
Введение
Среди методов машинного обучения — ассоциации, корреляции, классификации и кластеризации — акцент в этом руководстве сделан на обучении ассоциативным правилам, по которым выявляется набор элементов и атрибутов, встречающихся вместе в таблице.
Обучение ассоциативным правилам
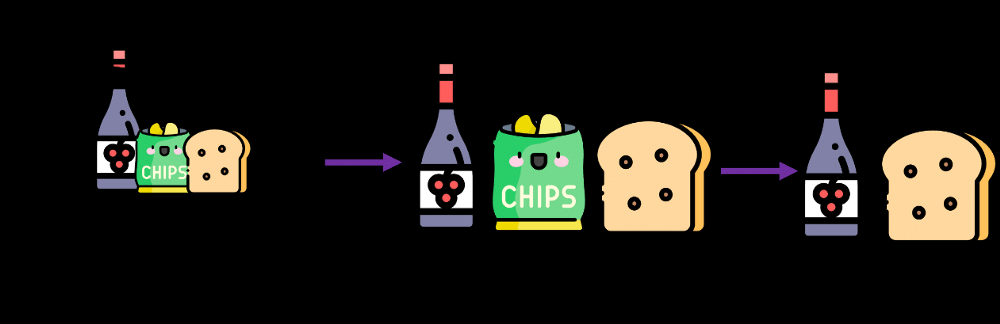
Обучение ассоциативным правилам — одна из важнейших концепций машинного обучения. Применяется в анализе рыночной корзины и статистики посещения сайтов, непрерывном производстве и т. д. Анализ рыночной корзины — это метод, используемый в крупных розничных сетях для выявления ассоциативных связей между товарами. Для его понимания показателен пример супермаркета, где все покупаемые вместе продукты раскладываются на полках рядом.
В обучении ассоциативным правилам выделяют три типа алгоритмов.
- Apriori.
- Eclat.
- FP Growth.
Введение в APRIORI
В основе Apriori — поиск частотных множеств элементов в наборе данных. Этот алгоритм построен на ассоциациях и корреляциях между наборами элементов. Он применяется на рекомендательных платформах — там, где мы обычно видим «вам также может понравиться».
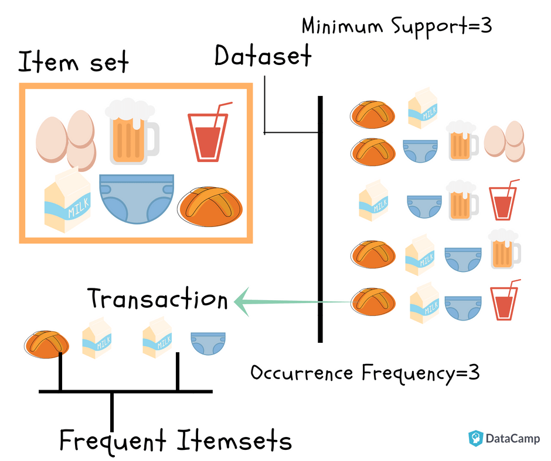
В алгоритме Apriori предполагается, что любое подмножество частотного набора элементов должно быть частотным. Например, если транзакция {молоко, яйца, хлеб} частотна, должна быть частотной и ее составляющая {яйца, хлеб}.
Принцип работы Apriori
Чтобы из всего многообразия правил отобрать интересные, для примера супермаркета применим следующие показатели:
- поддержка;
- доверие;
- лифт;
- уверенность.
Поддержка
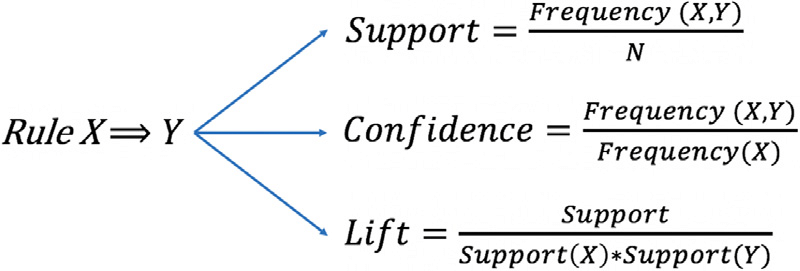
Поддержка элемента x — это не что иное, как отношение числа транзакций с товаром x к общему числу транзакций.
Доверие
Доверием (x => y) обозначают вероятность покупки товара y при покупке товара x. В этом методе учитывается популярность товара x.
Лифт
Лифт (x => y) — это не что иное, как «интересность» или вероятность покупки товара y при покупке товара x. В отличие от доверия (x => y), в этом методе учитывается популярность товара y.
- Если лифт (x => y) = 1, то корреляции в наборе товаров нет.
- Если лифт (x => y) > 1, корреляция в наборе товаров положительная, то есть вероятность совместной покупки товаров x и y выше.
- Если лифт (x => y) < 1, корреляция в наборе товаров отрицательная, то есть совместная покупка товаров x и y маловероятна.
Уверенность
Уверенность правила определяется так:
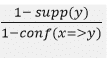
Диапазон значений [0, +∞].
- Если уверенность (x => y) = 1, то между x и y связи нет.
- В правиле чем выше уверенность, тем выше интерес.
Простое решение алгоритма Apriori
Часть 1. Применим Apriori к следующему набору данных:

Шаг 1
На первом шаге индексируем данные, затем для каждого набора вычисляем поддержку. Если она меньше минимального значения, набор из таблицы убираем:
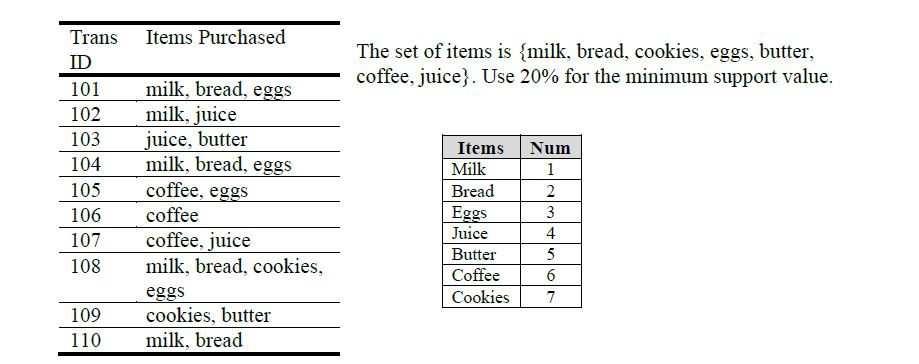
Шаг 2
Вычисляем поддержку каждого набора:
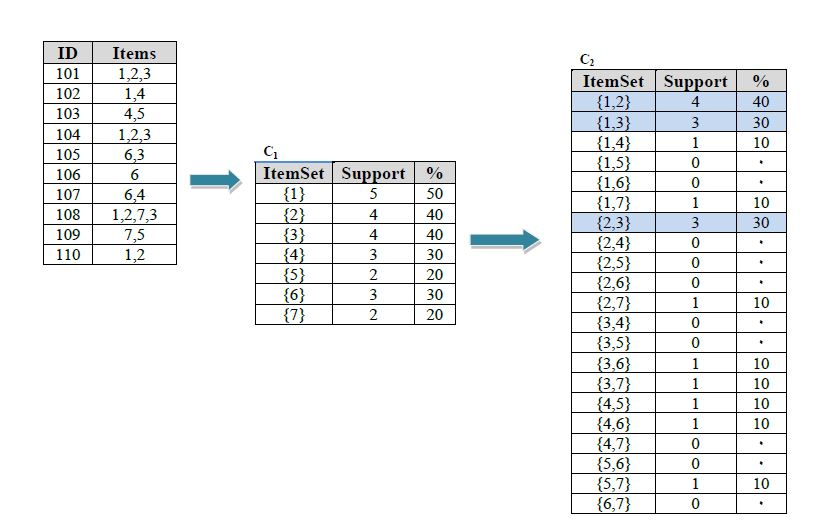
Шаг 3
Продолжаем вычислять поддержку и выбираем лучший вариант:
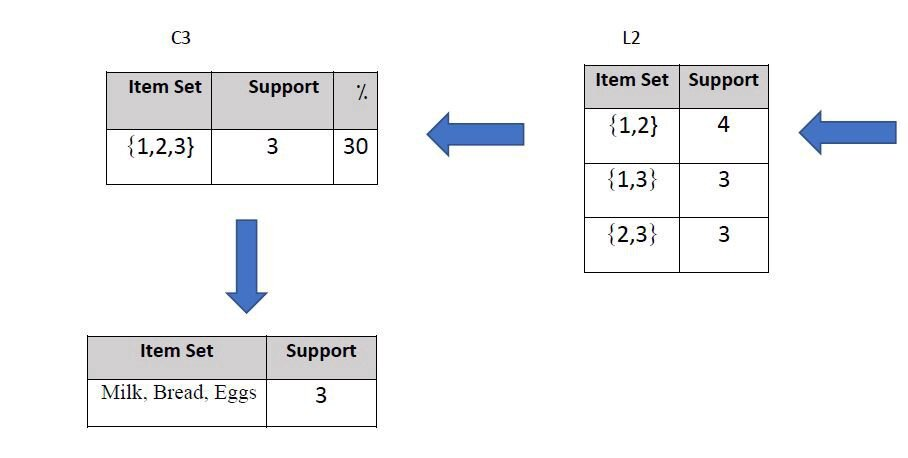
Часть 2. Покажем два правила с доверием не менее 70% для набора с тремя продуктами из части 1:
Шаг 1
Вычисляем доверие и следуем правилам в части 2:

Шаг 2
Кроме этих правил, можно учитывать и следующее, но для вычисления требуется только два правила:

Практический пример. Алгоритм Apriori на Python для анализа рыночной корзины
Постановка задачи
Для реализации алгоритма Apriori возьмем данные супермаркета. Каждая строка в них — отдельная транзакция со всеми купленными продуктами.
Задача директора магазина — выявить ассоциативное правило для товаров и, определив, какие чаще покупаются вместе, выложить их рядом друг с другом, чтобы увеличить продажи.
В наборе данных содержится 7500 записей. Вот ссылка для его загрузки с диска.
Настройка среды
Сначала установим в командной строке пакет apyori:

Анализ рыночной корзины на Python. Реализация
Чтобы помочь директору магазина выполнить анализ рыночной корзины, реализуем алгоритм Apriori.

Шаг 1. Импортируем библиотеки
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
Шаг 2. Загружаем набор данных
Набор данных в формате csv, поэтому считываем его функцией read_csv модуля pandas:
dataset = pd.read_csv("Market_Basket_Optimisation.csv")
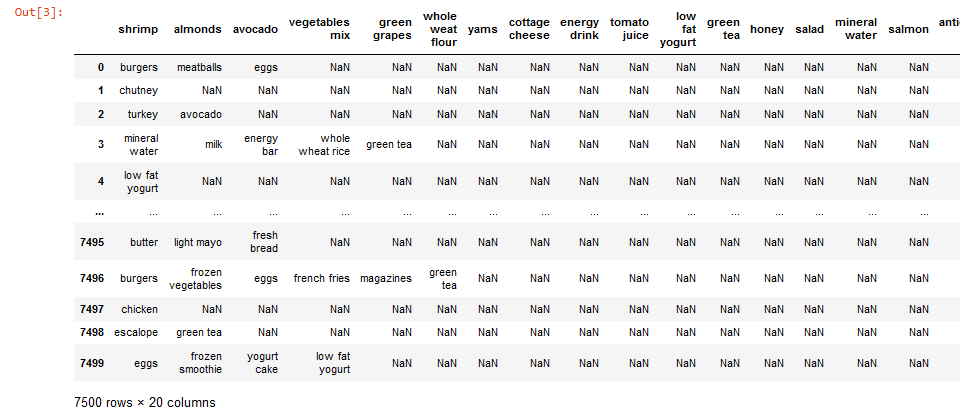
Шаг 3. Взглянем на записи
dataset
Шаг 4. Смотрим, что возвращается в методе shape
dataset.shape
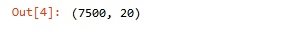
Шаг 5. Преобразуем фрейм данных Pandas в список списков
transactions = []
for i in range(0, 7501):
transactions.append([str(dataset.values[i,j]) for j in range(0,20)])
Шаг 6. Строим модель Apriori
Из модуля apyori импортируем функцию apriori. Ее итоговый вывод сохраняем в переменной rules, а в саму функцию передаем шесть параметров.
- Список транзакций — в качестве основных входных данных.
- Минимальная поддержка 0,003: продукт должен появляться не менее чем в трех транзакциях за день. Учитываются данные за неделю, поэтому значение поддержки должно быть 3*7/7500 = 0,0028.
- Минимальное доверие 0,2 (исходя из анализа различных результатов).
- Минимальный лифт 3.
- Минимальная длина 2, ведь значения лифта вычисляются для покупки одного товара при покупке другого.
- Максимальная длина 2 по той же причине.
from apyori import apriori
rules = apriori(transactions = transactions, min_support = 0.003, min_cinfidence = 0.2, min_lift = 3, min_length = 2, max_length = 2)
Шаг 7. Выводим списком количество правил:
results = list(rules)
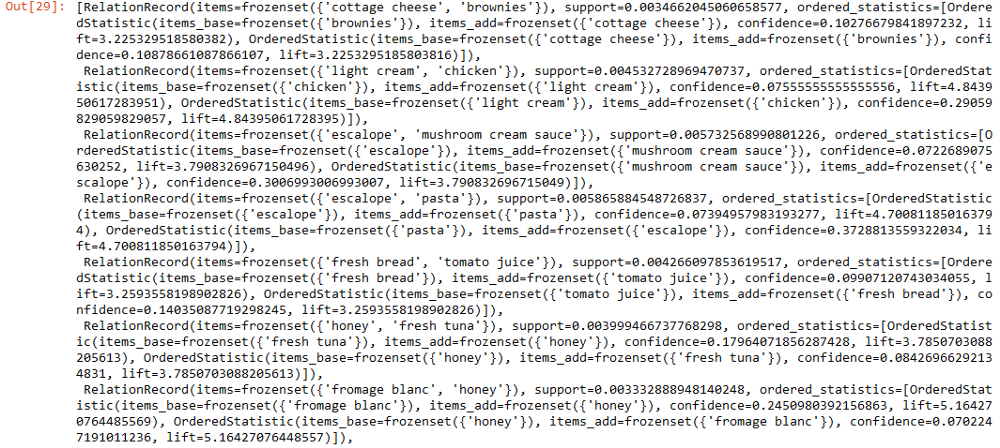
Шаг 8. Взглянем на правила
results
Шаг 9. Визуализация результатов
Сохраняем первый товар из всех результатов в переменной LHS, оттуда получаем второй, покупаемый уже после первого, и сохраняем его в переменной RHS.
В supports, confidences и lifts сохраняем из результатов все значения соответственно поддержки, доверия и лифта:
def inspect(results):
lhs =[tuple(result[2][0][0])[0] for result in results]
rhs =[tuple(result[2][0][1])[0] for result in results]
supports =[result[1] for result in results]
confidences =[result[2][0][2] for result in results]
lifts =[result[2][0][3] for result in results]
return list (zip(lhs, rhs, supports, confidences, lifts))
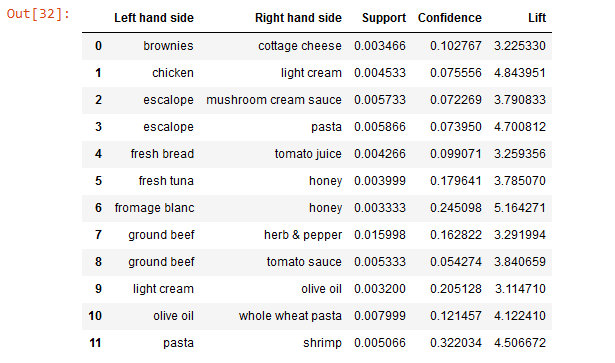
resultsinDataFrame = pd.DataFrame(inspect(results), columns = ["Left hand side", "Right hand side", "Support", "Confidence", "Lift"])
Наконец, сохраняем эти переменные в одном фрейме данных — так их проще визуализировать:
resultsinDataFrame
Теперь сортируем эти конечные результаты в порядке убывания значений лифта:
resultsinDataFrame.nlargest(n = 10, columns = "Lift")
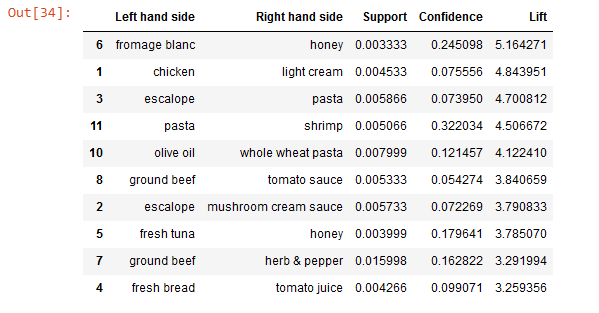
Таков конечный результат реализации Apriori на Python. В супермаркете эти данные применяются для увеличения продаж: упор делается на предложении пары товаров с бóльшими значениями лифта.
Почему Apriori?
- Это простой и понятный алгоритм.
- Легко реализуется на больших наборах данных.
Ограничения Apriori
Несмотря на простоту, у алгоритмов Apriori имеются ограничения.
- Потеря времени при обработке большого числа кандидатов с частотными наборами элементов.
- Снижение эффективности, когда большое количество транзакций пропускается через ограниченный объем памяти.
- Потребность в высокой вычислительной мощности и сканировании всей базы данных.
Заключение
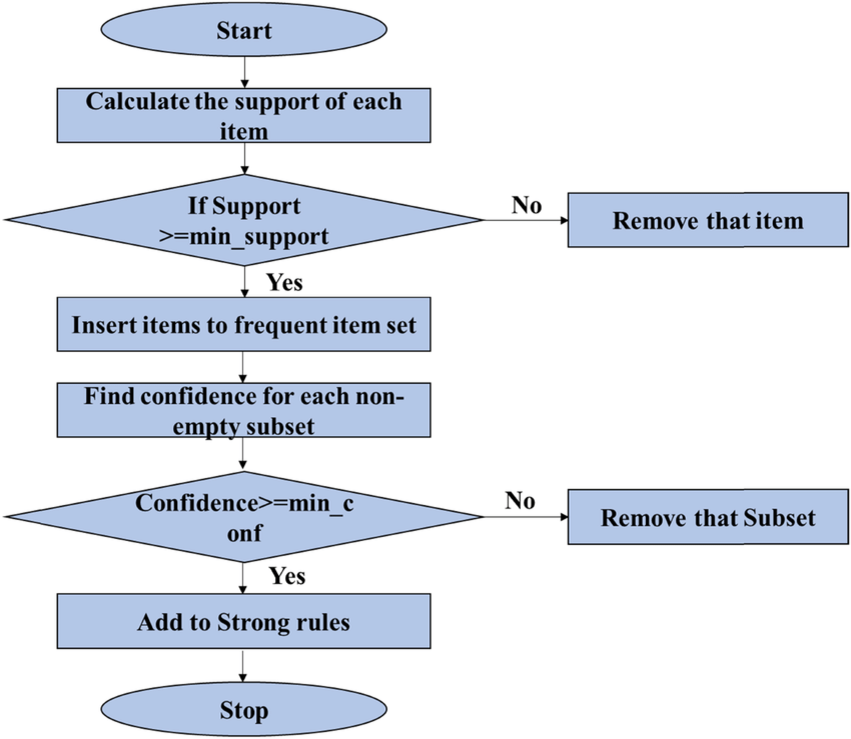
Обучение ассоциативным правилам — это методика машинного обучения без учителя, при которой проверяется наличие зависимости одного элемента данных от другого, выполняется их соответствующее распределение с целью извлечения бóльшей прибыли и ведется поиск интересных отношений или ассоциативных связей между переменными в наборе данных. Методика базируется на различных правилах обнаружения интересных взаимосвязей переменных в базе данных. Работа алгоритма в общем виде изображена на блок-схеме выше.
Читайте также:
- 5 видов регрессии и их свойства
- Как освоить машинное обучение
- Добыча данных: анализ рыночной корзины с помощью алгоритма Apriori
Читайте нас в Telegram, VK и Дзен
Перевод статьи Melanee Group: How to solve the Apriori algorithm in a simple way from scratch?





