
Как правило, Python негласно используется с библиотеками, написанными на других языках. При таком уровне абстракции бывает сложно понять, как улучшить производительность и потребление памяти. Однако подобные проблемы решаются с помощью профилировщика (англ. profiler).
Этот инструмент выявляет участки кода, требующие наибольших затрат времени и памяти. Scalene — отличный профилировщик Python, который целенаправленно занимается CPU, GPU и памятью. В сочетании с ИИ-рекомендациями он помогает быстрее выполнять рефакторинг проблемных участков кода для повышения производительности.
Применение Scalene
Scalene запускается командой scalene program_name.py. По умолчанию он проводит профилирование CPU, GPU и памяти. Для выбора одного или нескольких вариантов из предложенных применяются флаги: --cpu, --gpu и --memory. Например, scalene --cpu --gpu program_name.py профилирует только CPU и GPU.
Scalene обеспечивает профилирование как на уровне строк, так и функций. Для каждого из этих типов профилирования выделяется отдельный раздел выходной таблицы. Первый раздел включает профилирование всех строк, а второй — всех функций. Для профилирования только часто используемых строк и функций добавляется флаг --reduced-profile.
Интерфейсы
После выполнения команды профилирования результаты отображаются в интерфейсе. Предлагаются два варианта интерфейса: интерфейс командной строки (CLI) и веб-интерфейс. Сравним их на примере следующего файла Python test.py:
size = 1000000
# Большое выделение памяти
x = [i for i in range(size)]
y = [i for i in range(size)]
# Большое время вычисления
for i in range(size):
y[i] = y[i] * y[i]
Интерфейс командной строки
По умолчанию команда scalene test.py открывает веб-интерфейс. Для применения CLI добавляется флаг --cli:
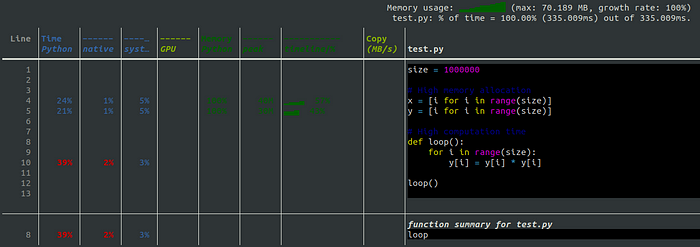
В таблице представлены три цвета: синий, зеленый и желтый. Синий обозначает профилирование CPU, зеленый — памяти, желтый — GPU и объема копирования.
Профилирование CPU показывает время, затраченное на выполнение кода Python, нативного кода (например, C или C++) и времязатраты на систему (например, I/O). В обозначенном примере 45% общего времени работы приходится на код Python в строке y[i] = y[i] * y[i]. Таким образом, это одна из строк, которая подлежит оптимизации для повышения производительности. При суммировании всех процентов в колонках синего цвета получается 100%.
Профилирование памяти предоставляет информацию о процентном количестве памяти, выделяемой кодом Python. Таблица также отображает потребление памяти во времени и его максимальное значение. Как и ожидалось, создание векторов x и y приводит к наибольшему выделению памяти. Для повышения производительности следует создавать их посредством более оптимальных функций.
Профилирование GPU и объема копирования показывает время работы GPU и соответственно объем копирования (мб/с). Объем копирования включает копии между GPU и CPU. Обратите внимание, что профилирование GPU поддерживает только NVIDIA GPU.
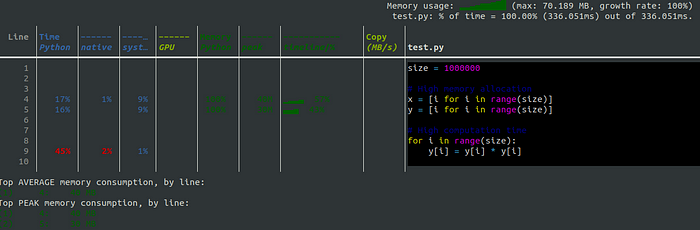
Веб-интерфейс

Веб-интерфейс похож на CLI. Однако в нем некоторые столбцы совмещены, и полученные результаты отображаются в виде шкалы с разными цветовыми оттенками. Например, для профилирования CPU выделяется только один синий столбец, в котором разными оттенками представлено время работы Python, нативного кода и системы.
Для профилирования памяти и GPU предоставляются дополнительные столбцы: Memorу average, Мemory activity и GPU memory. Memorу average показывает среднее потребление памяти. Мemory activity отображает память, выделяемую Python и нативным кодом, показатели которых обозначаются двумя разными оттенками зеленого цвета. GPU memory указывает на использование памяти GPU.
В отличие от CLI создаются дополнительные файлы с именами profile.html и profile.json, которые содержат отображаемые результаты. Для получения таких файлов в CLI применяются флаги --json и --html .
ИИ-рекомендации
Рассмотренные в предыдущих разделах инструменты помогают определять строки и функции, требующие улучшения. Вместо того чтобы самим разрабатывать варианты оптимизации, вы можете ускорить рабочий процесс за счет генерации ИИ-рекомендаций. К счастью, предоставляется возможность совместного взаимодействия Scalene и OpenAI при наличии ключа API.
Для получения ключа API создаем или входим в имеющийся аккаунт OpenAI. Далее в правом верхнем углу экрана нажимаем Personal и выбираем View API keys. На этой странице генерируем новый ключ API и копируем его в веб-интерфейс Scalene в раздел advanced options:

Вы можете выбирать из двух предлагаемых типов рекомендаций. Значок взрыва 💥 предусматривает варианты оптимизации для всего участка кода, а значок молнии ⚡ — только для строки. Ниже приведен пример рекомендаций со знаком ⚡ для test.py, которые в основном включают замены с использованием NumPy:
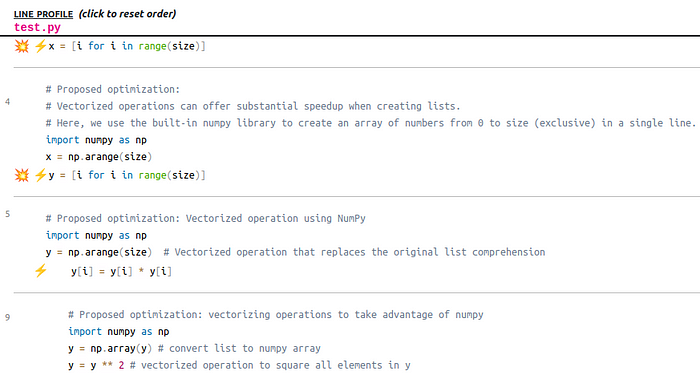
4.
# Предлагаемая оптимизация:
# Векторизованные операции позволяют значительно ускорить создание списков.
# Здесь задействуется встроенная библиотека NumPy для создания массива чисел от 0 до size (особого размера) в одной строке.
5.
# Предлагаемая оптимизация: Векторизованная операция с NumPy.
# Векторизованная операция заменяет исходное списковое включение.
9.
# Предлагаемая оптимизация: Векторизованные операции для извлечения преимуществ NumPy.
# Преобразование списка в массив NumPy.
# Векторизованная операция для удвоения всех элементов в y.
После оптимизации версия test.py выглядит следующим образом:
import numpy as np
size = 1000000
x = np.arange(size)
y = np.arange(size)
y = y ** 2
Полезные ресурсы
Читайте также:
- Программируем с ChatGPT: 10 советов
- Настраиваем автоматизированную модерацию с помощью OpenAI
- Будущее практического применения чат-ботов
Читайте нас в Telegram, VK и Дзен
Перевод статьи Dora Lourenço, MSc: Optimize Python Code With Scalene and AI Suggestions





