
Теперь, когда dbt (data build tool, инструмент моделирования данных) сделал Python неотъемлемой частью SQL-конвейеров, интересно посмотреть, какие возможности открывает использование Snowflake. Именно этому и посвящена данная статья. Готовы совершить исследовательское путешествие?
Что такое dbt?
dbt — это инструмент, помогающий управлять всеми трансформациями данных, которые выполняются в базах данных с использованием SQL.
Допустим, у вас есть таблица с общим числом клиентских заказов, и нужно подсчитать, сколько из них пришлось на праздничные дни. Выполнить эту задачу можно с помощью двух SQL-запросов.
- Добавить столбец
is_holidayв таблицуsf100_orders, объединив ее сall_holidays. Назвать полученную таблицуsf100_orders_annotated. - Подсчитать строки, для которых
is_holiday=trueв таблицеsf100_orders_annotated.
Эти два шага объединяют исходные данные, визуализированные с помощью dbt:

Используя dbt, можно записать эти две трансформации в виде “dbt-моделей”, которые представляют собой файлы, содержащие SQL и некоторую конфигурацию dbt (при необходимости):
-- sf100_orders_annotated.sql
{{ config(materialized='table') }}
select a.*, b.date is not null is_holiday
from {{ref('sf100_orders')}} a
left join {{ref('all_holidays')}} b
on a.o_orderdate = b.date
-- count_holidays.sql
{{config(materialized='table')}}
select count(*) total_days
, count_if(is_holiday) holiday_count
, holiday_count/total_days ratio
from {{ref('sf100_orders_annotated')}}
Эти два файла выглядят как типичный SQL, но с некоторым отличием. Вместо ссылок на таблицы dbt позволяет ссылаться на другие “модели” с помощью аннотаций {{ref(‘sf100_orders_annotated’)}}. Таким образом, dbt определяет связь и зависимости между всеми трансформациями, через которые проходят данные.
В этом и заключается суть dbt: писать SQL-трансформации в хорошо организованном виде, чтобы процессы работы с данными были должным образом протестированы, документированы и версионированы.
Новым в dbt является возможность писать эти трансформации не только на SQL, но и на Python. При этом все остальное будет работать как положено.
Первая dbt-модель на Python
Чтобы увидеть, как легко можно включить Python в dbt-конвейер, изменим приведенный выше файл sf100_orders_annotated.sql на sf100_orders_annotated.py:
# sf100_orders_annotated.py
import snowflake.snowpark.functions as F
def model(dbt, session):
df_sf100 = dbt.ref('sf100_orders')
df_holidays = dbt.ref('all_holidays')
joined_df = df_sf100.join(
df_holidays,
df_sf100['o_orderdate'] == df_holidays['date'],
'left'
)
joined_df = joined_df.withColumn(
'is_holiday',
F.col('date').isNotNull()
)
result_df = joined_df.select(df_sf100['*'], 'is_holiday')
return result_df
Выделим интересные моменты в этом коде.
- Есть возможность заменить SQL-модель dbt-моделью, написанной на чистом Python.
- dbt заботится о подключении ко всем зависимостям, используя ссылки на них, например
dbt.ref(‘sf100_orders’)иdbt.ref(‘all_holidays’). - Неважно, что используют эти dbt-модели — SQL или Python. Важно, что они являются источником данных для текущей модели.
- В конце этой модели нужно вернуть лишь датафрейм. Затем dbt материализует этот датафрейм в таблицу, которую смогут использовать другие модели — точно так же, как это было сделано с эквивалентной SQL-моделью.
- Для создания желаемого соединения между таблицами были использованы знакомые нам по PySpark функции манипулирования датафреймами.
- Но это не PySpark — это Snowpark Python Dataframes с большими преимуществами (которые будут рассмотрены далее).
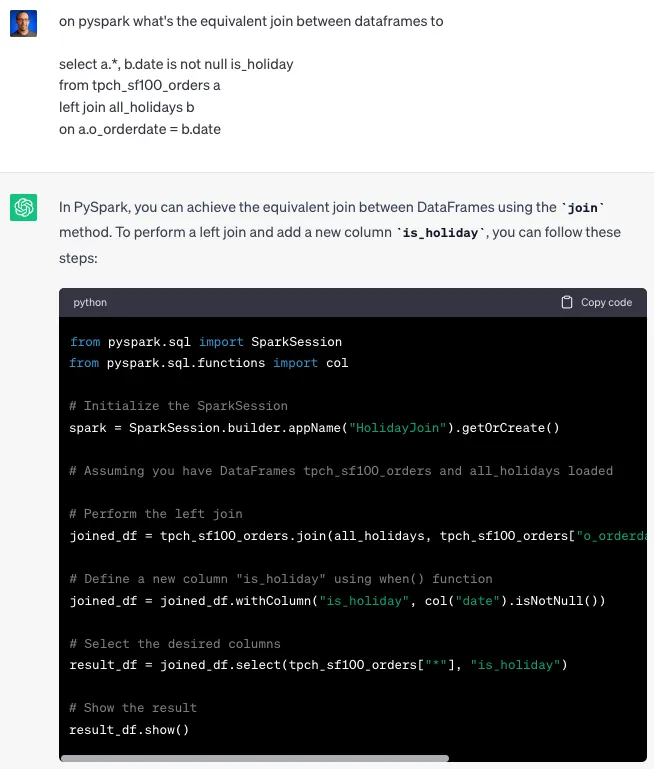
Бенчмаркинг этой dbt-модели Python на Snowflake
Объединим таблицу orders (заказов), содержащую 150 миллионов строк (прямо из TPC-H-SF100), с таблицей holidays (праздников), содержащей 458 строк. Объединение должно быть быстрым, а затем большая часть времени будет потрачена на рематериализацию таблицы в новую с теми же 150 миллионами строк, но уже с добавлением столбца is_holiday.
Время работы классической dbt-SQL-модели: 15 секунд на объединение двух таблиц и рематериализацию в результирующую таблицу.
Время работы dbt-Python-модели: 15 секунд (+9 секунд инициализации Python-кода).
Это хороший результат, который означает, что Snowflake удалось распараллелить Python-код для преобразования и материализации результирующей таблицы практически со скоростью чистого SQL.
Как dbt-модели, написанные на Python, работают на Snowflake
То, что делает dbt для обеспечения работы Python-моделей на Snowflake, по-настоящему круто: он переносит код модели (в основном нетронутый) на Snowflake, обернув его в хранимую процедуру Snowflake Python. Этот оберточный код берет на себя установку нужных библиотек, материализацию результирующего датафрейма и выполнение хранимой процедуры.
Как именно dbt справляется с этой задачей, можно узнать, заглянув в логи Snowflake:

Настройка этого процесса заняла у dbt и Snowflake около 9 секунд. Однако для выполнения объединения, как было определено в Python-коде, потребовалось всего 15 секунд при рематериализации 150 миллионов строк. В чем же тут ноу-хау?
“Магия” Snowpark Python Dataframes заключается в том, что все манипуляции с датафреймами (которые мы выполняли на языке Python) Snowflake переводит в SQL-запрос. Выполненный запрос можно также найти в логах Snowflake:
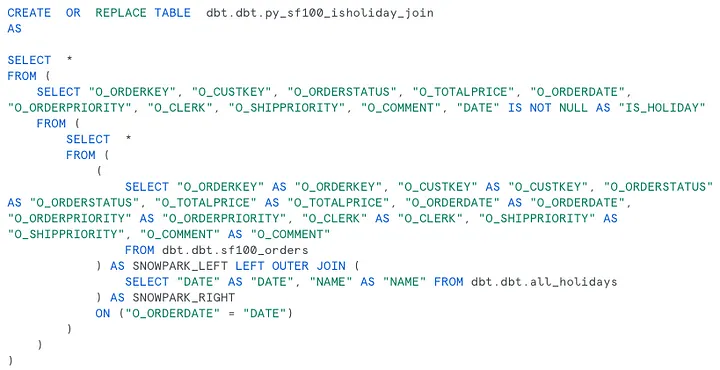
Таким образом:
- Специалисты по Python могут продолжать писать на Python даже в dbt-конвейерах.
- Python-код выполняется внутри Snowflake, поскольку об этом заботится dbt.
- Snowpark переводит манипуляции с датафреймами на Python в высокомасштабируемый и быстрый SQL-код.
Но что, если нужно выполнять пользовательский Python-код, который не может быть преобразован в SQL, и будет ли это так же быстро? Ответ: да.
dbt-модель на Python, которая не может быть преобразована в SQL
Следующий пример — демонстрация того, как достичь тех же результатов, что и в предыдущей Python-модели, но с пользовательским Python-кодом. Вместо того чтобы получать Holidays путем табличного соединения, будем использовать библиотеку Python holidays:
# sf100_orders_annotated.py
import snowflake.snowpark.functions as F
import snowflake.snowpark.types as T
import holidays
def model(dbt, session):
dbt.config(
packages = ["holidays"]
)
us_holidays = holidays.US(years=range(1990, 2030))
@F.udf(input_types=[T.DateType()], return_type=T.BooleanType())
def is_holiday(x):
return x in us_holidays
df = dbt.ref('sf100_orders')
df = df.withColumn("IS_HOLIDAY", is_holiday("O_ORDERDATE"))
return df
В приведенном выше примере используется библиотека Python, которая уже есть в Snowflake благодаря Anaconda (holidays).
Примечательно, что в таблицу со 150 миллионами строк dbt.ref(‘sf100_orders’) добавляется столбец, содержащий результат применения Python-функции is_holiday(“O_ORDERDATE”). Эта функция определяется прямо здесь с помощью специального декоратора: @F.udf().
Декоратор @F.udf() выполняет очень важную роль: дает команду Snowflake преобразовать эту пользовательскую Python-функцию в Snowflake Python UDF (User Defined Function, определенную пользователем функцию). Затем Snowflake может преобразовать операции с датафреймом в масштабируемый SQL-код. Это будет вызывать только что созданную Python UDF. Вот как выглядит процесс в Snowflake:
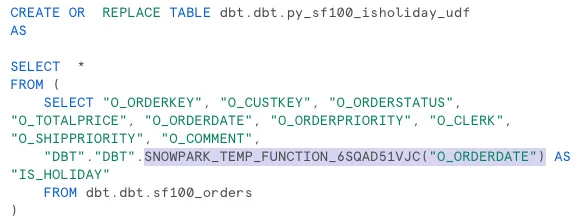
Бенчмаркинг вызова Python UDF
Выполнение этого преобразования заняло 36 секунд — не так уж плохо для рематериализации 150 миллионов строк и вызова произвольной UDF на языке Python 150 миллионов раз:
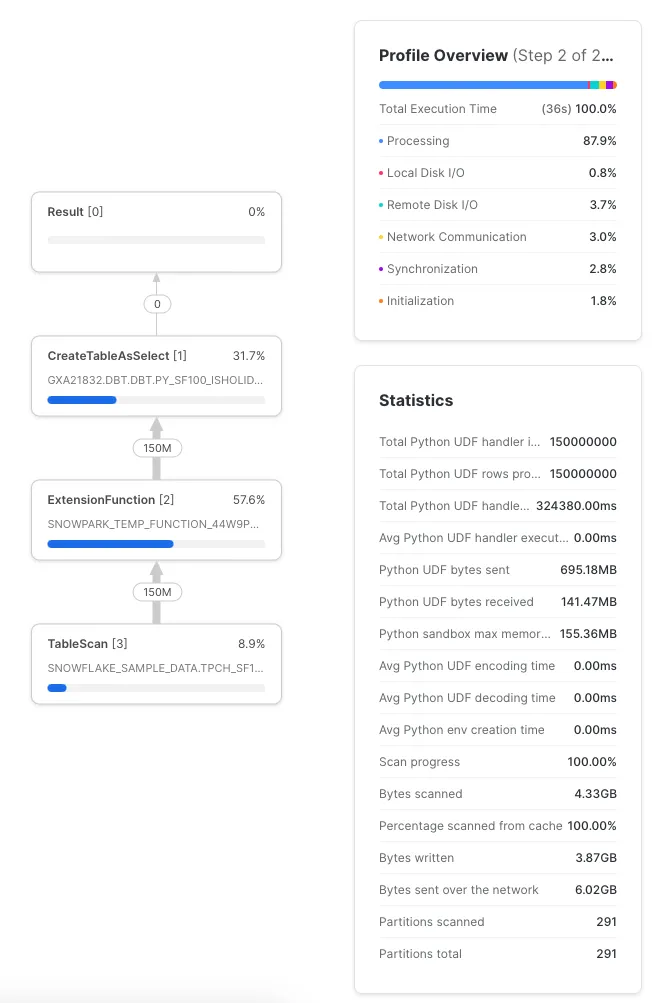
На скриншоте видно, что Python-код выполнился 150 млн раз, заняв в общей сложности 324 секунды. Это оказалось гораздо быстрее, поскольку Snowflake позаботился о распараллеливании этих вызовов.
Замечания по производительности
Python будет работать медленнее, чем чистый SQL, но насколько медленнее — во многом зависит от кода. Небольшие оптимизации могут оказать огромное влияние.
В качестве примера возьмем реализацию UDF, которая инициализирует словарь Holidays вне UDF:
us_holidays = holidays.US(years=range(1990, 2030))
@F.udf(input_types=[T.DateType()], return_type=T.BooleanType())
def is_holiday(x):
return x in us_holidays
И сравним ее с инициализацией словаря Holidays внутри UDF:
@F.udf(input_types=[T.DateType()], return_type=T.BooleanType())
def is_holiday(x):
us_holidays = holidays.US(years=range(1990, 2030))
return x in us_holidays
В первом случае на L-wh потребовалось 38 секунд для 150 миллионов строк.
Во втором случае на L-wh для тех же 150 миллионов строк потребовалось 3 часа 38 минут (на XL-wh — 1 час 52 м).
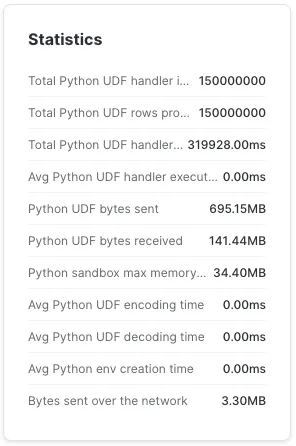
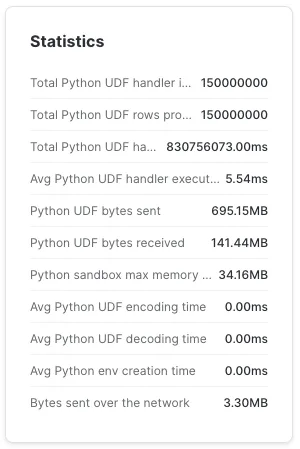
Это огромная разница. Перенос инициализации за пределы UDF экономит много времени. Если она находится внутри UDF, то UDF выполняется за 5,54 мс. Возможно, это и не кажется много, если не учесть, что 5,54 мс, умноженные на 150 миллионов, составляют 9,6 дня работы процессора.
Хорошая новость, вытекающая из сказанного выше: если вы позаботитесь об инициализации вне UDF, то декоратор Snowpark @F.udf() позаботится о переносе этих значений из контекста в UDF.
Возможности безграничны
Теперь, имея в распоряжении эти строительные блоки, дадим волю воображению. Что можно сделать в dbt-конвейерах, если писать произвольные преобразования Python-кода на каком-либо этапе?
- dbt позаботится о передаче Python-кода в Snowflake.
- Snowflake возьмет на себя распараллеливание преобразований датафреймов.
- Snowflake и Anaconda упростят использование множества библиотек Python.
- Можно применять собственные библиотеки Python.
Следующие шаги
- Попробуйте использовать dbt-модели Python в своей версии Snowflake и поделитесь результатами.
- Участвуйте в работе dbt-сообщества, чтобы определить будущее dbt-моделей Python.
- Ознакомьтесь с документацией по dbt-моделям Python и документацией по библиотеке Snowflake Snowpark Python.
- Пройдите такие экспресс-курсы по dbt+Snowflake, как “Data Engineering with Snowpark Python and dbt” (“Инжиниринг данных с помощью Snowpark Python и dbt”) и “Leverage dbt Cloud to Generate ML ready pipelines using Snowpark Python” (“Использование dbt Cloud для создания готовых к МО конвейеров с применением Snowpark Python”).
- Сравните простоту, мощность и производительность Python-моделей dbt на Snowflake с теми настройками, которые приходилось делать dbt для запуска Python-моделей на других платформах.
Хотите большего?
- Протестируйте бесплатную пробную версию Snowflake. Для начала работы потребуется указать только адрес электронной почты.
- Опробуйте dbt Cloud. Я использовал его в качестве веб-редактора, интегрированного с dbt и Snowflake для разработки примеров, приведенных в этой статье.
Читайте также:
- Запуск DBT в Azure Functions с помощью Snowflake
- Планирование и оркестрация облачных задач dbt Cloud с помощью Prefect
- Развертывание приложений Python в Azure
Читайте нас в Telegram, VK и Дзен
Перевод статьи Felipe Hoffa: How Snowflake makes the dbt Python models shine





