
При работе с данными в Pyth on у программистов есть инструмент, который никогда не подведет: pandas. Это полнофункциональная и интуитивно понятная библиотека с открытым ПО, предоставляющая структуры данных для работы с высокоразмерными датасетами.
Выделяют 2 основные структуры данных:
Seriesдля одномерных массивов;DataFrameдля двухмерных таблиц, содержащих строки и столбцы.
В статье мы рассмотрим наиболее эффективные функции для разделения датасетов на группы. После этого можно проводить статические вычисления, например находить стандартное отклонение, среднее, максимальное и минимальное значение, а также многое другое.
Вы научитесь применять функции apply, cut, groupby и agg. Они могут весьма пригодиться для лучшего понимания данных на основе их графического представления .
Содержание:
1. Импорт данных
2. Простые агрегации
3. Множественные агрегации
1. Импорт данных
Начнем с импорта библиотек и датасетов. В работе будем использовать датасет с ценами на недвижимость Бостона, доступный в библиотеке Scikit-learn.
import numpy as np # линейная алгебра
import pandas as pd # обработка данных, CSV файл ввода-вывода (например, pd.read_csv)
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(data=boston.data,columns=boston.feature_names)
df['price']=boston.target
df.head()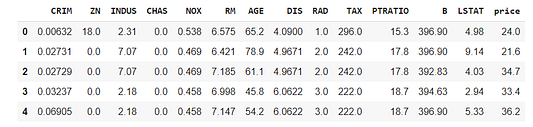
Данный DataFrame содержит только числовые признаки, а нам нужны категориальные переменные для разделения датасета на группы. Следовательно, займемся их созданием с помощью его описательной статистики:
df.describe()
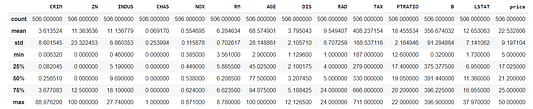
Допустим, нам нужны категориальные признаки для RM (число комнат) и price (цены), которые представляют собой среднее число комнат на жилое помещение и медиану цен на жилье в размере $10,000 соответственно. В зависимости от диапазона значений указанных числовых признаков у этих переменных должны быть разные уровни (level), для создания которых задействуем значения первого и третьего квантиля. С целью генерирования этих новых переменных воспользуемся функцией apply.
df['RM_levels']=df['RM'].apply(lambda x: 'low' if x<5.8 else 'middle' if x<6.6 else 'high')
df['price_levels']=df['price'].apply(lambda x: 'low' if x<17 else 'middle' if x<25 else 'high')
df[['RM','RM_levels','price','price_levels']].head()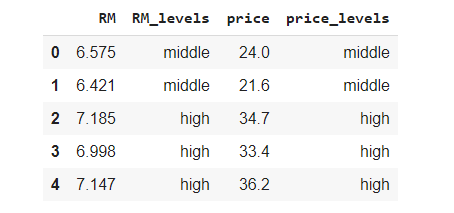
Новые столбцы появились благодаря функции apply, которая по умолчанию работает с каждой строкой датасета. Она по порядку проверяет условия. Первый уровень содержит значения числовых признаков, не превышающих первый квантиль. “Средний” уровень включает значения, располагающиеся в диапазоне между первым и третьим квантилем. Третий и последний уровень охватывают только значения, превосходящие третий квантиль.
Функция cut — альтернативный и более эффективный способ создания таких переменных, в особенности тех, что обладают несколькими уровнями. Как и в предыдущем случае, делим значения price на 3 группы: [3,5.8),[5.8,6.6),[6.6,9), где 3 и 9 соответствуют минимальной и максимальной границам переменной. Эту же логику применяем и к числу комнат. Передав только интервальные значения и аргумент right=False для игнорирования правого максимума, получаем следующие группы:
df['RM_levels'] = pd.cut(df['RM'],bins=[3,5.8,6.6,9],right=False)
df['price_levels'] = pd.cut(df['price'],bins=[5,17,25,51],right=False)
df[['RM','RM_levels','price','price_levels']].head()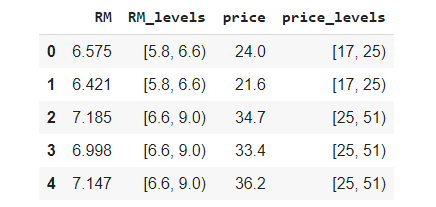
При необходимости сохранить эти метки учитывайте тот факт, что несмотря на категориальный тип новых столбцов, отдельные элементы являются не строками, а объектами Interval! Попытка осуществить поиск конкретного класса значений price окажется безрезультатной.
df[df.price_levels=='[17, 25)']
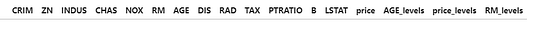
Если проверить тип столбца price_levels, взяв лишь первую строку, то увидим, что у нас есть на самом деле:
type(df['price_levels'][0])

Если вы намерены сохранить эти интервалы, то во избежание сложностей подскажу один прием — передайте метку для каждой группы, установив аргумент labels со списком строк:
l=[[3,5.8,6.6,9],[5,17,25,51]]
lbs1 = ['[{},{})'.format(l[0][i],l[0][i+1]) for i in range(len(l[0])-1)]
lbs2 = ['[{},{})'.format(l[1][i],l[1][i+1]) for i in range(len(l[1])-1)]
df['RM_levels'] = pd.cut(df['RM'],bins=[3,5.8,6.6,9],right=False,labels=lbs1)
df['price_levels'] = pd.cut(df['price'],bins=[5,17,25,51],right=False,labels=lbs2)
print(type(df['price_levels'][0]))
Теперь у вас есть строковые объекты! В любом случае в данной статье я буду сохранять метки, как показано ниже, всегда устанавливая аргумент labels:
df['RM_levels'] = pd.cut(df['RM'],bins=[3,5.8,6.6,9],labels=['low','middle','high'],right=False)
df['price_levels'] = pd.cut(df['price'],bins=[5,17,25,51],labels=['low','middle','high'],right=False)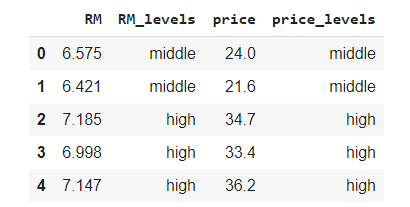
2. Простые агрегации
Итак, первый этап пройден, и мы приступаем к группировке датасета на основании заданных признаков. Допустим, нужно узнать среднее значение каждого столбца для каждого типа price:
df_price = df.groupby(by=['price_levels']).mean()
df_price
Как видно, по каждому уровню мы получили строку, содержащую соответствующие средние значения всех переменных, представленных в датасете. Переменная price_levels считается индексом, поскольку groupby по умолчанию в качестве такого индекса возвращает метку группы. Обратите внимание на произвольный порядок уровней. Выясним причину:
df.info()
На данный момент новые переменные сохранены в памяти как объекты. Очевидно, что их необходимо преобразовать в категории. Как только мы это сделали, определяем порядок уровней переменных.
df['price_levels']=df['price_levels'].astype('category')
df['price_levels'].cat.reorder_categories(['low','middle','high'], inplace=True)
df['RM_levels']=df['RM_levels'].astype('category')
df['RM_levels'].cat.reorder_categories(['low','middle','high'], inplace=True)Попробуем заново сгруппировать датасет для каждого уровня price. Если установить аргумент as_index в значение False, то метка группы более не будет рассматриваться в качестве индекса:
df_price = df.groupby(by=['price_levels'],as_index=False).mean()
df_price
В результате получаем упорядоченные уровни и переменную price_levels, которая более не является индексом. Как видим, датасет содержит много столбцов. Их число можно сократить, если выбрать лишь несколько признаков (например, RM и price). Кроме того, расположим ценовые уровни по возрастанию.
df_price = df.groupby(by=['price_levels'],as_index=False)[['price','RM']].mean().sort_values(by='price_levels', ascending=True)
df_price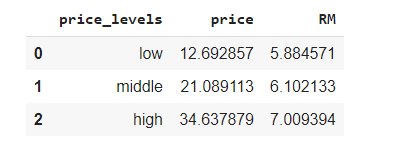
С увеличением числа комнат повышается стоимость жилплощади. Но что если мы не хотим ограничиваться вычислением среднего, минимального и максимального значений? В таком случае нам потребуется функция apply. Выясним диапазон значений столбцов CRIM и LSTAT, имена которых соответственно означают уровень преступности на душу населения по городу и процент граждан с низким социальным статусом.
df_price = df.groupby(by=['price_levels'],as_index=False)[['CRIM','LSTAT']].apply(lambda v: v.max()-v.min())
df_price
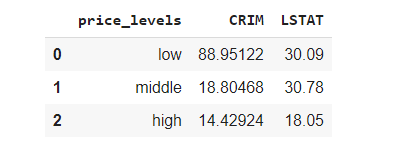
Как видно, уровень преступности и процент населения с низким социальным положением уменьшаются с ростом цен на жилплощадь. Представим это соотношение в виде гистограммы:
import plotly.express as px
fig = px.bar(df_price, x='price_levels', y='CRIM', labels={'price_levels':'Price','CRIM':'Range of Criminality'})
fig.show()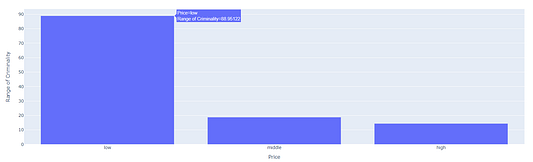
3. Множественные агрегации
С целью выполнения множественных агрегаций для нескольких столбцов потребуется функция agg, позволяющая применить среднее, минимальное и максимальное значения, а также стандартное отклонение для каждого выбранного столбца. Результаты сгруппируем по типу цены.
df_price = df.groupby(by=['price_levels'],as_index=False)[['price','AGE','CRIM']].agg(['mean','min','max','std'])
df_price
Как видно, при добавлении функции agg аргумент as_index более не работает. Во избежание использования метки группы в качестве индекса можно в конце поместить функцию reset_index:
df_price = df.groupby(by=['price_levels'])[['price','AGE','CRIM']].agg(['mean','min','max','std']).reset_index()
df_price
Теперь все признаки агрегированы, но при работе с этим датасетом могут возникнуть проблемы. Выбирая конкретный признак, вы должны указывать двойные индексы:
df_price.columns
Работа с двойными индексами может стать обременительной. Чтобы не создавать лишних сложностей, можно заменить имена столбцов следующим образом:
stats = ['mean','min','max','std']
df_price.columns = ['price_levels']+['price_{}'.format(stat) for stat in stats]+['age_{}'.format(stat) for stat in stats]+['age_{}'.format(stat) for stat in stats]
df_price
С таким DataFrame работается уже намного легче.
Передача словаря в функцию agg позволит применять различные статистики в зависимости от столбца. В этом случае ключами будут имена столбцов, а значениями — агрегированная функция, подлежащая измерению. На этот раз для группировки датасета нам понадобятся два признака:
df_price = df.groupby(by=['price_levels','RM_levels'],as_index=False).agg({'CRIM':['count','mean','max','min'],'price':['mean']})
df_price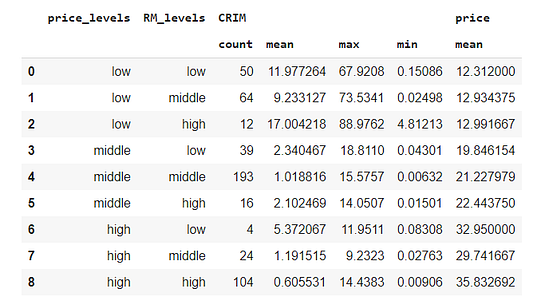
Отразим новые итоги обработки данных в гистограмме. Сначала поменяем метки датасета, а затем посмотрим на результаты для жилья с наибольшим числом комнат.
import plotly.express as px
stats = ['count','mean','max','min']
df_price.columns = ['price_levels','RM_levels']+['CRIM_{}'.format(stat) for stat in stats]+['price_mean']
df_price
fig = px.bar(df_price[df_price.RM_levels=='high'], x='price_levels', y='CRIM_count', labels={'price_levels':'Price','CRIM_count':'Count of observations'})
fig.show()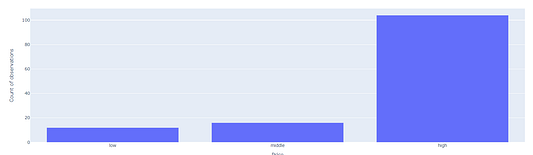
Очевидно, что число домов увеличивается с ростом цены, поскольку мы выбрали большое количество комнат. Налицо прямая зависимость между числом комнат и ценой дома.
Выводы
В статье мы рассмотрели шаги по освоению функций для разделения датасета на группы. Надеюсь, что предложенные примеры помогли закрепить полученные знания.
Благодарю за внимание!
Полезные ссылки
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.apply.html
- https://pandas.pydata.org/docs/reference/api/pandas.cut.html
- https://www.google.com/search?q=groupby+pandas&oq=groupby+pandas&aqs=chrome..69i57j0j0i20i263j0l2j69i60j69i61j69i60.5962j0j7&sourceid=chrome&ie=UTF-8
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.agg.html
Читайте также:
- 7 полезных операций в Pandas при работе с DataFrame
- Новая библиотека превосходит Pandas по производительности
- 7 трюков pandas для науки о данных
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Eugenia Anello: 3 Pandas Functions To Group and Aggregate Data





