
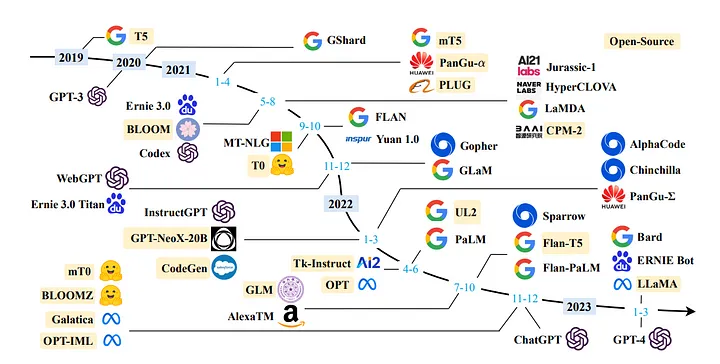
В последние несколько месяцев большие языковые модели (Large Language Models, LLM) привлекли к себе внимание разработчиков со всего мира. Эти модели открывают захватывающие перспективы, особенно для создателей чат-ботов, персональных помощников и контента. Возможности, которые предлагают LLM, вызвали волну энтузиазма в сообществе разработчиков и специалистов по искусственному интеллекту и обработке естественного языка.
Что такое LLM?
LLM — это модели машинного обучения, способные создавать тексты на языке, близком к человеческому, и воспринимать промпты (запросы) естественным образом. Эти модели проходят обучение на обширных массивах данных, включающих книги, статьи, сайты и другие источники. Выявляя в предоставляемых данных статистические закономерности, LLM предсказывают наиболее вероятные слова и фразы, которые должны следовать за введенным текстом.
Использование LLM позволяет включать данные, специфичные для конкретных областей, что способствует эффективному выполнению запросов. Это особенно удобно при работе с информацией, которая не была доступна модели при ее первоначальном обучении, например с внутренней документацией или хранилищем данных компании.
Архитектура, используемая для этой цели, известна как Retrieval Augmentation Generation (генерация ответа, дополненная результатами поиска). Иногда ее также называют Generative Question Answering (генеративная вопросно-ответная система).
Что такое LangChain?
LangChain — это фреймворк, находящийся в свободном доступе. Он помогает разработчикам создавать приложения на основе языковых моделей, в частности LLM.
LangChain революционизирует процесс разработки широкого спектра приложений, включая чат-боты, генеративные вопросно-ответные системы и генераторы информационных обзоров текстовых и аудиовизуальных материалов. Благодаря бесшовному цепочечному соединению компонентов из различных модулей, LangChain позволяет создавать исключительные приложения, основанные на использовании возможностей LLM.
Подробности в официальной документации.
Для мотивации
В данной статье мы рассмотрим пошаговый процесс создания с нуля личного помощника по работе с документами. Будем использовать LLaMA 7b и Langchain, библиотеку с открытым исходным кодом, специально разработанную для бесшовной интеграции с LLM.
Ниже приводится структура статьи с указанием разделов, содержащих подробное описание разработки.
- Настройка виртуальной среды и создание файловой структуры.
- Установка LLM на локальный компьютер.
- Интеграция LLM с LangChain и настройка PromptTemplate.
- Поиск документов и генерация ответов.
- Создание приложения с использованием Streamlit.
Раздел 1. Настройка виртуальной среды и создание файловой структуры
Настройка виртуальной среды обеспечит контролируемую и изолированную среду для запуска приложения. Это гарантирует изолирование зависимостей приложения от других общесистемных пакетов. Такой подход упрощает управление зависимостями и помогает поддерживать согласованность в различных средах.
Для настройки виртуальной среды для данного приложения я предоставлю pip-файл в репозитории GitHub. Сначала создадим необходимую файловую структуру, как показано на изображении ниже. В качестве альтернативы можно просто клонировать репозиторий для получения необходимых файлов.
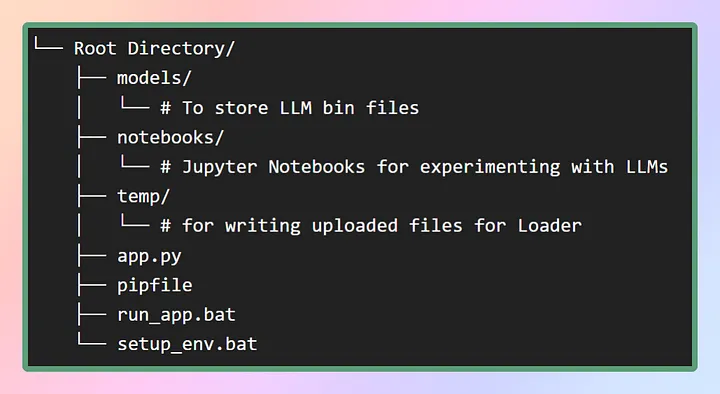
В папке models будут храниться загружаемые LLM, а pip-файл будет находиться в корневом каталоге.
Для создания виртуальной среды и установки в нее всех зависимостей можно воспользоваться командой pipenv install из того же каталога или просто запустить пакетный файл setup_env.bat, который установит все зависимости из pip-файла. Это обеспечит установку всех необходимых пакетов и библиотек в виртуальную среду. После успешной установки зависимостей можно переходить к следующему шагу — загрузке необходимых моделей. Вот ссылка на репозиторий.
Раздел 2. Установка LLaMA на локальный компьютер
Что такое LLaMA?
LLaMA (Large Language Model Meta AI) — это новая большая языковая модель, разработанная Meta AI*, которая является материнской компанией Facebook*. Благодаря разнообразной коллекции моделей с числом параметров от 7 до 65 млрд, LLaMA является одной из наиболее полных языковых моделей. 24 февраля 2023 года компания Meta* выложила LLaMA в открытый доступ.
Учитывая замечательные возможности LLaMA, мы решили использовать эту мощную языковую модель для достижения своих целей. В данном случае воспользуемся самой малой версией LLaMA, известной как LLaMA 7B. Несмотря на столь уменьшенный размер, LLaMA 7B обладает впечатляющими возможностями обработки языка, что позволит эффективно и результативно достичь поставленных целей.
Для функционирования LLM на локальном процессоре необходима локальная модель в формате GGML. Ее можно получить несколькими способами, но наиболее простым является загрузка bin-файла непосредственно из репозитория Hugging Face Models. Для нашего случая потребуется загрузка модели LLaMA 7B. Эти модели имеют открытый исходный код, и их можно скачать бесплатно.
Если хотите сэкономить время и силы, вот прямая ссылка для загрузки моделей. Просто скачайте любую версию, а затем переместите файл в папку models в корневом каталоге.
Что такое GGML?
GGML — Tensor-библиотека для машинного обучения. Это просто библиотека C++, которая позволяет запускать LLM на CPU или CPU + GPU. Она определяет бинарный формат для распространения больших языковых моделей. GGML использует технику, называемую квантованием, которая позволяет запускать большие языковые модели на оборудовании пользователя.
Что такое квантование?
Веса LLM — это числа с плавающей точкой (десятичные). Как для представления большого целого числа (например, 1000) требуется больше места по сравнению с малым целым числом (например, 1), так и для представления числа с плавающей точкой высокой точности (например, 0,0001) требуется больше места по сравнению с числом с плавающей точкой низкой точности (например, 0,1).
Процесс квантования большой языковой модели заключается в уменьшении точности представления весов с целью сокращения ресурсов, необходимых для использования модели. GGML поддерживает несколько различных стратегий квантования (например, 4-, 5- и 8-битное квантование), каждая из которых предлагает различные компромиссы между эффективностью и производительностью.

Для эффективного использования моделей необходимо учитывать требования к памяти и диску. Поскольку в настоящее время модели полностью загружаются в память, необходимо иметь достаточно места на диске для их хранения и достаточно оперативной памяти для их загрузки во время установки. Если речь идет о модели 65B, то даже после квантования рекомендуется иметь в наличии не менее 40 Гбайт оперативной памяти. Стоит отметить, что требования к памяти и диску в настоящее время эквивалентны.
Квантование играет решающую роль в управлении этими требованиями к ресурсам. Если только у вас нет доступа к исключительным вычислительным ресурсам.
За счет снижения точности параметров модели и оптимизации использования памяти квантование позволяет применять модели на более скромных аппаратных конфигурациях. Это позволяет сохранить целесообразность и эффективность использования моделей для более широкого круга систем.
Как применять GGML в Python, если речь идет о библиотеке C++?
Вот тут-то и вступает в игру Python-биндинг. Под биндингом (обвязкой) понимается процесс создания моста или интерфейса между двумя языками, например Python и C++.
Мы будем использовать llama-cpp-python, который является Python-биндингом для llama.cpp, выполняющего функции вывода модели LLaMA на чистом C/C++. Основная задача llama.cpp — запустить модель LLaMA с использованием 4-битного целочисленного квантования. Такая интеграция позволяет эффективно применять модель LLaMA, используя преимущества реализации на языке C/C++ и достоинства 4-битного целочисленного квантования.

Подготовив модель GGML и установив все зависимости (благодаря pip-файлу), можно совершить погружение в увлекательный мир LangChain. Но прежде выполним привычный ритуал “Hello World”. Это традиция, которой мы следуем при знакомстве с новым языком или фреймворком, ведь LLM — тоже языковая модель.
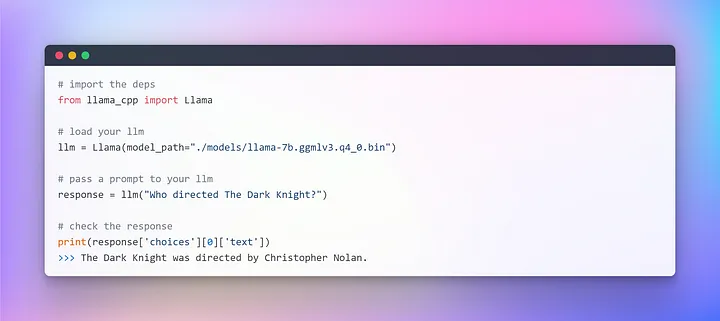
Мы успешно установили первую LLM на CPU, полностью автономно и полностью рандомизированно (можете поэкспериментировать с гиперпараметром температуры).
После прохождения этого важного этапа, мы вплотную приблизились к выполнению основной задачи — генерации ответов на вопросы на основе пользовательского текста с помощью фреймворка LangChain.
Раздел 3. Начало работы с LLM: интеграция с LangChain
В предыдущем разделе мы инициализировали LLM с помощью llama cpp. Теперь воспользуемся фреймворком LangChain для разработки приложения с применением LLM. Основным интерфейсом, через который можно взаимодействовать с моделями, является текст. Упрощенно говоря, многие модели представляют собой text in (ввод текста), text out (вывод теста). Таким образом, многие интерфейсы в LangChain сосредоточены вокруг текста.
Запуск промпт-инжиниринга
В постоянно развивающейся области программирования появилась интересная парадигма: промптинг. Под промптингом подразумевается передачи языковой модели определенных входных данных для получения желаемого ответа. Этот инновационный подход позволяет формировать выходные данные модели на основе предоставленных данных.
Поразительно, как нюансы формулировки промпта способны существенно повлиять на характер и содержание ответа модели. В зависимости от формулировки результаты могут отличаться кардинально, что подчеркивает важность тщательной работы над составлением промптов.
Для обеспечения удобного взаимодействия с LLM в LangChain предусмотрено несколько классов и функций, облегчающих создание промптов и работу с ними с помощью шаблона промптов (Prompt Template). Это воспроизводимый способ генерации промптов. Он содержит текстовую строку-шаблон, которая может принимать набор параметров от конечного пользователя и генерировать промпт. Рассмотрим несколько примеров.
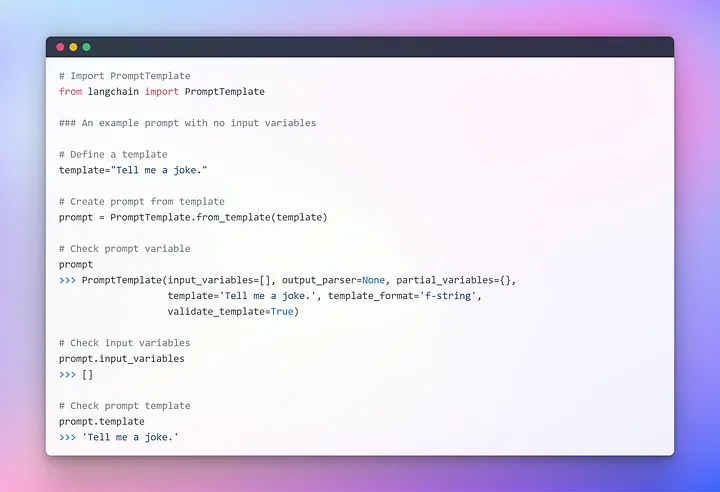
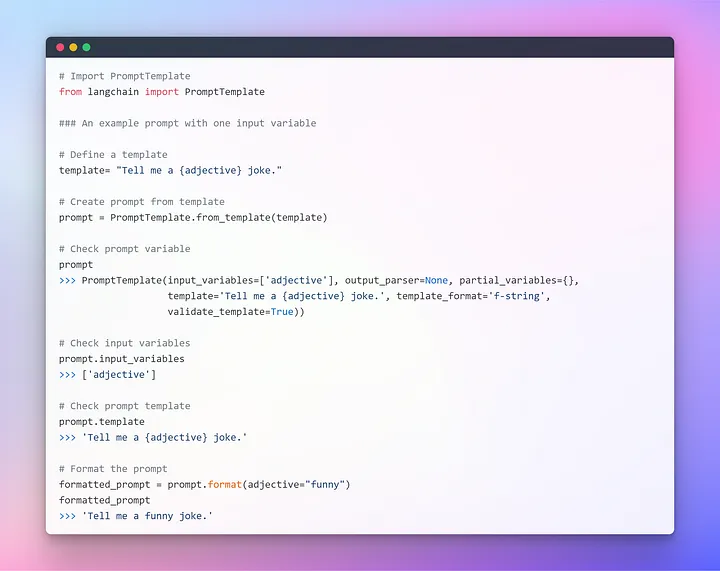
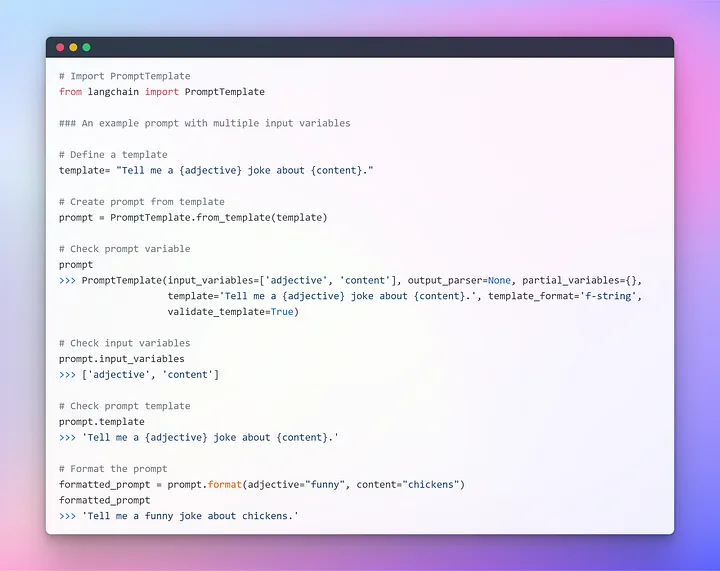
Надеюсь, предыдущее объяснение позволило вам составить более четкое представление о концепции промптинга. Теперь перейдем к передаче промтов LLM.
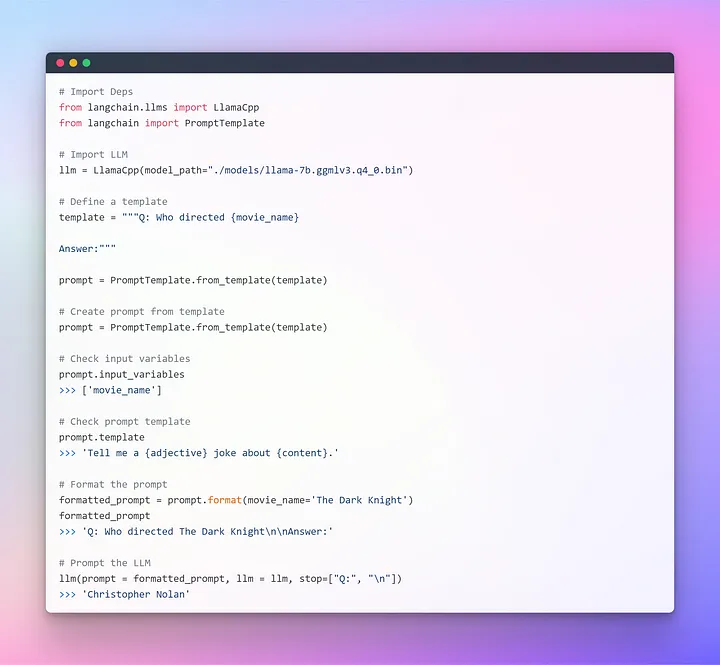
Это прекрасно работает, но не является оптимальным вариантом применения LangChain. До сих пор мы использовали отдельные компоненты: с помощью Prompt Template форматировали промпты, затем передавали эти параметры LLM для генерации ответа. Использование отдельной LLM вполне подходит для простых приложений, но более сложные требуют сцепления моделей — либо друг с другом, либо с другими компонентами.
LangChain предоставляет Chain-интерфейс для таких цепочечных приложений. Мы определяем цепочку в общем виде как последовательность вызовов компонентов, которая может включать в себя другие цепочки. Цепочки позволяют объединять несколько компонентов для создания единого целостного приложения. Например, можно создать цепочку, которая принимает пользовательский ввод, форматирует его с помощью Prompt Template, а затем передает отформатированный ответ LLM. Можно создавать более сложные цепочки, объединяя несколько цепочек вместе или комбинируя цепочки с другими компонентами.
Для более четкого понимания создадим очень простую цепочку, которая будет принимать пользовательский ввод, форматировать промпт, а затем передавать его LLM, используя уже созданные нами отдельные компоненты.
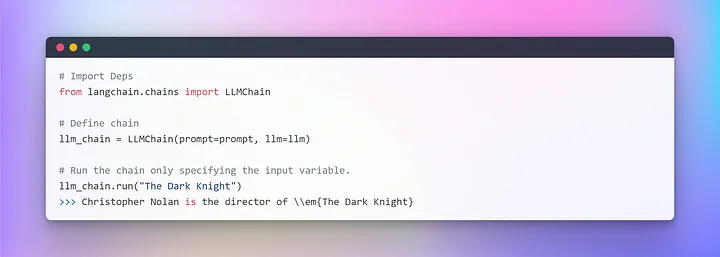
При работе с несколькими переменными есть возможность вводить их совместно, используя словарь. На этом данный раздел завершается, и мы переходим к основной части, в которой будем использовать внешний текст в качестве ретривера для генерации ответов на вопросы.
Раздел 4. Генерация эмбеддингов и векторного хранилища для ответов на вопросы
Во многих LLM-приложениях возникает необходимость в пользовательских данных, которые не входят в обучающий набор модели. LangChain предоставляет необходимые компоненты для загрузки, преобразования, хранения и запроса данных.
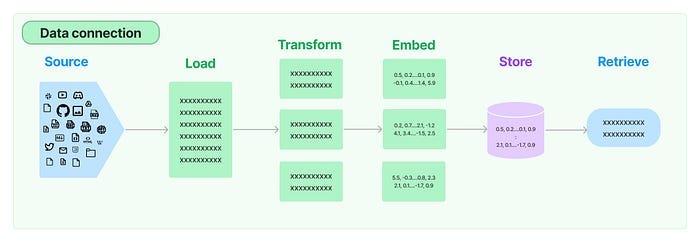
Пять этапов передачи данных в LangChain:
- Document Loader (загрузчик документов). Выполняет загрузку данных в виде документов.
- Document Transformer (преобразователь документов). Разбивает документ на более мелкие фрагменты.
- Embedding (встраивание). Преобразует фрагменты в векторные представления, так называемые эмбеддинги.
- Vector Stores (хранилища векторов). Используются для хранения векторных представлений в векторной базе данных.
- Retrievers (извлекатели). Используется для извлечения набора векторов, которые наиболее похожи на запрос, в виде вектора, встроенного в то же латентное пространство.
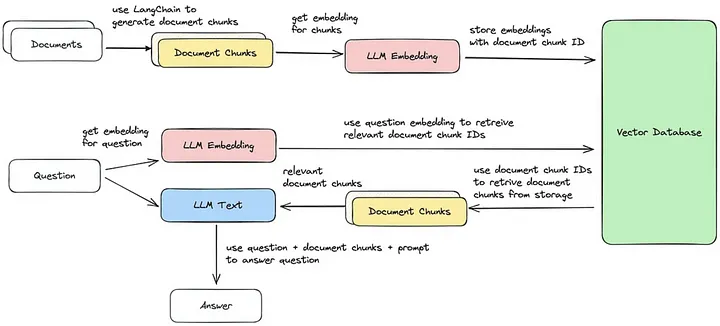
Теперь рассмотрим каждый из пяти шагов, чтобы выполнить извлечение фрагментов документов, наиболее схожих с запросом. Это позволит сгенерировать ответ на основе полученного векторного фрагмента, как показано на изображении.
Однако прежде чем приступить к дальнейшим действиям, необходимо подготовить текст для выполнения вышеуказанных задач. В качестве примера я скопировал из Википедии текст о популярных супергероях вселенной DC. Вот он:

Загрузка и преобразование документов
Для начала создадим объект документа. В данном примере будем использовать текстовый загрузчик. Однако надо иметь в виду, что LangChain может поддерживать несколько документов, поэтому в зависимости от конкретного документа можно использовать различные загрузчики. Применим метод load для извлечения данных и их загрузки в виде документов из предварительно настроенного источника.
После загрузки документа приступим к его преобразованию путем разбивки на более мелкие фрагменты. Для этого воспользуемся функцией TextSplitter. По умолчанию она разбивает документ по разделителю ‘\n\n’. Однако если установить разделитель в null и определить конкретный размер фрагмента, то каждый фрагмент будет иметь указанную длину. Следовательно, длина результирующего списка будет равна длине документа, деленной на размер фрагмента. В общем случае это будет выглядеть примерно так: list length = length of doc / chunk size (длина списка = длина документа / размер фрагмента). Но пора подкрепить слова действиями:
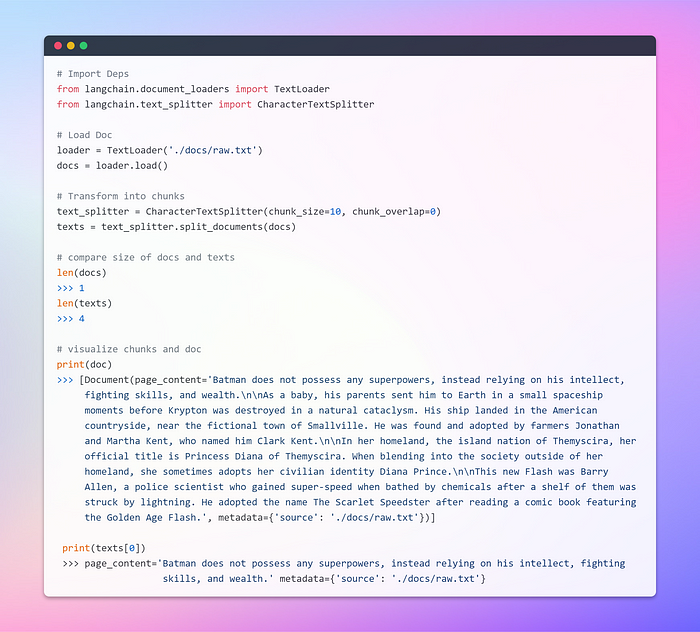
Следующий этап — эмбеддинги
Это самый ответственный этап. Эмбеддинги генерируют векторное изображение текстового контента. Это имеет практическое значение, так как позволяет концептуализировать текст в векторном пространстве.
Эмбеддинг слова — это просто векторное представление слова, причем вектор содержит вещественные числа. Поскольку каждый язык обычно включает по меньшей мере десятки тысяч слов, простые двоичные векторы слов могут стать непрактичными из-за большого числа измерений. Эмбеддинги слов решают эту проблему, предоставляя плотные представления слов в низкоразмерном векторном пространстве.
Говоря об извлечении, мы имеем в виду извлечение набора векторов, наиболее похожих на запрос, в виде вектора, вложенного в то же латентное пространство.
Базовый класс Embeddings в LangChain предоставляет два метода: для эмбеддинга документов и для эмбеддинга запроса. В первом случае на вход принимается несколько текстов, во втором — один текст.
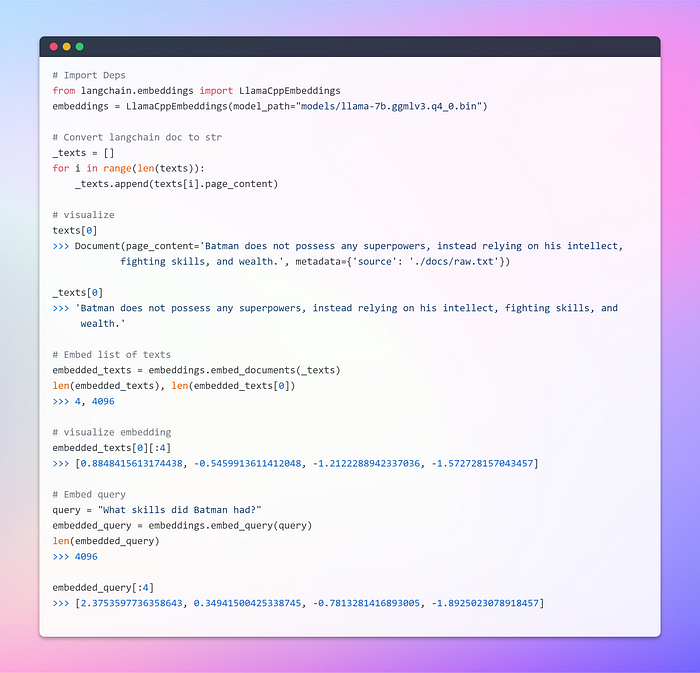
Создание векторного хранилища и извлечение документов
Векторное хранилище эффективно управляет хранением внедренных данных и облегчает операции векторного поиска. Эмбеддинг и хранение полученных векторов эмбеддинга являются распространенными методами хранения и поиска неструктурированных данных. Во время выполнения неструктурированного запроса он также подвергается эмбеддингу, и извлекаются векторы эмбеддинга, имеющие наибольшее сходство с запросом эмбеддинга. Такой подход позволяет эффективно извлекать релевантную информацию из хранилища векторов.
В данном случае мы будем использовать Chroma — базу данных эмбеддинга и хранилище векторов, специально созданное для упрощения разработки ИИ-приложений, использующих эмбеддинги. Она предлагает полный набор встроенных инструментов и функциональных возможностей, облегчающих начальную настройку. Все эти инструменты можно легко установить на локальный компьютер, выполнив простую команду pip install chromadb.

До сих пор мы наблюдали замечательные возможности эмбеддингов и векторных хранилищ в извлечении релевантных фрагментов из обширных коллекций документов. Теперь настало время представить LLM извлеченный фрагмент в качестве контекста к запросу. Сейчас LLM по нашей команде должна сгенерировать ответ на основе предоставленной информации.
Здесь необходимо лишний раз подчеркнуть важность удачно структурированного промпта. Грамотно сформулированный промпт позволяет снизить вероятность возникновения у LLM галлюцинаций — придумывания фактов в условиях неопределенности.
Перейдем к заключительному этапу и выясним, способна ли LLM дать убедительный ответ.

Вот он, долгожданный момент! Мы только что создали диалогового бота, используя LLM, установленную на локальном компьютере.
Раздел 5. Используем Streamlit
Этот раздел не является обязательным, поскольку не служит исчерпывающим руководством по Streamlit. Не буду углубляться, просто представлю базовое приложение, позволяющее пользователям загружать любой текстовый документ и затем задавать вопросы с помощью текстового ввода. По сути, функциональность останется такой же, как и в предыдущем разделе.
Однако при загрузке файлов в Streamlit необходимо оговорить один момент. Чтобы предотвратить возможные ошибки, связанные с выходом за пределы памяти (особенно если учесть, что LLM требуют много памяти), я буду просто считывать документ и записывать его во временную папку в файловой структуре, назвав ее raw.txt. Таким образом, независимо от исходного названия документа, Textloader будет без проблем обрабатывать его в дальнейшем.
В настоящее время приложение предназначено для работы с текстовыми файлами, но его можно адаптировать для работы с PDF, CSV и другими форматами. Основная концепция остается неизменной, поскольку LLM в первую очередь предназначены для ввода и вывода текста. Кроме того, вы можете экспериментировать с различными LLM, поддерживаемыми биндингами Llama C++.
Не углубляясь в сложные детали, привожу код приложения. Вы можете адаптировать его под свой случай использования.
# Загрузка зависимостей
import streamlit as st
from langchain.llms import LlamaCpp
from langchain.embeddings import LlamaCppEmbeddings
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Кастомизация лейаута
st.set_page_config(page_title="DOCAI", page_icon="🤖", layout="wide", )
st.markdown(f"""
<style>
.stApp {{background-image: url("https://images.unsplash.com/photo-1509537257950-20f875b03669?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=1469&q=80");
background-attachment: fixed;
background-size: cover}}
</style>
""", unsafe_allow_html=True)
# функция для записи загруженного файла в temp
def write_text_file(content, file_path):
try:
with open(file_path, 'w') as file:
file.write(content)
return True
except Exception as e:
print(f"Error occurred while writing the file: {e}")
return False
# установка шаблона промпта
prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Answer:"""
prompt = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
# Инициализация LLM и эмбеддингов
llm = LlamaCpp(model_path="./models/llama-7b.ggmlv3.q4_0.bin")
embeddings = LlamaCppEmbeddings(model_path="models/llama-7b.ggmlv3.q4_0.bin")
llm_chain = LLMChain(llm=llm, prompt=prompt)
st.title("📄 Document Conversation 🤖")
uploaded_file = st.file_uploader("Upload an article", type="txt")
if uploaded_file is not None:
content = uploaded_file.read().decode('utf-8')
# st.write(content)
file_path = "temp/file.txt"
write_text_file(content, file_path)
loader = TextLoader(file_path)
docs = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
texts = text_splitter.split_documents(docs)
db = Chroma.from_documents(texts, embeddings)
st.success("File Loaded Successfully!!")
# Запрс через LLM
question = st.text_input("Ask something from the file", placeholder="Find something similar to: ....this.... in the text?", disabled=not uploaded_file,)
if question:
similar_doc = db.similarity_search(question, k=1)
context = similar_doc[0].page_content
query_llm = LLMChain(llm=llm, prompt=prompt)
response = query_llm.run({"context": context, "question": question})
st.write(response)
Вот как будет выглядеть приложение Streamlit.
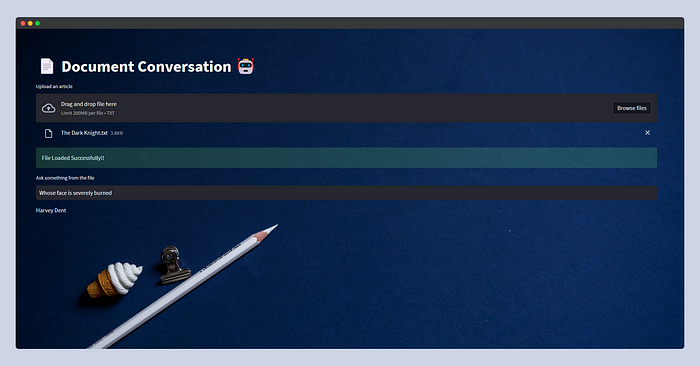
В этот раз я предоставил модели сюжет фильма The Dark Knight (“Темный рыцарь”), скопированный из Википедии, и спросил: “Whose face is severely burnt?” (“Чье лицо сильно обожжено?”). LLM ответила: “Harvey Dent” (“Харви Дента”).
Читайте также:
- Streamlit для создания интерактивных веб-приложений: начало
- Промпт-инжиниринг: как использовать LLM для создания приложений
- Как создать чат-бот на основе данных CSV с LangChain и OpenAI
Читайте нас в Telegram, VK и Дзен
Перевод статьи Afaque Umer: 🦜️ LangChain + Streamlit🔥+ Llama 🦙: Bringing Conversational AI to Your Local Machine 🤯


")


