
Contribution Explorer является частью Snowflake Cortex — полностью управляемого сервиса искусственного интеллекта и машинного обучения. В этом обзоре рассмотрим примеры использования TOP_INSIGHTS для оптимизации процесса анализа первопричин изменений наблюдаемых показателей.
Настройка
Данные, используемые для демонстрации этой функции, представляют собой случайно сгенерированные данные колл-центра.

Каждая строка — это звонок клиента в колл-центр. Параметры, указанные в таблице:
- местоположение колл-центра (call center location);
- группа колл-центра (call center group);
- период взаимодействия клиента с компанией (customer tenure);
- эскалация (escalation);
- продолжительность вызова (call duration).
Функция, которую выполняет TOP_INSIGHTS, заключается в автоматизации всей аналитической работы. Чтобы установить разницу между двумя группами, обычно приходится секционировать и фрагментировать данные таблицы, вручную сравнивая каждое измерение со всеми другими. TOP_INSIGHTS проводит эвристическое оценивание пространства, а затем выделяет сегменты, имеющие существенные различия между собой.
Принцип работы модели
Модель TOP_INSIGHTS ведет себя так, как человек, пытающийся понять разницу между двумя “группами” данных. В процессе построения моделью дерева извлекаются группы, или сегменты. При построении новой ветви создается новый сегмент. Это означает, что модель определила интересную дифференциацию, которая отделяет контрольную группу от тестовой (например, среднее количество обращений в колл-центр по сравнению с количеством аномальных звонков).
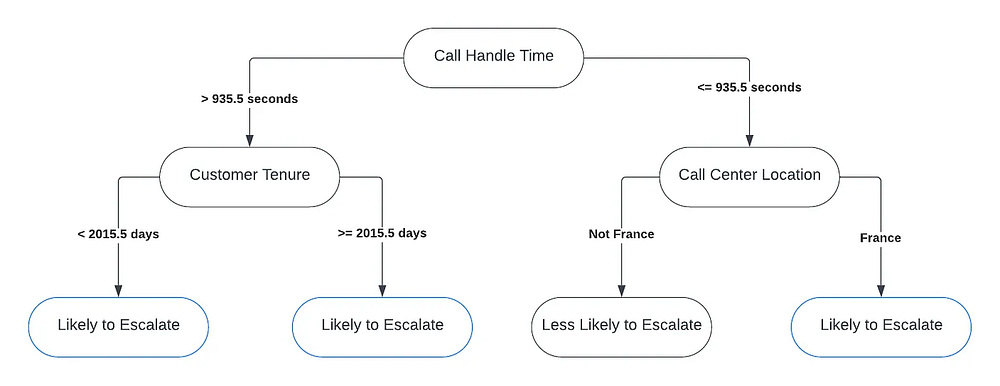
Запуск модели
Вызовите модель с помощью функции SNOWFLAKE.ML.TOP_INSIGHTS.
create or replace table escalated_analysis_results as (
WITH input AS (
SELECT
{
'call center': call_center,
'cc group': cc_group,
'product': product
}
AS categorical_dimensions,
{
'customer tenure': customer_tenure,
'call handle time': handle_time
}
AS continuous_dimensions,
1.0 as metric,
escalated::boolean as label
FROM calls
WHERE
(ts BETWEEN '2023-01-01' AND '2023-04-15')
)
SELECT res.* from input, TABLE(
SNOWFLAKE.ML.TOP_INSIGHTS(
input.categorical_dimensions,
input.continuous_dimensions,
metric::float,
input.label
)
OVER (PARTITION BY 0)
) res
);
Если проанализировать приведенный выше пример, то первым шагом будет построение категориальных измерений с помощью call_center, cc_group и product. Функция работает путем обнаружения сегментов, которые различаются между двумя совокупностями, разделенными категориальными и непрерывными метками. В данном случае рассматриваем метрики, связанные с “call center” (“колл-центр”), “cc group” (“группа колл-центра”), “product” (“продукт”), в отличие от “customer tenure” (“период взаимодействия клиента с компанией”) и “call handle time” (“время обработки звонка”).
Поскольку нам нужно установить значение эскалации как меру контроля, метрика равна 1.0. Каждый звонок или каждое измерение разбиваются на группы и считаются за 1 при определении вероятности того, будет ли звонок эскалирован или нет. Последний аргумент, OVER (PARTITION BY 0), позволяет объединить определенные группы данных, если в этом есть необходимость. Однако в данном случае мы не делаем разделения ни по чему, что, по сути, сводит аргумент на нет. Посмотрим на результат:

- Столбец RELATIVE_CHANGE (относительное изменение) представляет собой отношение шансов (OR). Это отношение вероятности события в одной группе к вероятности события в другой.
- Например, если в группе есть определенное количество звонков, то, исходя из средних значений, можно ожидать, что 4000 звонков будут эскалированы, но на самом деле их 12000, поэтому отношение шансов на 2,77 превышает статистически ожидаемое.
- Вот так сюрприз! Вероятность эскалации звонка в 3 раза выше у клиентов с периодом взаимодействия с компанией от 3 лет и большим временем обработки.
Относительное изменение аналогично отношению шансов, или уровню риска в статистике. Рассмотрим его на другом примере: применим относительное изменение для определения эффективности взаимного фонда по отношению к фондовому рынку в течение одной недели. Допустим, данный взаимный фонд за неделю заработал 100 миллионов долларов. Как понять, хорошая это в целом новость или плохая?
Если копнуть глубже, то выясним: общие активы взаимного фонда равны 5 миллиардам, что означает рост на 2% за неделю. Если бы рынок в целом вырос на 1,5%, это было бы хорошей новостью, потому что относительное изменение во взаимном фонде было бы в 1,33 раза больше, чем на рынке, или на 33% эффективнее. Однако, если бы рынок в целом вырос на 3%, это было бы плохой новостью, потому что относительное изменение взаимного фонда по сравнению с рынком составило бы 0,67 раза, или на 33% хуже, чем в среднем.
Расшифровка результатов
Первоначальный вывод дал набор результатов по 550 сегментам, что не очень удобно для восприятия человеческим глазом. Чтобы осмыслить данные, отфильтруем определенные сегменты, например те, у которых relative_change (относительное изменение) больше 1, и только те, чьи влияющие факторы положительно коррелируют с сегментом.
select
contributor,
metric_test as actual,
TRUNC(expected_metric_test) as expected,
TO_VARCHAR(relative_change, '9.99') as ratio
from escalated_analysis_results
WHERE
ABS(relative_change - 1) > 0.4
AND NOT ARRAY_TO_STRING(contributor, ',') LIKE '%not%'
ORDER BY ratio desc limit 50;

Теперь по данным видно, что когда “время обработки вызова” превышает 15 минут, звонок эскалируется в 2 раза чаще, чем когда вызов короче 15 минут.
Разберемся с другими столбцами выходных данных модели.
- METRIC_CONTROL — фактическая метрика для сегмента в контрольной группе (подсчитывается или суммируется).
- METRIC_TEST — то же самое для тестовой группы.
- SURPRISE — разница между фактической и ожидаемой метрикой в тестовой группе.
- RELATIVE_CHANGE — соотношение между фактическим и ожидаемым. Отношение, равное 1, является нейтральным, т. е. неинтересным. В научных исследованиях подобные числа называются отношением шансов или уровнем риска (эквивалентно GROWTH_RATE/OVERALL_GROWTH_RATE).
- GROWTH_RATE — METRIC_TEST/METRIC_CONTROL (ошибочное наименование неравных тестовых и контрольных групп, например 1 неделя против 4 недель).
- EXPECTED_METRIC_TEST — ожидаемая метрика, если данный сегмент не имеет различий в поведении между тестовой и контрольной группами.
- OVERALL_METRIC_CONTROL — суммарный показатель метрик в контрольной группе.
- OVERALL_METRIC_TEST — сумма метрик в тестовой группе.
- OVERALL_GROWTH_RATE — OVERALL_METRIC_TEST/OVERALL_METRIC_CONTROL.
- NEW_IN_TEST — истинное значение, если данный сегмент появился в тестовой, но не в контрольной группе.
- MISSING_IN_TEST — истинное значение, если данный сегмент появился в контрольной, но не в тестовой группе.
Дополнительный пример
Изучение объема звонков с течением времени:
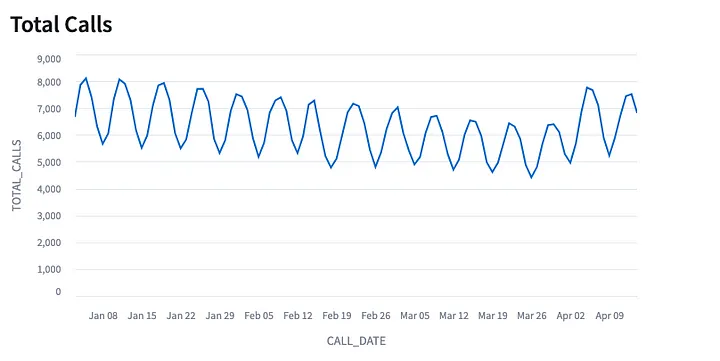
Объем звонков достиг пика в апреле. Используем TOP_INSIGHTS для сравнения группы звонков, эскалированных в апреле, с группой звонков до апреля, чтобы определить причину эскалации.
create or replace table more_time_analysis_results as (
WITH input AS (
SELECT
{
'call center': call_center,
'cc group': cc_group,
'product': product,
'escalated': escalated
}
AS categorical_dimensions,
{
'customer tenure': customer_tenure,
'call handle time': handle_time
}
AS continuous_dimensions,
handle_time as metric,
IFF(ts BETWEEN '2023-04-01' AND '2023-04-15', TRUE, FALSE) AS label
FROM calls
WHERE
(ts BETWEEN '2023-01-01' AND '2023-04-15')
)
SELECT res.* from input, TABLE(
SNOWFLAKE.ML.TOP_INSIGHTS(
input.categorical_dimensions,
input.continuous_dimensions,
metric::float,
input.label
)
OVER (PARTITION BY 0)
) res
);
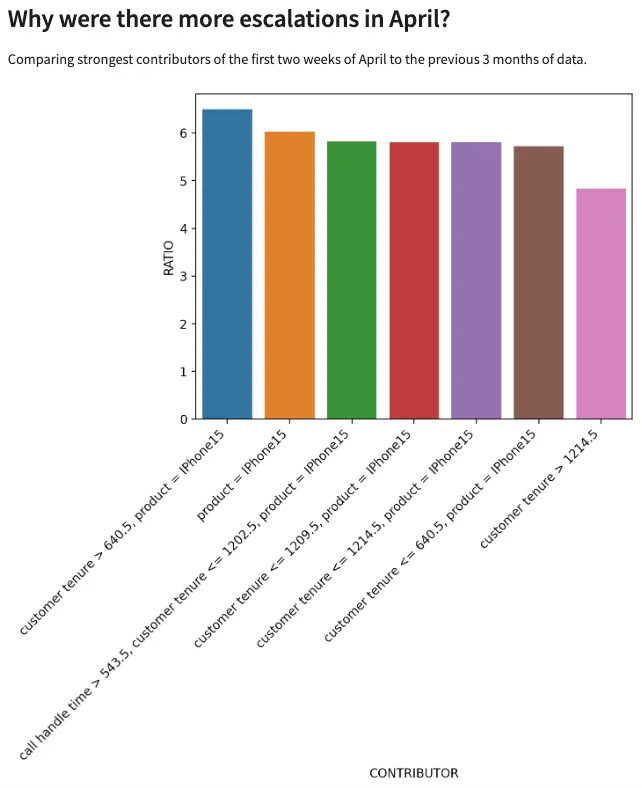
Судя по самым высоким показателям RELATIVE_CHANGE, наибольший вклад в эскалацию звонков внесли высокая продолжительность обработки вызовов и длительный период взаимодействия клиента с компанией. Данные также показывают, что в апреле клиенты, обратившиеся в колл-центр по поводу iPhone15, были наиболее склонны к эскалации звонков.
Другие возможные случаи применения TOP_INSIGHTS:
- Определение общего времени, проведенного в колл-центре.
- Сравнение длительной продолжительности звонков с короткой.
- Сравнение звонков в 90-м процентиле со звонками в 20-м процентиле для нахождения сегментов с высокой неожиданностью по сравнению с низкой неожиданностью.
От теории к практике
TOP_INSIGHTS не дает рекомендаций или предсказаний относительно того, что произойдет, когда клиент обратится в компанию, однако она помогает обнаружить ключевые точки данных. Ценность использования этой функции заключается в автоматизации ручного процесса извлечения первопричины из наборов данных с большим количеством измерений. В данном случае функция смогла указать на то, что клиенты с большим периодом взаимодействия с компанией, скорее всего, вызовут эскалацию, если звонок продлится более 10 минут. В дальнейшем колл-центр может принять решение об упреждении эскалации со стороны таких клиентов до истечения 10 минут, тем самым повышая удовлетворенность клиентов и улучшая их опыт взаимодействия со службой поддержки.
Читайте также:
- Запуск DBT в Azure Functions с помощью Snowflake
- Как Snowflake повышает эффективность dbt-моделей на Python
- Что такое Snowflake ID?
Читайте нас в Telegram, VK и Дзен
Перевод статьи Amber Beebe: Using Snowflake to Predict Call Center Escalation





