
“Ненавижу это!” — именно таким было мое отношение к первому заданию по инженерии данных. Мне поручили выполнить веб-скрейпинг нескольких цифровых данных из Википедии.
Пришлось уговаривать себя: “Сделай эту работу на Python! Ведь времена ручного поиска данных позади. Запасись терпением. У тебя оно есть”.
Проблема: может ли выпускник факультета общественных наук профессионально заниматься инженерией данных? К примеру, создать автоматизированный конвейер данных и надежно защитить его в облаке?
Нулевая гипотеза: инженер может заниматься инженерией данных так же успешно, как и тот, кто зарабатывает на жизнь написанием контента.
Стоит ли отклонить эту гипотезу? Мое шестое чувство подсказывает: “Да”. Быть не может, чтобы такой непрофессионал в области ИТ, как я, смог этого добиться.
Рассмотрим альтернативную гипотезу: тот, кто зарабатывает на жизнь написанием контента, может научиться выполнять задачи инженерии данных не хуже инженера.
Бизнес-кейс
Моя задача заключалась в создании базы данных для компании Gans, которая предоставляет для транспортировки электромобили. Чтобы оптимизировать предложение достаточного количества средств передвижения в определенное время, компании нужен специалист по изучению данных, который создаст базу данных для измерения спроса в зависимости от погодных факторов.
Поскольку основной бизнес компании связан с арендой скутеров в Германии, то спрос зависит от погоды: в дождь и снегопад он уменьшается, а перед прогнозируемыми осадками временно увеличивается.
Поэтому необходимо создать простую базу данных SQL, содержащую информацию о городах и погоде. Операционный отдел компании сможет ежедневно обращаться к этой базе данных и принимать обоснованные решения о географической доступности единиц мобильной техники.
В будущем базу данных можно усовершенствовать, включив в нее данные о прибытии общественного транспорта (например, с помощью API для авиарейсов, поездов и автобусов). Это позволит получить более полное представление о прибытии туристов (некоторые из них станут потенциальными клиентами компании).
Вот как выглядит карта проекта, включая API погоды (Weather) и авиарейсов (Flights):
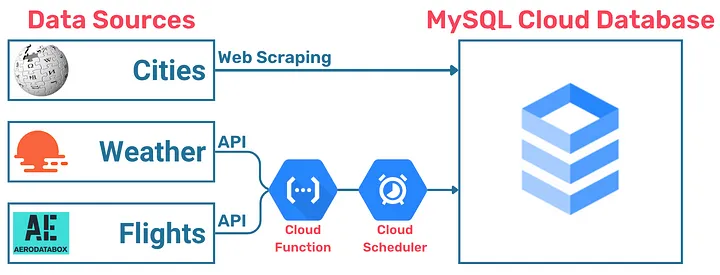
В данной статье рассмотрим только интеграцию погодных данных.
Начнем с импортирования всех библиотек, необходимых для работы в Python:
import pandas as pd
import requests
from bs4 import BeautifulSoup
from datetime import datetime
from pytz import timezone
Веб-скрейпинг 101: как получить HTML-код?
Первый шаг: создание таблицы с данными о городах. Эта таблица будет служить основным связующим звеном с остальными таблицами. Она будет статичной, поскольку содержащиеся в ней данные не придется регулярно обновлять. Назовем эту таблицу “cities_info” (“информация о городах”).
Для каждого города в ней будет одна строка и пять столбцов:
- уникальный идентификатор города (city ID);
- название города (city’s name);
- земля Германии, к которой относится город (German state);
- широта (latitude);
- долгота (longitude).
Эти данные по каждому городу можно получить с помощью веб-скрейпинга с сайтов английской Википедии. Достаточный бюджет позволил бы купить API городов с достоверными данными и методологической информацией. Но в рамках этого проекта буду отрабатывать навыки скрейпинга, используя Википедию.
Меня пугала мысль о том, что для каждого сайта придется вручную экспортировать HTML-код и копировать его в Vs Code. К счастью, с помощью библиотеки “requests” на Python это можно делать автоматически:
import requests
berlin_url = "https://en.wikipedia.org/wiki/Berlin"
berlin_response = requests.get(berlin_url)
berlin_soup = BeautifulSoup(berlin_response.content, 'html.parser')
print(berlin_soup.prettify)
1:0 в пользу Python.
Циклы и функции
Циклы и функции — неотъемлемая часть итерации. Без них невозможно воспроизвести один и тот же код и одновременно применить его к разным URL. Это ключ к автоматизации веб-скрейпинга.
Вот пример цикла, использованный мной для получения HTML-кода каждого сайта Википедии:
cities_list = ["Berlin", "Hamburg", "Munich", "Cologne", "Frankfurt"]
for city in cities_list:
url = f"https://www.wikipedia.org/wiki/{city}" # превращает url в строку f и помещает город в качестве переменной, которая меняется в зависимости от названия города
response = requests.get(url) # получает все содержимое страницы Википедии и сохраняет его под именем response
city_soup = BeautifulSoup(response.content, 'html.parser')
Пока еще функции меня пугают, поэтому стараюсь избегать их по мере возможности.
1000:0 в пользу Python.
Как получить доступ к материалам в формате HTML?
В HTML есть так называемые “p-теги”. Получить к ним доступ позволит следующий код:
print(soup.p) # получает доступ к первому p-тегу
print(soup.p.string) # получает доступ к строке, связанной с первым p-тегом
for child in soup.div: # пример поиска и вывода каждого дочернего элемента в 1-м div
print(child)
Создание датафреймов в Python и соответствующих таблиц в SQL
В процессе приобретения навыков работы с веб-скрейпингом, циклом и HTML мне удалось получить всю информацию, необходимую для создания первых двух таблиц.
Первый датафрейм работает как статический индекс (то есть его информация не будет регулярно обновляться): cities_info.
cities_list = ["Berlin", "Hamburg", "Munich", "Cologne", "Frankfurt"]
states = []
latitudes = []
longitudes = []
for city in cities_list:
url = f"https://www.wikipedia.org/wiki/{city}"
city_soup = BeautifulSoup(response.content, 'html.parser') # парсит контент (сохраняет содержимое сайта Википедии в переменной city_soup)
# получение земли, к которой принадлежит город
if city not in ["Hamburg", "Berlin"]: # для Берлина тоже подойдет общая формула .find! Только для Гамбурга нет раздела "State".
city_state = city_soup.find("table", class_="vcard").find(string="State").find_next("td").get_text() # получает данные о земле для городов с другим названием земли
else:
city_state = city # в случае Гамбурга и Берлина просто берется одноименное название города
states.append(city_state)
# получение широты каждого города и добавление ее в столбец latitudes
city_latitude = city_soup.find(class_="latitude").get_text()
latitudes.append(city_latitude)
# получение долготы каждого города и добаление ее в столбец longitude
city_longitude = city_soup.find(class_="longitude").get_text()
longitudes.append(city_longitude)
cities_info_non_rel = pd.DataFrame({ # это будет датафрейм cities_info
"city_name": cities_list,
"german_state": states,
"latitude": latitudes,
"longitude": longitudes
})
display(cities_info_non_rel) # вместо вывода показывается таблица в более красивом формате
Второй датафрейм содержит данные о населении, которые, вероятно, будут обновляться раз в год: cities_population.
populations = []
year_data_retrieved = []
for city in cities_list:
url = f"https://www.wikipedia.org/wiki/{city}" # превращает url в строку f и помещает город в качестве переменной, так что она меняется в соответствии с названием города
response = requests.get(url) # получает все содержимое страницы Википедии и сохраняет его под именем response
city_soup = BeautifulSoup(response.content, 'html.parser') # парсит контент (сохраняет содержимое сайта Википедии в переменной city_soup)
# получение количества жителей для каждого города и добавление его в столбец population
city_population = int(city_soup.find("table", class_="vcard").find(string="Population").find_next("td").get_text().replace(",", "")) # находит численность населения, очищает и превращает в целое число
populations.append(city_population)
# запись года, когда были получены данные
current_year = (datetime.now()).year
year_data_retrieved.append(current_year)
cities_population = pd.DataFrame({ # это будет датафрейм cities_population
"city_name": cities_list,
"population": populations,
"year_data_retrieved": year_data_retrieved,
})
display(cities_population)
Теперь в MySQL можно создать две таблицы, которые будут содержать всю информацию, впоследствии передаваемую из Python и облака. Это значит, что нужны таблицы с таким же количеством столбцов и типов данных, как в созданных датафреймах Python:
/***************************
Настройка среды
***************************/
-- Удалите базу данных, если она уже существует
DROP DATABASE IF EXISTS gans;
-- Создайте базу данных
CREATE DATABASE gans;
-- Используйте базу данных
USE gans;
/***************************
Создание первой таблицы
***************************/
-- Создайте таблицу 'cities_info'
CREATE TABLE cities_info (
cities_id INT AUTO_INCREMENT, -- Автоматически генерируемый идентификатор для каждого города
city_name VARCHAR(255) NOT NULL, -- Название города
german_state VARCHAR(255) NOT NULL, -- Название земли
latitude VARCHAR(255) NOT NULL, -- Координата широты
longitude VARCHAR(255) NOT NULL, -- Коордианта долготы
PRIMARY KEY (cities_id) -- Первичный ключ для уникальной идентификации каждого города
);
/***************************
Создание второй таблицы
***************************/
CREATE TABLE cities_population (
cities_id INT,
population INT, -- Численность населения
year_data_retrieved INT, -- год получения данных о населении
FOREIGN KEY (cities_id) REFERENCES cities_info(cities_id)
);
Переносим данные из Python в первую таблицу SQL:
schema = "gans" # название базы данных
host = "xxx.x.x.x"
user = "root" # имя пользователя
password = "xxxx" # явно укажите пароль SQL или импортируйте из другого ноутбука ("from xxxfile import my_password")
port = 3306
connection_string = f'mysql+pymysql://{user}:{password}@{host}:{port}/{schema}'
# Это то, что соединяет ноутбук python с sql workbench
cities_info_non_rel.to_sql('cities_info', # Таким образом мы передаем данные от PYTHON к SQL
if_exists='append', # не нужно ничего перезаписывать, просто добавляем данные к уже существующим
con=connection_string, # con - это аргумент, который нужен для подключения к sql workbench
index=False)
Обратите внимание: первая попытка выполняется локально. Позже, добавив экземпляр Google Cloud Platform, можно будет отредактировать поле “host” и напрямую отправить эти данные в облако.
Создав первую таблицу в SQL, получаем данные, содержащиеся в cities_info, чтобы использовать столбец cities_id в качестве индекса во втором датафрейме cities_population:
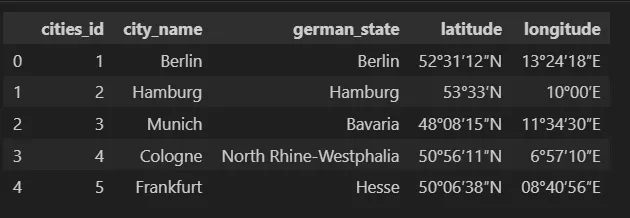
cities_info = pd.read_sql("cities_info", con=connection_string) # "считывает" информацию, хранящуюся в SQL
cities_info
Вот как выглядит cities_info:
Прежде чем передать содержимое второго датафрейма в SQL, используем вновь созданный столбец cities_id, добавив его в датафрейм cities_populations.
Изменяем порядок столбцов и удаляем столбец city_name, который больше не понадобится, поскольку теперь в датафрейме cities_populations добавлен столбец cities_id:
# добавляем столбец cities_id в другой датафрейм population
cities_population["cities_id"] = cities_info_non_rel["cities_id"]
cities_population
# убираем столбец city_name, потому что он нам больше не нужен + меняем порядок столбцов, чтобы сделать процесс более интуитивным
cities_population = cities_population[["cities_id", "population", "year_data_retrieved"]]
cities_population
Вот и второй датафрейм, который будет частично динамическим (его данные будут обновляться время от времени, примерно раз в год):
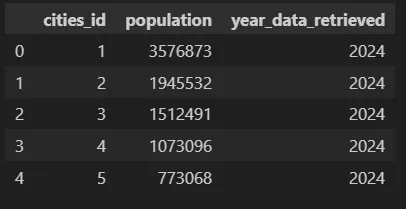
На данный момент будем считать cities_population нединамической таблицей, поскольку она не будет обновляться до следующего года.
Теперь можно передать ее содержимое в локальный экземпляр SQL:
# передааем содержимое второй таблицы в SQL
cities_population.to_sql('cities_population', # Таким образом мы передаем данные от PYTHON к SQL
if_exists='append', # не нужно ничего перезаписывать, просто добавляем данные к уже существующим
con=connection_string, # con - это аргумент, который нужен для подключения к sql workbench
index=False)
После запуска всего этого в SQL и использования функции “Reverse engineer” (“реверс-инжиниринг”), получим начальную версию схемы:
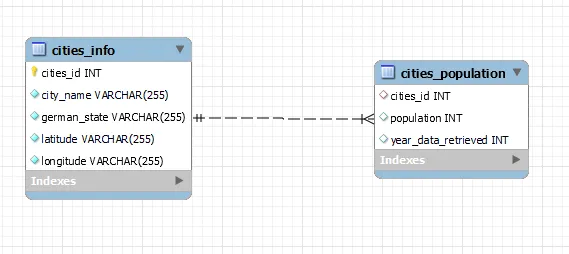
Погружаемся в процесс обучения еще глубже.
Следующий шаг: интеграция API в базу данных. Это простейшая операция, которую может выполнить любой дата-сайентист.
Лучше освоить ее, пока ИИ не научится делать это за нас.
Использование API прогнозов погоды
Третий важный шаг этого проекта — извлечение погодных данных из существующего хранилища данных и интеграция их в базу данных SQL. Доступ к таким хранилищам осуществляется через API (Application Programming Interface — интерфейс прикладного программирования). API — это набор правил и протоколов, которые позволяют различным программным приложениям взаимодействовать друг с другом.
Воспользуемся сайтом openweathermap.org, который позволит получить доступ к бесплатным прогнозам погоды для любой точки мира. Будем использовать API прогнозов погоды на 5 дней, включая данные прогноза с 3-часовым интервалом.
Теперь на очереди основная задача проекта: написать код для получения необходимых данных о погоде и передачи их в базу данных SQL. Долгие мучения, занявшие у меня несколько дней, привели к написанию кода для получения наиболее важных данных о погоде:
def get_weather_data(cities):
# Поскольку мы будем работать в облаке, компьютеры могут находиться где угодно. Исправим часовой пояс компьютера на наш местный часовой пояс
berlin_timezone = timezone("Europe/Berlin")
API_key = "7e5623c79f102b6c08b15c8hjib4cc9l" # это не настоящий ключ
weather_items = []
for city in cities:
url = (f"http://api.openweathermap.org/data/2.5/forecast?q={city}&appid={API_key}&units=metric")
response = requests.get(url)
json = response.json()
# Добавлено время получения, чтобы мы знали, когда был сделан прогноз
retrieval_time = datetime.now(berlin_timezone).strftime("%Y-%m-%d %H:%M:%S")
# Поскольку сейчас мы используем данные из реляционной базы данных, город должен обозначать city_id, а не название города
city_id = cities_info.loc[cities_info["city_name"] == city, "city_id"].values[0] # здесь нам нужно получить значения, иначе будут показаны серии
for item in json["list"]:
weather_item = {
# Добавлено название города, чтобы информация была понятна при просмотре нескольких городов
"forecast_time": item.get("dt_txt", None),
"temperature": item["main"].get("temp", None),
"feels_like": item["main"].get("feels_like", None),
"forecast": item["weather"][0].get("main", None),
"humidity": item["main"].get("humidity", None),
"rain_in_last_3h": item.get("rain", {}).get("3h", 0),
"risk_of_rain": item["pop"],
"snow_in_last_3h": item.get("snow", {}).get("3h", 0),
"wind_speed": item["wind"].get("speed", None),
"data_retrieved_at": retrieval_time
}
weather_items.append(weather_item)
weather_df = pd.DataFrame(weather_items)
weather_df["forecast_time"] = pd.to_datetime(weather_df["forecast_time"])
weather_df["data_retrieved_at"] = pd.to_datetime(weather_df["data_retrieved_at"])
weather_df["snow_in_last_3h"] = pd.to_numeric(weather_df["snow_in_last_3h"], downcast="float")
return weather_df
weather_df = get_weather_data(["Berlin", "Hamburg", "Munich", "Cologne", "Frankfurt"])
weather_df # создадим новый датафрейм с помощью функции
Одна из ключевых особенностей таблицы и датафрейма с информацией о погоде заключается в том, что они должны содержать столбец с указанием времени получения данных. Это позволит, помимо прочего, осуществлять соответствующую фильтрацию и создавать процедуры или функции на SQL для автоматического удаления устаревших данных спустя какое-то время. Это также необходимо для обеспечения согласованности данных, чтобы различать прогнозируемые дату/время (forecast time) от даты/времени получения данных (data retrieval).
Вот как выглядит новый погодный датафрейм на Python:
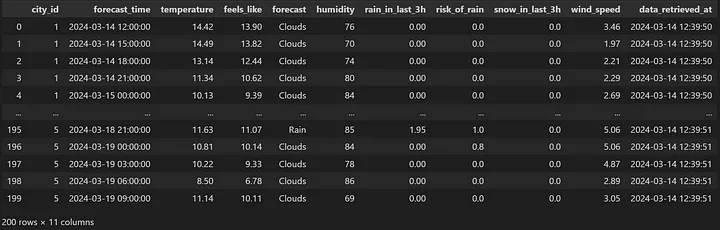
Получив структуру погодного датафрейма, перейдем к созданию третьей таблицы с именем weather (погода) на SQL:
/***************************
Создание таблицы WEATHER
***************************/
CREATE TABLE weather (
city_id INT,
forecast_time datetime,
temperature float,
feels_like float,
forecast VARCHAR(255) NOT NULL,
humidity INT,
rain_in_last_3h FLOAT,
risk_of_rain FLOAT,
snow_in_last_3h FLOAT,
wind_speed FLOAT,
data_retrieved_at DATETIME,
FOREIGN KEY (city_id) REFERENCES cities_info(city_id)
);
-- TRUNCATE TABLE weather; -- нам может понадобиться стереть все строки, когда таблица станет слишком длинной, а данные слишком старыми
Это обновленная схема SQL после реверс-инжиниринга:
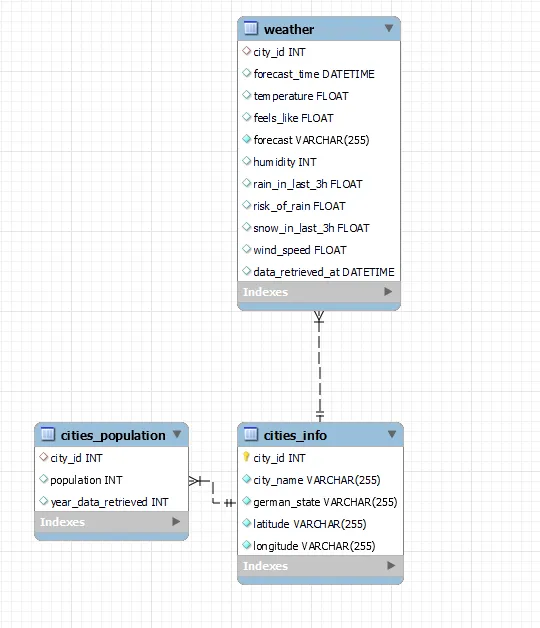
Переход от локального к глобальному
Прежде чем переносить код в облако, нужно убедиться, что код получения погодных данных работает локально. Для этого сразу после создания кода на Python попробуем перенести его в локальный экземпляр SQL:
weather_df.to_sql("weather",
if_exists='append',
con=connection_string,
index=False)
Если в таблицу SQL будут добавляться новые данные, значит, она работает!
Вот как выглядела таблица погоды SQL после локальной подачи данных из Python:
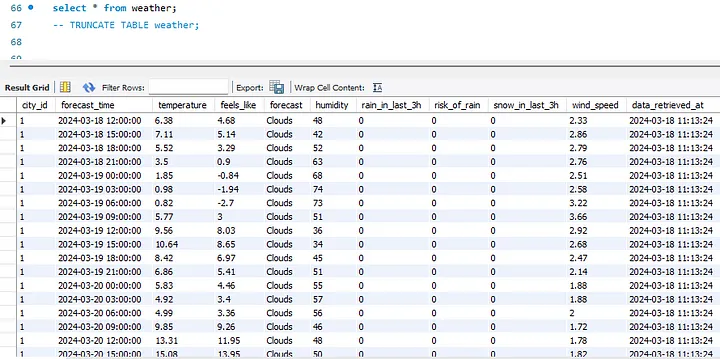
Интеграция с Google Cloud Platform
Убедившись, что код работает локально, перенесем его в облако.
Откроем аккаунт Google Cloud Platform (GCP) и настроим облачный экземпляр. Пошаговое описание этого процесса на примере MySQL можно найти здесь.
Одним из самых важных шагов является изменение локального IP-хоста на IP-хост Google в ноутбуке Python, в частности, в блоке кода, который передает данные в SQL:
schema = "gans" # название базы данных
host = "XX.XXX.XX.XX" # LOCAL HOST:"xxx.x.x.x" (до того, как я изменил это на облако)
user = "root" # имя пользователя (см. инструкции)
password = "XXXX" # явно укажите пароль или импортируйте из другого ноутбука ("from xxxfile import my_password")
port = 3306
connection_string = f'mysql+pymysql://{user}:{password}@{host}:{port}/{schema}' # Это то, что соединяет ноутбук python с sql workbench
Таким образом, ранее созданные статические таблицы на Python могут быть автоматически загружены в облако и заполнить уже существующие таблицы SQL без необходимости выполнять код на Python когда-либо снова. По крайней мере, пока не понадобится обновить нединамические таблицы (cities_info и cities_population).
Для целей данного проекта достаточно загрузить эти две таблицы из Python в GCP, изменив IP-адрес хоста. Другой вариант — загрузить код, создающий эти две таблицы, в облако. В данном случае поместим в облако только код, который создает и заполняет динамическую таблицу погоды.
После создания функции в поле “Cloud Functions” (“Облачные функции”) в GCP методом множества проб и ошибок код наконец-то заработал:
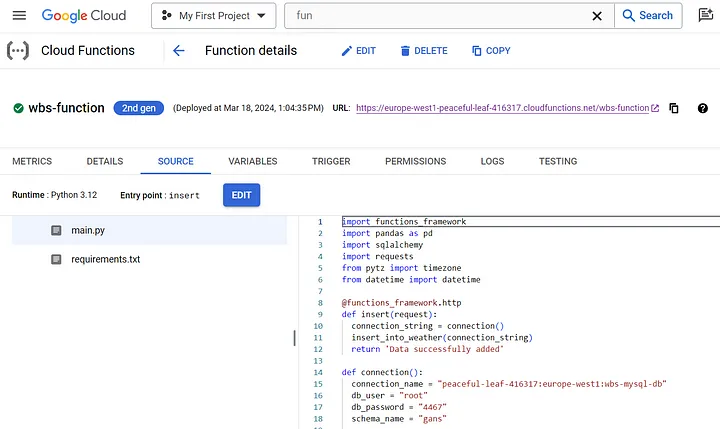
Но прежде чем код начнет работать, нужно подключить функцию к облачному экземпляру, выполнив следующие действия:
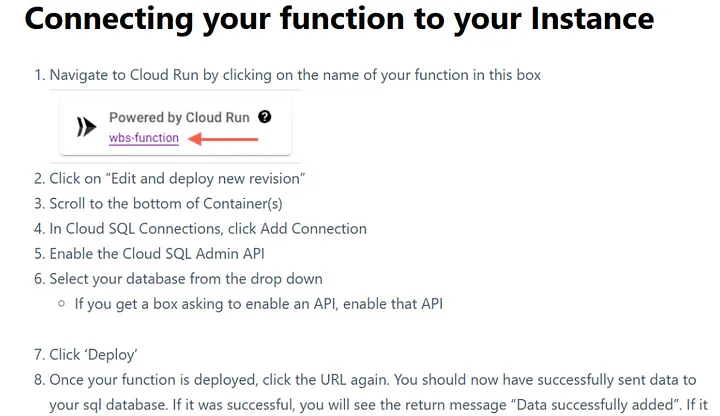
- Перейдите на Cloud Run, кликнув на название функции в этом боксе.
- Кликните на “Edit and deploy new version”.
- Прокрутите до низа контейнера (ов).
- Находясь в Cloud SQL Connections, нажмите Add Connection.
- Включите API админа в Cloud SQL.
- Выберите свою базу данных из выпадающего списка (если появится бокс с просьбой включить API, включите этот API).
- Нажмите “Deploy”.
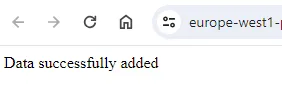
- Когда функция будет развернута, нажмите снова на URL. Вы должны успешно отправить данные в базу данных SQL. Если все прошло удачно, вы увидите сообщение “Data successfully added”.
Как понять, что все сработало? Лучшее уведомление, которое можно получить в этом случае, выглядит следующим образом:
По сравнению с кодом, протестированным локально, мне потребовалось внести несколько изменений. Вот как выглядит окончательный вариант кода:
import functions_framework
import pandas as pd
import sqlalchemy
import requests
from pytz import timezone
from datetime import datetime
@functions_framework.http
def insert(request):
connection_string = connection()
insert_into_weather(connection_string)
return 'Data successfully added'
def connection():
connection_name = "flying-dove-416317:europe-west1:wbs-mysql-db" # это не настоящие данные
db_user = "root"
db_password = "xxxx" # введите свой пароль SQL
schema_name = "gans"
driver_name = 'mysql+pymysql'
query_string = {"unix_socket": f"/cloudsql/{connection_name}"}
db = sqlalchemy.create_engine(
sqlalchemy.engine.url.URL(
drivername = driver_name,
username = db_user,
password = db_password,
database = schema_name,
query = query_string,
)
)
return db
# ЗДЕСЬ ЗАПУСКАЕТСЯ ФУНКЦИЯ ПОЛУЧЕНИЯ ПОГОДНЫХ ДАННЫХ:
def extract_city(connection_string):
return pd.read_sql("cities_info", con=connection_string)
def get_weather_data(cities_df):
berlin_timezone = timezone("Europe/Berlin")
API_key = "7e5623c79f102b6c08b15c8hjib4cc9l" # это не настоящий ключ
weather_items = []
for city in cities_df["city_name"]:
url = (f"http://api.openweathermap.org/data/2.5/forecast?q={city}&appid={API_key}&units=metric")
response = requests.get(url)
json = response.json()
# Добавлено время получения, чтобы мы знали, когда был сделан прогноз
retrieval_time = datetime.now(berlin_timezone).strftime("%Y-%m-%d %H:%M:%S")
# Поскольку сейчас мы используем данные из реляционной базы данных, город должен обозначать city_id, а не название города
city_id = cities_df.loc[cities_df["city_name"] == city, "city_id"].values[0] # здесь нам нужно получить значения, иначе будут показаны серии
for item in json["list"]:
weather_item = {
# Добавлено название города, чтобы информация была понятна при просмотре нескольких городов
"forecast_time": item.get("dt_txt", None),
"temperature": item["main"].get("temp", None),
"feels_like": item["main"].get("feels_like", None),
"forecast": item["weather"][0].get("main", None),
"humidity": item["main"].get("humidity", None),
"rain_in_last_3h": item.get("rain", {}).get("3h", 0),
"risk_of_rain": item["pop"],
"snow_in_last_3h": item.get("snow", {}).get("3h", 0),
"wind_speed": item["wind"].get("speed", None),
"data_retrieved_at": retrieval_time
}
weather_items.append(weather_item)
weather_df = pd.DataFrame(weather_items)
weather_df["forecast_time"] = pd.to_datetime(weather_df["forecast_time"])
weather_df["data_retrieved_at"] = pd.to_datetime(weather_df["data_retrieved_at"])
weather_df["snow_in_last_3h"] = pd.to_numeric(weather_df["snow_in_last_3h"], downcast="float")
return weather_df
def insert_into_weather(connection_string):
cities_df = extract_city(connection_string)
weather_df = get_weather_data(cities_df) #создадим новый датафрейм с помощью функции
weather_df.to_sql("weather",
if_exists="append",
con=connection_string,
index=False)
Уроки, усвоенные при создании кода, пригодного для работы в облаке
1. Зависимости
Одно из основных условий правильной работы кода — добавление необходимых зависимостей в файл requirements.txt. Важно учитывать, что некоторые библиотеки уже загружены на GCP по умолчанию и не должны включаться в .txt-файл, но их необходимо добавить в исходный код в качестве библиотек, например:
from pytz import timezone
from datetime import datetime
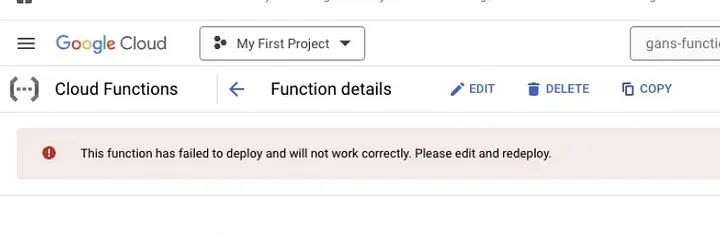
При попытке развертывания можно столкнуться с ошибкой, помеченной красным флагом (как показано на изображении ниже). В большинстве случаев это связано с импортом библиотек, не указанных в файле requirements.txt.
В разделе требований необходимо добавить только те пакеты, которые не являются модулями Python. Вот ссылка на полный список модулей Python.
Еще один полезный совет — выводите все внешние библиотеки, используемые в коде. После вызова функций в ноутбуке нужно выполнить:
print('\n'.join(f'{m.__name__}=={m.__version__}' for m in globals().values() if getattr(m, '__version__', None)))
Затем можно напрямую скопировать и вставить в файл requirements.txt нужные зависимости:
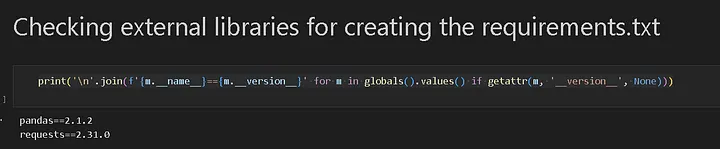
В файле .txt были указаны зависимости, необходимые для этого проекта:
functions-framework==3.*
SQLAlchemy==1.4.37
PyMySQL==1.0.2
pandas==1.5.2
requests==2.31.0
2. Тестирование кода подключения
Перед добавлением функций получения данных следует сначала проверить, работает ли код подключения. Это позволит убедиться в том, что проблема кроется в коде, а не в настройке соединения.
Лучший способ начать перенос локального скрипта в GCP — создать “фиктивную” функцию и протестировать ее. Например:
import functions_framework
import pandas as pd
import sqlalchemy
@functions_framework.http
def insert(request):
connection_string = connection()
insert_into_test_table(connection_string)
return 'Data successfully added'
def connection():
connection_name = "YOUR_DB_CON_NAME" # изменить соответственно
db_user = "root" # изменить
db_password = "YOUR_PASSWORD" # изменить
schema_name = "test_schema" # изменить
driver_name = 'mysql+pymysql'
query_string = {"unix_socket": f"/cloudsql/{connection_name}"}
db = sqlalchemy.create_engine(
sqlalchemy.engine.url.URL(
drivername = driver_name,
username = db_user,
password = db_password,
database = schema_name,
query = query_string,
)
)
return db
def insert_into_test_table(con_str):
data = {'FirstName': ['Function', 'Test'],
'City': ['Cloud', 'Complete']}
df = pd.DataFrame(data)
df.to_sql(name="test_table", con=con_str, if_exists='append', index=False)
Если эта простая функция работает, значит, и соединение работает. Остается только добавить и интегрировать фактический код.
Если получена приведенная ниже ошибка, проблема наверняка в коде, а не в соединении:
500 Internal Server Error: сервер столкнулся с внутренней ошибкой и не смог выполнить ваш запрос. Либо сервер перегружен, либо в приложении произошла ошибка.
3. Проблемы с реальным кодом
Основная ошибка, допущенная мной при размещении кода в сети, заключалась в следующем: код был настроен на основе “фиктивного” шаблона, и функция (“insert_into_weather”), вызванная в разделе “@functions_framework.http”, не была определена.
После добавления этой функции код по-прежнему не работал. Это было связано с тем, что нужные города были названы мной вручную, а не взяты из датафрейма cities_info. Пришлось добавить в начало блока еще одну функцию под названием “extract_city” (“извлечение города”) и убедиться, что весь блок работает локально, прежде чем выкладывать его в сеть.
После использования таблицы cities_info для извлечения названий городов я допустил еще одну ошибку. Она заключалась в том, что не был обновлен следующий цикл, который должен был уже брать названия городов из датафрейма вместо прежнего списка и не мог найти названия с прежними аргументами.
Последние шаги
Чтобы сделать проект полностью функциональным и автоматизированным, нужно запланировать периодический запуск функции. Это довольно просто сделать с помощью меню “Cloud Scheduler” (“Облачный планировщик”) на GCP.
Для этого нужно нажать “Schedule a job” (“Запланировать задание”), указать несколько параметров, задав периодичность (раз в неделю или в определенное время в определенный день, используя Cron Expressions), чтобы функция запускалась в указанное время и заполняла SQL-таблицу необходимыми данными. У меня запуск был настроен на 15:00 каждого понедельника:
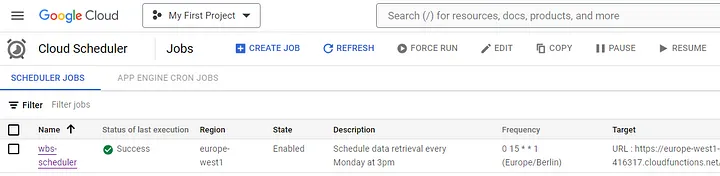
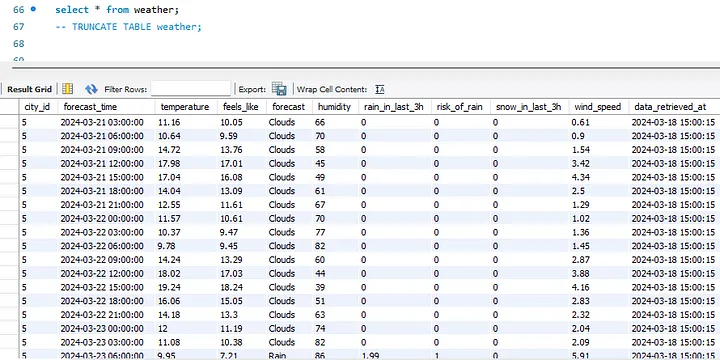
Убедимся, что это работает на SQL:
Прежде чем распрощаться с первым проектом SQL-Python-GCP, следует удалить свои данные из аккаунта GCP, чтобы созданный проект не расходовал ваши бесплатные кредиты. Речь идет об облачном экземпляре, функции и запланированном задании.
Заключение
У меня получилось создать базовую БД, используя SQL, Python и облачные вычисления.
В начале работы над проектом мне ничего не было известно ни о Google Cloud Platform, ни о любой другой платформе облачных вычислений. До сих пор я ничего не знаю о серверах, хостах, экземплярах и программных соединениях. Мои знания пока ограничиваются основами SQL и Python.
Как новичка, меня сначала одолевали сомнения: смогу ли справиться с такой сложной задачей, как создание автоматизированной базы данных и периодическое наполнение ее ценными данными? Теперь эти сомнения развеялись!
В дальнейшем постараюсь создать более полный и полезный конечный продукт, получая данные из различных API и объединяя их в своей функции GCP.
Возможно, человек, который зарабатывает на жизнь написанием контента, сразу не сможет добиться в инженерии данных тех же успехов, что инженер-программист. Но он может освоить базовые операции и продолжить развивать свои навыки в этом направлении.
Читайте также:
- Taipy: создание полнофункциональных приложений для работы с данными
- Шардинг как паттерн архитектуры базы данных
- 4 расширения VS Code, которые пригодятся дата-инженеру
Читайте нас в Telegram, VK и Дзен
Перевод статьи Marina Pasqual: Data Engineering is for Engineers — NOT!





