
Этот пост посвящен изучению JavaScript, определению и описанию его конструктивных компонентов. Мы поделимся с вами практическими лайфхаками, использованными при создании SessionStack — надежного и высокопроизводительного приложения JavaScript, призванного помочь компаниям оптимизировать цифровой опыт своих пользователей.
Структуры данных позволяют компьютерам эффективно хранить данные и манипулировать ими.
Мы рассмотрим операции со структурами данных, сосредоточив внимание на массивах и хэш-таблицах, выясним их различия и решим несколько алгоритмических проблем с каждым компонентом.
Что такое структура данных?
Структура данных — это набор значений, которыми можно манипулировать только с помощью алгоритмов. Можно сравнить структуру данных с чемоданом или шкафом, где хранят одежду. Каждый предмет одежды представляет определенную ценность. Можно также провести аналогию со школьной сумкой, в которой хранятся учебники. Каждая структура данных, подобно шкафу, чемодану или школьной сумке, обладает особым способом управления своим содержимым.
Программисты имеют дело со множеством структур данных, предназначенных для решения конкретных задач. Мы можем хранить строки, числа, объекты, массивы и многое другое. Все организовано. Кроме того, можно сказать: структуры данных + алгоритмы = программы
Есть два важных вопроса, связанных со структурами данных: как их создавать и как использовать. Второй, пожалуй, более актуален, поскольку наиболее часто используемые структуры данных уже созданы.
Структуры данных бывают различного типа: линейные и нелинейные. По мере развития отрасли они усложняются, поэтому хорошему разработчику нужно приобрести больше понимания, а лучше фундаментальных знаний о структурах данных (СД).
Предлагаем углубиться в это понятие: рассмотреть массивы и хэш-таблицы.
Отметим только, что некоторые языки имеют определенные типы данных, которых нет в других языках. Если в JavaScript нет чего-то похожего на стек, нам придется его создать (или использовать стороннюю библиотеку).
Операции со структурами данных
Чтобы манипулировать сохраненными данными, необходимо выполнить с ними определенные операции. Каждая из этих операций является общепринятой и специфически настроенной. Рассмотрим некоторые из них:
- Обход (Traversing): получение доступа к каждому элементу данных в структуре ровно один раз и его обработка. Таким образом вы переходите прямо к элементу в СД.
- Вставка (Insertion): добавление другого элемента в СД. Вставка имеет определенное имя в зависимости от СД, например, в стеке —
push, в очереди —enqueue. - Удаление (Deletion): выведение элемента из СД. В стеке —
pop, в очереди —dequeue. - Поиск (Searching): обнаружение определенного элемента в СД, проверка его наличия или отсутствия. Это часто используемая операция.
- Доступ (Access): получение значения элемента, фактическое местоположение которого известно.
Массивы
Массивы представляют собой последовательность элементов, организованных и идентифицированных по их индексам. Это СД, содержащие несколько значений данных, которые визуализируются в полях. Чтобы массив считался правильным, все его значения должны быть одного типа: либо целыми числами, либо символами, либо чем-либо еще, но только не смешанными.
Простейшей формой массива является одномерный массив. Бывают также многомерные массивы. Одной из главных причин растущей популярности массивов является доступность индексов во время выполнения. Именно это позволяет осуществлять итерацию или указывать интерактивный оператор для многих значений в массиве.
Рассмотрим примеры использования массивов в качестве СД, а также некоторые методы и операции, производимые с ними:
const names = ['Victor', 'Alex', 'Polya', 'Ugochi'];
// Добавление в массив выше
names.push('John')
// [ 'Victor', 'Alex', 'Polya', 'Ugochi', 'John' ]
// Удаление из массива выше
names.pop()
// [ 'Victor', 'Alex', 'Polya', 'Ugochi' ]
// Добавление элемента в первый индекс массива выше
names.unshift('Lawrence')
//[ 'Lawrence', 'Victor', 'Alex', 'Polya', 'Ugochi' ]
// Добавление элемента после второго индекса массива
names.splice(1, 0, 'Jonah')
// [ 'Lawrence', 'Jonah', 'Victor', 'Alex', 'Polya', 'Ugochi' ]
console.log(names)Массивы делятся на две категории: статическую и динамическую. Рассмотрим каждую из них.
Статические массивы
Размер или длина массива этого типа определяется в процессе компиляции (до времени выполнения), когда вы указываете количество индексов, которые вам нужны в массиве. Этот тип массива применим только в языках низкого уровня, таких как C++:
int a[4];
int b[10] {1, 2, 3, 4, 5, 6, 7, 8, 9, 0}Если нужно добавить новое значение в массив, придется создать новый массив и заново указать его размер. Память уже определена в RAM. Считается, что одна из причин, по которой C++ работает быстрее, заключается в том, что он просто не создает неиспользуемую память.
Динамические массивы
Динамические массивы расширяются по мере добавления в них дополнительных значений. Не нужно определять длину массива: он уже изменяет свой размер, удваивая его при добавлении другого значения. Допустим, вы создали массив размером для 5 элементов. Он может измениться следующим образом:
- при добавлении 6-го пункта увеличится вдвое до 10;
- при добавлении 11-го пункта увеличится вдвое до 20.
Имейте в виду, что при каждом добавлении прежний массив удаляется, создается больший массив с перемещением в него всех элементов. Этот процесс занимает дополнительное время, и его повторение дает наихудший результат 0(n). Хотя тут нет ничего страшного, имейте это в виду.
Реализация
Выше мы упомянули о двух важных аспектах СД — как их создавать и как использовать. Теперь поговорим о них более подробно. Начнем с того, что вам стоит знать, как создать массив, даже если он является обычным и встроенным в СД большинства языков. Нужно же понимать, как это работает. Такой технический вопрос часто возникает на собеседовании.
Итак, приступим к созданию массива на JavaScript. Сначала создадим класс с конструктором, который будет содержать две переменные данных: длину массива и значения в самом массиве:
class CustomArray {
constructor() {
this.data = {},
this.length = 0;
}
// получение элемента массива с помощью индекса
access(index) {
return this.data[index]
}
}Первый метод в классе — метод доступа к элементу в массиве.
const newArray = new CustomArray()
console.log(newArray.access(0)) // не определенПоскольку в массиве нет элемента, вывод не определен.
Теперь создадим еще один важный метод, который добавит значение в массив. Он похож на append(присоединение) или, точнее, на метод push:
class CustomArray {
constructor() {
this.data = {},
this.length = 0;
}
// получение элемента массива с помощью индекса
access(index) {
return this.data[index];
}
// добавление элементов в массив
push(value) {
this.data[this.length] = value;
this.length++;
return this.length;
}
}В этом методе push добавляемое значение присоединяется к текущей длине данных: если оно было length = 0, то добавляется в эту позицию. Следующая строка увеличивает длину, поэтому, если у нас есть другое значение для ввода, оно также добавляется в эту позицию.
Результат будет выглядеть так:
const newArray = new CustomArray()
newArray.push('first item');
newArray.push('second item');
newArray.push('third item');
console.log(newArray)
// CustomArray {
data: { '0': 'first item', '1': 'second item', '2': 'third item' },
length: 3
}Еще одна функциональность, которую нам нужно будет добавить, — это метод pop. Он удаляет последнее значение в массиве. Поэтому, если в массиве 6 элементов, последний элемент будет удален. Посмотрим, как это работает:
class CustomArray {
constructor() {
this.data = {},
this.length = 0;
}
// получение элемента массива с помощью индекса
access(index) {
return this.data[index];
}
// добавление элементов в массив
push(value) {
this.data[this.length] = value;
this.length++;
return this.length;
}
// удаление последнего элемента в массиве
pop() {
const lastValue = this.data[this.length - 1];
delete this.data[this.length - 1];
this.length--;
return lastValue;
}
}С помощью метода popмы находим последний элемент в массиве, удаляем его и уменьшаем длину на единицу.
Вот каким будет результат:
const newArray = new CustomArray()
newArray.push('first item');
newArray.push('second item');
newArray.push('third item');
newArray.pop();
console.log(newArray)
// CustomArray {
data: { '0': 'first item', '1': 'second item' },
length: 2
}При необходимости вы можете добавить свои методы. Я просто хотел показать, как строятся массивы с использованием некоторых методов.
Хэш-таблицы
Это моя любимая СД. Мне нравится воспринимать ее как ассоциативный массив, где элементы хранятся, но с этими элементами связан ключ. Ладно, скажу яснее. Хэш-таблица — это СД, где главным образом хранится информация, состоящая из двух компонентов: ключа и значения. Таким образом, ключ сопоставляется со значением.
Хэш-таблицы называются по-разному в разных языках: в Python — словарями, в Ruby — хэшами, а в Java — картами. Это одни из наиболее часто используемых СД в отрасли. Они используются не для хранения в основной базе данных, а для кэширования (что значительно ускоряет доступ к данным) и для индексации базы данных путем перебора базы данных таблицы, их анализа и обобщения и в результате приобретения вида ярлыка.
Существует также Map()— карта, представленная в 2015 году и рассматриваемая как хэш-карта. Подобно хэш-таблицам, хэш-карта обеспечивает функциональность ключа/значения, но есть небольшая разница. Хэш-карта позволяет использовать ключи любого типа данных, в отличие от хэш-таблиц, в которых ключи представлены только целыми числами и строками. Кроме того, хэш-карты не могут быть преобразованы в JSON.
Не забывайте, что хэш-таблицы и хэш-карта являются реализациями объектов в JavaScript.
Хэш-функция
Это функция, которая генерирует фиксированное значение длины для каждого ввода в нее. Возвращаемое значение принято называть хэш-значением. Проще говоря, хэш-функция вычисляет индекс в хэш-таблице, обычно принимающий свойство и значение объекта и помещающий его в хэш-функцию, которая решает, куда поместить его в памяти:
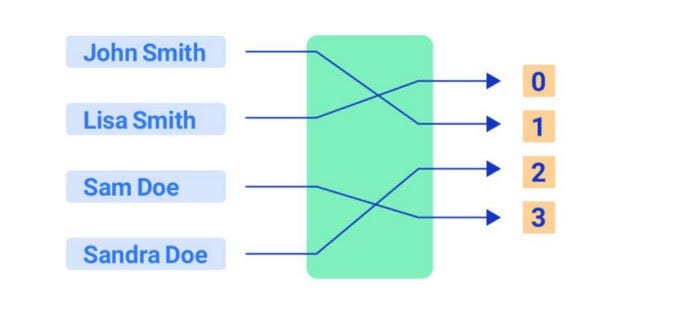
Хэш-столкновение
В большинстве случаев, хэш-функция, которая решает, где хранить свойство и значение объекта, назначает его одному и тому же слоту, что приводит к столкновению. Это проблема, потому что каждый слот в памяти должен хранить одно значение.
Как видно на изображении ниже, Джордж и Кори столкнулись с хэш-функцией и присвоили два значения одному индексу:
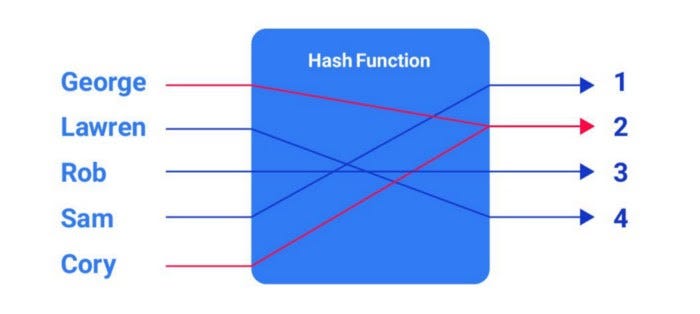
Реализация
Точно так же, как мы создавали собственный массив, будем создавать хэш-таблицу. Сначала создаем класс, где первым методом будет хэш-функция. Затем создаем массив в конструкторе, но без представления литерала. Применим конструктор Array с использованием размера в качестве параметра.
class HashTable {
constructor(size) {
this.data = new Array(size);
}
}Теперь создадим хэш-функцию, которая вернет хэш-значение. Это значение будет тем местом, где будут храниться наши данные. Мы собираемся использовать очень простую хэш-функцию, поскольку создание надежных функций — сложная тема криптографии. Мы же сосредоточимся на создании хэш-таблицы:
class HashTable {
constructor(size) {
this.data = new Array(size);
}
hashFunction(value) {
let hash = 0;
for (let i = 0; i < value.length; i++) {
hash = (hash + value.charCodeAt(i) * i) % this.data.length;
console.log(hash);
}
return hash;
}
}Назначение простой хэш-функции:
- прием значения;
- выполнение циклов через каждый символ;
- возвращение кода символа для каждого символа;
- умножение его на индекс;
- добавление его к исходному хэш-значению;
- использование оператора остатка для непревышения длины размера массива.
Запустив этот метод, получим такое значение:
const hashTable = new HashTable(4);
hashTable.hashFunction('Hey')
// 3Затем сосредоточимся на следующем методе, который является методом “установки”. Два его свойства: ключ и значение.
class HashTable {
constructor(size) {
this.table = new Array(size);
}
hashFunction(value) {
let hash = 0;
for (let i = 0; i < value.length; i++) {
hash = (hash + value.charCodeAt(i) * i) % this.table.length;
}
return hash;
}
// добавление элементов в хэш-таблицу
set(key, value) {
let memoryLocation = this.hashFunction(key);
if (!this.table[memoryLocation]) {
this.table[memoryLocation] = [];
}
this.table[memoryLocation].push([key, value]);
return this.table;
}
}Ключевое свойство используется для хэш-функции. Если место в памяти не существует, присвоим ему массив и поместим в него ключ и значение.
const hashTable = new HashTable(4);
hashTable.set('Victor', 24)
// [ <1 empty item>, [ [ 'Victor', 24 ] ], <2 empty items> ]Затем создадим метод, который вернет элемент, изначально помещенный нами в хэш-таблицу. Это проще, потому что можно использовать ключ для получения точного местоположения в памяти из хэш-функции. Взгляните на метод getItemниже:
class HashTable {
constructor(size) {
this.table = new Array(size);
}
hashFunction(value) {
let hash = 0;
for (let i = 0; i < value.length; i++) {
hash = (hash + value.charCodeAt(i) * i) % this.table.length;
}
return hash;
}
// добавление элементов в хэш-таблицу
set(key, value) {
let memoryLocation = this.hashFunction(key);
if (!this.table[memoryLocation]) {
this.table[memoryLocation] = [];
}
this.table[memoryLocation].push([key, value]);
return this.table;
}
// получение элементов для хэш-таблицы
getItems(key) {
let memoryLocation = this.hashFunction(key);
if (!this.table[memoryLocation]) return null;
return this.table[memoryLocation].find((x) => x[0] === key)[1];
}
}Требуется проверка ошибок, чтобы узнать, существует ли вообще эта ячейка памяти.
Это не идеальный пример, но он позволяет понять идею реализации.
Хэш-таблицы против массивов
Путем наблюдений мы выяснили различия между хэш-таблицами и массивами:
- хэш-таблицы, как правило, работают быстрее при поиске элементов; в массивах нужно перебрать все элементы, чтобы найти искомое, в то время как в хэш-таблице вы переходите непосредственно к местоположению элемента;
- вставка элемента выполняется быстрее в хэш-таблицах, так как вы просто хешируете ключ и вставляете его; в массивах важно сначала переместить элементы, прежде чем вставлять еще один.
На изображении ниже показана временная затратность всех операций:
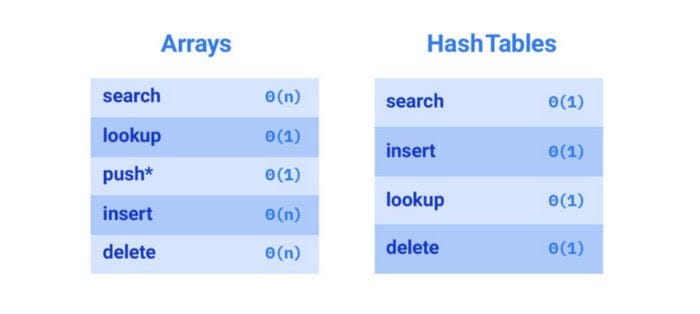
Стоит тщательно выбирать структуры данных для конкретных бизнес-задач, особенно для тех, которые потенциально могут снизить эффективность предлагаемого продукта. Сложность поиска O(n) для функциональности, которая выполняется в режиме реального времени и зависит от большого количества данных, может сделать продукт непригодным для внедрения. Даже если вы чувствуете, что были приняты правильные решения, всегда необходимо убедиться, что это действительно так, и ваши пользователи имеют большой опыт работы с вашим продуктом.
Такое решение, как SessionStack, позволит воспроизводить циклы взаимодействия с клиентами в формате видеороликов, показывающих, как ваши пользователи на самом деле воспринимают ваш продукт. Это даст возможность быстро определить, соответствует ли ваш продукт клиентским ожиданиям. Заметив что-то неладное, вы можете изучить все технические детали из браузера пользователя, такие как сеть, отладочную информацию и все, что касается среды, чтобы быстро понять проблему и решить ее.
Чтобы испытать SessionStack, воспользуйтесь бесплатной пробной версией.
Читайте также:
- 8 полезных на практике приёмов для веб-разработчиков
- Алгоритм JavaScript: Array.forEach()
- Эти JavaScript-методы всего за несколько минут прокачают ваши навыки
Читайте нас в Telegram, VK и Дзен
Перевод статьи Victor Jonah: How JavaScript works: Arrays vs Hash Tables





