
Базы данных PostgreSQL имеют преимущество в том, что подходят как для OLTP , так и для OLAP. Эта статья посвящена необходимым шагам, предпринимаемым при подготовке базы данных AWS Aurora PostgreSQL. Предоставляемые AWS базы данных Aurora несут в себе видоизмененные механизмы работы, и Aurora нацелена на повышение пропускной способности базы данных за счет устранения буфера логов в движке PostgreSQL. Это делает БД более оптимизированной под потребности масштабирования через стандартный сервис RDS PostgreSQL, предоставляемый AWS.
Создание базы данных
При создании базы данных через консоль AWS вы встретите множество опций, и ниже я привожу описание каждой в порядке их появления в интерфейсе Create Database.
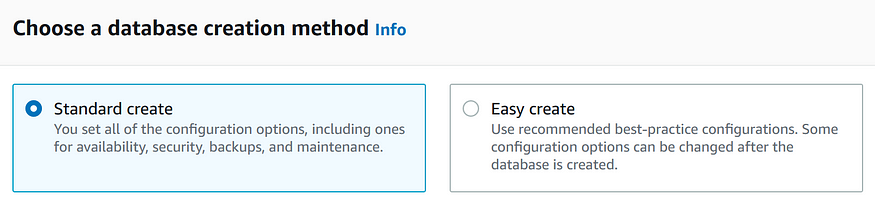
На этапе выбора способа создания базы данных вариант Standard дает больше контроля над доступным в этом процессе функционалом.
В нашем случае на этапе выбора движка мы указываем Aurora (PostgreSQL Compatible).

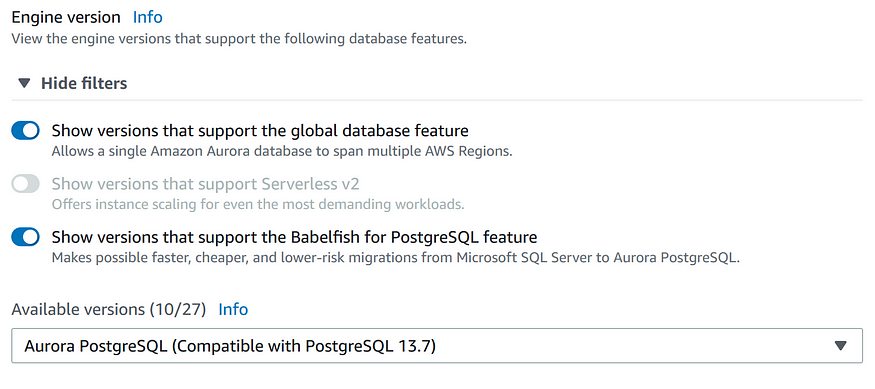
Существует множество версий движка PostgreSQL, поэтому рекомендуется предварительно изучить вопрос, чтобы выбрать подходящую. Остерегайтесь известных проблем с версиями, так как среди них в случае PostgreSQL есть и критические вроде дублирующихся первичных ключей. Для данного примера я выбрал PostgreSQL 13.7, являющуюся последней версией с поддержкой Babelfish.
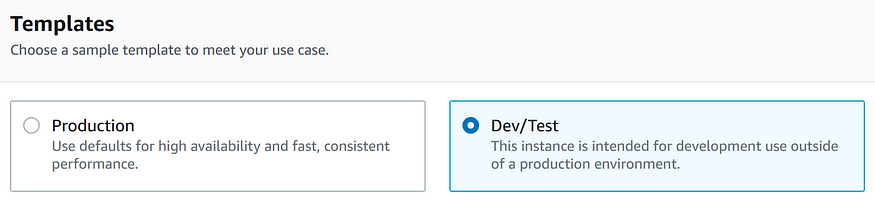
При выборе шаблона предлагается два варианта, ориентированных на Production и Dev/Test. Поскольку нас интересует разработка, я выбрал опцию Dev/Test.
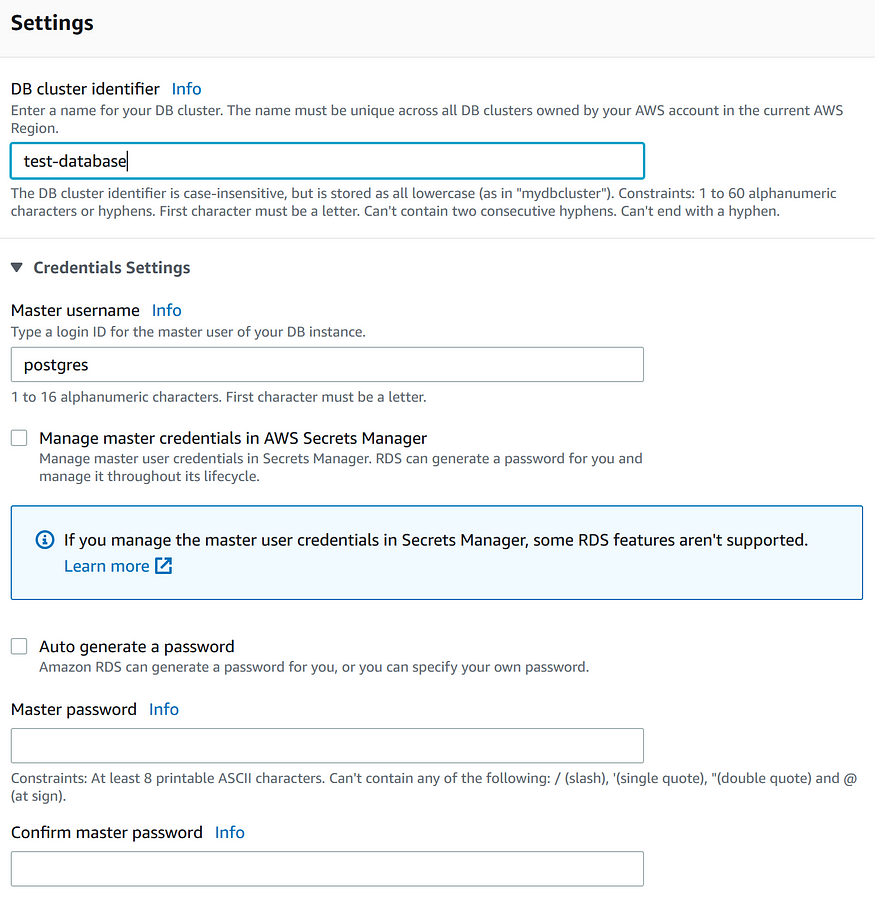
Следующий раздел посвящен настройкам идентификатора кластера БД и учетных данных. Идентификатор БД должен быть уникален для аккаунта AWS в конкретном регионе. Однако если позднее вы решите удалить кластер БД, то это имя инстанса можно будет заново использовать для создания другого кластера с тем же идентификатором.
Реплики инстансов будут иметь идентификатор с суффиксом: test-database-instance-1. В настройках учетных данных можно установить Master username и Master password. Для лучшей безопасности рекомендуется использовать имя, отличное от предустановленного “postgres”. Пароль можно сгенерировать автоматически, либо указать самому. В случае генерации после создания он будет доступен во вкладке деталей подключения инстанса базы данных.
Конфигурация инстанса определяет, сколько ресурсов должно выделяться для созданной базы данных. Вот три основных типа классов: Serverless, Memory optimized и Burstable. Классы Serverless — это предоставляемые по требованию автоматически масштабируемые ресурсы, где инстанс БД в случае прекращения использования автоматически закрывается и вновь запускается по запросу. Классы Memory optimized подходят для случаев, когда большие наборы данных требуется хранить в памяти для обработки. Классы Burstable обеспечивают базовую скорость CPU, но позволяют получать ее прирост на короткие промежутки времени.
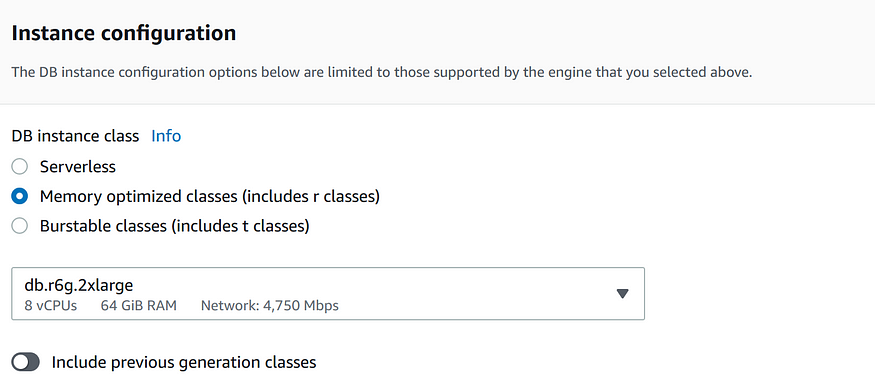
В разделе Availability и Durability можно выбирать, что должно создаваться в различных зонах доступности — Replica или Reader. Если вы создаете реплику, RDS в случае запланированного или нет отключения основного инстанса будет автоматически переключаться на нее.
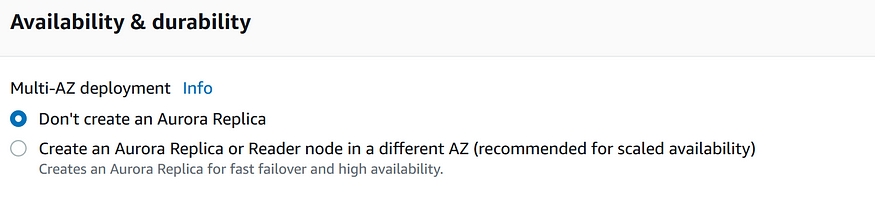
Следующий раздел связан с подключением. Здесь можно указывать, хотим ли мы, чтобы инстанс EC2 подключался при создании БД, а также тип Network и настройки межсетевого экрана VPC. Если вы не подключите инстанс EC2 на этой стадии, то сможете сделать это позднее, разрешив пропуск трафика через входящие/исходящие правила в группе безопасности VPC.
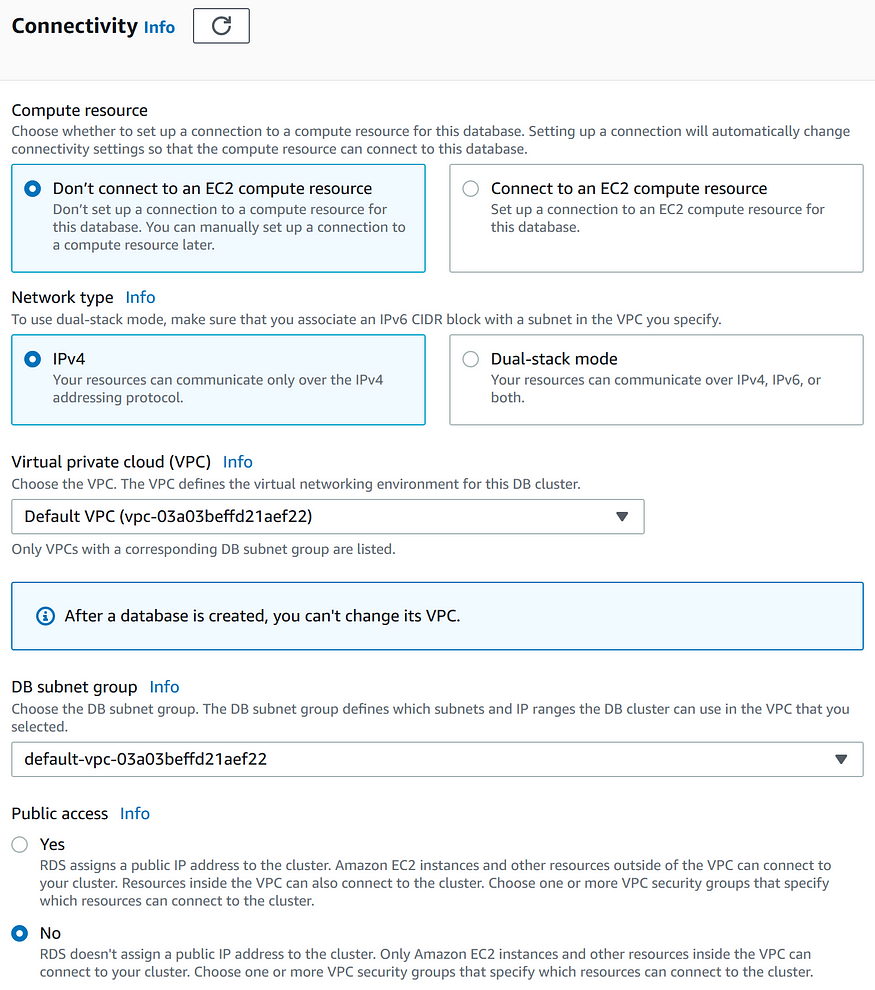
Правила группы безопасности могут разрешать/запрещать трафик по аналогии с записями межсетевого экрана. Здесь вы также можете указать, нужно ли создавать RDS Proxy. В разделе Additional configuration можно изменить порт базы данных, но здесь я оставил предустановленное значение для баз данных PostgreSQL, а именно 5432.
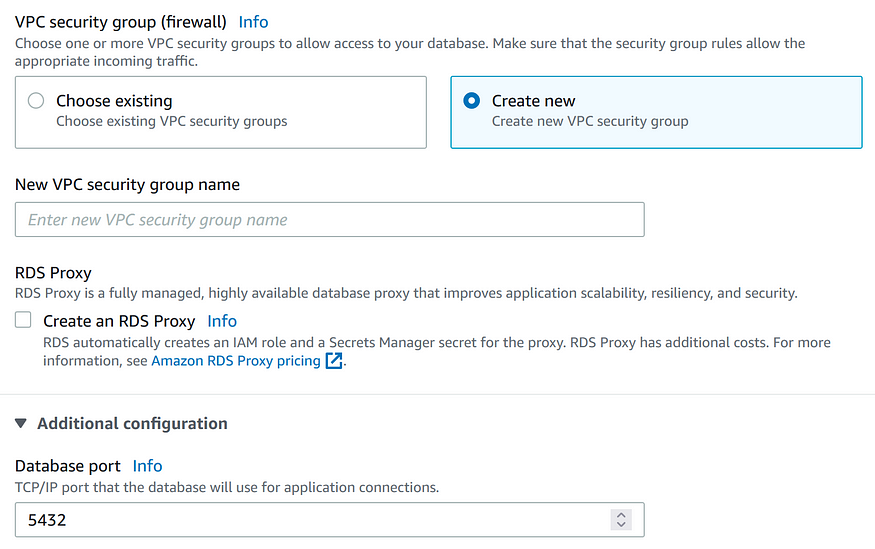
Если вы выбрали “Do not create replica”, то в разделе выше для вашего инстанса БД также будет доступна опция Availability zone (AZ). Если вы связываете этот инстанс БД с другими ресурсами AWS, то будет дешевле создать их в одной AZ, поскольку AWS берет плату за передачу каждого гигабайта данных между разными AZ.

Опция Babelfish полезна при переносе БД из Microsoft SQL.

Если вы хотите использовать для базы данных аутентификацию IAM или Kerberos, она указывается в разделе Database authentication.
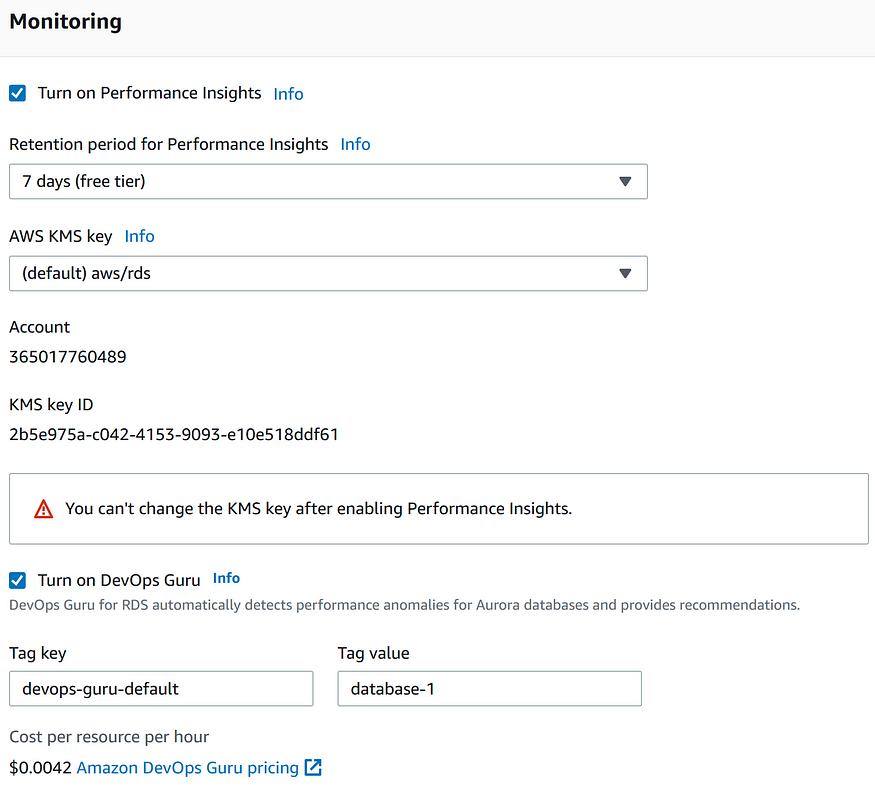
Раздел мониторинга содержит настройки Performance insights.
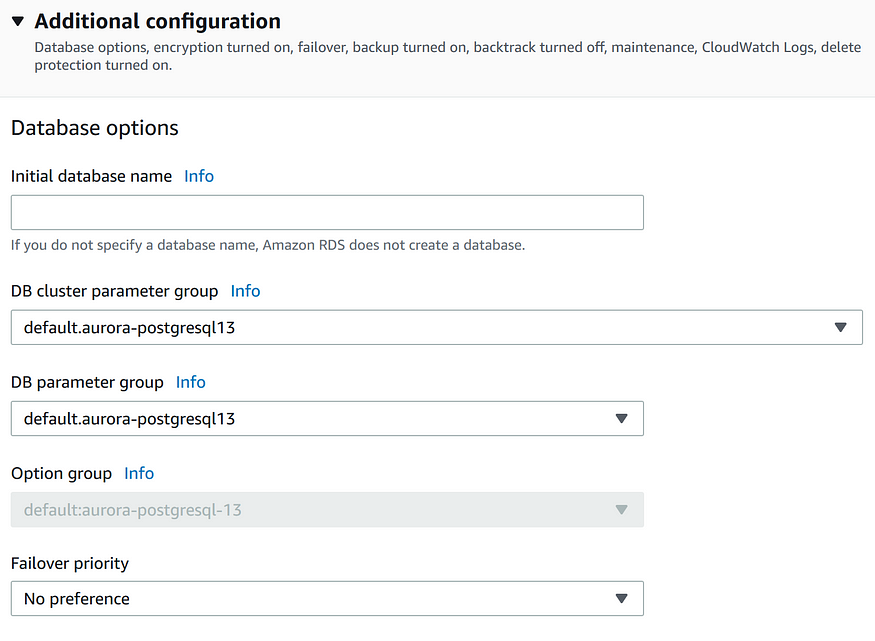
Этот раздел Additional configuration содержит ряд важных опций, таких как Initial database name, группы DB cluster и DB parameter, группа Option и fail-over priority. Имея опыт работы с PostgreSQL 13.7, я здесь заметил, что предустановленная группа параметров при активном использовании БД создает проблему, отражающуюся в исчерпании памяти операционной системы спустя определенный период работы. Эту проблему можно обойти, отредактировав параметры pg_stat_statements в группе параметров.
Раздел Backup позволяет настроить период хранения бэкапа.
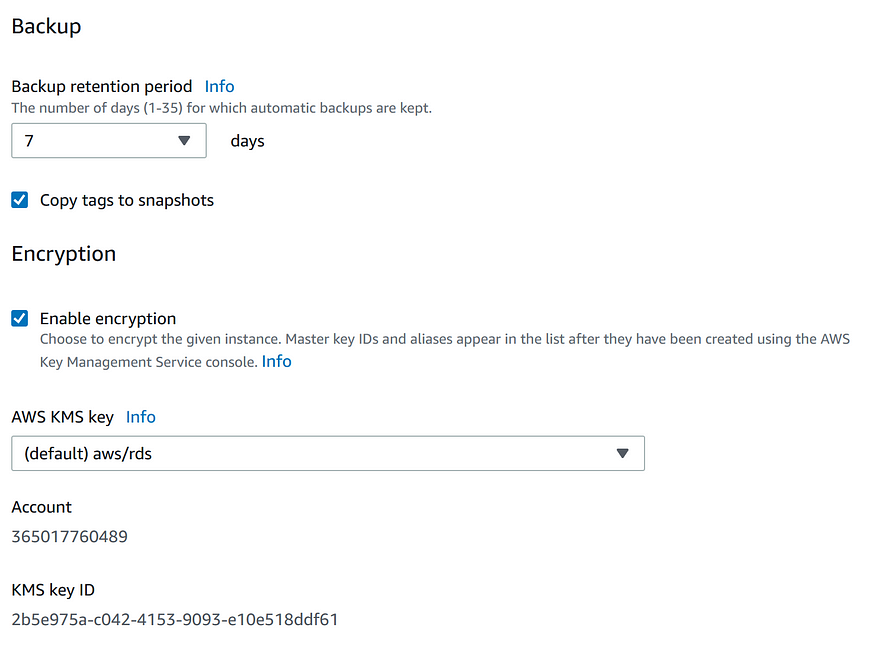
В следующем разделе содержатся настройки для экспорта логов, где можно выбирать типы логов, публикуемых в Amazon Cloudwatch Logs.
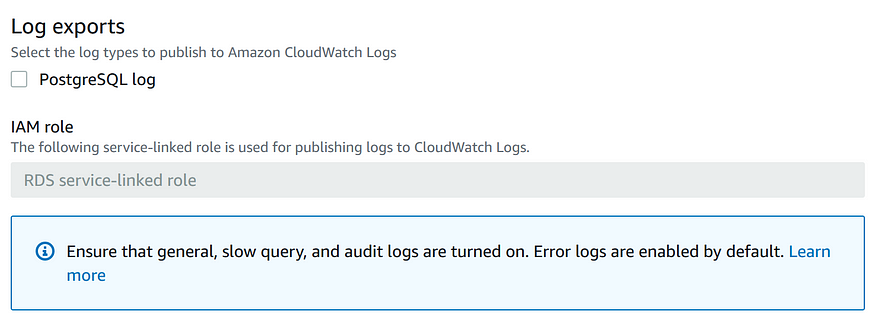
Если включить Deletion protection, то вы не сможете удалить БД из консоли AWS за одно действие, если только сначала не измените БД и не отключите защиту от удаления.
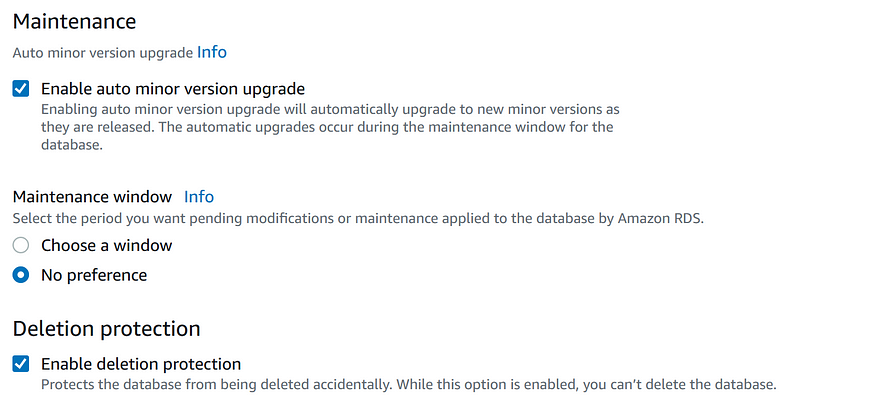
Вот и все опции создания БД, предоставляемые AWS Aurora PostgreSQL.
Читайте также:
- Доступная и масштабируемая 3-уровневая архитектура AWS
- Как запустить и использовать файловые системы с помощью Amazon FSx
- Все, что вам нужно знать о переходе на реляционную базу данных AWS
Читайте нас в Telegram, VK и Дзен
Перевод статьи Tharinda Aloka: Provisioning an AWS Aurora PostgreSQL Server and Monitoring it’s Performance





