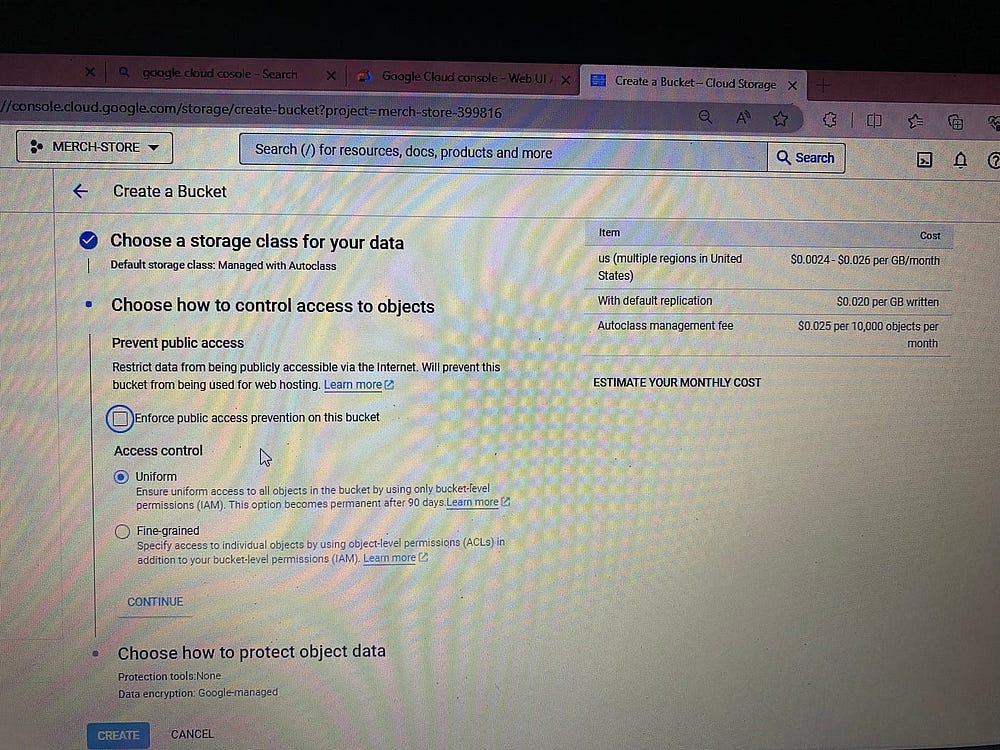
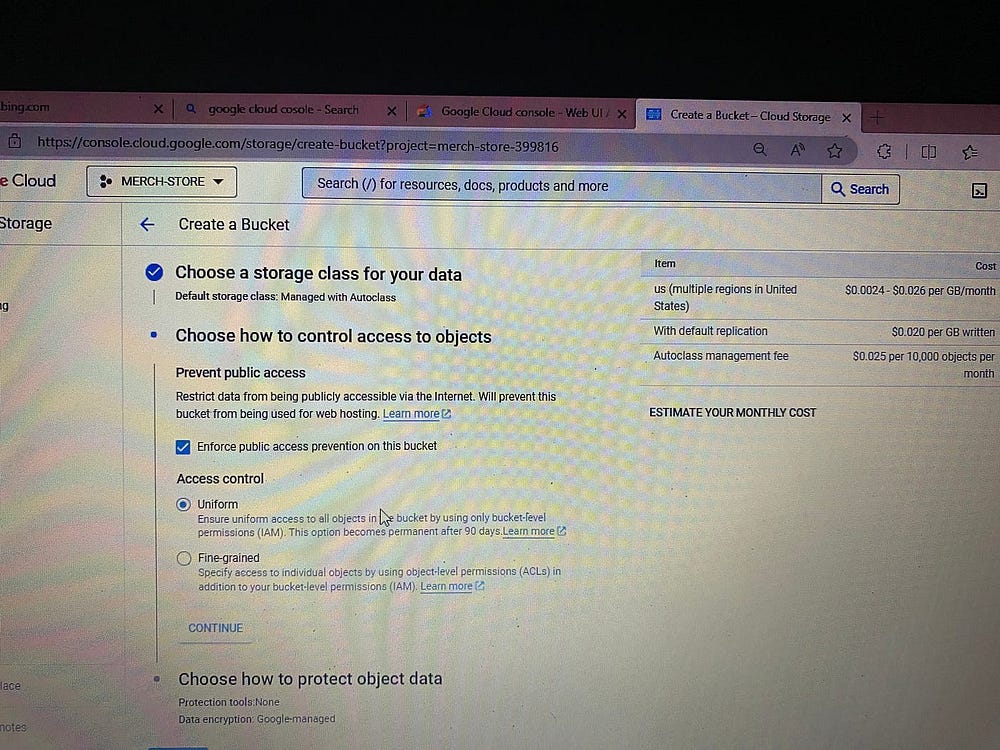
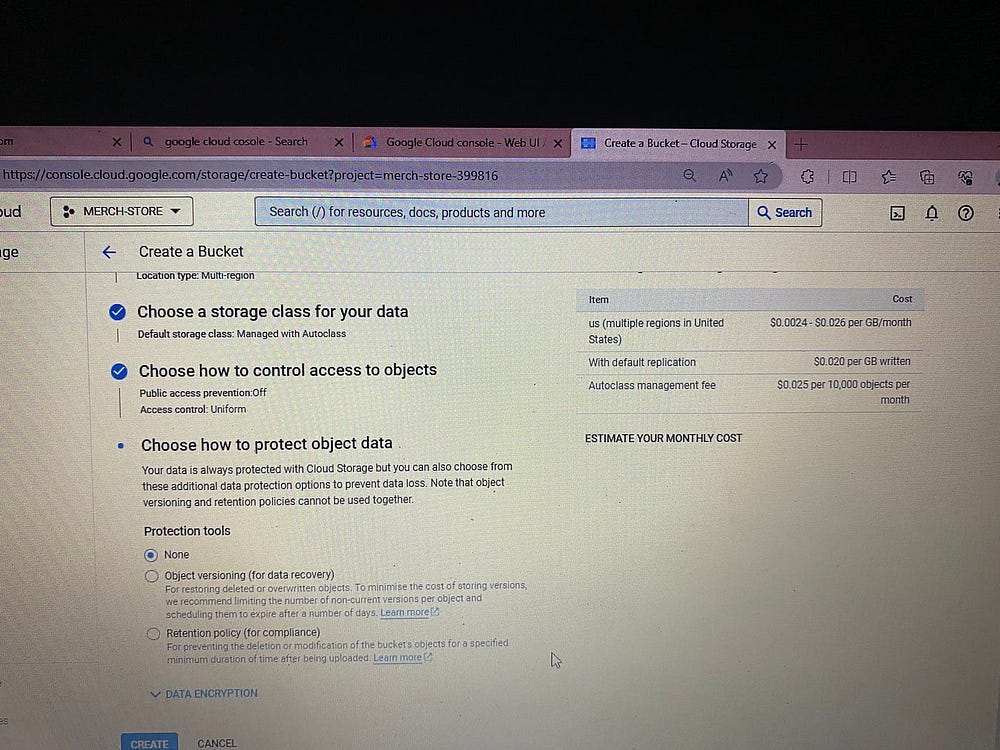
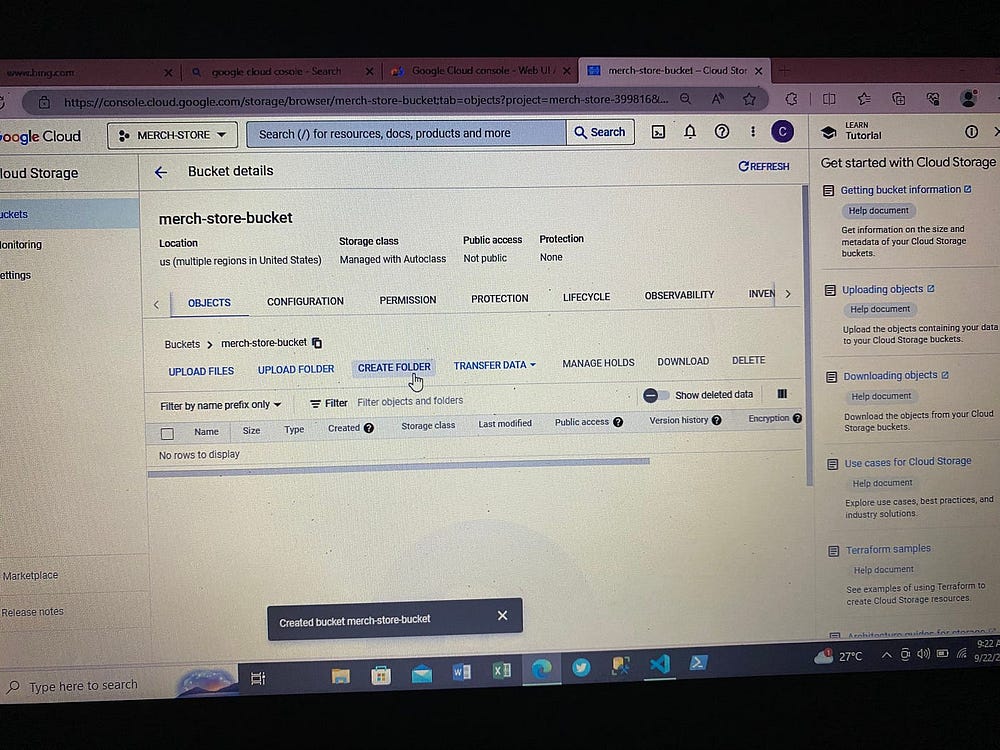
В Bucket создаем папки проекта.
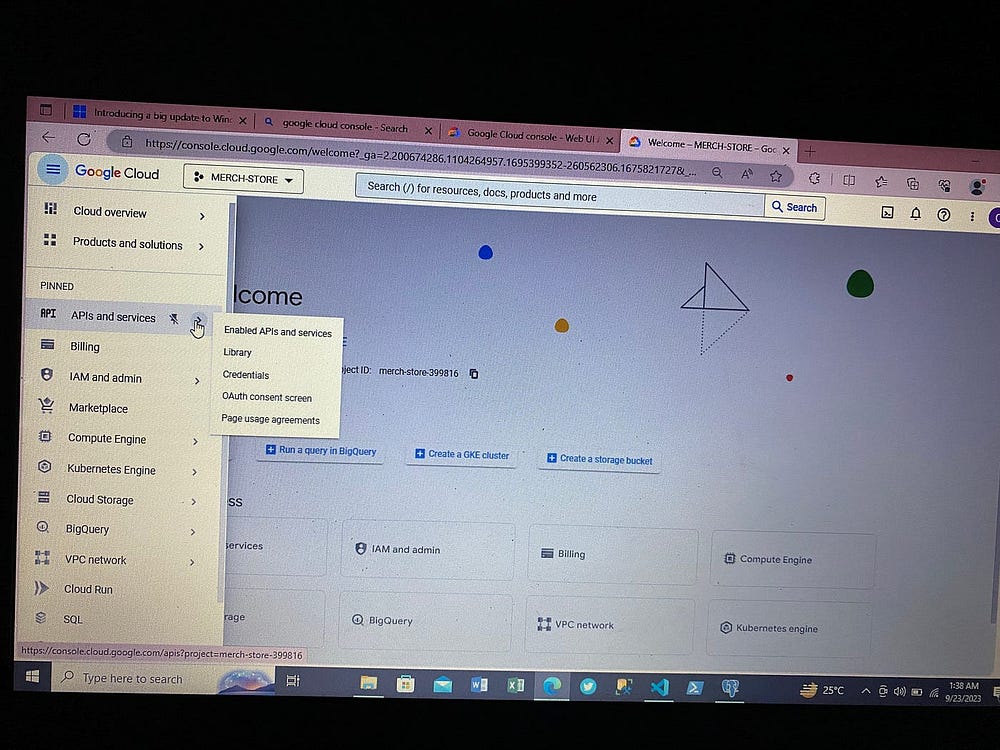
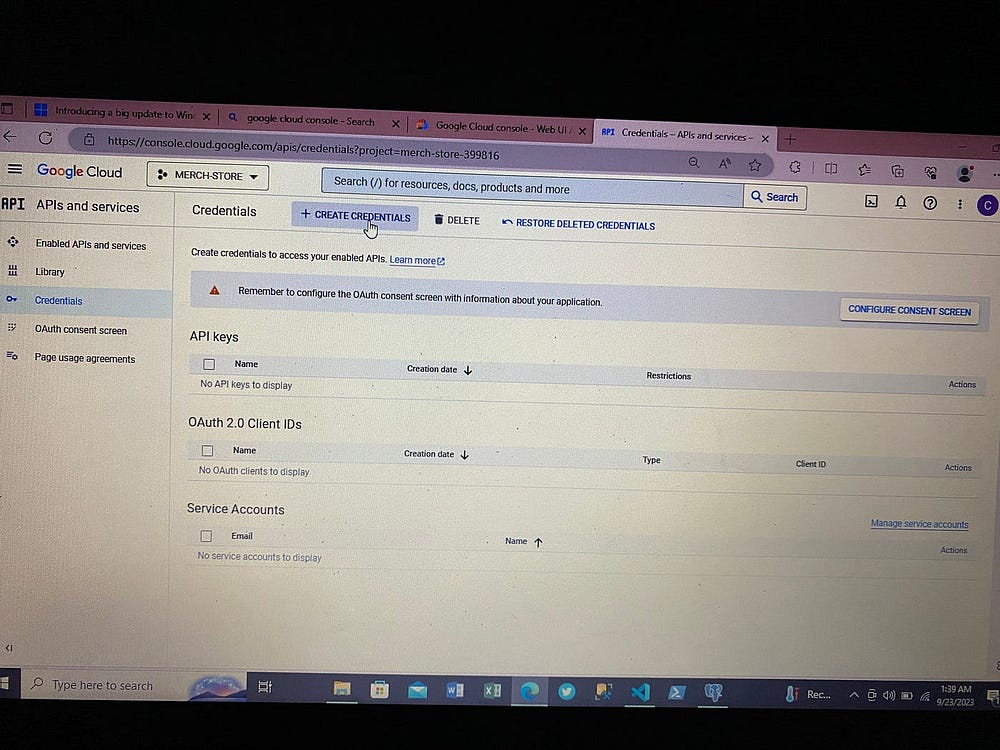
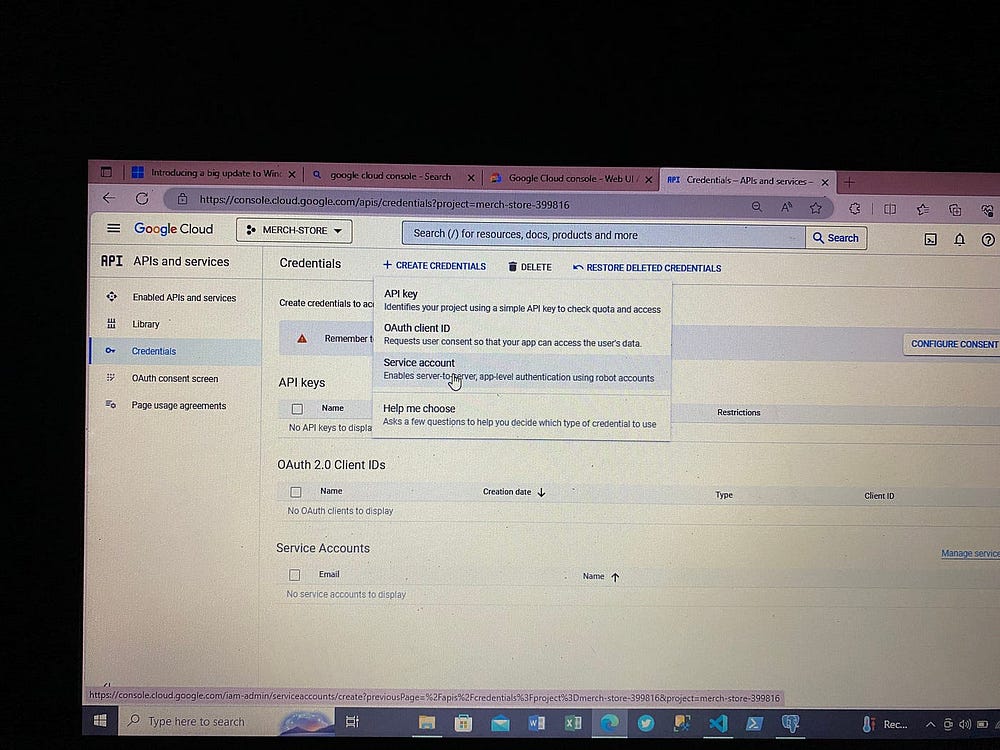
Теперь для взаимодействия с Airflow и доступа к сервисам GCP создаем ключи доступа, получаемые в файле json:
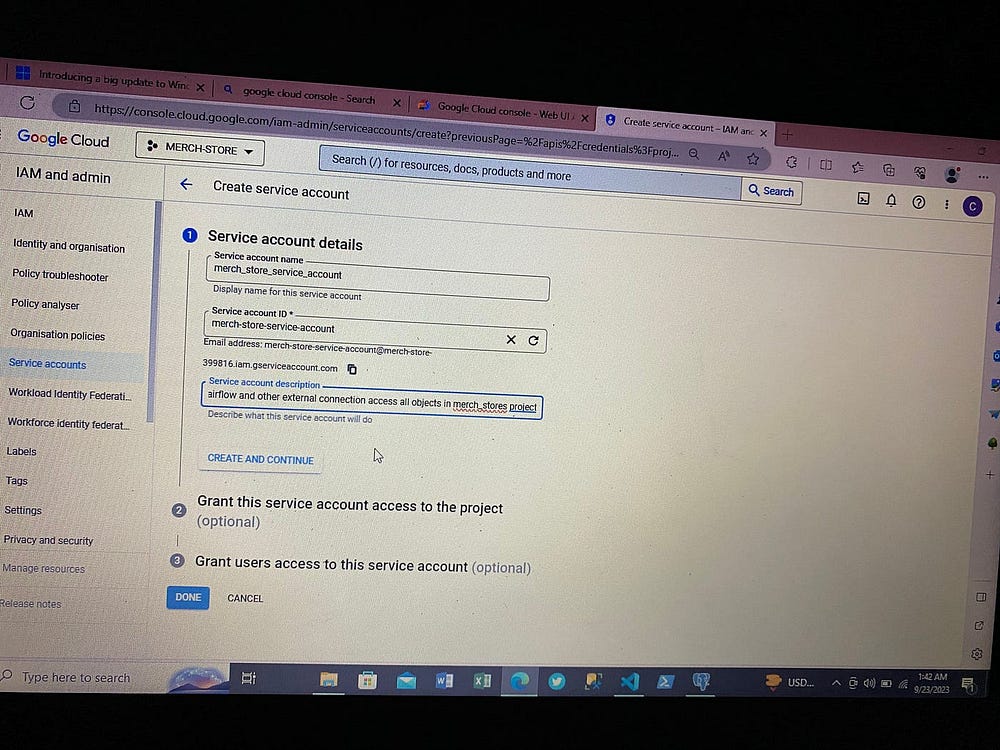
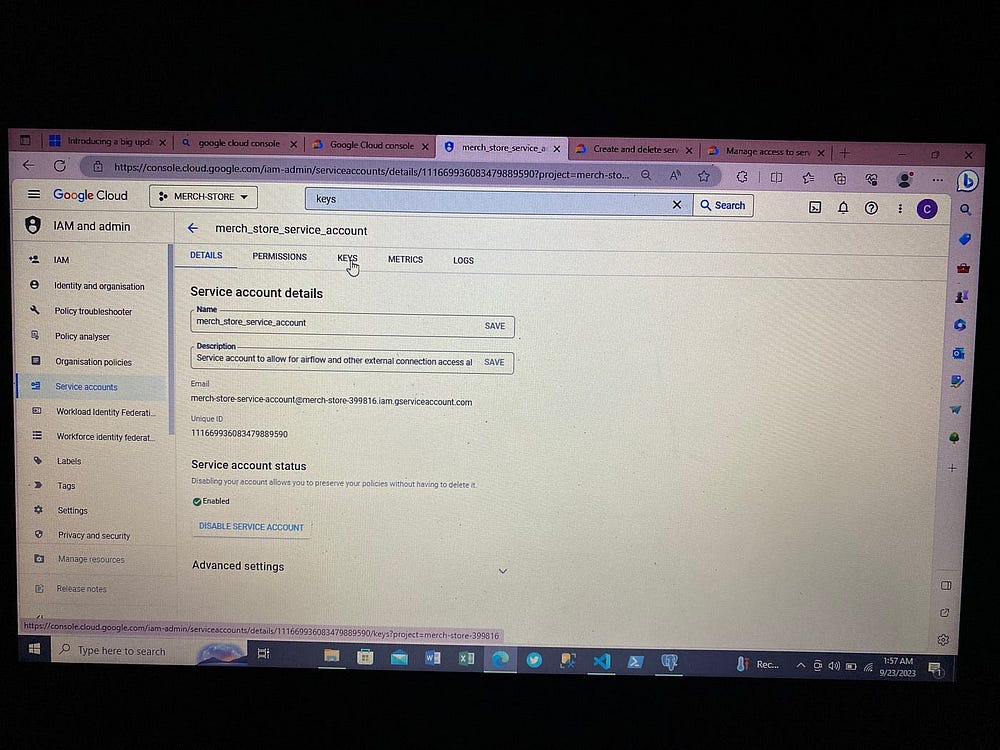
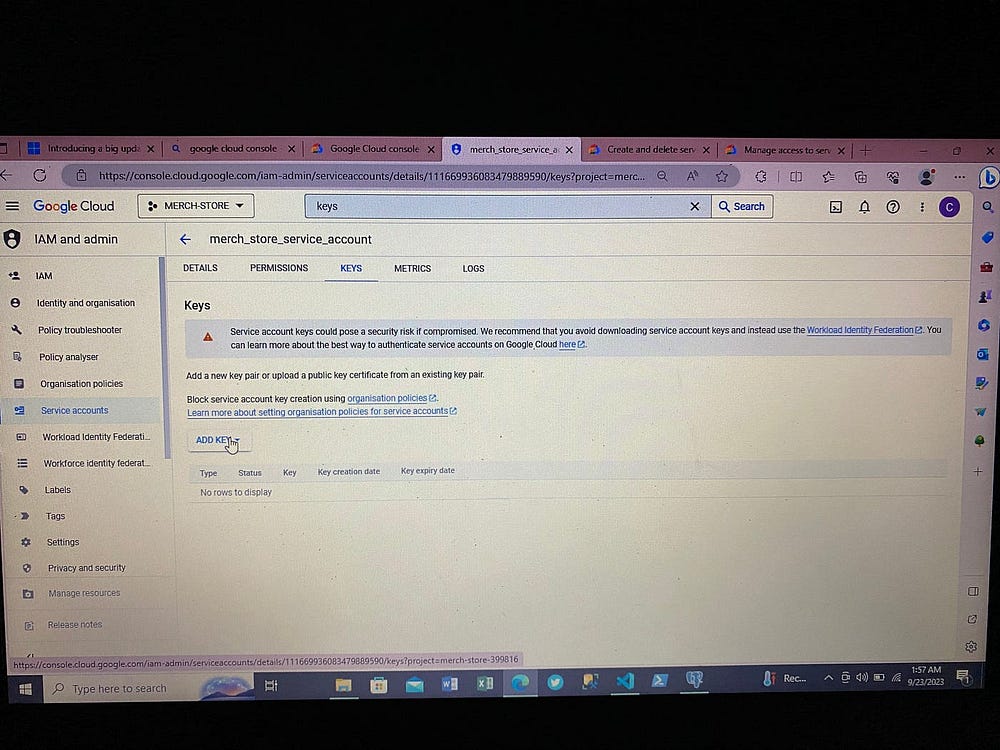
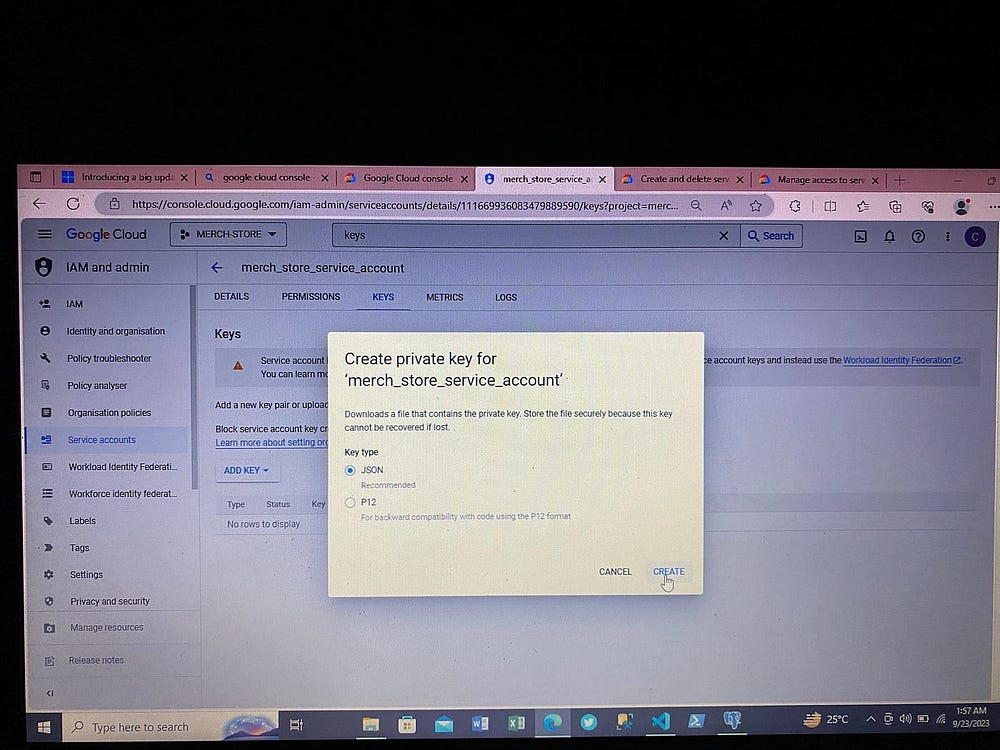
3. Настройка Airflow Docker
Этап 1. Устанавливаем Docker и Docker Compose, введя командной строке:
docker --version
docker-compose --version
Если версии выводятся, значит, на компьютере они уже установлены; если нет, загружаем с официального сайта Docker Desktop.
Этап 2. Создаем каталог Airflow с именем airflow-docker:
mkdir airflow-docker
Переходим в него:
cd airflow-docker
Этап 3. Открываем его в VS Code через командную строку:
code .
Открываем здесь терминал, нажав на клавиатуре ctrl+j.
Примечания:
В Apache Airflow имеются службы: воркер, веб-сервер, планировщик, база данных. Поэтому в Docker запустится больше одного контейнера, то есть по одному на каждую службу Airflow.
Файл docker-compose писать не нужно, он предоставлен сообществом на сайте Apache Airflow.
Этап 4. Чтобы получить файл docker-compose, в строке поиска браузера вводим airflow docker compose, нажимаем первую ссылку и прокручиваем вниз до Fetching docker-compose.yaml.
Для macOS или Linux копируем строку кода как есть:
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.7.2/docker-compose.yaml' -o 'docker-compose.yaml'
На Windows команда Lf0 не рабочая, меняем ее на эту:
curl 'https://airflow.apache.org/docs/apache-airflow/2.7.2/docker-compose.yaml' -o 'docker-compose.yaml'
Нажимаем Enter/Return ↵.
Этап 5. Открываем файл docker-compose.yaml в разделе томов:
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/dags:/opt/airflow/dags
- ${AIRFLOW_PROJ_DIR:-.}/logs:/opt/airflow/logs
- ${AIRFLOW_PROJ_DIR:-.}/config:/opt/airflow/config
- ${AIRFLOW_PROJ_DIR:-.}/plugins:/opt/airflow/plugins
Этими томами указываются каталоги, монтируемые в контейнере Docker из локальной системы при создании/воссоздании контейнеров для служб Airflow.
Поэтому в терминале, в VS Code, создаем эти каталоги:
mkdir dags
mkdir logs
mkdir plugins
Этап 6. Создаем AIRFLOW_UID и AIRFLOW_GID:
echo –e "AIRFLOW_UID=$(id –u)">.env
Это bash-команда, поэтому на Windows тип терминала меняем на git bash в VS Code.
Этап 7. Обычно для задачи нужны дополнительные зависимости. Чтобы они были видны службам Airflow в контейнерах Docker, создаем папку airflow_image, а в ней для создания пользовательских образов Docker — Dockerfile и файл requirements.txt, в котором содержатся зависимости для проекта.
Вот содержимое папки airflow_image с Dockerfile и файлом requirements.txt.
Меняем файл docker-compose.yaml таким образом:
version: '3.8'
x-airflow-common:
&airflow-common
# Для добавления пользовательских зависимостей или обновления пакетов поставщика нужен расширенный образ.
# Закомментируем строку образа, помещаем «Dockerfile» в один каталог с «docker-compose.yaml»
# и раскомментируем строку с «build» ниже. Затем для сборки образов запускаем «docker-compose build».
#image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.7.1}
build: airflow_image/
environment:
...
То есть закомментируем строку image: ${AIRFLOW_IMAGE_NAME: …..}.
Раскомментируем build:
Вставляем название папки, здесь это airflow_image, с Dockerfile и файлом requirements.txt, как во фрагменте кода выше.
Этап 8. Для этого проекта место назначения данных, то есть куда они загружаются, находится в облаке, для подключения к которому путь к ключам json облачного подключения подключается в контейнере Airflow так:
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/dags:/opt/airflow/dags
- ${AIRFLOW_PROJ_DIR:-.}/logs:/opt/airflow/logs
- ${AIRFLOW_PROJ_DIR:-.}/config:/opt/airflow/config
- ${AIRFLOW_PROJ_DIR:-.}/plugins:/opt/airflow/plugins
#создаем и подключаем каталог для ключей json учетных данных GCP
- C:/Users/USER/creds:/opt/airflow/creds
Затем, чтобы службы Airflow подключались к облачным службам, импортируем в файл dags как переменные ОС:
......
import os
# задаем переменные среды́
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "/opt/airflow/creds/merch-store-399816-963a8ea93cb6.json"
......
Этап 9. Инициализируем базу метаданных Apache Airflow, запуская в терминале VS Code:
docker-compose up airflow-init
И собираем образы Airflow Docker:
docker-compose up --build
При выполнении этих команд необходимо подключение к интернету: устанавливаемые зависимости берутся оттуда.
ETL-конвейер
Схема архитектуры
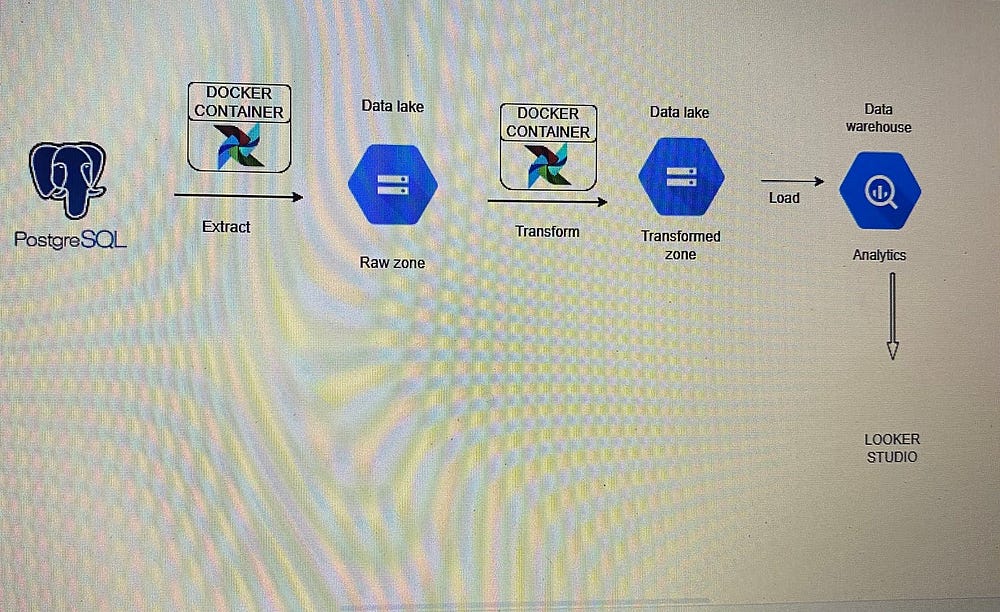
Этапы
Данные из общедоступной схемы скопированы в две новые схемы для двух категорий продаваемых в интернет-магазине товаров: модной одежды и электроники.
Скрипты Python написаны для:
- Извлечения необработанных данных из этих схем, модной одежды и электроники, в PostgreSQL.
- Загрузки таблицы в необработанную область в Google Cloud Storage bucket — озере данных.
- Извлечения из необработанной области и преобразования данных в каждой таблице под бизнес-задачи и загрузки этих преобразованных данных в очищенную область Google Cloud Storage bucket.
- Извлечения этих данных и загрузки в соответственные целевые таблицы Big Query.
Задача Big Query и Looker Studio
SQL-скрипты в Big Query написаны для создания киосков данных различных отделов, чтобы у последних гарантированно было все, что нужно для анализа и принятия бизнес-решений. Для визуализации данных киоски данных подключены к Looker Studio.
SQL-скрипт в Big Query написан для создания необходимых киосков данных. Киоски данных созданы в виде представлений, которые затем для визуализации данных подключены к Looker Studio.
Основная цель создания этих киосков данных — обеспечить управление данными для гарантированного доступа каждого отдела/подразделения компании только необходимым данным.
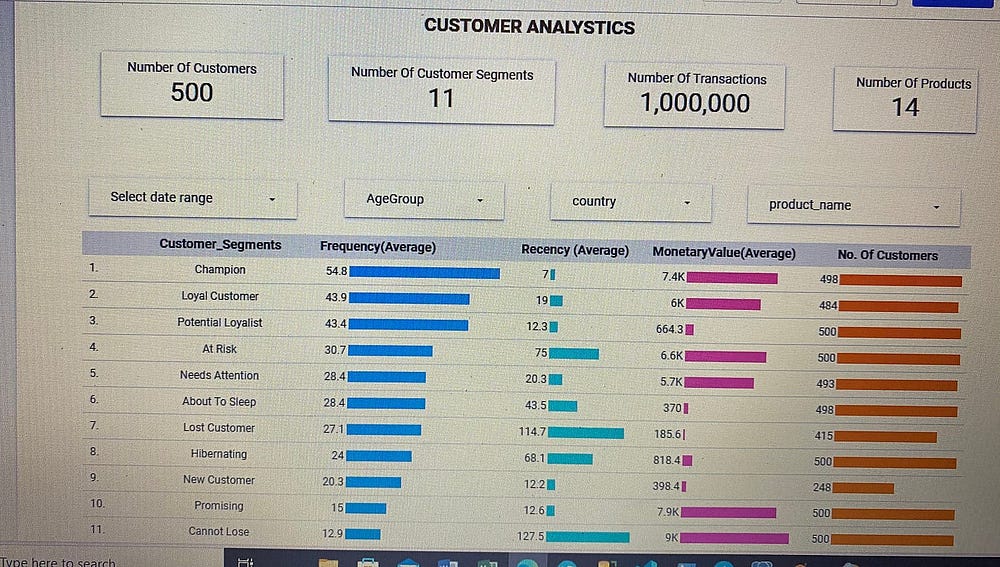
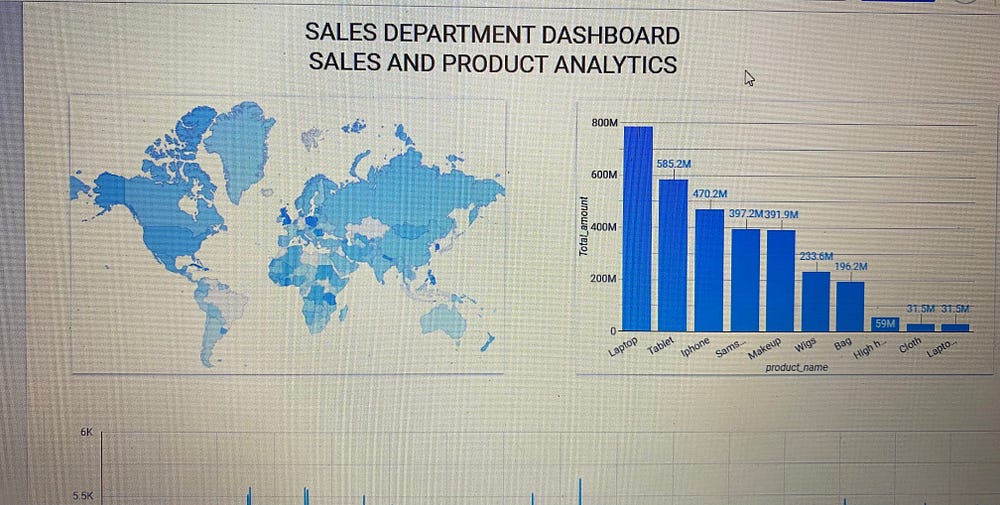
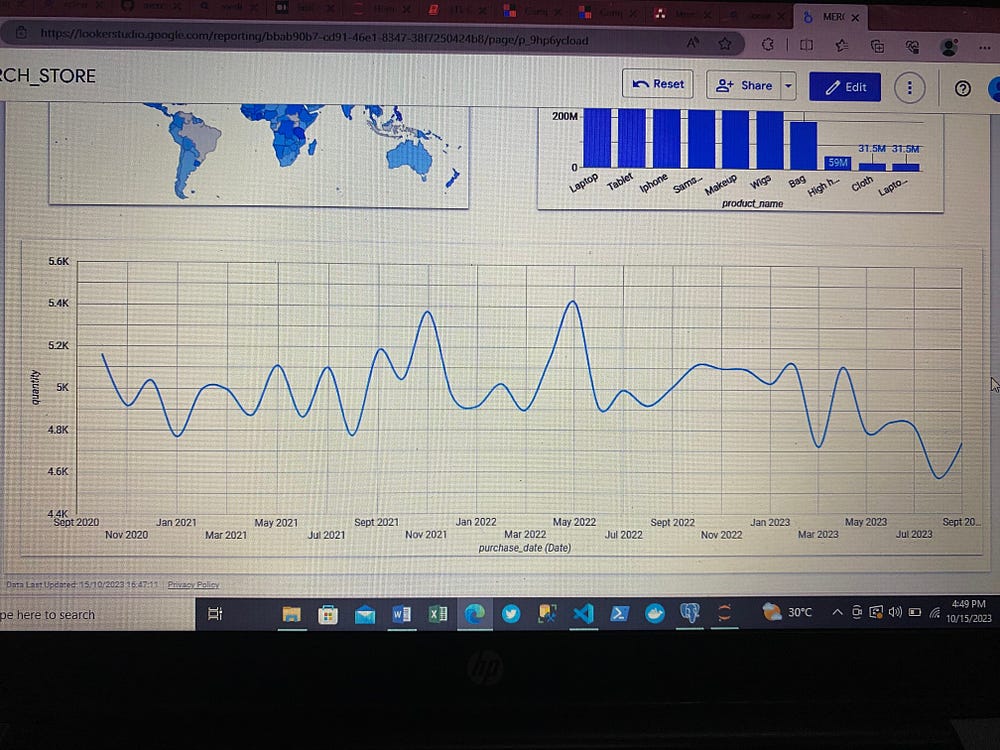
Полезные команды
Как сгенерированы данные этого проекта
Данные проекта сгенерированы Python-библиотекой Faker — ею генерируются данные любого рода — и затем сохранены в csv-файлах и загружены в общедоступной схеме базы данных PostgreSQL.
Подробнее о Faker — здесь.
Как данные загружены в базу данных
В PostgreSQL созданы две базы данных: Merch_Store_Electronics и Merch_Store_Fashion.
Таким Python-скриптом в этих БД создали таблицы и заполнили их информацией о csv-файлах:
#устанавливаем зависимости
pip install psycopg2-binary
#импортируем библиотеки
import psycopg2
from psycopg2 import sql
#создаем пользовательскую функцию
def create_table_in_postgres_db(your_user_name, your_password, your_db_name, table_name, columns):
database_params = {
"dbname": your_db_name,
"user": your_user_name,
"password": your_password,
"host": "host_server_name",
"port": "port number on which host_server_name is running"
}
#устанавливаем подключение к PostgreSQL
cnxn = None
cursor = None
try:
cnxn = psycopg2.connect(**database_params)
cursor = cnxn.cursor()
#создаем таблицу для загрузки данных
create_table = f"""
CREATE TABLE {table_name}(
{', '.join([f'{column[0]} {column[1]}' for column in columns])}
);"""
cursor.execute(create_table)
cnxn.commit()
print(f"Table {table_name} successfully created in {your_db_name} database!")
#загружаем в созданную таблицу данные из csv-файла
#df = pd.read_csv(csv_path)
#df.to_sql(name = table_name, con = cnxn, if_exists = 'replace', index = False)
except Exception as ex:
print(f"Error: {ex}")
finally:
if cursor:
cursor.close()
if cnxn:
cnxn.close()
# создаем в Merch_Store_Electronics таблицу Electronic_Purchase_Table
#определяем названия столбцов и типы данных
e_purchases_columns = [
("Order_ID", "INTEGER"),
("Purchase_Date", "TIMESTAMP"),
("Customer_ID", "INTEGER"),
("Customer_Gender", "VARCHAR(10)"),
("Customer_Country", "VARCHAR(200)"),
("Product_ID", "INTEGER"),
("Product_Name", "VARCHAR(200)"),
("Selling_Price", "NUMERIC"),
("Quantity", "INTEGER")
]
create_table_in_postgres_db("db_name", "your_password", "Merch_Store_Electronics", "Electronic_Purchase_Table", e_purchases_columns)
#создаем в Merch_Store_Electronics таблицу Electronic_Product_Table
#определяем названия столбцов и типы данных
e_products_columns = [
("Product_ID", "INTEGER"),
("Product_name", "VARCHAR(200)"),
("Cost_price", "NUMERIC"),
("Selling_price", "NUMERIC")
]
create_table_in_postgres_db("db_name", "your_password", "Merch_Store_Electronics", "Electronic_Product_Table", e_products_columns)
# создаем в Merch_Store_Electronics таблицу customers_Table_F
#определяем названия столбцов и типы данных
e_customer_columns = [
("Customer_id", "INTEGER"),
("Customer_name", "VARCHAR(100)"),
("Country", "VARCHAR(200)"),
("Email", "VARCHAR(200)"),
("Gender", "VARCHAR(220)"),
("Date_of_birth", "TIMESTAMP")
]
create_table_in_postgres_db("db_name", "your_password", "Merch_Store_Electronics", "Customer_Table_E", e_customer_columns)
# создаем в Merch_Store_Electronics таблицу Fashion_Purchases_Table
#определяем названия столбцов и типы данных
f_purchases_columns = [
("Order_ID", "INTEGER"),
("Purchase_Date", "TIMESTAMP"),
("Customer_ID", "INTEGER"),
("Customer_Gender", "VARCHAR(10)"),
("Customer_Country", "VARCHAR(200)"),
("Product_ID", "INTEGER"),
("Product_Name", "VARCHAR(200)"),
("Selling_Price", "NUMERIC"),
("Quantity", "INTEGER")
]
create_table_in_postgres_db("db_name", "your_password", "Merch_Store_Fashion", "Fashion_Purchase_Table", f_purchases_columns)
#создаем таблицу Fashion_Product_Table
#определяем названия столбцов и типы данных
f_products_columns = [
("Product_ID", "INTEGER"),
("Product_name", "VARCHAR(200)"),
("Cost_price", "NUMERIC"),
("Selling_price", "NUMERIC")
]
create_table_in_postgres_db("db_name", "your_password", "Merch_Store_Fashion", "Fashion_Product_Table", f_products_columns)
# создаем в Merch_Store_Fashion таблицу customers_Table_F
#определяем названия столбцов и типы данных
f_customer_columns = [
("Customer_id", "INTEGER"),
("Customer_name", "VARCHAR(100)"),
("Country", "VARCHAR(200)"),
("Email", "VARCHAR(200)"),
("Gender", "VARCHAR(220)"),
("Date_of_birth", "TIMESTAMP")
]
create_table_in_postgres_db("db_name", "your_password", "Merch_Store_Fashion", "Customer_Table_F", f_customer_column
#загружаем данные в целевую таблицу
database_params = {
"dbname": "Merch_Store_Electronics",
"user": "db_name",
"password": "your_password",
"host": "host_server_name",
"port": "port number on which host_server_name is running"
}
cnxn = psycopg2.connect(**database_params)
cursor = cnxn.cursor()
destination_table = 'Electronic_Purchase_Table'
#перебираем каждую строку во фрейме данных и вставляем ее в таблицу
for _, row in electronic_purchases.iterrows():
insert_query = f"INSERT INTO {destination_table}(Order_ID, Purchase_Date, Customer_ID, \
Customer_Gender, Customer_Country, Product_ID, Product_Name, Selling_Price, Quantity)\
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s);"
cursor.execute(insert_query, tuple(row))
cnxn.commit()
#electronic_purchases — имя фрейма данных, в котором сохраняется csv-файл с купленной электроникой
#меняем его на имя фрейма данных с информацией, загружаемой в целевую PostgreSQL
cnxn.close()
Лучшая практика Apache Airflow — тестирование задач Airflow
Чтобы узнать, выполнится задача или нет, перед ее планированием рекомендуется протестировать задачи в контейнере воркера Airflow. Так вы при необходимости сможете выполнить отладку перед планированием /оркестрированием задачи с Airflow. Это лучшая практика. Чтобы избежать невыполненных задач или сломанных DAG в Airflow, рекомендуется протестировать задачу перед ее планированием.
Чтобы протестировать задачу Airflow, после написания этих DAG в терминале, в VS Code, пишем:
docker-compose up
Открываем другой терминал в VS Code и пишем:
docker ps
Этой командой мы входим в контейнер Docker, которым запускается экземпляр Airflow. Им выводятся различные идентификаторы контейнеров для воркера, планировщика и веб-сервера Airflow.
Чтобы войти в воркер обработки задач Airflow, пишем:
docker exec -it worker_id /bin/bash
Заменяем worker_id на идентификатор контейнера воркера, получаемый после запуска команды docker ps.
Чтобы посмотреть, к чему у контейнера воркера Airflow имеется доступ, пишем в терминале:
ls
Чтобы протестировать задачу DAG в контейнере, пишем в терминале так:
airflow tasks test dag_id task_id yyyy/mm/d
dag_id — идентификатор тестируемого dag, указанный в файле DAG при инстанцировании dag.
task_id — идентификатор задачи в тестируемом DAG.
yyyy/mm/d — формат записи даты. Используется прошлая дата. Например, сегодня 2023/11/29, значит, указываемая для теста дата — 2023/11/28.
Если в выводимом по завершении тестирования задачи сообщении обнаруживается недостающая зависимость, просматриваем список зависимостей для выполняемой задачи, которые видны контейнеру Airflow, этой строкой кода:
pip freeze
Если нужной зависимости в списке нет, переходим к файлу requirements.txt и добавляем ее туда, например pandas.
Затем запускаем в терминале:
docker-compose up - build
Если после запуска pip freeze для проверки списка зависимостей, которые видны контейнеру Airflow, при получении зависимость не найдена/отсутствует после тестирования задачи, мы видим зависимость в выведенном списке, тогда в новом терминале в VS Code вводим:
docker-compose down
Затем в Docker Desktop удаляем тома и контейнеры, которыми запускается Airflow, в терминале VS Code вводим:
docker-compose up - build
Что такое «docker-compose up»?
Это команда для считывания содержимого файла docker-compose.yaml. Применяется она, согласно официальной документации Docker, для сборки, создания, воссоздания, запуска и присоединения к контейнерам для службы. Этой командой агрегируется вывод каждого контейнера. Подробнее — в официальной документации.
Что такое «docker-compose up airflow-init»?
docker-compose up airflow-init применяется для инициализации базы метаданных Apache Airflow при первом использовании файла Docker Compose или при внесении изменений в ее конфигурацию.
Вот репозиторий GitHub.
Читайте также:
- Нововведения в Apache Airflow 2.0: смогут ли они удовлетворить текущие потребности инженерии данных
- Airflow и Kubernetes - лучшее решение для конвейеров данных Geoblink
- Как создать первый проект по инженерии данных: инкрементный подход. Часть 2
Читайте нас в Telegram, VK и Дзен
Перевод статьи Chibuokejuliet: END-TO-END DATA ENGINEERING PROJECT USING APACHE AIRFLOW, POSTGRES AND GCP





