
Хотите создать инструмент, позволяющий собирать и анализировать данные из разных источников? Или просто внедрить в свой проект полнофункциональное средство аналитики? Тогда используйте ClickHouse в сочетании с Kafka.
ClickHouse
Наверняка вы уже слышали и о ClickHouse, и о Kafka, но отдельно. Разберемся, на что они способны вместе.
ClickHouse — это колоночная СУБД, позволяющая решать аналитические задачи.
Для построения аналитических отчетов требуется много данных и их агрегирование. Будучи СУБД группы OLAP (сокр. online analytical processing, т. е. «Интерактивная аналитическая обработка»), Clickhouse рассчитана на высокую пропускную способность при вставке данных.
Но это не куча маленьких вставок с постоянными обновлениями и удалениями — а вставки с большим объемом полезных данных, например сразу с миллионами строк. В Clickhouse нет поддержки обновлений и удалений.
При внедрении службы аналитики, вероятно, потребуется общий интерфейс для различных источников данных. На рынке есть много решений. Можно даже создать свой API или пользовательскую шину данных. Но как обеспечить высокую пропускную способность? С этим легко справляется Kafka.
Kafka
Это один из лучших инструментов: он обеспечивает высокую пропускную способность, перемотку сообщений, сохраняет порядок записей и дает высокую точность. Это быстрый и отказоустойчивый инструмент, который хорошо масштабируется.
Kafka позволяет отделять различные подсистемы (микросервисы), т. е. уменьшать связи «все со всеми», играя роль общей шины данных.
Kafka состоит из хорошо синхронизированного сочетания производителей, потребителей и брокера (посредника).
Производители (producers) создают сообщения для тем брокеров, а брокеры хранят эти сообщения и передают потребителям.
Потребители (consumers) подписываются на темы и начинают потреблять данные. В Kafka сообщения хранятся сколь угодно долго, пока позволяет объем памяти и разрешают регулирующие правила.
Брокер включает много тем (например, очереди сообщений или таблицы) для хранения разнообразных объектов домена или сообщений — данных о денежных транзакциях, платежах, операциях, изменениях в профилях пользователей и т. д.
Есть еще один элемент — потоки. Они получают данные от производителей, анализируют их, применяют функции (агрегирование и др.) в режиме реального времени и передают данные потребителям.
Но главный аргумент в пользу Kafka — это поддержка ClickHouse. В ClickHouse есть движок Kafka, облегчающий внедрение Kafka в экосистему аналитики.
Построение минималистичной аналитической системы платежей
Домен
В качестве примера возьмем платежную модель:
Payment
(
id # => первичный ключ
cents # => число центов, содержащихся в платеже
status # => логический — может быть отменен или завершен
created_at # => метка времени создания
payment_method # => строки, содержащие значения Paypal, Braintree и т. д.
version # => метка времени, содержащая дату и время добавления записи в Kafka
)Движок Kafka
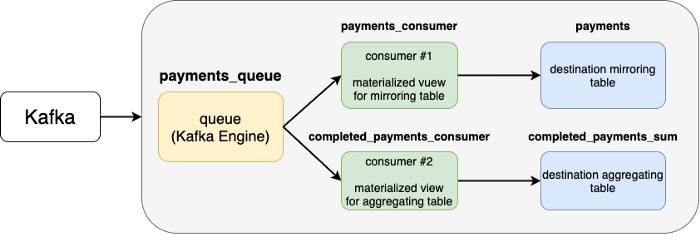
Начинаем с определения таблицы в Clickhouse с помощью Clickhouse Kafka Engine. В случае с настроенным кластером Kafka, чтобы подключить тему к таблице, надо указать всю необходимую информацию. Эта таблица — не конечная цель данных, а поток данных, не позволяющий считывать их более одного раза и выполнять фоновое агрегирование (об этом чуть позже).
Вот как создается такой поток данных (с постфиксом _queue):
CREATE TABLE IF NOT EXISTS payments_queue
(
id UInt64,
status String,
cents Int64,
created_at DateTime,
payment_method String,
version UInt64
)
ENGINE=Kafka('localhost:9292', 'payments_topic', 'payments_group1, 'JSONEachRow');где 1-й аргумент движка Kafka — это брокер, 2-й — тема Kafka, 3-й — группа потребителей (для исключения дублей, т. к. смещение в одной группе одинаково) и последний аргумент — это формат сообщения.
JSONEachRow значит, что данные представлены отдельными строками с валидным значением JSON, разделенным новой строкой, но весь фрагмент данных не является валидным JSON.
Имея единственную возможность считать данные с этого адаптера (таблица Kafka в ClickHouse), нам необходим механизм, позволяющий направлять эти данные в места (относительно) постоянного их хранения.
Постоянное хранилище и потребители
Обычно хранилищ (или таблиц) для хранения данных несколько.
Первый тип хранилища — это зеркало входящих данных. Оно не выполняет никаких агрегирований функций, а лишь хранит данные как есть. Некоторые столбцы здесь можно было бы пропустить, а значения — убрать, но в целом такие таблицы считаются данными строк.
Зачем хранить такие данные в ClickHouse? Чтобы иметь надежный набор необработанных данных, например, для выявления ошибок при агрегировании или для сравнения числа входящих и сохраненных данных (все ли отправленные данные получены?).
Второй тип — это агрегирование. Но одной таблицы агрегирования недостаточно, т. к. обычно по одной и той же модели домена есть несколько разных аналитических отчетов — одним нужно больше данных, другим нужны чуть преобразованные данные и т. д.
Здесь приходятся кстати материализованные представления ClickHouse.
Они отличаются от материализованных представлений других СУБД. Простое объяснение их — триггер вставки.
Почему бы просто не делать записи в таблицу напрямую? Ведь технически это возможно. Все потому же: для одной и той же модели домена нужно несколько таблиц (зеркальная таблица и таблицы для разных отчетов или агрегирования).
Построим эти таблицы и с помощью материализованного представления свяжем таблицу Kafka с таблицей конечного назначения.
Построение конечных таблиц
Начнем с зеркальной таблицы payments («Платежи»).
Создаем ее с помощью следующего оператора SQL:
CREATE TABLE your_db.payments
(
id UInt64,
status String
cents Int64,
created_at DateTime,
payment_method String,
version UInt64
)
Engine=ReplacingMergeTree()
ORDER BY (id, payment_method, status)
PARTITION BY (toStartOfDay(toDate(created_at)), status);Что это за параметры ENGINE, ORDER BY и PARTITION BY? В отличие от традиционных СУБД, в ClickHouse есть расширенная функциональность для выполнения фоновых манипуляций с данными.
Так, при использовании движка таблицы ReplacingMergeTree старые записи заменяются новыми. В ClickHouse они сравниваются по полям параметра ORDER BY: в случае обнаружения похожих записей старую сменяет запись с большим значением версии. Версия — это число, обозначающее дату создания (или обновления), поэтому у более новых записей значение версии больше.
Параметр PARTITION BY используется для разделения данных. В нашем случае разделение применяется для хранения данных по дням и статусу.
После раздел отсоединяется, удаляется целиком, данные очень просто фильтруются, и делается еще много всего — но это уже тема других статей.
В ClickHouse предлагают для большей эффективности число разделов ограничивать несколькими сотнями.
На следующем этапе создадим таблицу агрегирования completed_payments_sum. В ней будут только завершенные платежи. Позже отразим это в материализованном представлении.
Снова используем оператор SQL:
CREATE TABLE your_db.completed_payments_sum
(
cents Int64,
payment_method String,
created_at Date
)
ENGINE = SummingMergeTree()
ORDER BY (payment_method, created_at)
PARTITION BY (toStartOfMonth(created_at));Здесь уже другой движок. Движок агрегирования, принимающий все данные и суммирующий их.
Так, вместо 10 записей по дате date и одному платежному инструменту payment_method в итоге останется одна запись с суммой центов cents, одной датой создания created_at и платежным инструментом payment_method.
Создание потребителей
Свяжем таблицу движка Kafka с конечными таблицами при помощи материализованных представлений.
Проще всего создать материализованное представление для зеркальной таблицы платежей:
CREATE MATERIALIZED VIEW your_db.payments_consumer
TO your_db.payments
AS SELECT *
FROM your_db.payments_queue;Все данные получаем от payments_consumer как есть и отправляем в таблицу payments_table.
Возьмем пример посложнее — прикрепление потребителя к таблице completed_payments_sum. Здесь выбираем только завершенные платежи, поэтому status в сводной таблице не нужен.
Используем оператор SQL:
CREATE MATERIALIZED VIEW your_db.completed_payments_consumer
TO your_db.completed_payments_sum
AS SELECT cents, payment_method, toDate(created_at)
FROM your_db.payments_queue
WHERE status = 'completed';Вот и все. Через некоторое время у нас будут агрегированные значения на каждый день по каждому платежному инструменту payment_method. И мы мгновенно узнаем, например какая сумма центов была за 21 мая 2021 г. по платежному инструменту Paypal:
SELECT cents
FROM your_db.completed_payments_sum
WHERE created_at = '2021-05-21' AND payment_method = 'Paypal';Посмотрите: здесь не используется sum(cents), ведь центы — уже агрегированное значение суммы в таблице completed_payments_sum.
Для полной картины соберем весь SQL-код:
# создание очереди для подключения к Kafka (поток данных)
CREATE TABLE IF NOT EXISTS payments_queue
(
id UInt64,
status String,
cents Int64,
created_at DateTime,
payment_method String,
version UInt64
)
ENGINE=Kafka('localhost:9292', 'payments_topic', 'payments_group1, 'JSONEachRow');
# создание зеркальной таблицы платежей с «сырыми» данными
CREATE TABLE your_db.payments
(
id UInt64,
status String
cents Int64,
created_at DateTime,
payment_method String,
version UInt64
)
Engine=ReplacingMergeTree()
ORDER BY (id, payment_method, status)
PARTITION BY (toStartOfDay(toDate(created_at)), status);
# создание сводной таблицы для завершенных платежей
CREATE TABLE your_db.completed_payments_sum
(
cents Int64,
payment_method String,
created_at Date
)
ENGINE = SummingMergeTree()
ORDER BY (payment_method, created_at)
PARTITION BY (toStartOfMonth(created_at));
# создание потребителя для зеркальной таблицы платежей
CREATE MATERIALIZED VIEW your_db.payments_consumer
TO your_db.payments
AS SELECT *
FROM your_db.payments_queue;
# создание потребителя для сводной таблицы платежей
CREATE MATERIALIZED VIEW your_db.completed_payments_consumer
TO your_db.completed_payments_sum
AS SELECT cents, payment_method, toDate(created_at)
FROM your_db.payments_queue
WHERE status = 'completed';Теперь вы можете запрашивать конечные таблицы (платежи и сумма завершенных платежей) и делать на их основе аналитические расчеты, создавать всевозможные таблицы и собирать необходимые данные для составления отчетов.
В статье рассмотрена настройка с одним узлом. Многоузловая (кластерная) реализация, репликация, разделение данных — темы отдельных статей.🙂
Читайте также:
- 5 инструментов для специалистов по обработке данных
- PostgreSQL вместо Kafka: способ реализации системы очередей
- Руководство по SQL: Как лучше писать запросы
Читайте нас в Telegram, VK и Дзен
Перевод статьи Tim Lavnik: ClickHouse + Kafka = ❤




