
1. Анализ образцов датафреймов с помощью df.groupby().__iter__()
Обычно исследовать набор данных строка за строкой или группа за группой в блокнотах Jupyter сложнее, чем в Excel. Один из полезных трюков заключается в использовании генератора и комбинации клавиш Ctrl + Enter вместо Shift + Enter, чтобы итеративно просматривать различные образцы в одной ячейке, не создавая беспорядка в вашем блокноте.
Сначала создайте ячейку с генератором c .groupby () (или .iterrows ()) и добавьте .__iter__():
generator = df.groupby(['identifier']).__iter__()
Затем запустите следующую ячейку столько раз, сколько вам потребуется, чтобы увидеть необходимые вам данные, используя сочетание клавиш Ctrl + Enter:
group_id, grouped_data = generator.__next__()
print(group_id)
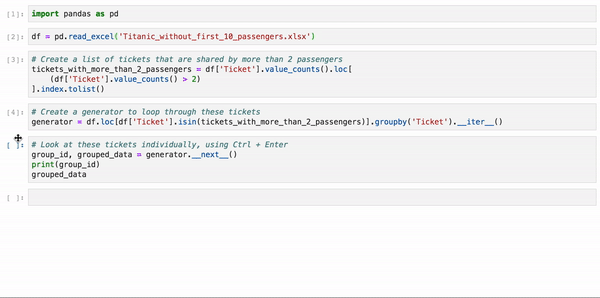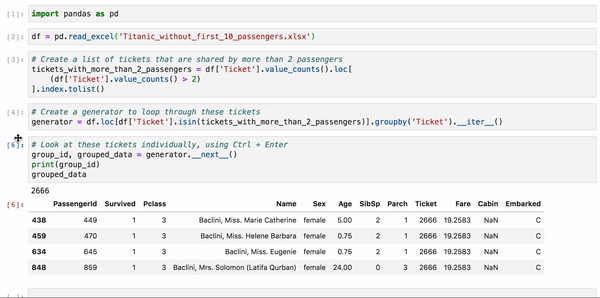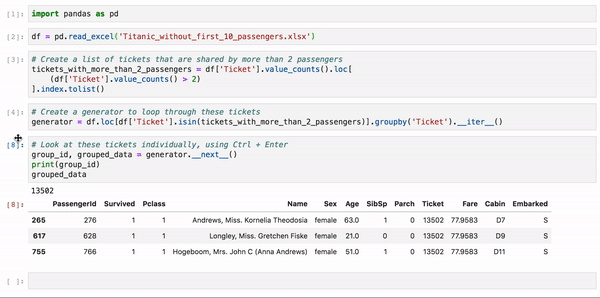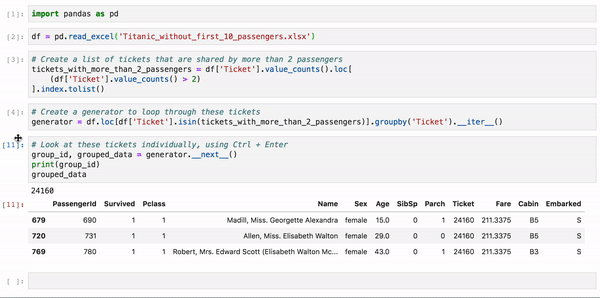
grouped_dataНа этом примере анализируется набор данных Titanic о пассажирах Титаника, у которых совпадают номера билетов. Так как у вас нет возможности исследовать каждую группу пассажиров по отдельности, вы можете воспользоваться этим несложным методом, чтобы проанализировать одну группу за другой:
2. Профилирование pandas для исследования данных и оценки их качества
Как часто бывает в науке о данных, мы обычно пишем код для исследования данных с нуля. Поскольку все наборы данных различны, это кажется логичным. Однако существует волшебный пакет pandas_profiling, который доказывает, что в этом нет необходимости. Пакет фактически автоматизирует этапы исследования и оценки качества данных! Взгляните:
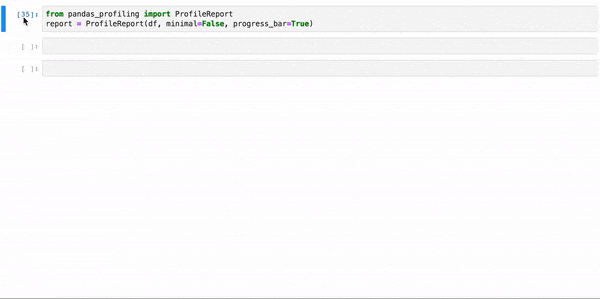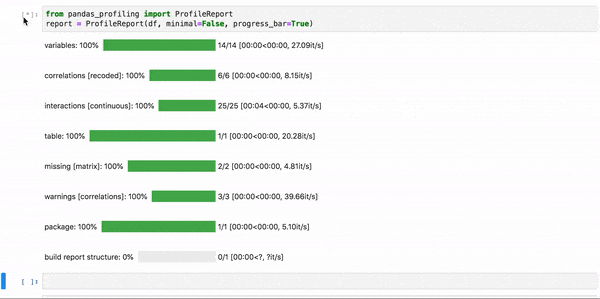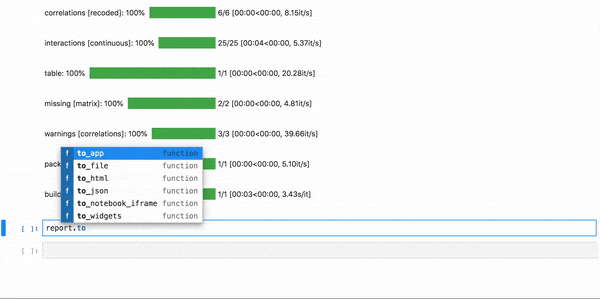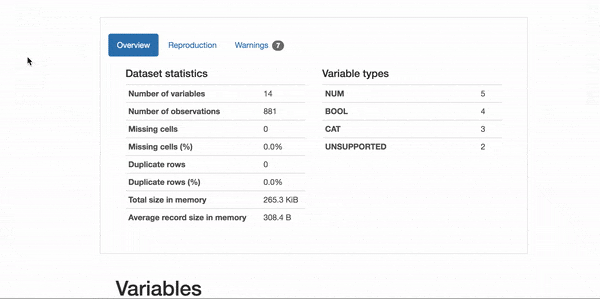
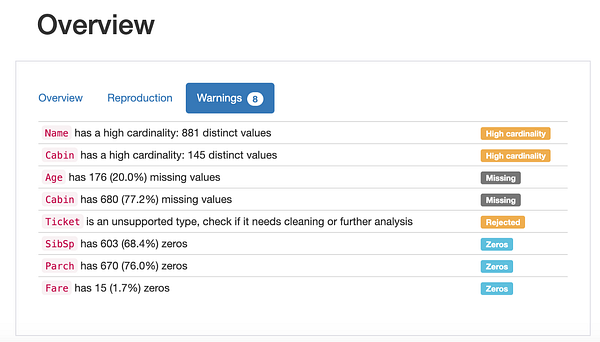
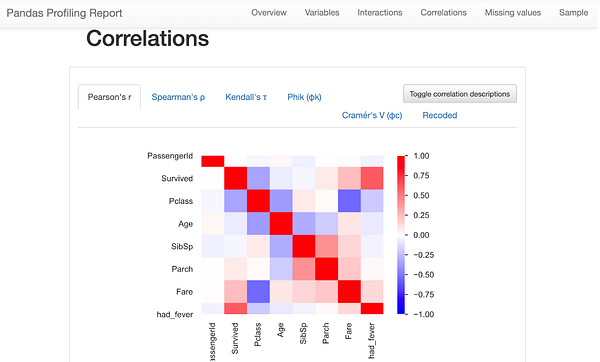
Похоже на магию!
Очевидно, что пакет pandas-profiling дает в наше распоряжение только общее приблизительное представление о данных. Например, он не поможет, если в ваших данных есть независимые текстовые переменные. Но начинать анализ любых наборов данных следует именно с этого.
3. Цепочка методов
Работа с pandas становbтся действительно интересной, как только вы понимаете, что можно объединять несколько операций, используя цепочку методов. По сути, формирование цепочки — это добавление операций в одну и ту же “строку” кода.
С помощью приведенной ниже строки кода я:
- добавляю новый столбец в мой набор данных (.merge);
- подсчитываю процент пассажиров женского пола (.apply(female_proportion));
- для групп, состоящих более чем из одного пассажира (df.Ticket.value_counts()>1);
- для групп с одинаковым номером билета (.groupby (“Ticket “)).
def female_proportion(dataframe):
return (dataframe.Sex=='female').sum() / len(dataframe)
female_proportion(df)
df.merge(
df.loc[
df.Ticket.isin(
df.Ticket.value_counts().loc[
df.Ticket.value_counts()>1
].index
)
].groupby('Ticket').apply(female_proportion) \
.reset_index().rename(columns={0:'proportion_female'}),
how='left', on='Ticket'
)Мне не пришлось создавать новые датафреймы, новые переменные или что-либо еще. Цепочка методов позволяет “переводить” свои идеи в реальные операции.
Далее мы можем увидеть еще один хороший пример цепочки методов.
4. Визуализация данных
Если вы занимаетесь машинным обучением, вы знаете, как нелегко бывает объяснить свою модель машинного обучения доступным языком. Вам может помочь качественная визуализация коэффициентов или оценки важности переменных вашей модели.
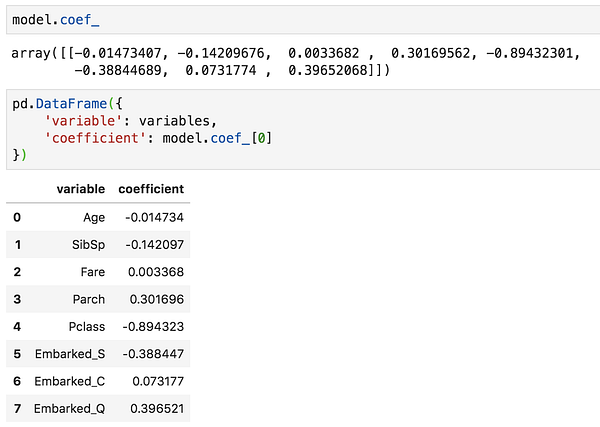
Я собрал код из нескольких источников, чтобы получить следующую визуализацию, которую я теперь использую постоянно, чтобы не изобретать велосипед:
pd.DataFrame({
'variable': variables,
'coefficient': model.coef_[0]
}) \
.round(decimals=2) \
.sort_values('coefficient', ascending=False) \
.style.bar(color=['grey', 'lightblue'], align='zero')Что дает следующий результат:
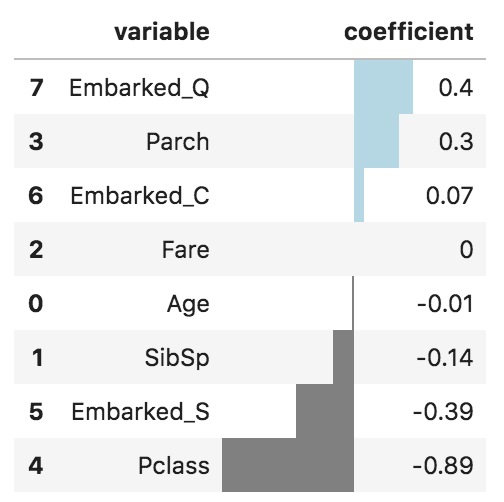
Довольно наглядно, верно?
5. sklearn_pandas
Если вы сторонник pandas, вы уже не раз замечали, что DataFrame pandas и sklearn не всегда хорошо работают в связке. Но не опускайте руки! Группа энтузиастов создала пакет sklearn_pandas, мост между двумя библиотеками. Он заменяет ColumnTransformer от sklearn на удобный для pandas DataFrameMapper. Теперь я использую только sklearn_pandas, чем очень доволен. Очень жаль, что я не знал о нем раньше!
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn_pandas import DataFrameMapper
from category_encoders import LeaveOneOutEncoder
imputer_Pclass = SimpleImputer(strategy='most_frequent', add_indicator=True)
imputer_Age = SimpleImputer(strategy='median', add_indicator=True)
imputer_SibSp = SimpleImputer(strategy='constant', fill_value=0, add_indicator=True)
imputer_Parch = SimpleImputer(strategy='constant', fill_value=0, add_indicator=True)
imputer_Fare = SimpleImputer(strategy='median', add_indicator=True)
imputer_Embarked = SimpleImputer(strategy='most_frequent')
scaler_Age = MinMaxScaler()
scaler_Fare = StandardScaler()
onehotencoder_Sex = OneHotEncoder(drop=['male'], handle_unknown='error')
onehotencoder_Embarked = OneHotEncoder(handle_unknown='error')
leaveoneout_encoder = LeaveOneOutEncoder(sigma=.1, random_state=2020)
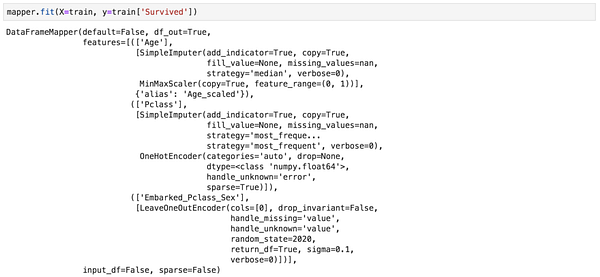
mapper = DataFrameMapper([
(['Age'], [imputer_Age, scaler_Age], {'alias':'Age_scaled'}),
(['Pclass'], [imputer_Pclass]),
(['SibSp'], [imputer_SibSp]),
(['Parch'], [imputer_Parch]),
(['Fare'], [imputer_Fare, scaler_Fare], {'alias': 'Fare_scaled'}),
(['Sex'], [onehotencoder_Sex], {'alias': 'is_female'}),
(['Embarked'], [imputer_Embarked, onehotencoder_Embarked]),
(['Embarked_Pclass_Sex'], [leaveoneout_encoder])
], df_out=True) # используйте df_out для вывода как датафрейма pandas
mapper.fit(X=train, y=train['Survived']) # вставляете как ColumnTransforme rsklearnВот пример выходных данных после использования метода .fit():
6. tqdm
При работе с большими наборами данных на их обработку потребуется какое-то время. Вместо того, чтобы скучать в ожидании неизвестности перед своим блокнотом Jupyter, используйте tqdm, чтобы отследить, выполняется ли ваш код, и узнать время, которое потребуется для его обработки. Это также хороший способ прервать сценарий, который выполняется слишком медленно, на ранней стадии.
from tqdm import notebook
notebook.tqdm().pandas()Теперь во всех датафреймах pandas есть новые методы:
- .progress_apply, .progress_applymap
- .progress_map для столбцов
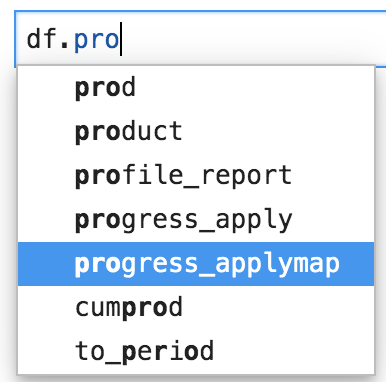
Они отличаются от apply, applymap и map лишь тем, что графически отображают индикатор выполнения. Очень полезно!

7. Метод .to_clipboard () для экспорта в Excel
Будучи преданным поклонником Excel, я отточил навыки создания привлекательных графиков и хорошего форматирования, чтобы показывать информацию, полученную из анализа данных. Несмотря на то, что pandas предлагает много дополнительных возможностей, получить аналогичный уровень вывода, практически не используя код, может быть нелегко.
Мне пришлось потрудиться, чтобы решить эту проблему, но в конечном итоге я нашел выход — экспортировать свои результаты в Excel. Однако вместо метода .to_excel я использую более мягкий метод .to_clipboard (index=False), который копирует данные в буфер обмена. Затем я использую Ctrl + V в Excel, чтобы вставить данные в свою текущую электронную таблицу. Вот и все, теперь вы можете выпустить на волю своего внутреннего зверя Excel!
Многие специалисты по обработке данных часто забывают, что ученые, не работающие с данными, как правило, хорошо разбираются в Excel. Проще поделиться с ними файлом Excel, чем обычным блокнотом или блокнотом, экспортированным в виде html-файла.
Спасибо за чтение!
Читайте также:
- TextHero - самый простой способ чистки и анализа текста в Pandas
- Импорт в Python
- Python 3: 3 функции, которые следует помнить
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Félix Revert: 7 advanced pandas tricks for data science





