
Введение
Методы онлайнового обучения машин (ОО) — это семейство динамических алгоритмов обучения с подкреплением, которое стоит за кулисами многих достижений во всей области ИИ за последние десять лет. Методы ОО относятся к классу обучения на сэмплах из раздела методов с подкреплением. Они позволяют определять значения состояния благодаря простым повторяющимся наблюдениям.
Подходы ОО (в отличие от своих “офлайновых” братьев) позволяют по нарастающей обновлять значения состояний и поведения внутри, так называемых, пространственных эпизодов. Еще с ними удобно наблюдать за растущим постоянно уровнем производительности.
Эволюция в УВР (учёт временной разницы) привела к возрастающим оценкам и улучшению значений состояний и поведения. О Q-обучении узнали как о базе для подходов сферы обучения с подкреплением. Оно было нужно для симуляций игровых пространств, например, на таких платформах-“спортзалах”, как OpenAI Gym. Но в этой статье не будет обсуждения теоретических аспектов.
Способы ОО подходят высокодинамичным окружениям, где значения состояний и поведения постоянно обновляются во времени и в наборах оценок из-за быстрой ответной реакции внутри эпизодов (в том числе УВР). Возможно, самое важное то, что УВР — это основа Q-обучения, более продвинутого алгоритма для тренировки агентов, который имеет дело с игровыми окружениями, которые можно увидеть в OpenAI Atari Gym.
В этом материале изучим, как можно использовать Q-обучение для агента, который играет в классический шутер от первого лица вроде Doom. Будем делать это с помощью открытой библиотеки-враппера Vizdoomgym. Мы настроим вашего первого агента, а также заложим базу для дальнейшней работы.
Выходя за пределы УВР: SARSA и Q-обучение
В УВР поведение агента циклично в пространстве в последовательности состояний (State), действий (Action) и наград (Reward).
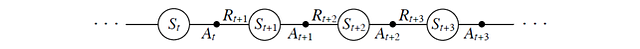
В процессе УВР мы можем обновить значение предыдущего состояния сразу же, как только достигаем следующей стадии. Дальше мы расширяем объем своей модели, чтобы в нее входили значения состояния-действия, согласно подходу SARSA (“состояние-действие-награда-состояние-действие”), регламентированному алгоритму управления УВР, который нужен для оценки значений поведения.
В процессе SARSA мы непрерывно оцениваем значения действий при инкрементальных временных шагах согласно текущей политике. Эта информация нужна, чтобы изменить правила по отношению к жадному алгоритму со значениями действий.
Давайте сравним уравнения обновлений состояния-действия и состояния-значения УВР:
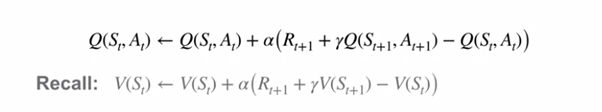
Q-обучение отличается от SARSA принудительным выбором действия с текущим максимальным значением в процессе обновления. Так же происходит и в похожем подходе, который наблюдается в уравнениях оптимальности Беллмана.
Изучим алгоритм SANSA и Q-обучение на фоне метода Беллмана и его уравнений оптимальности:

Любопытно, как обеспечивается полное исследование пространства состояний-действий, из-за чего нужно постоянно выбирать действия (с максимальным из существующих значений действий) для состояния. Теоретически мы можем игнорировать оптимальные действия, просто не проводя их оценку в первую очередь.
Чтобы продолжить обучение, мы можем следовать политике эпсилон-жадного затухающего алгоритма. Они по сути принуждают агента выбирать очевидное неоптимальное действие по вероятности затухания, чтобы лучше изучить его значение. С затухающим значением мы можем ограничить изучение, когда оценим все состояния. А после этого мы постоянно будем выбирать оптимальные действия для каждого состояния.
Теория закончилась, переходим к реализации.
Реализация
Наша реализация в Colaboratory от Google написана на Python с помощью Tensorflow. Ее можно найти на GradientCrescent Github.
Реализация с таким подходом достаточно непростая, поэтому давайте обобщим порядок необходимых действий:
1. Мы определяем нашу нейросеть глубокого Q-обучения. Это РНС, которая делает скриншоты во время игры и выводит вероятности для каждого из действий или Q-значений в игровом пространстве Ms-Pacman. Чтобы получить тензор вероятностей, нам не нужно добавлять никакой функции активации в финальный слой.
2. Так как для Q-обучения мы должны знать и текущие, и следующие состояния, нам стоит начать с генерации данных. Мы “скармливаем” предварительно обработанные входные изображения игровому пространству, предоставляем исходные состояния s нашей нейронной сети и получаем исходную вероятность распределения действий или Q-значений. До тренировки эти значения будут появляться случайно и неоптимально.
3. С тензором вероятностей мы готовы выбрать действие с текущей высшей вероятностью при помощи функции argmax() и использовать ее для создания правил эпсилон-жадного алгоритма.
4. Используя наши правила мы выбираем действие a, и оцениваем наше решение в окружении gym — чтобы получить информацию по новому состоянию s’ , награде r и информацию о том, закончился ли эпизод.
5. Мы сохраняем это сочетание информации в буфер в формате списка <s,a,r,s’,d> и повторяем шаги 2–4 для пресета с числами в промежутке времени, чтобы создать достаточно большой буферный датасет.
6. Как будет закончен 5-й шаг, двигаемся к генерации целевых y-значений, R’ и A’. Они нужны для расчета ошибки. Предыдущее — это просто уменьшенное значение R. Амы получаем A`, передавая S` в сеть.
7. У нас есть все компоненты пространства и мы готовы рассчитать ошибку для тренировки сети.
8. По окончании тренировки мы оцениваем производительность нашего агента в новом игровом эпизоде и записываем её.
Приступим-с. Вместе с Tensorflow 2 и окружениями из Colaboratory мы конвертировали код в совместимый с TF2 формат. Нам помог новый пакет compat.
Помните, что этот код не является нативным для TF2.
Импортируем все пакеты, без которых не обойтись, в том числе окружения OpenAI и Vizdoomgym, а также Tensorflow:
import gym
import vizdoomgym
!pip install tensorflow==1.15
import numpy as np
import tensorflow as tf
from tensorflow.contrib.layers import flatten, conv2d, fully_connected
from collections import deque, Counter
import random
from datetime import datetimeОпределяем функцию предварительной обработки для нормализации и изменения наблюдений из нашего окружения gym, конвертируем их в одномерные тензоры:
from skimage.color import rgb2gray
from skimage import transform
#предварительно обработаем uint8-фрейм (240, 320, 3) в плавающий одномерный вектор 30x40
color = np.array([240, 320, 74]).mean()
def preprocess_observation(obs):
img =obs/255.0
img[img==color] = 0
img_gray = rgb2gray(img)
preprocessed_frame = transform.resize(img_gray, [60,80])
return preprocessed_frame
Инициализируем окружение gym. Будем пользоваться сценарием получения здоровья Vizdoomgym. Его цель — собрать максимально возможное количество коробок здоровья, чтобы остаться в живых, пока он перемещается в квадратной комнате с опасной кислотой на полу.
env = gym.make(‘VizdoomHealthGathering-v0’)
n_outputs = env.action_space.n
print(n_outputs)
observation = env.reset()
import tensorflow as tf
import matplotlib.pyplot as plt
for i in range(22):
if i > 20:
print(observation.shape)
plt.imshow(observation)
plt.show()
observation, _, _, _ = env.step(1)Мы можем изучить скрин геймплея и просмотреть три доступных действия внутри игрового пространства, а именно: поворот налево, направо и движение вперёд. Конечно, эта информация недоступна нашему агенту.
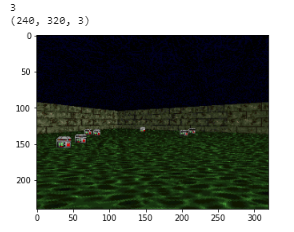
Воспользуемся этим шансом для сравнения нашего оригинала и предварительно обработанных вводных изображений:
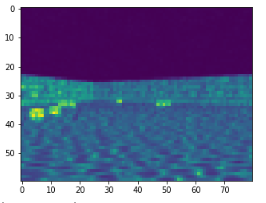
Теперь нам понадобится компоновка исходного фрейма в стек и композиция фрейма в конвейер предварительной обработки. Эти две техники появились в 2015 году благодаря Deepmind. Они нужны, чтобы давать временные и поведенческие ориентиры для вводных данных.
Применяем компоновку фрейма так: берём два исходных фрейма и возвращаем сумму поэлементных максимумов maxframe от них двух. Затем эти скомпонованные фреймы сохраняются в двухсторонней очереди или стеке, который автоматически убирает устаревшие записи с появлением новых.
stack_size = 4 # Всего в стеке 4 скомпонованных фрейма
stacked_frames = deque([np.zeros((60,80), dtype=np.int) for i in range(stack_size)], maxlen=4)
def stack_frames(stacked_frames, state, is_new_episode):
# Предварительная обработка фрейма
frame = preprocess_observation(state)
if is_new_episode:
# Очистка фреймов из стека stacked_frames
stacked_frames = deque([np.zeros((60,80), dtype=np.int) for i in range(stack_size)], maxlen=4)
# Так как мы в новом эпизоде, копируем тот же фрейм 4 раза, применяем поэлементный максимум
maxframe = np.maximum(frame,frame)
stacked_frames.append(maxframe)
stacked_frames.append(maxframe)
stacked_frames.append(maxframe)
stacked_frames.append(maxframe)
# Помещаем фреймы в стек
stacked_state = np.stack(stacked_frames, axis=2)
else:
#Так как двусторонняя очередь добавляет t справа, то мы можем получить самый крайний элемент справа
maxframe=np.maximum(stacked_frames[-1],frame)
# Добавляем фрейм в двустороннюю очередь, автоматически удаляется самый старый фрейм
stacked_frames.append(maxframe)
# Создаем состояние стека (первое измерение определяет разные фреймы)
stacked_state = np.stack(stacked_frames, axis=2)
return stacked_state, stacked_framesДавайте определим нашу модель глубокой Q-нейросети. По сути это трёхслойная свёрточная нейросеть, которая получает на вход предварительно обработанные наблюдения вместе со сгенерированным плоским выводом, скормленным полносвязному слою, а в результате генерирует вероятность каждого действия в игровом пространстве.
Заметьте, что здесь нет слоев активации, иначе на выходе бы было бы бинарное распределение.
tf.compat.v1.reset_default_graph()
def q_network(X, name_scope):
# Инициализируем слои
initializer = tf.compat.v1.keras.initializers.VarianceScaling(scale=2.0)
with tf.compat.v1.variable_scope(name_scope) as scope:
# Инициализация сверточного слоя
layer_1 = conv2d(X, num_outputs=32, kernel_size=(8,8), stride=4, padding=’SAME’, weights_initializer=initializer)
tf.compat.v1.summary.histogram(‘layer_1’,layer_1)
layer_2 = conv2d(layer_1, num_outputs=64, kernel_size=(4,4), stride=2, padding=’SAME’, weights_initializer=initializer)
tf.compat.v1.summary.histogram(‘layer_2’,layer_2)
layer_3 = conv2d(layer_2, num_outputs=64, kernel_size=(3,3), stride=1, padding=’SAME’, weights_initializer=initializer)
tf.compat.v1.summary.histogram(‘layer_3’,layer_3)
# Уплощенный результат слоя_3 до передачи данных полносвязному слою
flat = flatten(layer_3)
# Вставить полносвязный слой
fc = fully_connected(flat, num_outputs=128, weights_initializer=initializer)
tf.compat.v1.summary.histogram(‘fc’,fc)
# Добавить результирующий слой
output = fully_connected(fc, num_outputs=n_outputs, activation_fn=None, weights_initializer=initializer)
tf.compat.v1.summary.histogram(‘output’,output)
# Переменные будут хранить параметры сети, например, веса
vars = {v.name[len(scope.name):]: v for v in tf.compat.v1.get_collection(key=tf.compat.v1.GraphKeys.TRAINABLE_VARIABLES, scope=scope.name)}
# Возвращаем вместе переменные и результаты
return vars, outputТеперь давайте определим гиперпараметры нашей модели и тренировочного процесса. Обратите внимание, что X_shape (None, 60, 80, 4) сейчас находится в расчете нашего стека с фреймами.
num_episodes = 1000
batch_size = 48
input_shape = (None, 60, 80, 1)
learning_rate = 0.002
# Изменяется для собранных в стек фреймов
X_shape = (None, 60, 80, 4)
discount_factor = 0.99
global_step = 0
copy_steps = 100
steps_train = 4
start_steps = 2000Вспомните, что Q-обучение требует, чтобы мы выбирали действия с самыми высокими значениями. Чтобы убедиться в том, что мы всё ещё смотрим каждую отдельную возможную комбинацию состояний-действий, мы сделаем так, чтобы наш агент следовал многослойным правилам эпсилон-жадной стратегии с долей обучения в 5%.
epsilon = 0.5
eps_min = 0.05
eps_max = 1.0
eps_decay_steps = 500000
def epsilon_greedy(action, step):
p = np.random.random(1).squeeze() #Одномерные записи возвращаются при помощи squeeze
epsilon = max(eps_min, eps_max — (eps_max-eps_min) * step/eps_decay_steps) #Разделение на большее количество шагов
if p< epsilon:
return np.random.randint(n_outputs)
else:
return actionВспоминаем из уравнений выше, что обновление функции для Q-обучения требуют следующего:
- текущее состояние s;
- текущее действие a;
- награда за текущее действие r;
- следующее состояние s’;
- следующее действие a’.
Чтобы поддерживать эти параметры на значимом уровне, нам нужно оценить свои текущие правила для набора параметров и сохранить все переменные в буфер. А уже оттуда во время тренировки мы будем визуализировать данные небольшими партиями.
Давайте теперь создадим буфер с простой функцией сэмплирования:
buffer_len = 20000
exp_buffer = deque(maxlen=buffer_len)
def sample_memories(batch_size):
perm_batch = np.random.permutation(len(exp_buffer))[:batch_size]
mem = np.array(exp_buffer)[perm_batch]
return mem[:,0], mem[:,1], mem[:,2], mem[:,3], mem[:,4]Дальше копируем параметры веса нашей исходной сети в итоговую сеть. Подход с двумя сетями позволяет генерировать данные во время тренировки при помощи существующих правил в процессе, в то время как параметры оптимизируются для итерации с новыми правилами, уменьшая колебания ошибки.
# строим сеть Q, которая принимает на входе X и генерирует Q-значения для всех действий внутри состояния
mainQ, mainQ_outputs = q_network(X, ‘mainQ’)
# чтобы оценить правила, мы создаём итоговую сеть Q похожим образом
targetQ, targetQ_outputs = q_network(X, ‘targetQ’)
copy_op = [tf.compat.v1.assign(main_name, targetQ[var_name]) for var_name, main_name in mainQ.items()]
copy_target_to_main = tf.group(*copy_op)В конце мы также определим ошибку. Это всего-навсего квадратная разница целевого (с наивысшим значением действия) и предсказанного действий. Мы будем использовать оптимизатор ADAM (адаптивная оценка момента), чтобы минимизировать ошибку в процессе тренировки:
# определяем плейсхолдер для нашего вывода, например, действия
y = tf.compat.v1.placeholder(tf.float32, shape=(None,1))
# вычисляем значение ошибки - разницу между текущим и предсказанным значениями
loss = tf.reduce_mean(input_tensor=tf.square(y — Q_action))
# для оптимизации ошибки пользуемся оптимизатором adam optimizer
optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
init = tf.compat.v1.global_variables_initializer()
loss_summary = tf.compat.v1.summary.scalar(‘LOSS’, loss)
merge_summary = tf.compat.v1.summary.merge_all()
file_writer = tf.compat.v1.summary.FileWriter(logdir, tf.compat.v1.get_default_graph())Давайте же запустим нашу нейросеть и пройдем тренировку. Мы определили большую часть его в первоначальных итогах, но давайте вспомним для потомков.
- На каждом этапе мы передаём стек изображений в виде вводных данных внутрь нашей сети, чтобы генерировать вероятностное распределение доступных действий. Распределения генерируются до применения правил эпсилон-жадного к следующему действию.
- Дальше мы вводим всё это в сеть и получаем информацию о следующем состоянии и сопутствующих наградах, сохраняя её в буфер. Обновляем стек и повторяем процесс столько раз, сколько шагов предопределено.
- Когда буфер станет достаточно большим, мы отдаём следующие состояния в нашу сеть, чтобы получить следующее действие, и рассчитываем следующую награду, уменьшая текущую.
- Мы генерируем итоговые Y-значения в процессе работы функции обновления Q-обучения и тренируем сеть.
- Чтобы вывести улучшенные значения состояния-поведения для следующего правила, мы обновляем весовые параметры сети, уменьшая ошибки тренировки.
with tf.compat.v1.Session() as sess:
init.run()
# для каждого эпизода
history = []
for i in range(num_episodes):
done = False
obs = env.reset()
epoch = 0
episodic_reward = 0
actions_counter = Counter()
episodic_loss = []
# первый шаг, предварительная обработка и стек инициализации
obs,stacked_frames= stack_frames(stacked_frames,obs,True)
# пока состояние не переходное
while not done:
# генерируем данные с нетренированной сетью
# отдаем игровой экран и получаем значения Q для каждого действия
actions = mainQ_outputs.eval(feed_dict={X:[obs], in_training_mode:False})
# получаем действие
action = np.argmax(actions, axis=-1)
actions_counter[str(action)] += 1
# выбираем действие по стратегии эпсилон-жадной
action = epsilon_greedy(action, global_step)
# выполняем действие и переходим в следующее состояние next_obs, получаем награду
next_obs, reward, done, _ = env.step(action)
#в новом эпизоде обновлен стек фреймов
next_obs, stacked_frames = stack_frames(stacked_frames, next_obs, False)
# сохраняем этот переход как опыт в буфере повтора
exp_buffer.append([obs, action, next_obs, reward, done])
#После определенных шагов тренируем нашу сеть Q с примерами из буфера повтора опыта
if global_step % steps_train == 0 and global_step > start_steps:
o_obs, o_act, o_next_obs, o_rew, o_done = sample_memories(batch_size)
# состояния
o_obs = [x for x in o_obs]
# следующие состояния
o_next_obs = [x for x in o_next_obs]
# следующие действия
next_act = mainQ_outputs.eval(feed_dict={X:o_next_obs, in_training_mode:False})
# уменьшенная награда: значения Y
y_batch = o_rew + discount_factor * np.max(next_act, axis=-1) * (1-o_done)
# собираем все итоги и записываем их в файл
mrg_summary = merge_summary.eval(feed_dict={X:o_obs, y:np.expand_dims(y_batch, axis=-1), X_action:o_act, in_training_mode:False})
file_writer.add_summary(mrg_summary, global_step)
# выполняем ранее определенные функции, о которых мы говорили при передаче данных на вход для расчета ошибки.
train_loss, _ = sess.run([loss, training_op], feed_dict={X:o_obs, y:np.expand_dims(y_batch, axis=-1), X_action:o_act, in_training_mode:True})
episodic_loss.append(train_loss)
# после некоторого интервала мы копируем веса нашей главной сети Q в итоговую Q-сеть
if (global_step+1) % copy_steps == 0 and global_step > start_steps:
copy_target_to_main.run()
obs = next_obs
epoch += 1
global_step += 1
episodic_reward += reward
next_obs=np.zeros(obs.shape)
exp_buffer.append([obs, action, next_obs, reward, done])
obs= env.reset()
obs,stacked_frames= stack_frames(stacked_frames,obs,True)
history.append(episodic_reward)
print(‘Epochs per episode:’, epoch, ‘Episode Reward:’, episodic_reward,”Episode number:”, len(history))Когда обучение завершается, мы можем вывести распределение наград и инкрементальные эпизоды. Ниже показываю первую тысячу эпизодов:
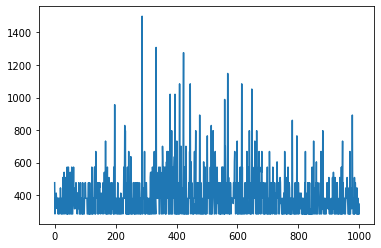
Результат принимается с видимыми зачатками улучшения, данными в таком виде, который предлагает оригинальная документация Vizdoom. Для более значительного улучшения понадобятся сотни тысяч эпизодов.
img_array=[]
with tf.compat.v1.Session() as sess:
init.run()
observation, stacked_frames = stack_frames(stacked_frames, observation, True)
while True:
# передаем экран игры и получаем значения Q для каждого действия
actions = mainQ_outputs.eval(feed_dict={X:[observation], in_training_mode:False})
# получаем действие
action = np.argmax(actions, axis=-1)
actions_counter[str(action)] += 1
# выбираем действие согласно эпсилон-жадному правилу
select the action using epsilon greedy policy
action = epsilon_greedy(action, global_step)
environment.render()
new_observation, stacked_frames = stack_frames(stacked_frames, new_observation, False)
observation = new_observation
# теперь выполняем действие и переходим в следующее состояние next_obs, получаем награду
new_observation, reward, done, _ = environment.step(action)
img_array.append(new_observation)
if done:
#наблюдение = env.reset()
break
environment.close()
Наконец, мы можем взять наш список фреймов и “скормить” их библиотеке skvideo.io — сгенерируем выходную видео-последовательность для изучения:
from random import choice
import cv2
from google.colab.patches import cv2_imshow
import numpy as np
import skvideo.io
out_video = np.empty([len(img_array), 240, 320, 3], dtype = np.uint8)
out_video = out_video.astype(np.uint8)
for i in range(len(img_array)):
frame = img_array[i]
out_video[i] = frame
# Записываем выходные последовательности изображений в видео-файл
skvideo.io.vwrite(“/content/doom.mp4”, out_video)Посмотрим на нашего агента в действии!
Обратите внимание, как агент приостанавливается, когда замечает ящик здоровья прямо перед тем, как начинает двигаться к нему. Ну и просто веселья ради мы натренировали агента по базовому сценарию, где цель — поразить монстра как можно скорее. Лучшее время пока что: около 1,3 секунды, показываем его ниже на одном из более ранних эпизодов.
Такая вот упаковка имплементации Q-обучения.
Надеюсь, вам понравилось читать и вы захотите погрузиться в теоретические аспекты применения ИИ.
Читайте также:
- Глубокие свёрточные нейросети: руководство для начинающих
- Что такое тензор?
- Лучшие фреймворки для ИИ и машинного обучения в веб-разработке
Перевод статьи Adrian Yijie Xu: Learning: An Implementation in Tensorflow.





