
В процессе глубокого обучения моделей МО локальная отладка не всегда представляется возможной или целесообразной. Речь идет о тех случаях, когда отладка требует привлечения GPU/максимальных объемов вычислительных ресурсов, обращения к данным, отсутствующим на компьютере, или доступа к распределенной многоузловой среде обучения.

Занимаясь отладкой задач обучения в облаке, многие инженеры МО многократно выполняют инструкции print для устранения неполадок. Однако добавление print в код для определения возможных мест ошибок и перезапуск удаленного выполнения могут оказаться неэффективными и времязатратными мерами.
Есть один способ, позволяющий преодолеть эти ограничения. Он состоит в подключении визуального отладчика к удаленной задаче обучения.
В предлагаемом руководстве мы реализуем это решение с помощью VSCode на примере простого рабочего процесса обучения Flyte, выполняемом в локальном кластере Kubernetes. Данный обучающий материал не требует доступа к каким-либо облачным ресурсам. Изучаемый метод одинаково работает в управляемом облачном кластере Kubernetes, таком как GKE, или без Kubernetes при наличии возможности перенаправить порт сервиса на localhost ноутбука, например через ssh с виртуальной машины GCE/EC2.
Настройка
Создание локального кластера Kubernetes
Используя k3d, создаем локальный кластер Kubernetes. Кроме того, создаем локальный реестр Docker-образов, доступный для кластера:
k3d registry create registry.localhost --port 6000
k3d cluster create -p "30081:30081@server:0:direct" -p "30084:30084@server:0:direct" --no-lb --k3s-arg '--no-deploy=traefik' --k3s-arg '--no-deploy=servicelb' --registry-use k3d-registry.localhost:6000 sandbox
Примечание. Мы перенаправили порты 30081 и 30084. В дальнейшем это потребуется для доступа к движку оркестровки рабочих процессов MLOps.
Развертывание движка оркестровки рабочих процессов MLOps
В руководстве применяется платформа оркестровки рабочих процессов Kubernetes под названием Flyte. Она 1) полностью с открытым ПО; 2) прошла масштабное тестирование в Lyft (первоначальный создатель) и Spotify; 3) на мой взгляд, самый мощный и наиболее развитый инструмент из имеющихся аналогов.
Устанавливаем Flyte в созданный локальный кластер (руководство по установке helm):
helm repo add flyte https://flyteorg.github.io/flyte
helm repo update
helm install -n flyte flyte-deps flyteorg/flyte-deps --create-namespace -f https://raw.githubusercontent.com/flyteorg/flyte/master/charts/flyte-deps/values-sandbox.yaml --set minio.service.type=NodePort --set contour.envoy.service.type=NodePort
helm install -n flyte -f https://raw.githubusercontent.com/flyteorg/flyte/master/charts/flyte-core/values-sandbox.yaml --create-namespace flyte flyte/flyte-core
Выполнение команд helm install может занять одну минуту. Наблюдать за процессом исполнения можно с помощью watch kubectl --namespace flyte get pods, где watch необязателен. В конечном итоге должны запуститься все поды в пространстве имен flyte. Подождите пару минут, пока не исчезнут все ошибки типа Init:Error и Init:CrashLoopBackOff:
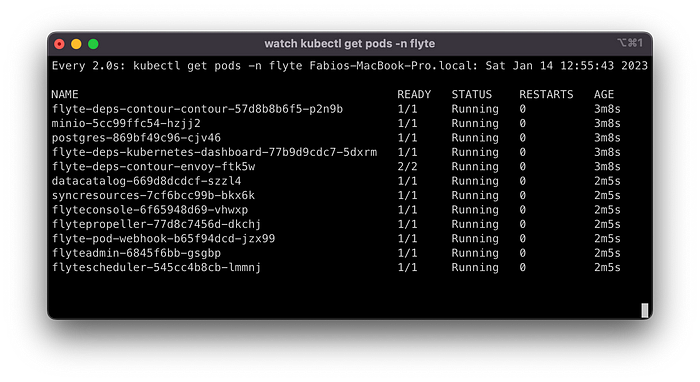
На данном этапе интерфейс Flyte-Console должен быть доступен по адресу http://localhost:30081/console (напоминаем, что этот порт был перенаправлен во время создания кластера):
В текущей рабочей директории создаем конфигурационный файл flytekit.config:
[platform]
url = localhost:30081
insecure = True
Удаленная отладка
Создание рабочего процесса для отладки
Создадим рабочий процесс, который подготавливает набор данных, обучает модель и оценивает ее качество. В данном примере используется классификатор случайного леса для набора данных Iris (пер. ирис):
import logging
from typing import Tuple
import joblib
import pandas as pd
from flytekit import task, workflow
from flytekit.types import schema # noqa: F401
from flytekit.types.file import FlyteFile
from sklearn import datasets, metrics
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
logger = logging.getLogger(__name__)
@task(cache=True, cache_version="1.0")
def preprocess_data() -> Tuple[pd.DataFrame, pd.DataFrame, pd.DataFrame, pd.DataFrame]:
"""Предварительная обработка набора данных iris"""
iris = datasets.load_iris()
data = pd.DataFrame({
'sepal length':iris.data[:,0],
'sepal width':iris.data[:,1],
'petal length':iris.data[:,2],
'petal width':iris.data[:,3],
'species':iris.target
})
X = data[['sepal length', 'sepal width', 'petal length', 'petal width']] # Случайные признаки
y = data[['species']] # Labels
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
return X_train, X_test, y_train, y_test
@task
def train(X_train: pd.DataFrame, y_train: pd.DataFrame) -> FlyteFile:
"""Обучение модели"""
clf=RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train['species'])
joblib.dump(clf, out_path := "cls.joblib")
return FlyteFile(path=out_path)
@task
def eval(model: FlyteFile, X_test: pd.DataFrame, y_test: pd.DataFrame) -> float:
"""Оценка модели"""
model.download()
clf = joblib.load(model.path)
y_pred=clf.predict(X_test)
accuracy = metrics.accuracy_score(y_test, y_pred)
logging.info(f"Accuracy = {accuracy}")
return float(accuracy)
@workflow
def wf() -> float:
"""Предварительная обработка набора данных iris, обучение и оценка классификатора"""
X_train, X_test, y_train, y_test = preprocess_data()
model = train(X_train=X_train, y_train=y_train)
return eval(model=model, X_test=X_test, y_test=y_test)
if __name__ == "__main__":
print(f"Accuracy = {wf()}")
Во Flyte с помощью декоратора @task вы определяете конкретные шаги в конвейере обучения, а посредством декоратора @workflow — взаимосвязи между ними. (Ссылка на руководство по началу работы с Flyte).
Устанавливаем требуемые пакеты и библиотеки с помощью pip install flytekit scikit-learn pandas и локально запускаем рабочий процесс:
❯ python workflow.py
Accuracy = 0.9111111111111111
Очевидно, что этот рабочий процесс не требует облачных ресурсов. Однако ради целей данного руководства представим, что он обучает большую модель глубокого обучения, которая в них нуждается. По этой причине выполняем рабочий процесс в кластере Kubernetes:
pyflyte run --remote workflow.py wf
Команда возвращает ссылку, перейдя по которой, можно увидеть граф рабочего процесса в Flyte Console:
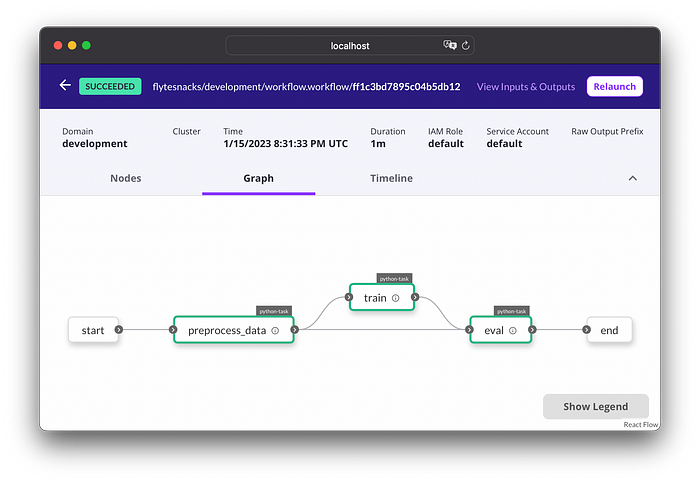
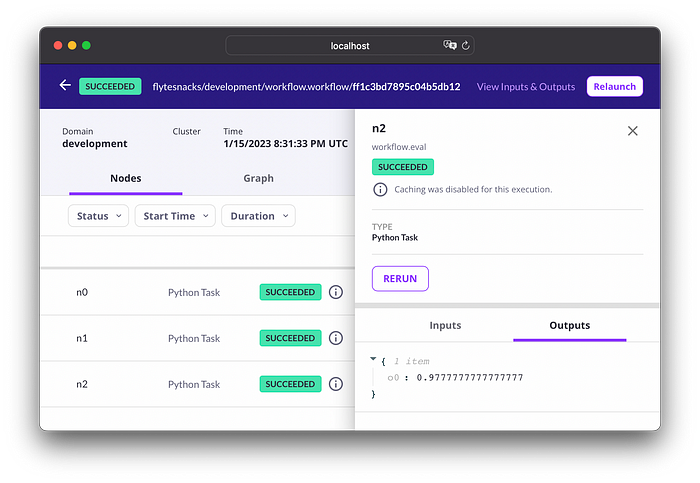
С помощью следующей команды можно узнать, где выполнялось обучение, и увидеть поды, соответствующие задачам:
❯ kubectl get pods --namespace flytesnacks-development
flytesnacks — это проект песочницы по умолчанию, а development — домен по умолчанию.
Установка отладчика
Для подключения визуального отладчика к удаленному процессу обучения с помощью VSCode применяется библиотека Microsoft debugpy.
Предустановленный Docker-образ для задач Flyte не содержит эту библиотеку. Поэтому создаем собственный образ, наследующий от образа задачи по умолчанию:
FROM ghcr.io/flyteorg/flytekit:py3.8-1.2.5 # Образ, используемый задачами flyte по умолчанию
RUN pip install debugpy
Создаем Dockerfile и загружаем образ в имеющийся локальный реестр Docker-образов:
docker build -t localhost:6000/task-image:latest .
docker push localhost:6000/task-image:latest
Подготовим рабочий процесс обучения для подключения визуального отладчика. Для этого запускаем сервер debugpy (на порту по умолчанию 5678) и устанавливаем точку останова debugpy, например в задаче обучения:
@task
def train(X_train: pd.DataFrame, y_train: pd.DataFrame) -> FlyteFile:
"""Обучение модели"""
import debugpy # new
debugpy.listen(("0.0.0.0", 5678)) # new
debugpy.wait_for_client() # new
debugpy.breakpoint() # new
logger.warning("Debugging in the cluster") # new
clf=RandomForestClassifier(n_estimators=100)
Теперь подготовим VSCode для подключения его визуального отладчика к удаленной задаче обучения. Для этого создаем конфигурационный файл .launch.json:
Нажимаем на Run and Debug (Запуск и Отладка):
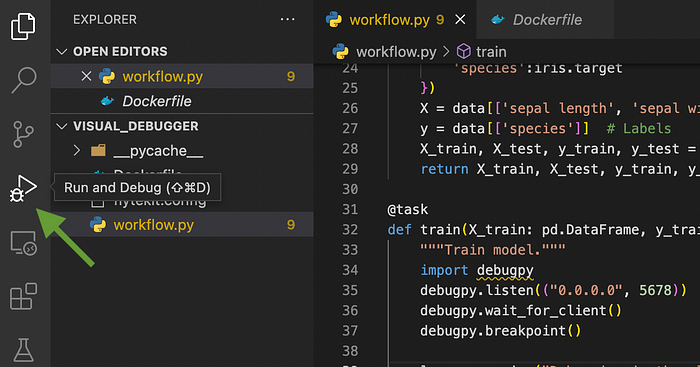
Далее нажимаем на create a launch.json file (создать файл launch.json):
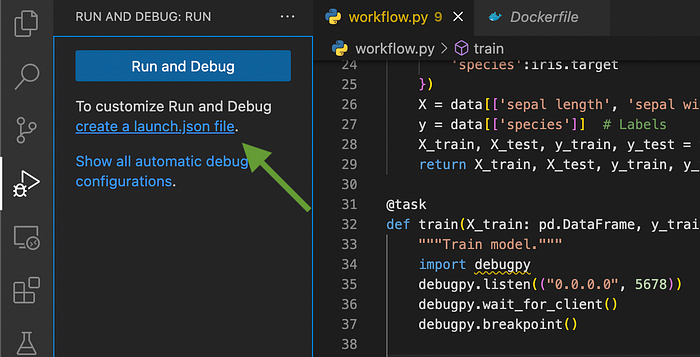
Выбираем Remote Attach (Удаленное подключение), а также подтверждаем localhost и порт по умолчанию 5678:
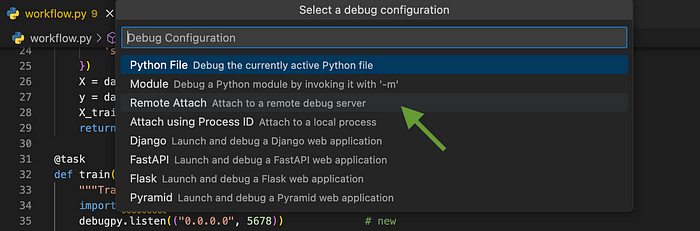
В результате .launch.json приобретает следующий вид:
"version": "0.2.0",
"configurations": [
{
"name": "Python: Remote Attach",
"type": "python",
"request": "attach",
"connect": {
"host": "localhost",
"port": 5678
},
"pathMappings": [
{
"localRoot": "${workspaceFolder}",
"remoteRoot": "."
}
],
"justMyCode": true
}
]
}
Примечание. Для полноты изучения темы стоит познакомиться с расширением Google VSCode под названием Cloud Code, которое занимается перенаправлением портов на localhost. Однако оно основано на устаревшем пакете ptvsd, предшествующем debugpy. Кроме того, данное расширение работает только с Kubernetes. Это означает, что оно не будет работать при перенаправлении портов сервера отладки, например через ssh с виртуальной машины.
Подключение визуального отладчика
Снова запускаем рабочий процесс. На этот раз используем образ, содержащий зависимость debugpy:
pyflyte run --remote --image k3d-registry.localhost:6000/task-image:latest workflow.py wf
Примечание. К тегу образа добавляется префикс k3d-. Эта необходимость обусловлена особенностями работы k3d с локальными реестрами образов.
Перейдя по ссылке для запуска, возвращаемой pyflyte run, вы увидите, что результат задачи preprocess_data извлечен из кеша Flyte. Задача train выполняется и ожидает подключения к серверу debugpy:
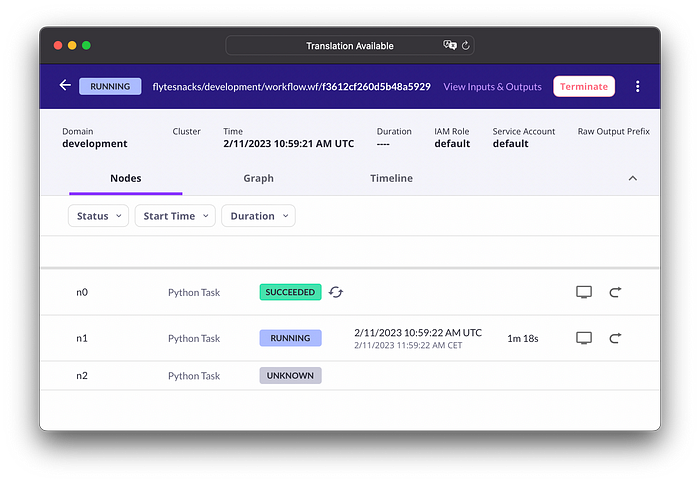
Получаем имя пода, выполняющего задачу, после того как он переходит в состояние выполнения:
❯ kubectl get pods --namespace flytesnacks-development
NAME READY STATUS RESTARTS AGE
f3612cf260d5b48a5929-n1-0 1/1 Running 0 3m8s
Перенаправляем порт сервера debugpy, работающего на порту 5678, на localhost:
❯ kubectl --namespace flytesnacks-development port-forward pod/f3612cf260d5b48a5929-n1-0 5678:5678
В пункте меню VSCode Run and Debug нажимаем стрелку запуска Python: Remote Attach:
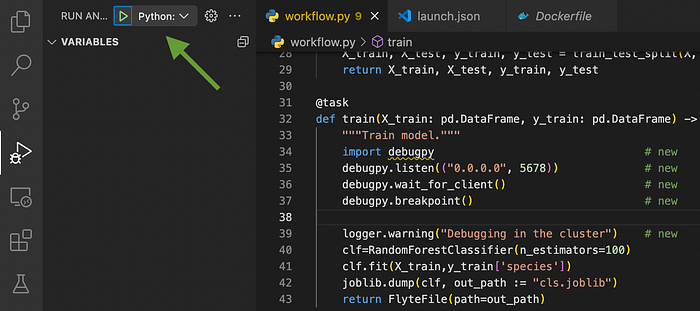
Визуальный отладчик подключается и переходит к строке после точки останова:
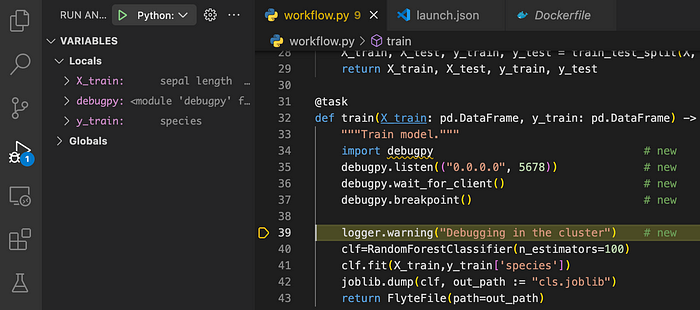
Чтобы проверить, что процесс, подвергаемый отладке, действительно выполняется в поде кластера Kubernetes, а не на ноутбуке, можно просматривать логи с подов в режиме реального времени:
❯ kubectl --namespace flytesnacks-development logs -f f3612cf260d5b48a5929-n1-0
При нажатии Step Over:
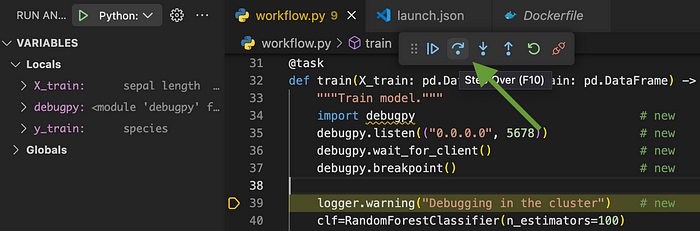
… записывается лог следующей строки:
❯ kubectl -n flytesnacks-development logs -f f3612cf260d5b48a5929-n1-0
...
Debugging in the cluster
Лог показывает, что мы проводим визуальную отладку процесса, который действительно выполняется удаленно. Теперь можно во всю пользоваться преимуществами визуального отладчика. Мы избавились от необходимости многократно добавлять инструкции print и перезапускать рабочий процесс обучения для разбора ошибок в удаленной среде.
Заключение
В данном руководстве мы рассказали о том, как с помощью k3d развернуть локальный кластер Kubernetes, установить движок Flyte для оркестровки рабочих процессов MLOps, создать простой процесс обучения и выполнить его отладку, используя VSCode и debugpy.
По сравнению с отладкой повторяющимися инструкциями print этот превосходный способ позволяет инженерам МО экономить массу времени.
Читайте также:
- Простой способ решить алгоритм Apriori с нуля
- Как ИИ влияет на разработку мобильных приложений и пользовательский опыт
- 25 прикольных вопросов для собеседования по машинному обучению
Читайте нас в Telegram, VK и Дзен
Перевод статьи Fabio M. Graetz: Attach a Visual Debugger to ML-training Jobs on Kubernetes





