
Абстракция датафрейма является одной из наиболее полезных концепций в современной экосистеме управления данными. Вращается она главным образом вокруг табличных структур, которые имеют повышенную производительность при обновлении и запросе данных различными способами. Сериализация/десериализация этих структур из/в различные форматы файлов упрощает работу с данными. Более того, возможность производить различные SQL-подобные операции, такие как объединение, наряду с выполнением математических вычислений в самом датафрейме существенно расширяет возможности программиста.
Эта статья подчеркивает некоторые наиболее полезные операции, которые можно выполнять с помощью абстракции датафрейма. Реализовывать мы их будем через библиотеку Pandas. Постараюсь представить материал в интуитивно понятной форме, чтобы в дальнейшем вы могли применить эти знания в других случаях или при работе с другими фреймворками.
1. Конкатенация DataFrame
Есть два способа конкатенировать датафрейм A и B. Представьте их как проиндексированные таблицы. Эти две таблицы можно объединить либо по оси y, либо по оси x.
Если требуется конкатенировать их вдоль x, то вызов API будет таким:
import pandas as pdpd.concat([A, B], axis=1)
Если же вдоль y, то таким:
import pandas as pdpd.concat([A, B]) # по умолчанию axis = 0
Применение
Предположим, у вас есть большое количество CSV-файлов или XLSX-данных, которые нужно присоединить друг к другу. Одним из способов сделать это будет считать данные файлов в датафреймы и использовать инструкцию pd.concat([file_1, file_2]). Программно можно перебрать имена файлов (используя модуль glob для чтения набора имен файлов с помощью техники сопоставления шаблонов, например regex), считать их в датафрейм, соединить в памяти и сериализовать конкатенированные датафреймы в нужный формат файлов.
Вариант с axis = 0 используется нечасто, но его можно применять в сценариях, когда нужно обработать массивы данных, собранных с упорядочиванием. То есть, когда последовательность данных соответствует последовательности других массивов данных. В таком случае эти массивы можно объединить вдоль оси x, получив более объемное и значительное представление в табличном формате. Затем к полученной структуре можно применять операции, использующие все типы данных в ее столбцах.
2. Разделение DataFrame
Датафрейм можно разделить множеством способов, и выбор техники полностью зависит от цели этого разделения. Рассмотрим ряд случаев.
Просмотр сведений
В некоторых сценариях, особенно при написании кода с помощью блокнотов (например Jupyter), мы заглядываем в датафрейм, только чтобы понять, как он выглядит. В таких случаях можно использовать метод head().
import pandas as pdprint(df.head(10)) # выводит первые 10 строк dataframe
Исключение столбцов
Этот метод разделяет датафрейм вдоль оси y, то есть просто выбрасывает из него часть столбцов. Используется данный метод в типичном сценарии, когда нам не нужно, чтобы конечный DataFrame содержал эти столбцы, или когда мы предполагаем, что при дальнейшем обновлении структура станет занимать слишком много памяти.
import pandas as pddf.drop('COLUMN_NAME', inplace=True, axis=1)
# указывает, что 'COLUMN_NAME' находится на оси x
Удаление датафреймов друг из друга
Представим, что у нас есть датафрейм X, состоящий из столбцов [A, B, C, D], и датафрейм Y, состоящий из подмножества столбцов X. Нам нужно удалить Y из X. Это можно сделать так:
import pandas as pdpd.concat([X, Y]).drop_duplicates(keep=False)
Конкатенация этих датафреймов приведет к дублированию общих записей, которые в итоге будут удалены выражением keep = false функции drop_duplicates().
Применение
Предположим, что столбец A — это определенный вид ID сведений о работнике. К примеру, датафрейм X состоит из всех данных о работниках, а датафрейм Y содержит данные (с той же структурой) о работниках, не разбирающихся в Python. Нам нужно отфильтровать сведения о сотрудниках, которые не знакомы с Python.
Определение дельты записей на основе столбца
Представим, что у нас есть датафрейм X, состоящий из столбцов [A, B, C, D], а также датафрейм Y, состоящий из тех же столбцов. При этом некоторые элементы столбцов A этих датафреймов являются общими. Нам нужно получить из датафрейма X строки, которые не содержат значения из столбца A, находящиеся в столбце A датафрейма Y.
import pandas as pdX[~X['A'].isin(Y['A'])]
Применение
Взгляните на эту таблицу:
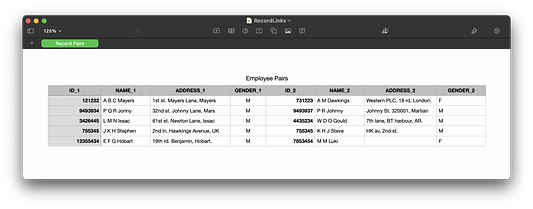
Эти пары могли быть сгенерированы, например, из двух журналов: старого и нового. Нам нужно найти пары ID, принадлежащие одному и тому же человеку. Предположим, что ваш отдел кадров неожиданно заявляет, что определенный список (hr_list) сотрудников с ID_1 больше в компании не работает. Как удалить их из этого датафрейма?
import pandas as pdfiltered_pairs = employee_pairs[~employee_pairs['ID_1'].isin(hr_list)]Разделение на основе значений столбцов
Датафрейм можно фильтровать на основе значений столбца. В этом случае критерий отбора может включать несколько выражений при условии, что они будут возвращать логические значения.
import pandas as pdfiltered_df = df[~df['A'].isna() & (df['B'] > 10)]
# Возвращает строки, где столбец A не null, а значение столбца B больше 10.Это простейший пример.
3. Подсчет записей в столбце
Это эффективный способ определения количества различных элементов в столбце.
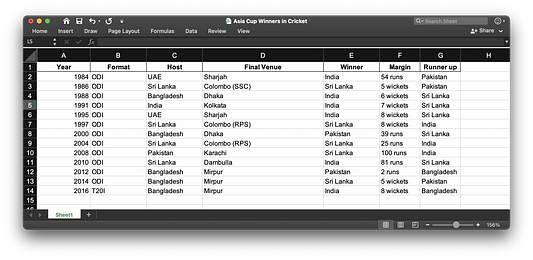
Ответ на приведенный выше запрос можно получить следующим подходом:
import pandas as pd
df = df[ (1984 <= df['Year']) & (df['Year'] <= 2014) ]['Host'].value_counts().reset_index()
df.columns = ['Contry', 'Count']
{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"colab": {
"name": "Host Countries.ipynb",
"provenance": []
},
"kernelspec": {
"name": "python3",
"display_name": "Python 3"
}
},
"cells": [
{
"cell_type": "code",
"metadata": {
"id": "502dBbjWHq89"
},
"source": [
"import pandas as pd\n",
"\n",
"df = pd.read_excel('Asia Cup Winners in Cricket.xlsx')"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "14WfNdQRIjWw",
"outputId": "2b1e8cc9-75c1-40a5-8d2b-b45ed1641723"
},
"source": [
"df.shape"
],
"execution_count": null,
"outputs": [
{
"output_type": "execute_result",
"data": {
"text/plain": [
"(13, 7)"
]
},
"metadata": {
"tags": []
},
"execution_count": 9
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "eSwxxIeTH90N"
},
"source": [
"df = df[ (1984 <= df['Year']) & (df['Year'] <= 2014) ]"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "1X6LwBL-IBcB",
"outputId": "9277501d-c02e-4345-a38c-66371d50979d"
},
"source": [
"df.shape"
],
"execution_count": null,
"outputs": [
{
"output_type": "execute_result",
"data": {
"text/plain": [
"(12, 7)"
]
},
"metadata": {
"tags": []
},
"execution_count": 11
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "ZC1nYNy1IaT5"
},
"source": [
"df = df['Host'].value_counts().reset_index()\n",
"df.columns = ['Country', 'Counts']"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 204
},
"id": "PdFw0MMkIwDH",
"outputId": "8daa83cb-af9f-41aa-b3e9-71d6a948de51"
},
"source": [
"df"
],
"execution_count": null,
"outputs": [
{
"output_type": "execute_result",
"data": {
"text/html": [
"<div>\n",
"<style scoped>\n",
" .dataframe tbody tr th:only-of-type {\n",
" vertical-align: middle;\n",
" }\n",
"\n",
" .dataframe tbody tr th {\n",
" vertical-align: top;\n",
" }\n",
"\n",
" .dataframe thead th {\n",
" text-align: right;\n",
" }\n",
"</style>\n",
"<table border=\"1\" class=\"dataframe\">\n",
" <thead>\n",
" <tr style=\"text-align: right;\">\n",
" <th></th>\n",
" <th>Country</th>\n",
" <th>Counts</th>\n",
" </tr>\n",
" </thead>\n",
" <tbody>\n",
" <tr>\n",
" <th>0</th>\n",
" <td>Sri Lanka</td>\n",
" <td>4</td>\n",
" </tr>\n",
" <tr>\n",
" <th>1</th>\n",
" <td>Bangladesh</td>\n",
" <td>4</td>\n",
" </tr>\n",
" <tr>\n",
" <th>2</th>\n",
" <td>UAE</td>\n",
" <td>2</td>\n",
" </tr>\n",
" <tr>\n",
" <th>3</th>\n",
" <td>Pakistan</td>\n",
" <td>1</td>\n",
" </tr>\n",
" <tr>\n",
" <th>4</th>\n",
" <td>India</td>\n",
" <td>1</td>\n",
" </tr>\n",
" </tbody>\n",
"</table>\n",
"</div>"
],
"text/plain": [
" Country Counts\n",
"0 Sri Lanka 4\n",
"1 Bangladesh 4\n",
"2 UAE 2\n",
"3 Pakistan 1\n",
"4 India 1"
]
},
"metadata": {
"tags": []
},
"execution_count": 13
}
]
}
]
}4. Чтение фрагментов DataFrame
В некоторых случаях будет более эффективно считывать только части датафрейма, особенно при его больших размерах. Обратите внимание, что каждый датафрейм является индексированной табличной структурой, находящейся в памяти, а значит потребляющей пространство, потенциально нужное другим структурам данных. В связи с этим при работе с большими массивами информации всегда лучше считывать только ее нужную часть.
import pandas as pdpd.read_csv('file.csv', usecols=['A', 'B'])
# Считать только столбцы 'A' и 'B'Более того, можно считывать большие файлы в отдельные фрагменты и маршалировать их в датафреймы.
import pandas as pdfor chunk in pd.read_csv('file.csv', chunksize=1000):
process(chunk)Таким образом одновременно в памяти удерживается только фрагмент размером chunksize.
5. Применение функций к строкам
Бывают случаи, в которых требуется внести изменения в конкретные столбцы детафрейма. К примеру, в датафрейме X, содержащем столбцы A, B и C, мы можем применить функцию f() к значениям столбца B, чтобы сохранить их в столбце D.
import pandas as pddf['D'] = df.apply(lambda row: f(row['B'], row['C']), axis=1)
Эта операция окажется намного быстрее, чем перебор всего датафрейма с помощью iterrows().
Есть и альтернативный метод. Его можно использовать, когда функцию f() требуется применить только к одному столбцу.
import pandas as pddf['D'] = df['B'].map(lambda b: f(b))
6. Объединение двух датафреймов
По аналогии с реляционными базами данных датафреймы можно объединять merge , используя разрешающий столбец.
import pandas as pdpd.merge(left=df_a, left_on['A'], right=df_b, right_on=['B'], how='inner')
# Также работает для left и right объединения.Однако стоит заметить, что операция merge является дорогостоящей, в связи с чем перед слиянием больших датасетов стоит проявлять особое внимание. В случаях, когда датасеты слишком велики, рекомендуется использовать методы группировки (англ.), чтобы избежать перегрузки памяти и связанных с этим проблем производительности.
7. Переименование столбцов
Переименовывать столбцы особенно полезно перед сериализацией файла или перед внедрением стороннего хранилища данных.
import pandas
df = df.rename(columns={
"A_1": "A"
"B_1": "B"
})
# переименовывает оригинальные столбцы ["A_1", "B_1"] в ["A", "B"].Читайте также:
- Новая библиотека превосходит Pandas по производительности
- 7 трюков pandas для науки о данных
- Хватит использовать Pandas, пора переходить на Spark + Scala!
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод Dasun Pubudumal: 7 Useful Pandas Operations To Use on DataFrames





