
Было решено, что Apache Kafka не подходит RudderStack в качестве основного движка потоковой передачи/организации очередей. Вместо этого мы создали собственный потоковый движок поверх PostgreSQL. В этой статье подробно рассматриваются внутренние компоненты нашей реализации системы очередей.
Системы на основе очередей: введение
Основная концепция любой системы очередей тривиальна. Реализация CS101 берет за основу связанный список элементов. Система очередей добавляет элементы (или, в нашем случае, события) на один конец, потребляя их с другого, как показано на рисунке ниже. Как только система отработает событие, его можно удалить из списка.
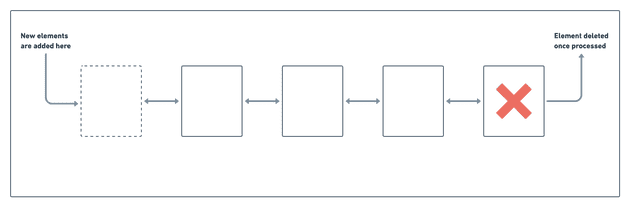
Однако для практического применения системы очередей, особенно в такой сложной системе, как RudderStack, она должна решать еще несколько задач.
Задача 1: постоянство
Во-первых, системе необходимо сохранять очередь на диске для обеспечения отказоустойчивости и обработки системных сбоев. К сожалению, минимальный объем единицы памяти в дисковой системе представлено блоком от 4 до 64 КБ.
Кроме того, зачастую по соображениям производительности желательно выполнять чтение и запись сразу из нескольких блоков, в том числе размером до нескольких МБ. Нецелесообразно хранить отдельные события на диске, как показано в базовой реализации CS101 в предыдущем разделе.
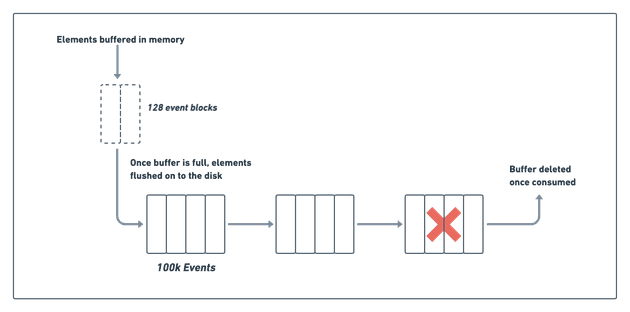
Эту проблему можно решить путем пакетной обработки событий в памяти и сброса всего пакета на диск. В нашем случае мы пакуем ориентировочно около 128 событий. Таков идеальный размер пакета — он обеспечивает хороший баланс между временем ввода/вывода и задержкой подтверждения клиента (ACK) в ходе тестирования. Подтверждение клиенту не уходит, если событие не сохранено на диске. Кроме того, нельзя допустить, чтобы клиенты слишком долго ждали подтверждения.
Со стороны потребителя нам под силу обрабатывать партии гораздо большего объема, чтобы избежать накладных расходов на выполнение небольших операций ввода-вывода. Для этого на диске создаются сегменты из ста тысяч событий, которые система обрабатывает вместе. Как только система обработает сегмент пакетов, его, как правило, можно удалить (см. диаграмму ниже):
Задача 2: Порядок обработки очередей
В примере CS101 события обрабатываются по порядку, начиная с верхней части очереди, что упрощает их удаление. Однако на практике события, возможно, придется обрабатывать не по порядку.
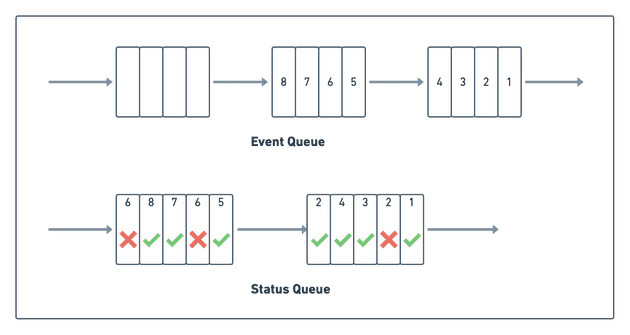
Например, если не удалось доставить событие, мы помечаем его как неудачное и блокируем дальнейшие события от пользователя. Тем временем начинают обрабатываться другие несвязанные события, присутствующие в очереди после этого неудачного события. Такой процесс может привести к сценарию (показанному на следующей диаграмме), в котором некоторые события уже были обработаны (отмечены зеленой галочкой), в то время как другие (отмечены красным крестом) по-прежнему ожидают обработки:
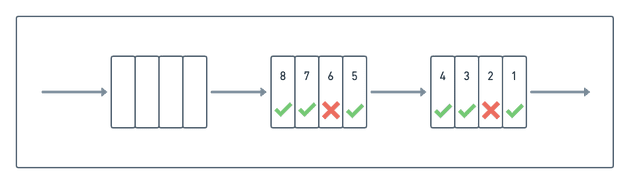
Эта динамика несогласованной поставки событий усложняет обновление рабочего пространства. Хотя перед удалением блока можно было бы подождать, пока все события в блоке не окажутся обработаны, это не идеальное решение. Одно необработанное событие может предотвратить обновление всего блока, что приведет к переполнению пространства.
Уплотнение
Мы решаем эту проблему, запуская то, что называем “уплотнением”, когда система сжимает несколько частично обработанных блоков в один.
В процессе уплотнения система удаляет уже обработанные события, сохраняя при этом необработанные. Как видно на диаграмме ниже, процесс объединил два ведущих частично обработанных блока в один:
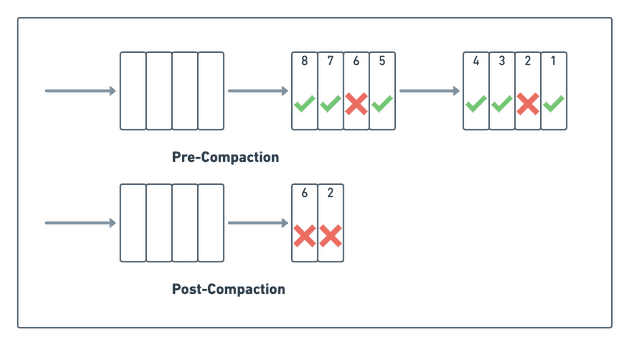
Запускать алгоритм уплотнения можно периодически или по событию-триггеру. Например, как только будет достаточно неуплотненных блоков или, как в нашем случае, когда мы запускаем уплотнение каждые 30 минут. Однако запуск происходит только в том случае, если в очереди есть по крайней мере два блока с не менее чем 80% обработанных задач. Такая логика гарантирует, что во время уплотнения получится освободить достаточно места. В то же время это гарантирует, что уплотнение не запустится слишком часто (так как сжатие замедляет работу системы).
В обычном устойчивом режиме все задания выполняются успешно, и операция уплотнения обрабатывает блоки, где нет ожидающих заданий, в то время как основные задания обработки занимаются необработанными блоками. В результате между заданием уплотнения и основным заданием обработки практически нет разногласий.
Задача 3: Обновление статуса “на месте” в очереди статусов
На приведенной выше диаграмме мы показали события, отмеченные как успешные или неудачные, по мере их обработки системой. К сожалению, обновление блоков “на месте” неэффективно из-за базовых принципов работы диска.
Это потребовало бы сначала считать блок с диска (выполнив случайный ввод-вывод), потом обновить его в памяти и синхронизировать обратно (выполнив еще один случайный ввод-вывод). Два случайных ввода-вывода в этом процессе могут занять от нескольких миллисекунд до сотен. Эти операции ввода-вывода станут узким местом в конвейере обработки событий с высокой пропускной способностью.
Решение — не обновлять статус события мгновенно, “на месте”, а сохранять его в отдельной очереди. По мере того как система обрабатывает события, она добавляет статус успеха/сбоя и другие метаданные события (например, идентификатор события, причину сбоя и т. д.) в отдельную очередь.
Важно отметить: система может обрабатывать событие несколько раз. Например, если событие в первый раз завершится неудачно, система повторит попытку, в результате чего в очереди появятся две отдельные записи.
Отмечание статуса приводит к последовательному вводу-выводу в очередь состояния, что на порядки быстрее, чем случайный ввод-вывод для обновления “на месте». Однако недостаток этого подхода в том, что для получения статуса задания и определения следующего, которое должна отработать система, необходимо получать доступ к двум отдельным блокам.
Однако на практике система будет обрабатывать текущие блоки (блок состояния и блок событий), а также кэшировать их в памяти, поэтому для этих операций не требуется дисковый ввод-вывод.
Заключение
Мы обсудили три основных принципа проектирования, лежащих в основе нашей реализации очереди через PostgreSQL. Каждый блок на схеме, показанной выше, хранится в PostgreSQL в виде отдельной таблицы. Таблицы/блоки пронумерованы как <queue_name>_job_1, <queue_name>_job_2 и т. д., где queue_name — уникальный идентификатор очереди. Внутри RudderStack сосуществует множество очередей.
Статусы хранятся в отдельных таблицах <queue_name>_job_status_1, <queue_name>_job_status_2 и т. д. После обработки определенной таблицы или последовательности таблиц они сжимаются в один блок (или ни в какой блок, если все задания выполнены успешно). Это уплотнение выполняется в отдельном потоке.
Запросы для поиска необработанных заданий в основном потоке также находят обработанные задания во время уплотнения, и все это реализовано на SQL. Интерфейс SQL также отлично подходит для отладки, проверки и обновления заданий. Например, иногда приходится принудительно повторять прерванные задания или наоборот, что в SQL очень легко.
Реализация этих концепций, безусловно, интересна, но мы дадим вам самостоятельно разобраться в реальном коде в репозитории GitHub.
Читайте также:
- Кэширование в связке Spring Boot + Redis + PostgreSQL
- Оптимизация работы баз данных с PostgreSQL 12
- SQL для Data Science: альтернатива обмену через Google Disk и Slack
Читайте нас в Telegram, VK и Дзен
Перевод статьи RudderStack: Kafka Vs. PostgreSQL: How We Implemented Our Queueing System Using PostgreSQL




