
Когда выяснилось, что большие языковые модели (LLM) можно нагружать данными пользователей, возникла дискуссия о том, как наиболее эффективно преодолеть разрыв между общими и пользовательскими знаниями LLM. Было много споров о том, что предпочтительнее для этого — тонкая настройка или генерация ответа, дополненная результатами поиска (Retrieval-Augmented Generation, RAG). Спойлер: и то, и другое.
Первая часть этой статьи, посвященной концепции RAG, будет теоретической. Во второй части рассмотрим реализацию простого RAG-пайплайна, используя LangChain для оркестровки, языковые модели OpenAI и векторную базу данных Weaviate.
Что такое RAG
Концепция RAG предполагает предоставление LLM дополнительной информации из внешнего источника знаний. Такой подход позволяет модели генерировать более точные и контекстные ответы, уменьшая количество галлюцинаций.
Проблема
Современные LLM обучаются на больших объемах данных, чтобы получить широкий спектр общих знаний, хранящихся в весах (параметрической памяти) нейронной сети. Однако, если попросить модель сгенерировать заключение, требующее информации, не включенной в ее обучающие данные (новой, частной или специфической), можно получить результат с фактическими неточностями (галлюцинациями), как показано на следующем скриншоте:
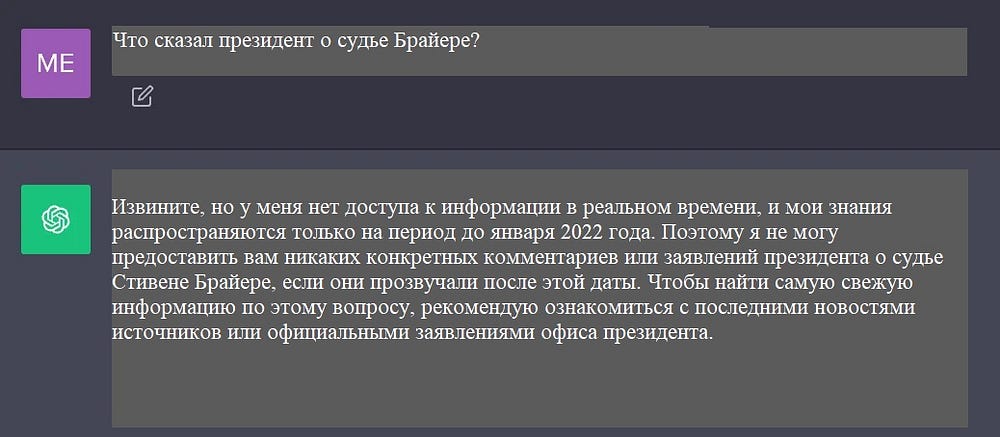
Таким образом, необходимо преодолеть разрыв между общими знаниями LLM и любым дополнительным контекстом. Это поможет LLM генерировать более точные и контекстуальные заключения и сократит количество галлюцинаций.
Решение
Традиционно нейронные сети адаптируются к специфической или закрытой информации путем тонкой настройки модели. Несмотря на свою эффективность, эта техника требует больших вычислительных затрат, дорого стоит и требует технических знаний, что делает ее менее гибкой для адаптации к меняющейся информации.
В 2020 году группа исследователей во главе с Патриком Льюисом (Patrick Lewis) предложила более гибкую технику RAG в статье “Генерация ответа, дополненная результатами поиска, для решения информационно емких задач NLP”. В этой работе была представлена генеративная модель, объединенная с модулем поисковика (Retriever — ретривера) для предоставления дополнительной информации из внешнего легко обновляемого источника знаний.
Говоря простым языком, RAG для LLM — то же самое, что экзамен “с открытой книгой” для людей. На экзамене “с открытой книгой” студентам разрешается использовать справочные материалы, например учебники или конспекты, в которых они могут искать необходимую информацию для ответа на вопрос. Идея экзамена “с открытой книгой” заключается в проверке умения студентов рассуждать, а не способности запоминать конкретную информацию.
Аналогичным образом фактические знания отделяются от способности LLM к рассуждению и хранятся во внешнем источнике знаний, легко доступном и обновляемом.
- Параметрические знания. Усваиваются в процессе обучения и неявно хранятся в весах нейронной сети.
- Непараметрические знания. Хранятся во внешнем источнике знаний, например в векторной базе данных.
Кстати, это гениальное сравнение придумано не мной. Насколько мне известно, впервые о нем упомянул Джей Джей (JJ) во время конкурса “Kaggle — LLM Science”.
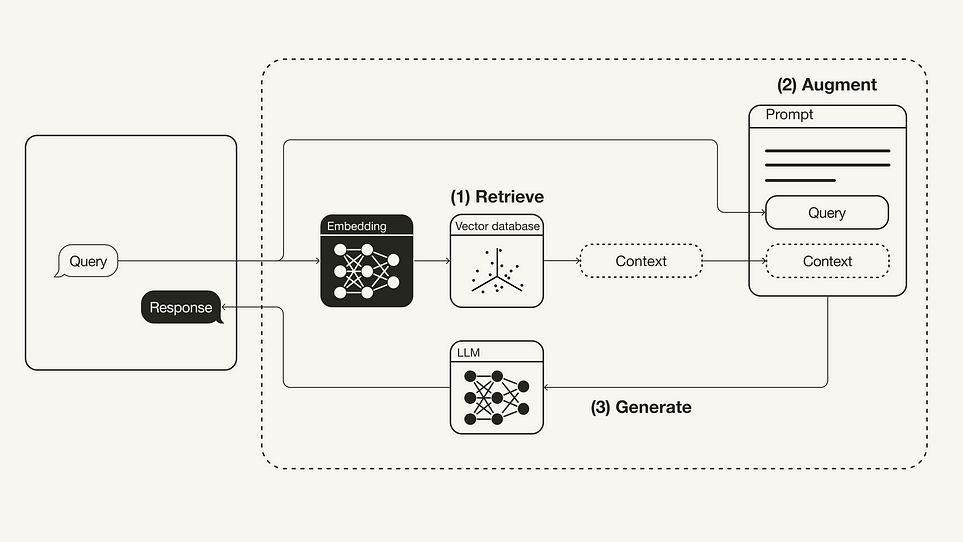
Ниже показан “ванильный” рабочий процесс RAG:

Английский термин “Retrieval Augmented Generation” точно передает суть процесса.
- Retrieve (извлечение). Пользовательский запрос используется для извлечения релевантного контекста из внешнего источника знаний. Для этого пользовательский запрос встраивается с помощью эмбеддинг-модели в то же векторное пространство, что и дополнительный контекст в векторной базе данных. Это позволяет выполнить поиск по сходству с возвращением k-ближайших соседей из векторной базы данных.
- Augment (дополнение). Пользовательский запрос и полученный дополнительный контекст помещаются в шаблон промпта.
- Generate (генерирование). Промпт, дополненный результатами поиска, поступает в LLM.
Реализация RAG с использованием LangChain
Теперь рассмотрим реализацию RAG-пайплайна на Python с применением LLM от OpenAI в сочетании с векторной базой данных Weaviate и эмбеддинг-моделью OpenAI. Для оркестровки будем использовать LangChain.
Необходимые условия
Убедитесь, что у вас установлены следующие пакеты Python:
langchainдля оркестровки;openaiдля эмбеддинг-модели и LLM;weaviate-clientдля векторной базы данных.
#!pip install langchain openai weaviate-client
Кроме того, определите соответствующие переменные среды в файле .env в корневом каталоге. Чтобы получить OpenAI API Key (ключ), заведите учетную запись OpenAI, а затем нажмите “Create new secret key” (“Создать новый секретный ключ”) в разделе API keys (Ключи API).
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
Теперь выполните следующую команду, чтобы загрузить соответствующие переменные среды.
import dotenv
dotenv.load_dotenv()
Подготовка
Прежде всего необходимо подготовить векторную базу данных в качестве внешнего источника знаний, содержащего всю дополнительную информацию. Векторная база данных заполняется в три этапа:
- сбор и загрузка данных;
- разбивка документов;
- эмбеддинг и сохранение чанков.
Приступим к сбору и загрузке данных. В этом примере в качестве дополнительного контекста будет использована речь президента США Джо Байдена о положении дел в США в 2022 году. Необработанный текстовый документ доступен в репозитории LangChain на GitHub. Чтобы загрузить данные, вы можете использовать один из множества DocumentLoader (загрузчиков документов), встроенных в LangChain. Document — это словарь с текстом и метаданными. Для загрузки текста будем использовать TextLoader от LangChain.
import requests
from langchain.document_loaders import TextLoader
url = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"
res = requests.get(url)
with open("state_of_the_union.txt", "w") as f:
f.write(res.text)
loader = TextLoader('./state_of_the_union.txt')
documents = loader.load()
Теперь перейдем к разбивке документов на чанки. Поскольку Document в исходном состоянии слишком длинный, чтобы поместиться в контекстное окно LLM, нужно разбить (chunk) его на более мелкие части (чанки). Для этой цели LangChain поставляется со множеством встроенных разделителей текста. Для данного простого примера можно использовать CharacterTextSplitter с размером чанка (chunk_size) около 500 и перекрытием чанков (chunk_overlap) 50, чтобы сохранить непрерывность между частями текста.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
Наконец, настала очередь эмбеддинга и сохранения чанков. Чтобы обеспечить семантический поиск по чанкам текста, необходимо сгенерировать векторные эмбеддинги для всех чанков, а затем сохранить эти эмбеддинги. Для генерации векторных эмбеддингов можно использовать эмбеддинг-модель от OpenAI, а для их хранения — векторную базу данных Weaviate. При вызове функции .from_documents() векторная база данных автоматически заполняется чанками.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
import weaviate
from weaviate.embedded import EmbeddedOptions
client = weaviate.Client(
embedded_options = EmbeddedOptions()
)
vectorstore = Weaviate.from_documents(
client = client,
documents = chunks,
embedding = OpenAIEmbeddings(),
by_text = False
)
Шаг 1. Извлечение (Retrieve)
После того, как векторная база данных заполнена, можно определить ее в качестве ретривера (retriever), который извлекает дополнительный контекст на основе семантического сходства между пользовательским запросом и чанками-эмбеддингами.
retriever = vectorstore.as_retriever()
Шаг 2: Дополнение (Augment)
Чтобы вносить в промпт дополнительный контекст, необходимо подготовить шаблон промпта (prompt template). Шаблон промпта позволяет легко настроить промпт, как показано ниже.
from langchain.prompts import ChatPromptTemplate
template = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
prompt = ChatPromptTemplate.from_template(template)
print(prompt)
Шаг 3: Генерирование (Generate)
Наконец, можно построить цепочку для RAG-пайплайна, соединив вместе ретривер, шаблон промпта и LLM. Когда RAG-цепочка будет определена, появится возможность вызвать ее.
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
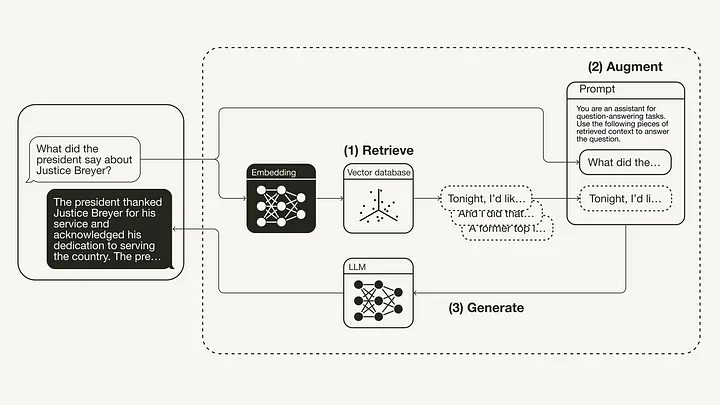
query = "What did the president say about Justice Breyer"
rag_chain.invoke(query)
"The president thanked Justice Breyer for his service and acknowledged his dedication to serving the country.
The president also mentioned that he nominated Judge Ketanji Brown Jackson as a successor to continue Justice Breyer's legacy of excellence."
Ниже показан получившийся RAG-пайплайн для данного примера:
Заключение
Мы рассмотрели концепцию RAG, представленную в статье “Генерация ответа, дополненная результатами поиска, для решения информационно емких задач NLP” от 2020 года. После ознакомления с теоретической базой концепции, включая проблему и ее решение, была продемонстрирована реализация RAG на языке Python. В итоге был выполнен RAG-пайплайн, использующий LLM от OpenAI в сочетании с векторной базой данных Weaviate и эмбеддинг-моделью OpenAI. Для оркестровки был задействован фреймворк LangChain.
Читайте также:
- 12 стратегий настройки готовых к производству RAG-приложений
- 10 способов повысить эффективность RAG-системы
- Как создать Android-приложение чат-бота с генеративным ИИ Google
Читайте нас в Telegram, VK и Дзен
Перевод статьи Leonie Monigatti: Retrieval-Augmented Generation (RAG): From Theory to LangChain Implementation





