
Код, представленный в статье, также доступен на GitHub.
ChatGPT используется повсеместно: начиная с компании Microsoft, которая добавила его в поисковую систему Bing, и заканчивая маркетинговыми компаниями, которые привлекают его для рекламы финального матча Super Bowl.
Но у этой новой технологии есть один большой недостаток: она ограничена событиями, произошедшими до 2021 года, поскольку именно такой объем данных задействовался для обучения большой языковой модели (LLM).
А что если исправить этот недостаток и сделать так, чтобы ИИ мог обращаться к внешним сайтам, анализировать страницы на наличие требуемой информации и предоставлять отчет о результатах?
Так вот, решим эту задачу с помощью одного пользовательского расширения браузера и ускоренного курса обучения.
В качестве примера приведем фактический ответ ChatGPT при использовании данной технологии:

Данные от 9 февраля 2023 года, время 12:49. Текущая цена акций компании Microsoft Corporation составляет 267,26 долларов США, что на 0,53 (+0,20%) больше по сравнению с предыдущим закрытием.
Принцип работы
Описание алгоритма действий:
- Добавляется пользовательское расширение браузера с помощью
Tampermonkey. Этот удобный инструмент позволяет вставлять небольшой фрагмент пользовательского кода JavaScript на посещаемые страницы. - Расширение ищет на сайте определенное ключевое слово. Это слово включает URL-адрес источника информации, где ChatGPT предполагает найти ответ.
- При обнаружении ключевого слова расширение принимает URL-адрес, делает запрос и извлекает весь текст с данного сайта.
- Далее расширение передает информацию обратно в ChatGPT, который ищет ответ в тексте и сообщает его содержание.
Расширение Tampermonkey
Прежде всего я написал расширение для Tampermonkey, а точнее говоря, его написал ChatGPT.
Сначала я попросил его просто найти фразу на странице:
Напиши небольшой плагин
Tampermonkey, который сканирует весь текст на сайте и находит все совпадения строки::external_request:[any url]::, где фраза[any url]соответствует любому действительному URL сайта.
Обратите внимание на особое требование: ::external_request:[any url]::.
Это специальная команда, которую возвращает ChatGPT, когда ему требуется помощь в поиске информации. Я создал специальный формат ключа, чтобы гарантировать получение обдуманного ответа от ИИ.
Теперь предстоит обучить ИИ принципу его применения. Далее рассмотрим, как это сделать.
Ниже представлен первый разработанный вариант кода:
// ==UserScript==
// @name Find External Requests
// @namespace http://tampermonkey.net/
// @version 1.0
// @description Find all instances of "::external_request:[any url]::" on a page
// @author You
// @match *://*/*
// @grant none
// ==/UserScript==
(function() {
'use strict';
const regex = /::external_request:(.*)::/g;
// Получение всего текста страницы
let text = document.body.textContent;
let match;
while ((match = regex.exec(text)) !== null) {
console.log(`Matched: ${match[1]}`);
}
})();
Отлично! Код находит соответствия указанной команде, а консоль заполняется логами при обновлении чата, содержащего ключевую фразу.
Помимо этого, необходимо обеспечить повторное сканирование при каждом обновлении страницы. Попросим ChatGPT добавить эту функциональность и посмотрим, что получится:
Обнови код таким образом, чтобы он проводил повторную проверку при каждом изменении текстового содержимого на сайте.
Обновленный вариант кода:
// ==UserScript==
// @name Find External Requests
// @namespace http://tampermonkey.net/
// @version 1.0
// @description Find all instances of "::external_request:[any url]::" on a page and re-run the search any time the text content of the page changes
// @author You
// @match *://*/*
// @grant none
// ==/UserScript==
(function() {
'use strict';
const regex = /::external_request:(.*)::/g;
// Функция для запуска поиска
function runSearch() {
// Получение всего текста страницы
let text = document.body.textContent;
let match;
while ((match = regex.exec(text)) !== null) {
console.log(`Matched: ${match[1]}`);
}
}
// Первоначальный запуск поиска
runSearch();
// Отслеживание изменений в текстовом содержимом страницы
const observer = new MutationObserver(runSearch);
observer.observe(document.body, {
childList: true,
subtree: true,
characterData: true
});
})();
С MutationObserver я еще ни разу не сталкивался. Похоже, это идеальное решение поставленной задачи.
Процесс продвигается успешно. Но предстоит еще решить вопрос с выполнением запросов с целью извлечения текста для анализа ChatGPT.
К сожалению, если вы просто начнете отправлять запросы к разным доменам с помощью fetch, то получите ошибки CORS, т.е. данный способ не сработает.
Будем разбираться с этой проблемой.
CORS Anywhere
К счастью, решение уже существует в виде разработанного прокси Node, позволяющего делать запросы к другим сайтам.
С помощью CORS Anywhere плагин Tampermonkey способен выполнять запросы к внешним сайтам из браузера. На Heroku размещен общедоступный экземпляр инструмента, но с ограниченными возможностями его применения.
Однако для целей данного исследования подойдет и общедоступный экземпляр. Кроме того, предоставляется также Docker-образ, позволяющий запускать его локально. Этот вариант даже предпочтительнее, если вы не собираетесь ограничиваться изучаемым случаем и планируете в дальнейшем задействовать CORS Anywhere.
Я попросил ChatGPT включить CORS Anywhere в плагин Tampermonkey:
Заново обнови скрипт таким образом, чтобы он использовал совпадение URL для отправки запроса к
https://cors-anywhere.herokuapp.com/[URL], где[URL]соответствует совпадению. Далее скрипт извлекает содержимое полученного ответа, анализирует его и возвращает содержимое элементаbodyв переменнуюbody.
ChatGPT генерирует следующий код:
// ==UserScript==
// @name Find External Requests
// @namespace http://tampermonkey.net/
// @version 1.0
// @description Find all instances of "::external_request:[any url]::" on a page, send a request to "https://cors-anywhere.herokuapp.com/[URL]", retrieve the contents of that response, parse it, and return the contents of the "body" element
// @author You
// @match *://*/*
// @grant none
// ==/UserScript==
(function() {
'use strict';
const regex = /::external_request:(.*)::/g;
const corsAnywhereUrl = "https://cors-anywhere.herokuapp.com/";
// Функция для запуска поиска
function runSearch() {
// Получение всего текста страницы
let text = document.body.textContent;
let match;
while ((match = regex.exec(text)) !== null) {
const url = match[1];
const fullUrl = corsAnywhereUrl + url;
console.log(`Matched: ${url}`);
// Отправка запроса к cors-anywhere
fetch(fullUrl)
.then(response => response.text())
.then(text => {
// Парсинг текста ответа как HTML
const parser = new DOMParser();
const htmlDoc = parser.parseFromString(text, "text/html");
// Получение содержимого элемента "body"
const body = htmlDoc.querySelector("body").innerHTML;
console.log(`Retrieved body: ${body}`);
})
.catch(error => console.error(error));
}
}
// Первоначальный запуск поиска
runSearch();
// Отслеживание изменений в текстовом содержимом страницы
const observer = new MutationObserver(runSearch);
observer.observe(document.body, {
childList: true,
subtree: true,
characterData: true
});
})();
ChatGPT отлично поработал, остальное я беру на себя.
- Осталось отправить запрос обратно в ChatGPT. Для этого нужно найти
textarea, чтобы добавить текст, и нажатьbuttonдля отправки. - Обойдемся без отправки запросов для демонстрационных целей, поэтому исключаем эту опцию из кода.
- Для поддержания частоты появления запроса на странице немного изменим регулярное выражение и установим для него “ленивый” режим поиска совпадений.
- Ограничим длину тела ответа до 4 000 символов во избежание проблем с длиной контента со стороны ChatGPT. Это определенно недостаток, который в перспективе требует решения.
Итоговый отредактированный вариант плагина Tampermonkey:
// ==UserScript==
// @name Find External Requests
// @namespace http://tampermonkey.net/
// @version 1.0
// @description Find all instances of "::external_request:[any url]::" on a page, send a request to "https://cors-anywhere.herokuapp.com/[URL]", retrieve the contents of that response, parse it, and return the contents of the "body" element
// @author Seamus James and ChatGPT
// @match *://chat.openai.com/chat*
// @grant none
// ==/UserScript==
(function() {
'use strict';
const requestedUrls = [];
const regex = /::external_request:(.+?)::/g;
const corsAnywhereUrl = "https://cors-anywhere.herokuapp.com/";
// Функция для запуска поиска
function runSearch(initializing) {
// Получение всего текста страницы
let text = document.body.textContent;
let match;
while ((match = regex.exec(text)) !== null) {
const url = match[1];
const fullUrl = corsAnywhereUrl + url;
if ( ['[URL]', 'http://www.timeanddate.com'].includes(url) ) continue;
if ( requestedUrls.includes(url) ) continue;
requestedUrls.push(url);
if ( initializing ) continue;
console.log(`Matched: ${url}`);
// Отправка запроса к cors-anywhere
fetch(fullUrl)
.then(response => response.text())
.then(text => {
// Парсинг текста ответа как HTML
const parser = new DOMParser();
const htmlDoc = parser.parseFromString(text, "text/html");
// Получение содержимого элемента "body"
const body = htmlDoc.body.innerText.slice(0,4000);
const textArea = document.querySelector('textarea');
const button = document.querySelector('textarea + button');
textArea.value=body;
button.click();
})
.catch(error => console.error(error));
}
if ( initializing ) {
console.log("Initialized", requestedUrls);
}
}
// Первоначальный запуск поиска
runSearch(true);
// Отслеживание изменений в текстовом содержимом страницы
const observer = new MutationObserver(() => runSearch(false));
observer.observe(document.body, {
childList: true,
subtree: true,
characterData: true
});
})();
Принцип применения
Согласно задумке, ChatGPT отправляет обратно специальную строку, если не знает ответа. Он сообщает информационный ресурс, где следует искать, после чего мы предоставляем ему то, что он ищет. Чтобы добиться этого результата, я написал следующий пояснительный текст:
Привет, ChatGPT. С этого момента, если ты не знаешь ответ, но знаешь URL-адрес, по которому ты можешь его найти, отреагируй текстом
::external_request:[URL]::, где[URL]означает сайт, предположительно содержащий требуемый ответ. Например, на вопрос о текущем времени и дате, можешь отреагировать так:::external_request:http://www.timeanddate.com::. При каждом ответе, содержащимexternal_request, я получаю внутренний текстinnerTextэлементаbodyуказанной страницы и предлагаю его тебе в качестве обратной связи. Ты должен проанализировать этот текст и дать ответ на первоначальный вопрос.
Сначала я инструктирую ИИ о том, как запрашивать информацию, которую он не знает. Затем объясняю механизм взаимодействия. Наконец, для полной ясности привожу пример. (Отметим, что эти иллюстративные фразы будут проигнорированы плагином Tampermonkey во избежание выполнения ненужных запросов http://www.timeanddate.com).
Он отвечает сообщением о своей готовности, после чего вы отправляете вопрос, ответа на который он точно не знает, например такой:
Какова текущая цена акций MSFT?
Как видно, браузер автоматически возвращает большой блок текста, а ChatGPT выдает ответ.
Выглядит это следующим образом:
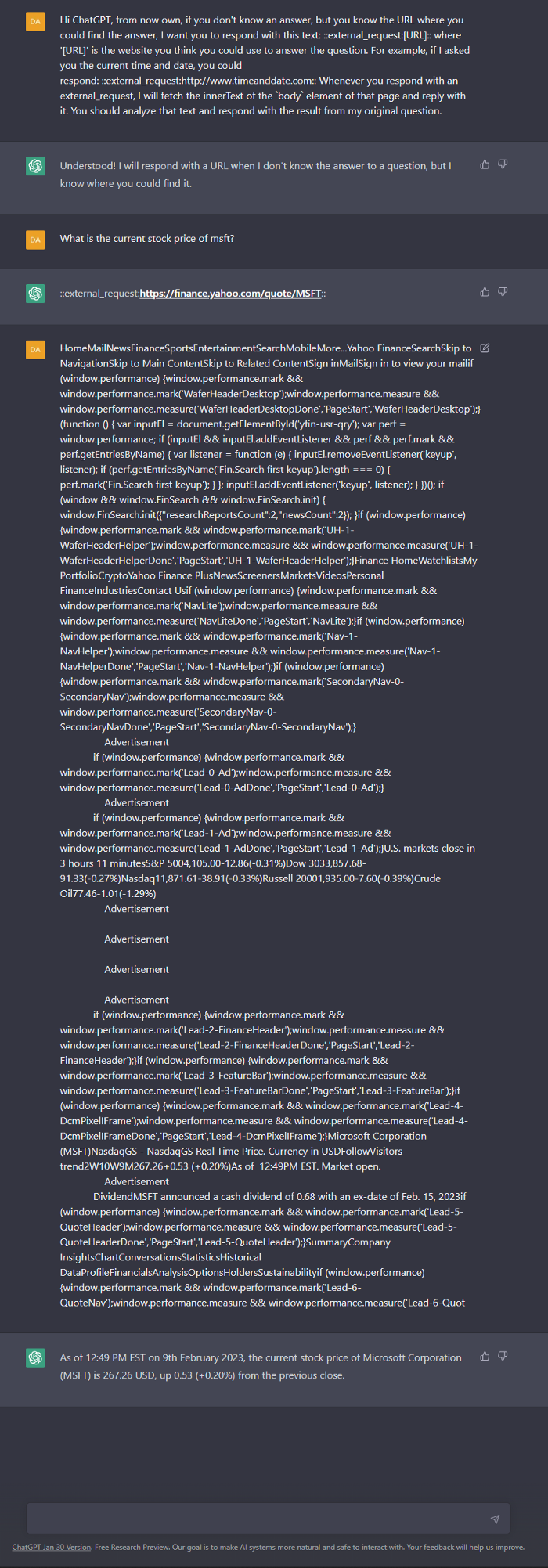
- Привет, ChatGPT. С этого момента, если ты не знаешь ответ, но знаешь URL-адрес, по которому ты можешь его найти, отреагируй текстом
::external_request:[URL]::, где[URL]означает сайт, предположительно содержащий требуемый ответ. Например, на вопрос о текущем времени и дате, можешь отреагировать так:::external_request:http://www.timeanddate.com::. При каждом ответе, содержащимexternal_request, я получаю внутренний текстinnerTextэлементаbodyуказанной страницы и предлагаю его тебе в качестве обратной связи. Ты должен проанализировать этот текст и дать ответ на первоначальный вопрос. - Понял! Когда я не знаю ответа на вопрос, но знаю, где его найти, то предоставляю ответ с URL.
- Какова текущая цена акций MSFT?
- ::external_request:http://finance.yahoo.com/quote/MSFT::
- … блок текста…
- Данные от 9 февраля 2023 года, время 12:49. Текущая цена акций компании Microsoft Corporation составляет 267,26 долларов США, что на 0,53 (+0,20%) больше по сравнению с предыдущим закрытием.
Автоматический ответ генерирует большой блок текста, но ChatGPT знает, как его обрабатывать.
Заключение
Технология не идеальна, но проверка концепции показывает ее практический потенциал. Она позволяет:
- локально расширить возможности ИИ-чата и создать API для доступа к этим возможностям. В описанном случае API — это просто команда
::external_request::; - обучить ИИ, как и когда обращаться к API;
- предоставить соответствующие ответы ИИ для последующего анализа.
Если запустить локальный сервер и установить на нем плагин Tampermonkey, то спектр возможностей становится бесконечным. ChatGPT способен:
- писать скрипты, которые выполняются автоматически (не так страшно, если в это происходит Docker-контейнере);
- отправлять SMS;
- обновлять базу данных;
- честно говоря, да все что угодно.
Нельзя не впечатлиться самим этим инструментом, его способностью создавать нечто подобное и плавным процессом взаимодействия с подобного рода API, гарантированного по умолчанию.
Читайте также:
- Как Scalene с ИИ-рекомендациями оптимизирует код Python
- 5 способов упростить повседневные задачи с помощью ChatGPT
- Интеграция ChatGPT с Node.js: руководство для начинающих
Читайте нас в Telegram, VK и Дзен
Перевод статьи Seamus James: I Made a Browser Extension That Allows ChatGPT to Access External Sites and Get Current Events





