
Инструментарий
- Apache Airflow
- Apache Kafka
- Cassandra
- MongoDB
- Docker
- Apache Zookeeper
- EmailOperator
- SlackWebhookOperator
Обзор
Сделаем конвейер данных, целиком оркестрируемый в Airflow. Сначала создадим тему Kafka, затем отправим сообщения, в которых в качестве записей содержатся электронная почта и одноразовый пароль OTP. Таким образом проиллюстрируем потоковую передачу данных в тему Kafka.
Далее получим эти данные из темы Kafka, вставим их в таблицу Cassandra и в коллекцию MongoDB и проверим наличие в них корректных данных. Если таковые имеются, отправим письмо на электронную почту и сообщение в Slack с адресом почты и одноразовым паролем OTP.
Это реальный проект валидации электронной почты. Отправку в тему Kafka потоковых записей, включая данные электронной почты и одноразового пароля OTP, проиллюстрируем с отправителем Kafka. Наличие почты и пароля определим с помощью получателя Kafka и проверки данных.
Службы как контейнеры Docker
Сначала создаем Dockerfile, для запуска всех служб как контейнеров Docker берем официальный образ Airflow и устанавливаем все необходимые библиотеки и пакеты в контейнер Airflow:
# В качестве базового образа берем «Apache Airflow 2.7.1»
FROM apache/airflow:2.7.1
# Переключаемся на пользователя «airflow»
USER airflow
# Устанавливаем «pip»
RUN curl -O 'https://bootstrap.pypa.io/get-pip.py' && \
python3 get-pip.py --user
# Устанавливаем библиотеки из «requirements.txt»
COPY requirements.txt /requirements.txt
RUN pip install --user -r /requirements.txt
В этом файле Dockerfile устанавливаются команда pip и, чтобы не получить потом ошибку импорта, все необходимые библиотеки файла requirements.txt. С помощью Dockerfile создается контейнер install-requirements.
Затем, следуя инструкциям, получаем файл docker-compose.yaml локально и меняем его перед запуском служб. В разделе служб добавляем такой контейнер:
install-requirements:
<<: *airflow-common
container_name: install-requirements
build:
context: .
volumes:
- ./requirements.txt:/requirements.txt
depends_on:
- postgres
- redis
networks:
- cassandra-kafka
Этим контейнером установятся все необходимые зависимости внутри контейнера Airflow. Теперь в разделе x-airflow-common добавляем параметры:
#Задаем время перезагрузки 30 сек. вместо 5 мин. по умолчанию
AIRFLOW__SCHEDULER__DAG_DIR_LIST_INTERVAL: 30
# Параметры ниже нужны для корректного использования «EmailOperator». Пояснения — во второй части.
AIRFLOW__SMTP__SMTP_HOST: 'smtp.gmail.com'
AIRFLOW__SMTP__SMTP_MAIL_FROM: 'sample_email@my_email.com'
AIRFLOW__SMTP__SMTP_USER: 'sample_email@my_email.com'
AIRFLOW__SMTP__SMTP_PASSWORD: 'your_password'
AIRFLOW__SMTP__SMTP_PORT: '587'
С одним файлом docker-compose.yaml будет проще, добавим в него и другие службы, все они запустятся одной командой:
zoo1:
image: confluentinc/cp-zookeeper:7.3.2
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_SERVER_ID: 1
ZOOKEEPER_SERVERS: zoo1:2888:3888
networks:
- kafka-network
- cassandra-kafka
kafka1:
image: confluentinc/cp-kafka:7.3.2
container_name: kafka1
ports:
- "9092:9092"
- "29092:29092"
environment:
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka1:19092,EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9092,DOCKER://host.docker.internal:29092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT,DOCKER:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"
KAFKA_BROKER_ID: 1
KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_AUTHORIZER_CLASS_NAME: kafka.security.authorizer.AclAuthorizer
KAFKA_ALLOW_EVERYONE_IF_NO_ACL_FOUND: "true"
networks:
- kafka-network
- cassandra-kafka
kafka2:
image: confluentinc/cp-kafka:7.3.2
container_name: kafka2
ports:
- "9093:9093"
- "29093:29093"
environment:
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka2:19093,EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9093,DOCKER://host.docker.internal:29093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT,DOCKER:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"
KAFKA_BROKER_ID: 2
KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_AUTHORIZER_CLASS_NAME: kafka.security.authorizer.AclAuthorizer
KAFKA_ALLOW_EVERYONE_IF_NO_ACL_FOUND: "true"
networks:
- kafka-network
- cassandra-kafka
kafka3:
image: confluentinc/cp-kafka:7.3.2
container_name: kafka3
ports:
- "9094:9094"
- "29094:29094"
environment:
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka3:19094,EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9094,DOCKER://host.docker.internal:29094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT,DOCKER:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"
KAFKA_BROKER_ID: 3
KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_AUTHORIZER_CLASS_NAME: kafka.security.authorizer.AclAuthorizer
KAFKA_ALLOW_EVERYONE_IF_NO_ACL_FOUND: "true"
networks:
- kafka-network
- cassandra-kafka
kafka-connect:
image: confluentinc/cp-kafka-connect:7.3.2
container_name: kafka-connect
ports:
- "8083:8083"
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka1:19092,kafka2:19093,kafka3:19094
CONNECT_REST_PORT: 8083
CONNECT_GROUP_ID: compose-connect-group
CONNECT_CONFIG_STORAGE_TOPIC: compose-connect-configs
CONNECT_OFFSET_STORAGE_TOPIC: compose-connect-offsets
CONNECT_STATUS_STORAGE_TOPIC: compose-connect-status
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.storage.StringConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.storage.StringConverter
CONNECT_INTERNAL_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_INTERNAL_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_REST_ADVERTISED_HOST_NAME: 'kafka-connect'
CONNECT_LOG4J_ROOT_LOGLEVEL: 'INFO'
CONNECT_LOG4J_LOGGERS: 'org.apache.kafka.connect.runtime.rest=WARN,org.reflections=ERROR'
CONNECT_PLUGIN_PATH: '/usr/share/java,/usr/share/confluent-hub-components'
networks:
- kafka-network
- cassandra-kafka
schema-registry:
image: confluentinc/cp-schema-registry:7.3.2
container_name: schema-registry
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: kafka1:19092,kafka2:19093,kafka3:19094
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_LISTENERS: http://0.0.0.0:8081
networks:
- kafka-network
- cassandra-kafka
kafka-ui:
container_name: kafka-ui
image: provectuslabs/kafka-ui:latest
ports:
- 8888:8080
depends_on:
- kafka1
- kafka2
- kafka3
- schema-registry
- kafka-connect
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: PLAINTEXT://kafka1:19092,PLAINTEXT_HOST://kafka1:19092
KAFKA_CLUSTERS_0_SCHEMAREGISTRY: http://schema-registry:8081
KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME: connect
KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS: http://kafka-connect:8083
DYNAMIC_CONFIG_ENABLED: 'true'
networks:
- kafka-network
- cassandra-kafka
cassandra:
image: cassandra:latest
container_name: cassandra
hostname: cassandra
ports:
- 9042:9042
environment:
- MAX_HEAP_SIZE=512M
- HEAP_NEWSIZE=100M
- CASSANDRA_USERNAME=cassandra
- CASSANDRA_PASSWORD=cassandra
volumes:
- ./:/home
- cassandra-data:/var/lib/cassandra
networks:
- cassandra-kafka
mongo:
image: mongo
container_name: mongo
restart: always
environment:
MONGO_INITDB_ROOT_USERNAME: root
MONGO_INITDB_ROOT_PASSWORD: root
networks:
- cassandra-kafka
mongo-express:
image: mongo-express
container_name: mongo-express
restart: always
ports:
- 8082:8081
environment:
ME_CONFIG_MONGODB_ADMINUSERNAME: root
ME_CONFIG_MONGODB_ADMINPASSWORD: root
ME_CONFIG_MONGODB_URL: mongodb://root:root@mongo:27017/
networks:
- cassandra-kafka
volumes:
cassandra-data:
postgres-db-volume:
networks:
kafka-network:
driver: bridge
cassandra-kafka:
external: true
Дополнительные службы:
- Kafka;
- Zookeeper;
- MongoDB;
- Cassandra;
- Kafka UI;
- Mongo Express.
Для всех служб добавляем внешнюю сеть cassandra-kafka:
docker network create cassandra-kafka
Добавив новые службы и параметры в стандартный Airflow docker-compose, запускаем контейнеры. Этой командой инициируем Airflow:
docker compose up airflow-init
Затем запускаем все службы:
docker compose up -d --build
Этой командой создается контейнер на основе Dockerfile и запускаются все остальные службы. Следуя инструкциям выше, получим каталог dags, в который поместим все скрипты, в том числе сам скрипт DAG. Все такие скрипты — это задачи Airflow DAG.
Создание темы Kafka
Создаем тему Kafka. Если она уже имеется, в скрипте возвращается соответственный результат:
from confluent_kafka.admin import AdminClient, NewTopic
import logging
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
admin_config = {
'bootstrap.servers': 'kafka1:19092,kafka2:19093,kafka3:19094',
'client.id': 'kafka_admin_client'
}
admin_client = AdminClient(admin_config)
def kafka_create_topic_main():
"""Checks if the topic email_topic exists or not. If not, create the topic."""
topic_name = 'email_topic'
existing_topics = admin_client.list_topics().topics
if topic_name in existing_topics:
return "Exists"
# Создаем новую тему
new_topic = NewTopic(topic_name, num_partitions=1, replication_factor=3)
admin_client.create_topics([new_topic])
return "Created"
if __name__ == "__main__":
result = kafka_create_topic_main()
logger.info(result)
Используем серверы начальной загрузки, определенные в файле docker-compose, а client.id определяем как угодно. Если тема уже имеется, скриптом возвращается “Exists”, если создана только что — “Created”. Воспользуемся этой информацией во второй части при создании BranchPythonOperator. Определяем коэффициент репликации 3 — по числу брокеров Kafka как контейнеров.
Скоро сделаем два DummyOperator — в зависимости от результата этой задачи при создании Airflow DAG. Назовем тему email_topic. Проверяем ее наличие с помощью пользовательского интерфейса Kafka:
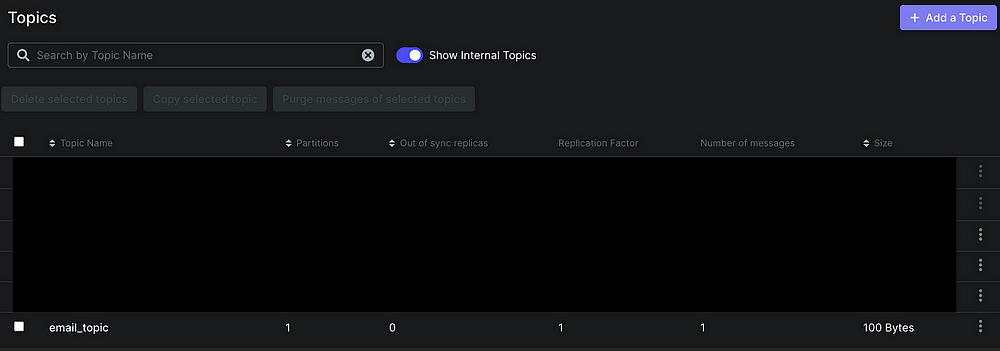
Отправитель Kafka
Чтобы проиллюстрировать потоковую передачу данных в тему Kafka, создадим также отправитель Kafka:
import logging
from confluent_kafka import Producer
import time
# Конфигурируем логгер
logging.basicConfig(level=logging.INFO, format='%(asctime)s [%(levelname)s] %(message)s')
logger = logging.getLogger(__name__)
class KafkaProducerWrapper:
def __init__(self, bootstrap_servers):
"""
Initializes the Kafka producer with the given bootstrap servers.
"""
self.producer_config = {
'bootstrap.servers': bootstrap_servers
}
self.producer = Producer(self.producer_config)
def produce_message(self, topic, key, value):
"""
Produces a message to the specified Kafka topic with the given key and value.
"""
self.producer.produce(topic, key=key, value=value)
self.producer.flush()
def kafka_producer_main():
bootstrap_servers = 'kafka1:19092,kafka2:19093,kafka3:19094'
kafka_producer = KafkaProducerWrapper(bootstrap_servers)
topic = "email_topic"
key = "sample_email@my_email.com"
value = "1234567"
start_time = time.time()
try:
while True:
kafka_producer.produce_message(topic, key, value)
logger.info("Produced message")
elapsed_time = time.time() - start_time
if elapsed_time >= 20: # Остановка через 20 секунд
break
time.sleep(5) # Ожидание в течение пяти секунд между отправкой сообщений
except KeyboardInterrupt:
logger.info("Received KeyboardInterrupt. Stopping producer.")
finally:
kafka_producer.producer.flush()
logger.info("Producer flushed.")
if __name__ == "__main__":
kafka_producer_main()
Этим скриптом в email_topic отправляются сообщения с ключом sample_email@my_email.com и значением 1234567. Значение — одноразовый пароль, а ключ — электронная почта, отправляемые в тему Kafka. Этот процесс продолжается в течение 20 секунд. Временной период меняется в соответствии с вариантом использования.
Отправка данных в email_topic проверяется и вручную, с помощью пользовательского интерфейса Kafka:
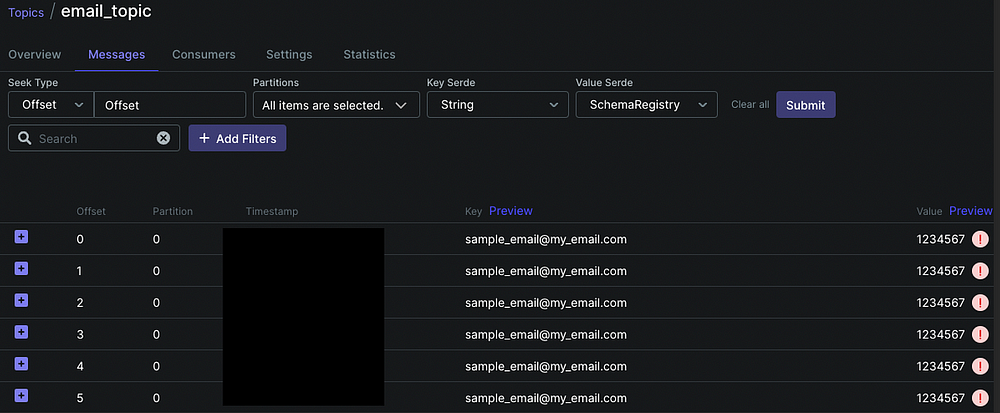
Получатель Kafka для Cassandra
Создав тему Kafka и отправив сообщения в email_topic, получим их в Cassandra и MongoDB.
Импортировав все библиотеки, подключаемся к Cassandra и выполняем необходимые команды:
class CassandraConnector:
def __init__(self, contact_points):
self.cluster = Cluster(contact_points)
self.session = self.cluster.connect()
self.create_keyspace()
self.create_table()
def create_keyspace(self):
self.session.execute("""
CREATE KEYSPACE IF NOT EXISTS email_namespace
WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 1}
""")
def create_table(self):
self.session.execute("""
CREATE TABLE IF NOT EXISTS email_namespace.email_table (
email text PRIMARY KEY,
otp text
)
""")
def insert_data(self, email, otp):
self.session.execute("""
INSERT INTO email_namespace.email_table (email, otp)
VALUES (%s, %s)
""", (email, otp))
def shutdown(self):
self.cluster.shutdown()
В этом классе сначала подключаемся к серверу Cassandra, затем создаем пространство ключей email_namespace и таблицу email_table. Полученные в теме Kafka сообщения вставляются в созданную таблицу:
def fetch_and_insert_messages(kafka_config, cassandra_connector, topic, run_duration_secs):
consumer = Consumer(kafka_config)
consumer.subscribe([topic])
start_time = time.time()
try:
while True:
elapsed_time = time.time() - start_time
if elapsed_time >= run_duration_secs:
break
msg = consumer.poll(1.0)
if msg is None:
continue
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
logger.info('Reached end of partition')
else:
logger.error('Error: {}'.format(msg.error()))
else:
email = msg.key().decode('utf-8')
otp = msg.value().decode('utf-8')
query = "SELECT email FROM email_namespace.email_table WHERE email = %s"
existing_email = cassandra_connector.session.execute(query, (email,)).one()
if existing_email:
logger.warning(f'Skipped existing email: Email={email}')
else:
cassandra_connector.insert_data(email, otp)
logger.info(f'Received and inserted: Email={email}, OTP={otp}')
except KeyboardInterrupt:
logger.info("Received KeyboardInterrupt. Closing consumer.")
finally:
consumer.close()
Этой функцией в течение предопределенного периода времени — здесь это 30 секунд — получаются все входящие сообщения и ими заполняется соответствующая таблица Cassandra. Уже имеющиеся в таблице данные пропускаются и логируются в разделе логов Airflow:
def kafka_consumer_cassandra_main():
cassandra_connector = CassandraConnector(['cassandra'])
cassandra_connector.create_keyspace()
cassandra_connector.create_table()
kafka_config = {
'bootstrap.servers': 'kafka1:19092,kafka2:19093,kafka3:19094',
'group.id': 'cassandra_consumer_group',
'auto.offset.reset': 'earliest'
}
topic = 'email_topic'
run_duration_secs = 30
fetch_and_insert_messages(kafka_config, cassandra_connector, topic, run_duration_secs)
cassandra_connector.shutdown()
Воспользуемся этой функцией для задачи Airflow. В ней применяются практически все созданные нами до этого момента методы. После подключения к серверу Cassandra функцией создадутся пространство ключей и таблица.
После того как сообщения в email_topic получены, отсутствующие вставляются в таблицу Cassandra:

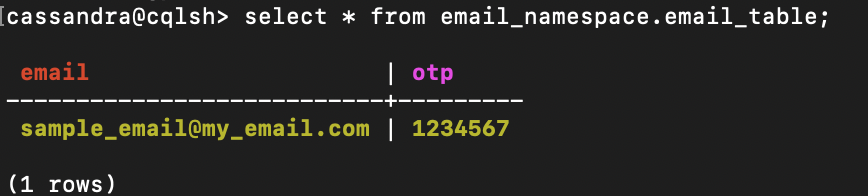
Проверяем наличие данных вручную, по очереди выполняя такие команды:
docker exec -it cassandra /bin/bash/
cqlsh -u cassandra -p cassandra
select * from email_namespace.email_table;
Получатель Kafka для MongoDB
Подключимся к MongoDB и вставим входящие сообщения в соответственную коллекцию.
Импортировав все библиотеки, подключаемся к MongoDB и выполняем необходимые команды:
class MongoDBConnector:
def __init__(self, mongodb_uri, database_name, collection_name):
self.client = MongoClient(mongodb_uri)
self.db = self.client[database_name]
self.collection_name = collection_name
def create_collection(self):
# Проверяем наличие коллекции
if self.collection_name not in self.db.list_collection_names():
self.db.create_collection(self.collection_name)
logger.info(f"Created collection: {self.collection_name}")
else:
logger.warning(f"Collection {self.collection_name} already exists")
def insert_data(self, email, otp):
document = {
"email": email,
"otp": otp
}
self.db[self.collection_name].insert_one(document)
def close(self):
self.client.close()
Явно создавать новую базу данных не нужно, для MongoDB — в отличие от Cassandra — она создается «на лету»:
class KafkaConsumerWrapperMongoDB:
def __init__(self, kafka_config, topics):
self.consumer = Consumer(kafka_config)
self.consumer.subscribe(topics)
def consume_and_insert_messages(self):
start_time = time.time()
try:
while True:
elapsed_time = time.time() - start_time
if elapsed_time >= 30:
break
msg = self.consumer.poll(1.0)
if msg is None:
continue
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
logger.info('Reached end of partition')
else:
logger.warning('Error: {}'.format(msg.error()))
else:
email = msg.key().decode('utf-8')
otp = msg.value().decode('utf-8')
existing_document = self.db[self.collection_name].find_one({"email": email, "otp": otp})
if existing_document:
logger.warning(f"Document with Email={email}, OTP={otp} already exists in the collection.")
else:
mongodb_connector.insert_data(email, otp)
logger.info(f'Received and inserted: Email={email}, OTP={otp}')
except KeyboardInterrupt:
logger.info("Received KeyboardInterrupt. Closing consumer.")
finally:
mongodb_connector.close()
def close(self):
self.consumer.close()
Этим классом в течение предопределенного периода времени — здесь это 30 секунд — получаются все входящие сообщения и ими заполняется соответственная таблица MongoDB, уже имеющиеся в таблице данные пропускаются:
def kafka_consumer_mongodb_main():
mongodb_connector.create_collection()
kafka_config = {
'bootstrap.servers': 'kafka1:19092,kafka2:19093,kafka3:19094',
'group.id': 'consumer_group',
'auto.offset.reset': 'earliest'
}
topics = ['email_topic']
kafka_consumer = KafkaConsumerWrapperMongoDB(kafka_config, topics)
kafka_consumer.consume_and_insert_messages()
Воспользуемся этой функцией для задачи Airflow. В ней применяются практически все созданные нами до этого момента методы и классы. После подключения к серверу MongoDB функцией создастся коллекция.
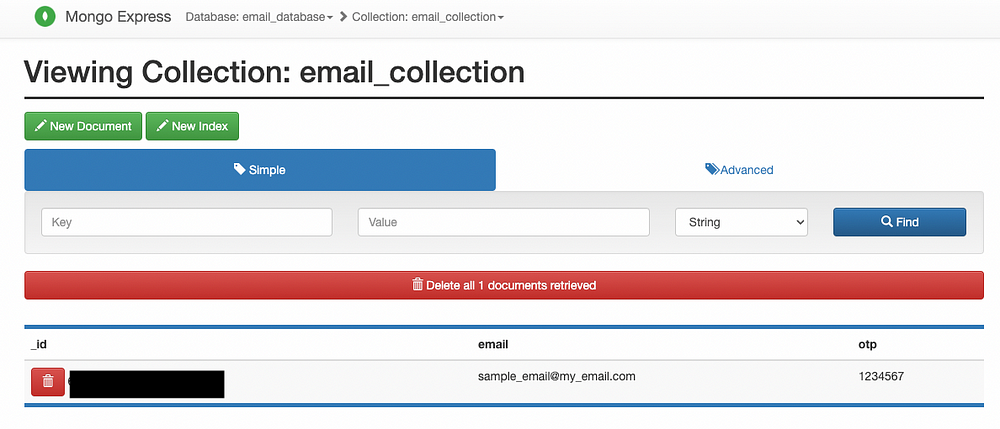
После того как сообщения в email_topic получены, отсутствующие вставляются в коллекцию MongoDB.
Проверяем наличие данных вручную с помощью Mongo Express:
Мы проиллюстрировали потоковую передачу данных с отправителем Kafka и получили сообщения в email_topic для Cassandra и MongoDB. Во второй части проверим корректность данных для них, отправим письмо на электронную почту и сообщение в Slack. В конце дадим пояснение всего Airflow DAG.
Читайте также:
- Проект инженерии данных «от и до» с Apache Airflow, Postgres и GCP
- Нововведения в Apache Airflow 2.0: смогут ли они удовлетворить текущие потребности инженерии данных
- Airflow и Kubernetes - лучшее решение для конвейеров данных Geoblink
Читайте нас в Telegram, VK и Дзен
Перевод статьи Dogukan Ulu: Data Engineering End-to-End Project — Part 1 — Airflow, Kafka, Cassandra, MongoDB, Docker, EmailOperator, SlackWebhookOperator





