
Как превратить Jupyter Notebook в рабочий процесс по обработке данных
1. Введение
Jupyter Notebook — это «золотой стандарт» в разведочном анализе данных (EDA-анализ) и отличный инструмент для документирования data science проектов. В основном аналитики работают в блокнотах итерационно, а не идут сверху вниз по ячейкам. Несмотря на это, в Jupyter Notebook можно воспроизвести пошаговый анализ данных, запуская ячейки с первой по последнюю.
Единственная проблема Jupyter Notebook при выполнении повторяющихся задач и ETL‑операций, — это скудная автоматизация и отсутствие функций логирования. То есть вам нужно каждый раз открывать нужный блокнот и запускать его вручную. Кроме того, в процессе выполнения ячейки вы не можете отслеживать возможные ошибки и исключения.
1.1. Знакомство с Papermill
Papermill — это инструмент для параметризации и запуска блокнотов. Он превращает Jupyter Notebook в своего рода рабочий процесс, способный последовательно выполнять каждую ячейку без открытия JupyterLab (или Notebook). Пробелы по части логирования и автоматизации Papermill с лихвой восполняет запуском блокнотов в виде файлов и созданием отчетов для каждого выполнения.
ЦЕЛЬЮ данной статьи является интеграция Papermill и Jupyter Notebook для создания рабочего процесса обработки данных. Для наглядности мы создадим Python Notebook. В этом блокноте мы проведем простой анализ данных по метеопрогнозу через API (PyOWM), выполним первичную обработку данных, создадим несколько визуализаций и сформируем итоговый отчет.
Jupyter Notebook и другие необходимые файлы можно найти в репозитории проекта на GitHub. Если вы хотите повторить все сами, то установите библиотеки из papermill_env.yaml.
2. Настройка среды разработки
2.1. Установка Papermill и JupyterLab
Для начала создадим среду разработки в Conda (1, 2) и установим JupyterLab со всеми нужными библиотеками (3).
# 1) Создадим conda среду
conda create -n papermill python=3.7
# 2) Активируем ее
conda activate papermill
# 3) Установим библиотеки через pip (или conda)
pip install papermill pyowm jupyterlab pandas seaborn boto3 pdfkit
После установки Papermill мы видим подробную информацию в терминале (4).
# 4) Документация по Papermill
papermill -h
Использование: papermill [OPTIONS] NOTEBOOK_PATH OUTPUT_PATH.
Эта утилита выполняет по одному блокноту в подпроцессе. Papermill берет исходный блокнот, применяет к нему параметры, выполняет (4) блокнот с указанным ядром и сохраняет результат в конечном блокноте.
NOTEBOOK_PATH и OUTPUT_PATH теперь можно заменить на `-` (представление stdout и stderr) или input/output между вертикальными слешами. То есть
`<generate input>... | papermill | ...<process output>`
с `papermill - -`, заключенной в вертикальные слеши, прочитает блокнот из stdin и запишет его в stdout.
Опции:
-p, --parameters TEXT... — Параметры для передачи в ячейку параметров.
-r, --parameters_raw TEXT... — Параметры для чтения в виде неотформатированной строки.
-f, --parameters_file TEXT — Путь к YAML-файлу с параметрами
-y, --parameters_yaml TEXT — YAML-строка для использования в качестве параметров.
-b, --parameters_base64 TEXT — YAML-строка в кодировке Base64 для использования в качестве параметров.
--inject-input-path — Добавляет путь к входному блокноту PAPERMILL_INPUT_PATH в качестве параметра блокнота.
--inject-output-path — Добавляет путь к блокноту вывода PAPERMILL_OUTPUT_PATH в качестве параметра блокнота.
--inject-paths — Добавляет пути к входному/выходному блокноту PAPERMILL_INPUT_PATH/PAPERMILL_OUTPUT_PATH в качестве параметров блокнота
--engine TEXT — Название механизма выполнения, используемого при анализе блокнота.
--request-save-on-cell-execute / --no-request-save-on-cell-execute
— Запрос на сохранение блокнота после выполнения каждой ячейки
--prepare-only / --prepare-execute — Флажок для вывода блокнота без выполнения, но с применением параметров
-k, --kernel TEXT — Название ядра для запуска
--cwd TEXT — Рабочая директория для запуска блокнота
--progress-bar / --no-progress-bar — Флажок для включения индикатора выполнения
--log-output / --no-log-output — Флажок для записи результата блокнота в настроенный журнал
--stdout-file FILENAME — Файл для записи результата stdout
--stderr-file FILENAME — Файл для записи результата stderr
--log-level [NOTSET|DEBUG|INFO|WARNING|ERROR|CRITICAL] — Установка уровня записи
--start_timeout INTEGER — Время (сек.) ожидания запуска ядра
--report-mode / --no-report-mode — Флажок для скрытия входных данных.
--version — Флажок для отображения версии
-h, --help — Показать это сообщение и выйтиСудя по документации, в основных функциях Papermill ничего сложного нет. Мы просто указываем путь к нужному Jupyter Notebook и задаем имя для блокнота вывода (он выполняет функцию журнала). К ряду других полезных опций мы вернемся позже.
2.2. Установка Jupyter Kernel
Несмотря на то, что Jupyter Notebook чаще всего ассоциируется с запуском на Python, он работает практически под любым языком программирования при установке нужного ядра. Papermill в сочетании с подходящим ядром позволяет запускать блокноты в различных средах, избегая проблем с отсутствующими библиотеками (5).
# 5) Установка ядра Jupyter для среды Papermill
pip install ipykernelipython kernel install --user --name=papermill-tutorial
3. Создание рабочего процесса
Мы воспользуемся Jupyter Notebook для анализа метеорологических данных. Суть вот в чем: мы извлечем данные по определенному городу через PyOWM (Python API), выполним первичную обработку данных, создадим графики и представим структурированную информацию в PDF-отчете.
3.1. Работа с метеорологическим PyOWM API
Как говорится на главной странице библиотеки, PyOWM — это клиентская обертка Python-библиотеки для Web API OpenWeatherMap. Она упрощает доступ к метеорологическим данным, предлагая «простую объектную модель». Единственное требование к использованию данной библиотеки — API-ключ, который можно бесплатно получить на OpenWeather.
3.2. Рабочий процесс. Часть 1: получение метеоданных через PyOWM API
В первой части рабочего процесса мы используем библиотеку PyOWM для получения информации об уже заданном городе city (в исходном блокноте — это Сан-Паулу, Бразилия). Мы перебираем объект forecast и структурируем возвращаемую информацию в DataFrame, чем существенно облегчаем себе жизнь в дальнейшем.
1. Доступ к pyown API
На первом этапе анализа мы получаем метеоданные по выбранному городу через pyown API.
Эта информация структурируется в словаре, а затем загружается в виде DataFrame Pandas для выполнения первичной обработки.
[1] #импорт библиотек
import pyowm
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import pdfkit1.1. Установка API-ключа PyOWM и определение переменных
Здесь мы определяем API-ключ для доступа к сервису OpenWeather, а также ячейку с параметром city , которая прописывается в Papermill.
In [2] # Установка API-ключа:
owm = pyowm.OWM('xxxxxxxxxxxPyOWM-API-keyxxxxxxxx')
In [3] # Определение параметров по умолчанию:
city = ‘Sao Paulo,BR’
1.2. Получение метеоданных по определенному городу
На данном этапе мы используем PyOWM для получения данных о городе и структурирования их сначала в словаре, а затем в DataFrame.
In [4] # Инстанцирование объекта forecast и получение метеоданных о городе:
fc = owm.three_hours_forecast(city)
forecast = fc.get_forecast()
In [5] # Создание словаря для структурирования метеоданных по выбранному городу:
dict_forecast = {
‘datetime’:[],
‘clouds’:[],
‘humidity’:[],
‘temp’:[],
‘temp_max’:[],
‘temp_min’:[],
‘detailed_status’:[],
‘icon_url’:[],
‘rain_vol’:[]
}In [6] # Перебор объекта forecast для доступа к метеорологическим характеристикам (опциям):
for weather in forecast:
dict_forecast['datetime'].append(str(weather.get_reference_time(timeformat='iso')))
dict_forecast['clouds'].append(weather.get_clouds()) dict_forecast['humidity'].append(weather.get_humidity())
dict_forecast['temp'].append(weather.get_temperature(unit='celsius').get('temp'))
dict_forecast['temp_max'].append(weather.get_temperature(unit='celsius').get('temp_max'))
dict_forecast['temp_min'].append(weather.get_temperature(unit='celsius').get('temp_min'))
dict_forecast['detailed_status'].append(weather.get_detailed_status())
dict_forecast['icon_url'].append(weather.get_weather_icon_url())
if '3h' in weather.get_rain().keys():
dict_forecast['rain_vol'].append(weather.get_rain().get('3h'))
else:
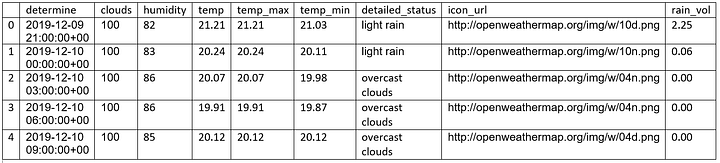
dict_forecast['rain_vol'].append(0)In [7] # Создание Dataframe из словаря:
df = pd.DataFrame.from_dict(dict_forecast)
df.head()
Out [7]
3.3. Рабочий процесс. Часть 2: получение метеоданных через PyOWM API
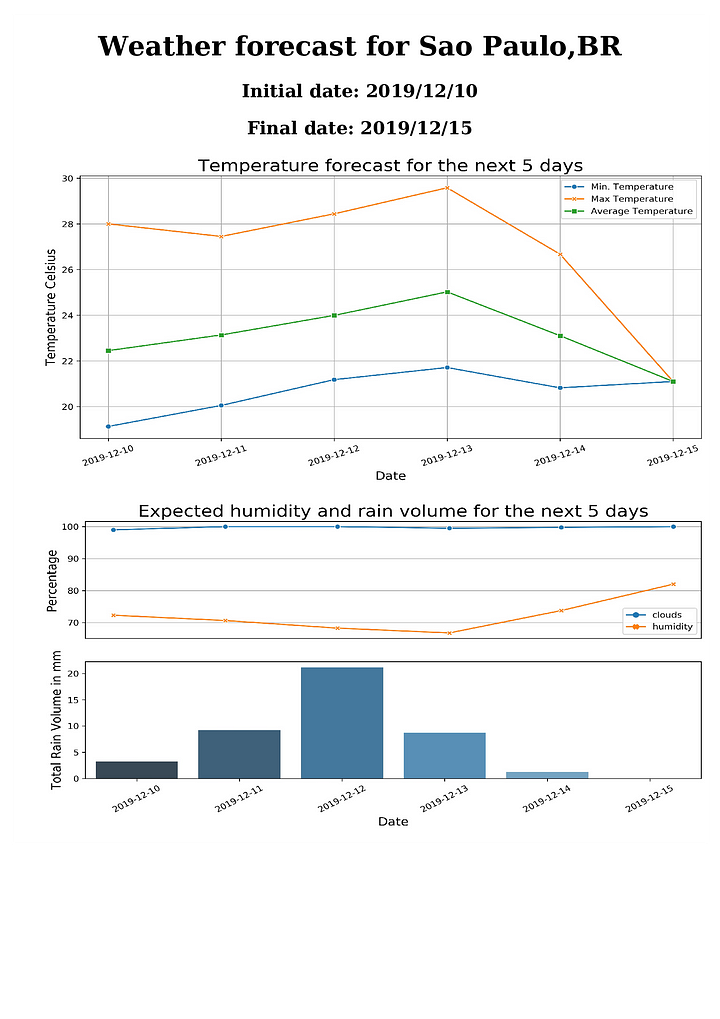
Во второй части рабочего процесса мы объединяем данные по дням, а затем визуализируем информацию на двух графиках. Первый график показывает температурные данные, а второй — осадки, облачность и влажность.
2. Создание визуализации
На этом этапе мы будем создавать графики из структурированных данных через seaborn.
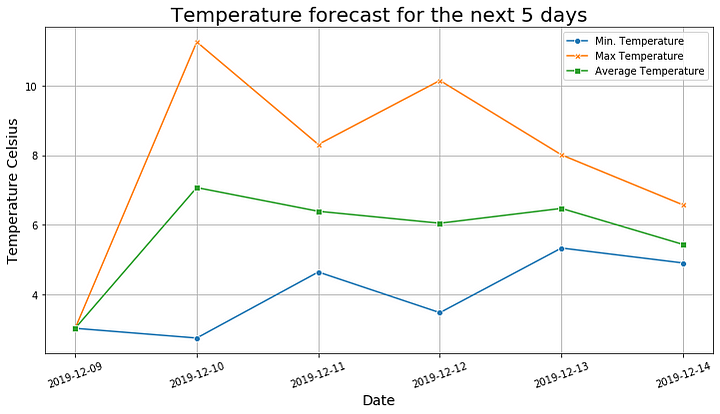
2.1. Температурный график
График показывает метеопрогноз с максимальной, минимальной и средней температурой на ближайшие 5 дней.
In [14] # Создание графика температур на ближайшие 5 дней
fig = plt.figure()
sns_plot = sns.lineplot(data=df_temp, style="event",markers=True, dashes=False)
sns_plot.set_title(f'Temperature forecast for the next 5 days', fontsize=20)
sns_plot.set_xlabel('Date', fontsize=14)
sns_plot.set_ylabel('Temperature Celsius', fontsize=14)
sns_plot.set_xticklabels(df_temp.index, rotation=20)
sns_plot.grid(True)
sns_plot.legend(labels=['Min. Temperature', 'Max Temperature', 'Average Temperature'])
fig.set_size_inches(12, 6)
temperature_plot = f"{city.split(',')[0].replace(' ','_')}_temperature.png"
sns_plot.figure.savefig(temperature_plot,
dpi=300, facecolor='w',
Out [14]
2.2. График влажности, осадков и облачности
В этом графике мы объединяем данные об осадках и влажности.
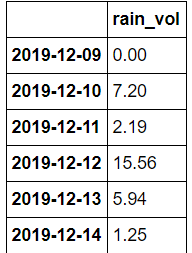
In [15] # Создание Dataframe с ожидаемым объемом осадков по дням:
df_rain_per_day = df.resample(‘D’, on=’datetime’).sum()[[‘rain_vol’]]
df_rain_per_day.index = df_rain_per_day.index.date
Out [15]
In [17]
fig = plt.figure()
# Линейный график влажности и облачности:
ax1 = fig.add_subplot(211)
ax1 = sns.lineplot(data=df_mean[['clouds', 'humidity']], markers=True, dashes=False)
ax1.set_xticks([])
ax1.set_title(f'Expected humidity and rain volume for the next 5 days', fontsize=20)
ax1.set_ylabel('Percentage', fontsize=14)
ax1.grid(True)
# Столбцы с общим объемом осадков по дням:
ax2 = fig.add_subplot(212)
ax2 = sns.barplot(x=df_rain_per_day.index, y='rain_vol',
data=df_rain_per_day,
palette="Blues_d")
ax2.set_xticklabels(df_temp.index, rotation=30)
ax2.set_ylabel('Total Rain Volume in mm', fontsize=14)
ax2.set_xlabel('Date', fontsize=14)
fig.set_size_inches(12, 6)
rain_humidity_plot = f"{city.split(',')[0].replace(' ','_')}_rain_humidity.png"
fig.savefig(rain_humidity_plot,
dpi=300, facecolor='w',
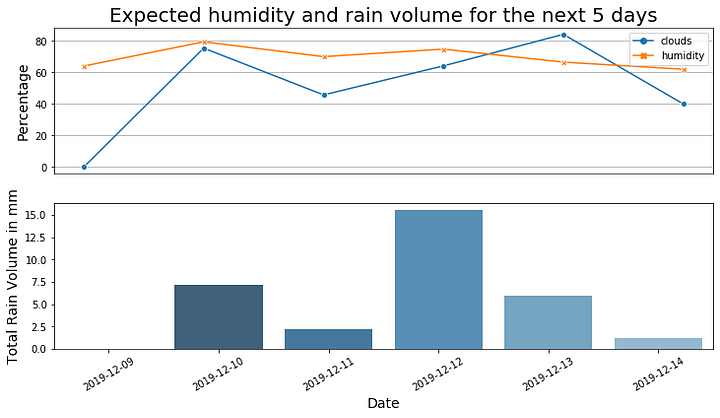
3.4. Рабочий процесс. Часть 3: создание прогноза погоды в PDF
На последнем этапе рабочего процесса мы создаем общую метеорологическую сводку с использованием данных по городу и информации из графиков. Здесь нам понадобится библиотека pdfkit. С ее помощью мы сможем преобразовать HTML-шаблон в PDF-файл.
3. Создание метеосводки
На этом этапе рабочего процесса мы воспользуемся простым HTML-шаблоном и на его основе создадим итоговый отчет, куда добавим информацию о выбранном городе и наши графики.
In [49] # Задаем начальные и конечные даты для анализа:
today = str(df_mean.index.min()).replace(‘-’, ‘/’)
last_day = str(df_mean.index.max()).replace(‘-’, ‘/’)
In [50] # HTML-шаблон для добавления данных и графиков:
report_template = f’’’
<!DOCTYPE html>
<html>
<head>
<meta charset=’utf-8'>
<title>Weather Forecast with PyOWM</title>
<link rel=’stylesheet’ href=’report.css’>
<style>
h1 {{
font-family: Arial;
font-size: 300%;
}}
h2 {{
font-family: Arial;
font-size: 200%;
}}
@page {{
size: 7in 9.25in;
margin: 27mm 16mm 27mm 16mm;
}}
</style>
</head>
<h1 align=”center”>Weather forecast for {city}</h1>
<h2 align=”center”>Initial date: {today}</h2>
<h2 align=”center”>Final date: {last_day}</h2>
<figure>
<img src=”{temperature_plot}” width=”1200" height=”600">
</figure>
<figure>
<img src=”{rain_humidity_plot}” width=”1200" height=”600">
</figure>
</html>
‘’’In [51] # Сохранение HTML-строки в файл:
html_report = f"{city.split(',')[0].replace(' ','_')}_report.html"
with open(html_report, "w") as r:
r.write(report_template)In [52] # Использование pdfkit для создания графика в PDF:
pdfkit.from_file(html_report, f”{city.split(‘,’)[0].replace(‘ ‘, ‘_’)}_weather_report_for.pdf”)
3.5. Окончательная проверка перед подключением к Papermill
Сразу после завершения анализа в Jupyter Notebook, рекомендуется протестировать рабочий процесс через перезапуск ядра и запуск всех ячеек (Run > Run all cells). Если мы видим, что все ячейки выполнились успешно, и был получен ожидаемый результат, то наш блокнот готов к интеграции с Papermill. Ожидаемый метеопрогноз, который наш рабочий процесс сгенерировал для Сан-Паулу, представлен на Рис. 2. В дальнейшем мы настроим Jupyter Notebook на принятие любого города в качестве параметра рабочего процесса и его автоматическое выполнение через Papermill.
4. Настройка блокнота для Papermill
Теперь, когда наш блокнот готов для работы, необходимо внести ряд изменений в его настройки для корректной интеграции с Papermill. Вы можете воспользоваться JupyterLab либо интегрировать Jupyter Notebook с Papermill. Настройка ячейки с параметрами разнится для каждой платформы, поэтому на данном этапе будьте предельно внимательны.
4.1. Определение параметров в JupyterLab
При запуске блокнота через JupyterLab мы должны будем создать ячейку параметров рабочего процесса со значениями по умолчанию. Далее мы выделяем ячейку с параметрами, выбираем Notebook Tools(иконка с гаечным ключом на панели настроек слева) и Advanced Tools(Рис. 3).
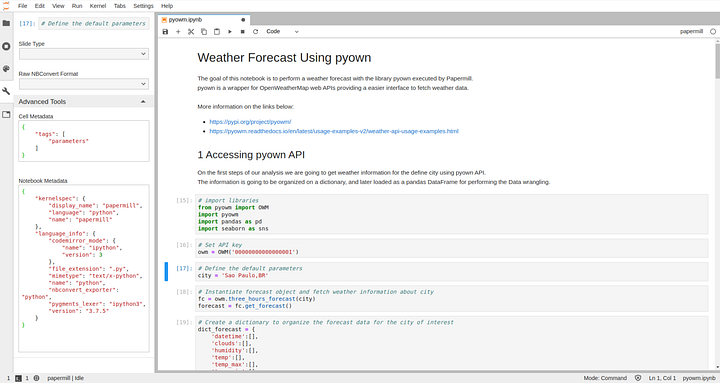
В поле Cell Metadata добавляем следующее описание:
{
"tags": [
"parameters"
]
}Не забудьте сохранить изменения, нажав на иконку вверху поля. Теперь ваш блокнот в JupyterLab готов к получению параметров из Papermill.
4.2. Определение параметров в Jupyter Notebook
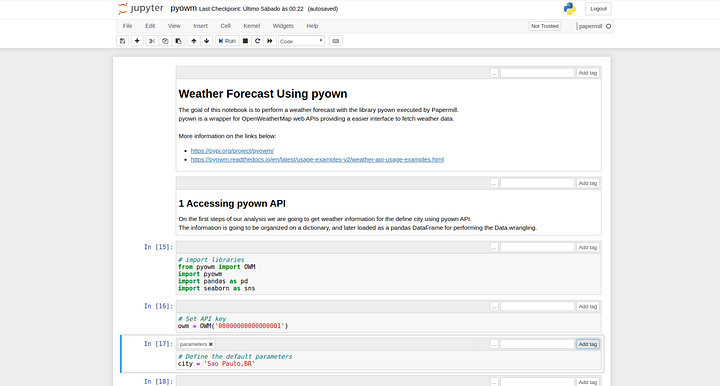
Для настройки ячейки параметров в Jupyter Notebook нужно нажать View > Cell Toolbar > Tags. Далее прописываем и добавляем тег parameters в нужную ячейку блокнота (Рис. 4).
5. Выполнение Papermill
Запустить Papermill можно из командной строки или через Python API. Для запуска Jupyter Notebooks через терминал мы выполним следующую команду (6):
# 6) Запуск Papermill из терминала
papermill weather_forecast_using_pyowm.ipynb \
weather_forecast_using_pyowm_output.ipynb \
-p city 'Sao Paulo,BR' \
-k papermill-tutorialПервые два параметра — это название целевого блокнота (из сессии 3) и название блокнота вывода (выполненная версия ввода). Для перечисления параметров используется -p, поэтому здесь мы описываем название и значение каждого параметра (в нашем случае есть только city). И, наконец, через -k указывается ядро. Тут мы выбираем papermill-tutorial, созданное в шаге 5).
Если бы мы захотели запустить тот же процесс через Python API в Papermill, то написали бы следующее:
import papermill as pm
pm.execute_notebook('weather_forecast_using_pyowm.ipynb',
'weather_forecast_using_pyowm_output.ipynb',
parameters={'city':'Sao Paulo,BR'},
kernel_name='papermill-tutorial')5.1. Блокнот вывода
С помощью Python API в Papermill можно при желании объединить выполнение блокнота с другими действиями. Например, если бы в процессе выполнения вдруг возникла ошибка, то мы могли бы проанализировать выходной файл, обнаружить проблему и сохранить информацию в структуре базы данных.
Файлы блокнотов Jupyter (с расширением .ipynb) — это JSON-файлы с информацией о тексте каждой ячейки, исходном коде, выводе и метаданных. Papermill создает файл вывода, который представляет собой блокнот входа, выполненный с пользовательскими параметрами. По сути, здесь присутствует вся нужная информация для обработки документа. То есть мы можем использовать блокнот вывода в качестве некоего журнала логирования данных при выполнении рабочего процесса. Один из способов сохранения выходных JSON-файлов — это использование базы данных «ключ-значение» NoSQL (Amazon DynamoDB, MongoDB, CassandraDB, BigTable и т.д.).
6. Заключение
Papermill — это простой и удобный инструмент, преобразующий Jupyter Notebook в рабочий процесс обработки данных. Он расширяет возможности использования блокнотов, устраняет ограничения среды по визуализации/документации и предлагает готовую к запуску платформу. Papermill можно использовать как быстрое и качественное решение для прототипирования рабочих процессов перед созданием ETL, работающих с более сложными процессами передачи данных (как, например, Airflow или Luigi).
Интеграционные возможности данной платформы безграничны. Мы уверены, что Papermill обзаведется своим сообществом, которое направит развитие проекта в серьезное русло.
Читайте также:
- 4 совета по улучшению Jupyter Notebooks
- Прокачка Jupyter Notebooks
- Как легко оптимизировать Jupyter Notebook. Часть 1
Перевод статьи Gabriel dos Santos Goncalves: Introduction to Papermill





