
Генерация уникальных ID — это задача, с которой всем программистам приходилось сталкиваться на определенном этапе цикла разработки приложения. Уникальные ID позволяют нам правильно идентифицировать объекты данных, сохранять их, извлекать и привлекать к сложным реляционным структурам.
Но как генерируются эти уникальные ID и какой подход лучше всего работает при различных масштабах нагрузки? Как они остаются неповторяющимися в распределенной среде, где несколько вычислительных узлов конкурируют за следующий доступный ID?
В этой статье я рассмотрю три наиболее распространенных работающих метода — от небольшого, одноузлового масштаба, до объемов Twitter.
Универсальные уникальные ID — UUID
Это хорошо известная концепция, которая используется в ПО много лет. UUID — это 128-битное число, которое, будучи сгенерированным контролируемым и стандартизированным способом, обеспечивает чрезвычайно большое пространство ключей, практически исключая возможность коллизии.
UUID — это искусственный ID, состоящий из нескольких отдельных частей, таких как время, MAC-адрес узла или хешированное пространство имен MD5. Для размещения всех этих комбинаций на протяжении многих лет существовало несколько версий спецификации UUID, в частности версии 1 и 4. Однако и другие версии могут представлять интерес в зависимости от ваших данных и области бизнеса.
Работа со 128-битными числами — не самый удобный для разработчиков способ отображения информации, поэтому UUID обычно представлены в канонической текстовой форме, где 16 октетов (16 * 8 бит = 128 бит) преобразуются в 32 шестнадцатеричных символа, разделенных дефисами, в сумме 36:

Становится очевидным то, что наиболее интересной особенностью UUID является факт их способности генерироваться изолированно и при этом гарантировать уникальность в распределенной среде. Кроме того, базовый алгоритм генерации ID не является сложным и не требует синхронизации (по крайней мере до 100-наносекундного уровня), поэтому он может выполняться параллельно:
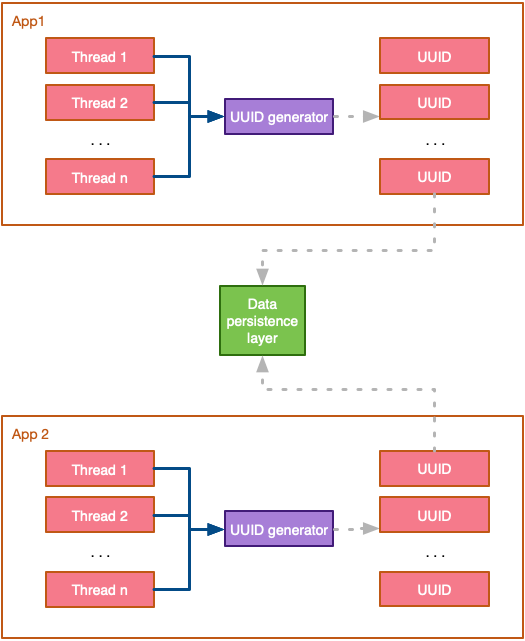
Внутреннее свойство уникальности самогенерации делает UUID одним из наиболее часто используемых методов в распределенных средах. Однако имейте в виду, что UUID требуют дополнительного хранилища и могут негативно повлиять на производительность запросов.
Сгенерированные ID на уровне хранения
Уникальные ID не принято генерировать на уровне приложения. Вместо этого об ID заботится постоянное хранилище. Все недавние СУБД предоставляют некий тип данных столбца, позволяющий делегировать им генерацию уникального ID. MongoDB предоставляет ObjectID, MySQL и MariaDB предоставляют AUTO_INCREMENT, MS SQL Server предоставляет IDENTITY и т.д. Фактическое представление ID отличается в разных реализациях БД, однако семантика уникальности остается неизменной.
Подобные значения, созданные на уровне хранения,облегчают проблему генерации уникальных ID в коде приложения. Однако, если вы управляете большим кластером БД с очень загруженным приложением на фронте, этот подход может оказаться недостаточно эффективным.
Еще одна реальная проблема при использовании таких ID заключается в том, что они неизвестны вашему коду без обратного обращения к БД:
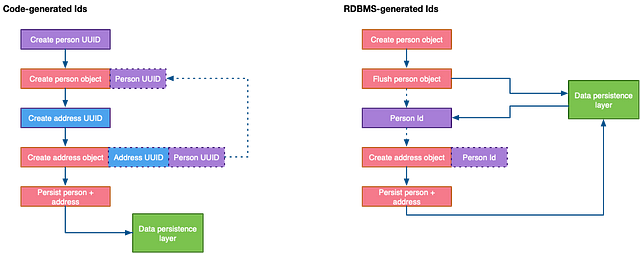
Описанный выше дополнительный переход к СУБД может замедлить работу приложения и усложнить код без надобности, однако современные ORM-фреймворки могут помочь выполнить генерацию стандартизированным способом, независимо от базового продукта СУБД, который вы используете.
ID сервера или ID Snowflake
Сервер ID заботится о создании уникальных ID для распределенной инфраструктуры. В соответствии с реализацией он может быть или одним, или целым кластером серверов, генерирующим большое количество ID в секунду.
Twitter не нуждается в особом представлении и со средним показателем 9000 твитов в секунду и максимумом до 143199 твитов в секунду, им нужно было решение, которое не только масштабировалось под их обширную инфраструктуру серверов, но и генерировало ID, эффективные для хранения. Вот так Twitter придумал проект “Snowflake” :
Snowflake — это сетевой сервис для генерации уникальных ID в большом количестве с некоторыми простыми гарантиями.
Twitter искал минимум 10000 ID в секунду для каждого процесса с частотой отклика <2 мс. Серверы не должны были требовать никакой взаимной сетевой координации, а генерируемые ID должны быть, грубо говоря, упорядочены по времени. И кроме того, чтобы свести хранение к минимуму, ID должны быть компактными.
Для решения вышеупомянутых задач, Twitter разработал проект Snowflake в качестве сервера Thrift, написанного на Scala. Сгенерированные ID состояли из:
- Времени — 41 бит (точность миллисекунды);
- ID настроенной машины — 10 бит;
- Порядковый номер — 12 бит — меняется через каждые 4096 на машину.
Хотя Snowflake теперь находится в отставке, будучи замененным более крупным проектом TwitterServer, основные принципы работы распределенного генератора ID все еще применимы. Благодаря независимому характеру каждого генератора, Twitter смог масштабировать свою инфраструктуру по мере необходимости, не вводя дополнительных задержек благодаря кластерной синхронизации и координации.
Решение с сервером работает аналогично ID, сгенерированному кодом:
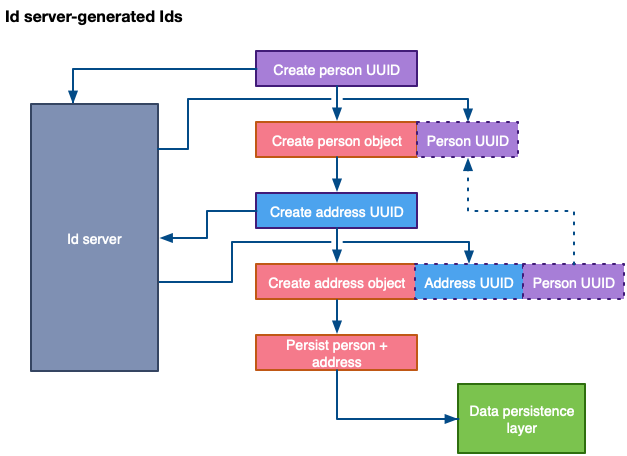
Как вы можете заметить, производительность все еще снижается из-за циклических переходов на сервер ID, однако это значительно меньше, чем отправка объекта в СУБД, поскольку здесь отсутствуют сложные операции с базой.
Сервер ID предоставляет промежуточное решение, позволяющее вам контролировать, как и где генерируются уникальные ID без сложной инфраструктуры с высокой задержкой.
Вывод
Генерация уникальных ID является необходимостью для всех приложений, которые в конечном итоге нуждаются в сохранении данных.
В статье обсуждались три широко используемых подхода: UUID — генерация ID локально; ID, управляемые уровнем хранения — централизованное создание ID; Snowflake ID — генерация сетевым сервисом.
При выборе стратегии создания уникальных ID в приложении необходимо учитывать конкретную специфику данных, а также параметры сохраняемости и сетевую инфраструктуру. Поскольку не существует универсального решения, вы должны оценить свои варианты и выбрать тот, который соответствует вашим требованиям и масштабу.
Спасибо за чтение!
Читайте также:
- Смертоносные интерфейсы
- Основные принципы дизайна для НЕ дизайнеров
- Java для начинающих: часть 3 из 4
Читайте нас в Telegram, VK и Дзен
Перевод статьи Nassos Michas: What Are Snowflake IDs?





