
Уже больше десятка лет будучи разработчиком и большую часть времени работая на Java, я довольно долго пытался адаптироваться к соглашению о коде Spotify, которое продемонстрировано ниже:
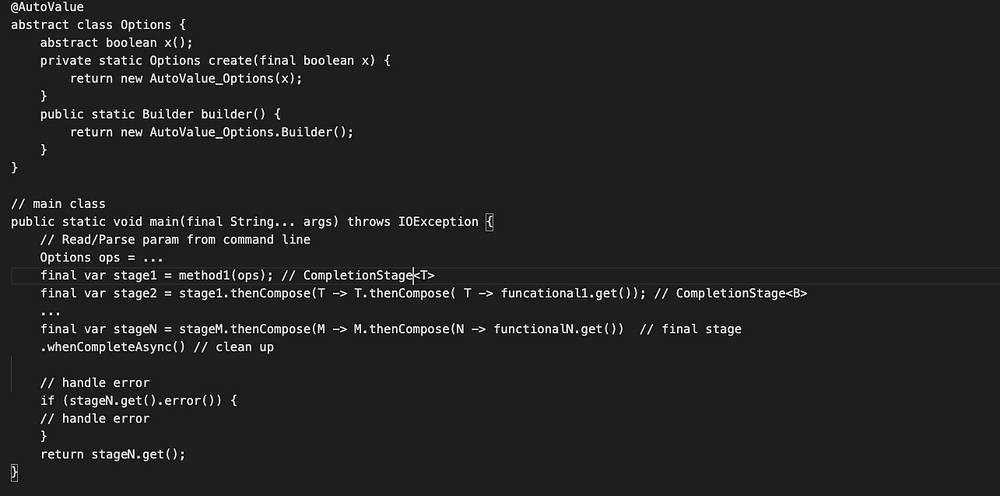
Этот небольшой фрагмент демонстрирует, как выглядит Java-код в компании, где принято асинхронное программирование с помощью CompletionStage и AutoValue.
В этой статье я опишу, как понимаю эти структуры, приведу примеры их использования и, наконец, объясню, почему они того стоят.
Ключевые моменты:
- Понимайте причину, по которой необходимо перейти от параллельного программирования к асинхронному.
- Практикуйте немутирующий шаблон с
AutoValue. - Изучите API
CompletionStageв сравнении соStream. - Освойте различные типы функциональных интерфейсов на Java.
- Изучите плюсы и минусы асинхронного программирования с помощью
CompletionStage.
Параллельно или асинхронно?
Java долгие годы считается безопасным языком высокого уровня, который предоставляет различные API для поддержки блокировки, параллелизма и даже асинхронного программирования. В JDK 1.5 впервые в качестве опробования асинхронных функций был представлен интерфейс Future. Но это, скорее, псевдосинхронность — этот интерфейс не избавлял разработчиков от ожиданий, тогда как некоторые другие языки, например JavaScript и Node.js, уже поддерживали полную асинхронность с применением обратных вызовов.
Эта неловкая ситуация продолжалась до тех пор, пока в JDK 1.8 (считается самой популярной версией JDK во всем мире) не появились CompletableFuture и CompletionStage.
Прежде, чем переходить к деталям асинхронного программирования, стоит заговорить о параллелизме. Как мы все знаем, параллелизмом в программировании пользуются только при обработке общих данных. Но правильно его применять — непросто, как в том, что касается определении правильного момента, так и в освоении необходимых API.
В Java существует множество решений, которые не ограничиваются ключевым словом synchronized, параллельными коллекциями, atomic и различными блокировками для сокрытия сложной логики, таких как CAS, барьеры памяти и кэш процессора. Тем не менее, обычным разработчикам все еще требуются годы, чтобы понять библиотеки, найти разницу между различными вариантами использования и устранить возникающие проблемы производительности. Поверьте мне: невозможно полностью избежать ошибок и проблем с производительностью.
Думаю, никому не нравится писать код, полный блокировок или synchronized. Это не только тяжелый труд для тех, кто работает над ним, но и пытка для любого преемника. Поэтому умные разработчики придумывают способы преодоления барьеров: программирование без блокировки, также называемое неблокирующим — некоторые, возможно, знают или, по крайней мере, слышали об этом. Я не буду углубляться в него, но вкратце перескажу одним предложением. Оно использует примитивы или другие низкоуровневые методы, чтобы преодолеть препятствия и достичь блокировки на верхнем уровне.
Честно говоря, я далеко не эксперт по темам программирования с параллелизмом, но знаю, как избежать попадания в упомянутые ловушки. Не применяйте параллелизм! Но как это?
На самом деле, если разработчики будут следовать некоторым принципам, есть большая вероятность освободить свой код от параллелизма. Ниже приведены три простых правила:
- Не делитесь данными.
- Используйте неизменяемую структуру данных.
- Пишите идемпотентный код.
Держите это в голове: не меняются данные — нет необходимости в блокировках. Однако сложно устоять перед соблазном ярлыков, потому что так легко обновить переменную, написав var a = 2; a = method(a). Таким образом, мы возлагаем надежду на неизменяемый шаблон строителя, чтобы сдерживать разработчиков.
Объект, состояние которого не может быть изменено после построения, называется немутирующим объектом.
И библиотека автозаполнения от Google — это элегантный выбор для применения неизменяемого шаблона.
AutoValue использует конструктор для создания экземпляра объекта, и в каждом поле есть только геттер, но нет сеттера. Типичный пример автоматического значения AutoValue показан ниже:
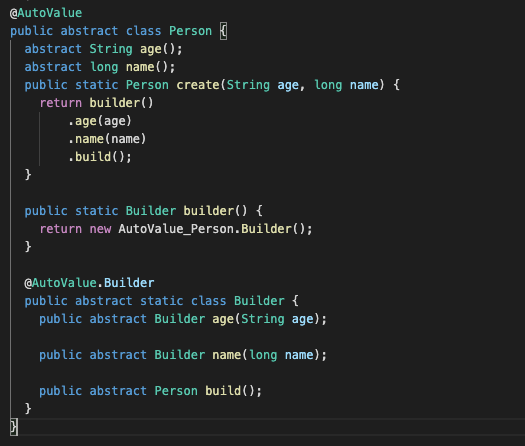
Для ускорения разработки как в Eclipse, так и в IntelliJ есть полезные плагины.
Если вы хотите узнать больше об AutoValue, пожалуйста, обратитесь к этому документу. Я не могу сделать ничего лучше.
Хотя немутирующий шаблон имеет свои преимущества, его еще недостаточно для замены параллелизма. Один из способов исправить дефекты — сделать ваш код идемпотентным. Встречающаяся повсюду в современной архитектуре, идемпотентность — один из наиболее важных символов микросервисов. Различные модули вызывают другие через REST API или методы RPC, и это не влияет на конечный результат, независимо от того, сколько раз происходят попытки вызова.
Асинхронное программирование
Разработчики хотят, чтобы их код выполнялся как можно быстрее, и это одна из причин, по которым люди прибегают к параллелизму, разделяя задачу на подзадачи и максимально исследуя возможности многоядерных процессоров.
Когда мы берем на вооружение немутирующий шаблон, где возможно копирование данных и, следовательно, требуется больше ресурсов памяти и процессора, программа замедляется. Пришло время обратиться к асинхронному программированию.
Асинхронное программирование — это способ параллельного программирования, при котором единица работы выполняется отдельно от основного потока приложения и уведомляет вызывающий поток о его завершении, сбое или прогрессе. — из статьи “Asynchronous Programming in .NET”
Наиболее распространенный пример асинхронного программирования — использование обратных вызовов в REST API JS.
CompletionStage — ключ к достижению полностью асинхронного режима программирования, а CompletableFuture — его реализация. Рассмотрим простой пример.

Мы в Spotify создаем код, с самого начала и на протяжении всего метода применяя CompletionStage, и в конечном итоге возвращаем конкретные объекты.
Это сложнее, чем кажется, если у вас нет предыдущего опыта с CompletionStage или функционального программирования, и все становится еще хуже, если вы неправильно используете API. У меня ушли месяцы на разработку и переработку десятков неоднократно проверенных пулл-реквестов, чтобы ознакомиться с ними.
Суть заключается в конвейере. Поэтому очень важно выяснить, как построить конвейер с CompletionStage<?>, используя все API и функциональные интерфейсы от начала до конца.
Во-первых, нужно понять API. У CompletionStage есть более тридцати методов, и крайне проблематично освоить их все. Но если вам удобно пользоваться Stream, CompletionStage легко понять, сравнив с API Stream. Ниже приведен график, на котором для сравнения перечислены некоторые часто используемые API.

Я разделяю API на четыре основные группы:
- Build (сборка);
- Intermediate (промежуточная операция);
- Contact (контакт);
- Terminate (прекращение).
Операция сборки — это способ создать Stream или CompletionStage. Поток часто генерируется из API-интерфейсов массива или коллекции, и CompletionStage полагается на своего исполнителя, CompletableFuture, для выполнения этой работы.
Промежуточная операция часто означает изменение входных данных. Все методы, обернутые Stream или CompletionStage, принимают Function, чтобы совершить какое-то волшебство над входными данными и вернуть нечто другое.
Операция контакта очень часто встречается в CompletionStage, но не в Stream. У CompletionStage есть методы, позволяющие принимать четыре различных функциональных интерфейса и обеспечивать поддержку почти всех типов поведения. Я подробнее остановлюсь на этом позже.
Операция прекращения, по сравнению с тремя вышеперечисленными категориями, отличается сильнее всего. Мы привыкли завершать поток, превращая его в коллекцию или устаревший forEach. Что касается CompletionStage, у него не так много методов завершения, как у Stream, и большинство из них возвращают CompletionStage, в надежде, что конвейер никогда не закончится.
Помимо этих четырех групп, в CompletionStage есть два дополнительных типа API:
- Те, которые естественным образом поддерживают асинхронность. Один метод API часто имеет три преобразования, поддерживающих асинхронность и асинхронность с исполнителем.

- Те, которые поддерживают обработку ошибок. Как в
CompletionStage, так и вCompletableFutureесть API-интерфейсы, которые поддерживают исключение, сбой и время ожидания, что может быть полезно для управления потоком.

Хотя у Stream и CompletionStage есть кое-что общее, они сильно отличаются по масштабу. Stream настолько ограничен, что предназначен только для операций сбора. Напротив, CompletionStage может состоять из любых операций и дает разработчикам больше свободы — мы можем строить, комбинировать, контактировать, мутировать практически при любых обстоятельствах. Представьте, что вводите A и B, получаете C на следующем шаге и асинхронно выполняете другую задачу, и в конечном итоге у вас оказывается D.
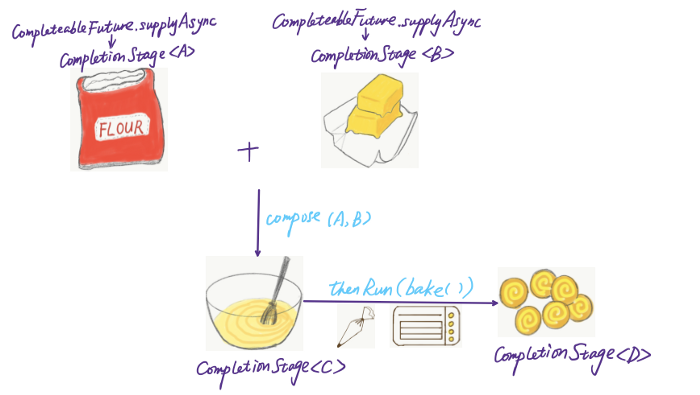
Эти операции могут быть настолько сложными, насколько вы можете себе представить, поэтому попробуйте попрактиковать их самостоятельно.
Функциональное программирование
Наилучшая практика для CompletionStage — построение конвейера, который проходит через всю программу и в конце возвращает определенный результат или ошибку.
Чтобы достичь этого, нужно углубиться в функциональное программирование. Как вы, возможно, заметили, в разделе операций контакта приведенной выше таблицы выделены четыре функциональных интерфейса. Именно они — настоящие душа и сердце построения конвейера.
“Функциональное программирование — парадигма программирования, стиль построения структуры и элементов компьютерных программ, который рассматривает вычисления как оценку математических функций и избегает изменения состояния и данных.” — Википедия
Статьи, излагающие функциональное программирование с разных точек зрения и на разных языках, сейчас повсюду, и вы задаетесь вопросом, почему вдруг все говорят об этом. Ответ в том, что мы хотим вернуть простоту.
Взгляните на свой код.
- Есть ли у него функция, содержащая сотни строк?
- Есть ли у него большой цикл, включающий сложную логику?
- Вы сходите с ума от отладки или рефакторинга?
Если ответы “да”, то рассмотрите возможность применения функционального программирования.
Возвращаясь к теме, я хочу кратко объяснить функциональные интерфейсы. Представленные в JDK8, они сопровождаются аннотацией @Functioninterface и обычно содержат только один абстрактный метод. Наиболее важный их эффект в Java — обеспечение перехода в многоконтекстных ситуациях. Согласно математической концепции, они делятся на два типа: унарные и бинарные функции.
- Унарные функции включают
Function<T, R>,Consumer<T>,Supplier<T>,Predicate<T>,UnaryOperator<T>. - Бинарные функции включают
BiFunction<T, U, R>,BiConsumer<T, U>,BiPredicate<T, U>,BiOperator<T>.
Конечно, я могу объяснить функциональные интерфейсы на примерах, как во многих других случаях, но на мой взгляд, практичнее будет таблица, содержащая некоторые ключевые факторы и сравнение различных интерфейсов.

Интерфейсы Consumer и Supplier легко получить по имени, независимо от того, унарные они или бинарные. Интерфейсы Consumer выполняют действие без возвращаемого типа, таким образом, они обращают все в void. Интерфейсы Supplier считаются генераторами, с которых начинается Stream<T> или CompletionStage<T>.
Интерфейсы Function<T,U> и Function<T,U,R> широко применяют для составления и передачи между различными методами, поддерживая конвейер в рабочем состоянии.
Если вы еще путаетесь в таблице выше, вам может помочь чтение некоторых примеров кода. Снова возвращаясь к таблице, вы получите более глубокое представление о функциональных интерфейсах.
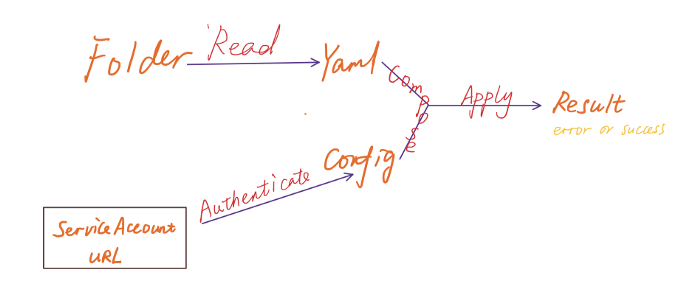
API-интерфейсы CompletionStage часто задействуют Consumer, Function, BiFunction. Итак, суть в том, как объединить несколько этапов в один в зависимости от поведения кода. Проект, над которым я работаю, может послужить прекрасным примером. В нем требовалось прочитать папку Kubernetes, содержащую несколько файлов ресурсов (таких как служба, развертывание и HPA), применить их к клиенту с помощью библиотеки fabric8 KubernetesClient, и вернуть результат либо ошибку. Чтобы упростить, я разделил его на четыре этапа:
- Чтение справочника;
- Аутентификация для клиента;
- Применение YAML ресурсов;
- Наконец, возвращение.
Обращаю внимание, что весь код выполняется асинхронно через CompletionStage.
Вот простой график перехода CompletionStage между четырьмя этапами.
Ограничиваясь рамками статьи, я вставлю здесь только некоторые ключевые примеры кода.
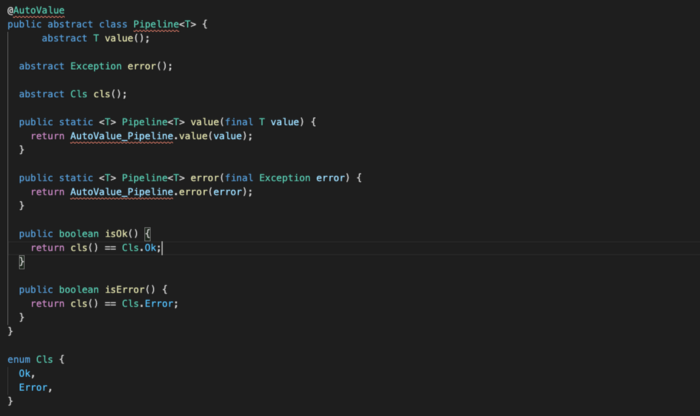
ApplyResourceкак основной класс и точка входа

- Для передачи различных результатов между этапами используется класс
Pipeline<T>. Здесь вся магия заключена вT.
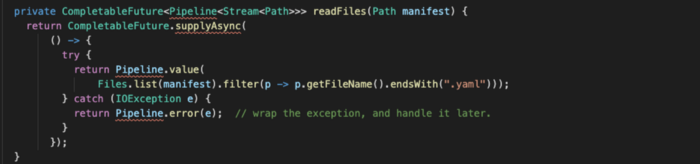
- Метод
readFiles. Конвейер стартует здесь и возвращаетCompletionStage<Pipeline<Stream<Path>>>.
- Метод
authenticate. Результат этого метода совершенно не имеет отношения к предыдущему методуreadFiles, поэтому нужно преобразовать оба результата в новый объектFileAndAuthи перенести его (Pipeline<FileAndAuth>) на следующий этап.

- Следующий шаг — применение всех конфигураций с информацией для аутентификации через клиент Kubernetes. В конечном итоге, нам возвращается
Pipeline<Result>.
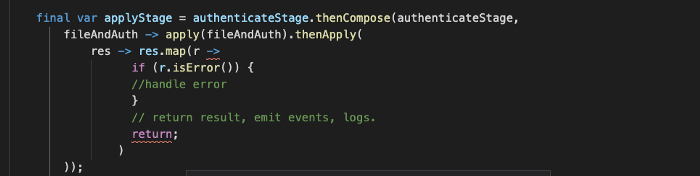
Наконец, появляется возможность обрабатывать ошибки или возвращать результаты.
Вышеперечисленные концепции и API могут немного ошеломлять для новичка, поэтому мне хотелось бы поделиться еще одним небольшим трюком, а именно: запоминание типов параметров API типа Runnable и игнорирование результата вычисления.
Consumer — это результат расчета чистого потребления;
BiConsumer объединяет чистое потребление другого CompletionStage;
Function преобразует результат расчета;
BiFunction объединяет результат расчета другого CompletionStage для преобразования.
Преимущества асинхронного программирования
Как описано выше, применение AutoValue и CompletionStage для создания полностью асинхронной программы — это то, как все работает в Spotify. Что касается причин такого выбора, с моей точки зрения важнейшими будут четыре.
Безопасность
Неизменяемые модели данных освобождают разработчиков от беспокойства по поводу параллельной обработки, взаимоблокировок, плохой производительности и других сложных ситуаций.
Более легкая мутация
Неизменяемые модели данных и все функциональные интерфейсы упрощают изменение данных. Все копируется, а не обновляется. И больше никаких барьеров памяти или блокировок, только краткий и читаемый код.
Производительность
Что касается производительности программ, CompletionStage позволяет программам задействовать преимущества многоядерных процессоров и избавляет от необходимости управлять потоками. По сравнению с многопоточностью, асинхронность представляется более легкой. Кроме того, эффективность работы также повышается, поскольку CompletionStage удобнее для разработчиков, чем параллельный код.
Масштабируемость
Не храните состояние своего сервиса, сделайте его идемпотентным. Почему? Потому что код будет намного удобнее масштабировать. И все крупные облачные провайдеры поддерживают автоматическое масштабирование с помощью Kubernetes, что подходит для данного случая. Ваша программа становится дружественнее к облаку!
Что можно улучшить
Ничто не идеально, в том числе этот шаблон кода. На практике у меня возникли кое-какие трудности.
Трудно писать код
Как “уродливый” код, так и элегантный код могут выполняться и достигать результата. Но последний сложнее написать, если у вас нет многолетней практики и глубокого понимания API.
Трудно писать тесты
Разработчики тратят две трети своего времени на написание тестов, и в этом случае понадобится еще больше времени, поскольку асинхронный код всегда сложно тестировать.
В любом случае, с AutoValue и CompletionStage меня ожидали и горечь, и сладости. Но мой выбор был сделан.
Альтернативы
Существует множество открытых фреймворков, уже использующих такую модель асинхронного программирования, к примеру Play (веб-фреймворк без состояния), Quarkus (Java-клиент Kubernetes), lettuce (неблокирующий клиент Redis) и т.д.
Поэтому, если вам действительно трудно начать создавать что-то самостоятельно, выберите подходящую библиотеку, которая поможет вам начать и усвоить необходимые навыки программирования из нее. В конце концов, пройдите собственный путь к написанию полностью асинхронного кода.
Читайте также:
- Как пользоваться Thread.sleep на JVM без блокировки
- Все о ключевых словах static и final
- Топ-10 книг для Java-программистов
Читайте нас в Telegram, VK и Дзен
Перевод статьи Stefanie Lai: Make Your Java Code Fully Async





