
Аналитик данных — лучший в статистике среди программистов и лучший программист среди статистиков. В этом топе обсудим, как программисту стать лучше в статистике.
Примеры, код и детальный вывод доступны на github и в Jupyter Notebook. В коде библиотека d6tflowуправляет рабочим процессом, а d6tpipe обеспечивает публичное хранение данных.
1. Неполное понимание целевой функции
Аналитики хотят создать «лучшую» модель. Но красота в глазах смотрящего. Если вы не знаете, в чем заключается основная задача и целевая функция, не знаете, как модель себя ведёт, то вряд ли построите «лучшую» модель. Кроме того, задача может заключаться в улучшении бизнес-метрики, а не в построении математической функции.
Решение: убольшинства победителей Kaggle уходит много времени на понимание целевой функции и того, как с ней связаны модель и данные. Если вы оптимизируете бизнес-метрику, сопоставьте её с соответствующей целевой функцией.
Пример: для оценки моделей классификации используется F-мера. Однажды мы построили модель классификации, успех которой зависел от того, в каком проценте случаев она была правильной. Как выяснилось, F-мера вводит в заблуждение, потому что показывает, что модель была правильной примерно 60% времени, а на самом деле — только 40%.
f1 0.571 accuracy 0.42. Это работает, но почему?
Аналитики хотят строить «модели». Они слышали, что xgboost и алгоритм “случайный лес” работают лучше всего и просто используют их. Они читают о глубоком обучении и думают, что, возможно, оно улучшит результат. Они бросают модели в проблему, не глядя на данные и не выдвигая гипотезы, какая модель лучше всего отражает особенности данных. Это сильно усложняет объяснение вашей работы хотя бы потому, что вы сами её не понимаете.
Решение: смотрите на данные! Поймите их характеристики и сформулируйте гипотезы о том, какие модели лучше всего их отражают.
Пример: посмотрев на данные на графике даже без запуска модели, вы увидите: x1 линейно связан с y, а x2 не имеет с ним сильно выраженной связи.
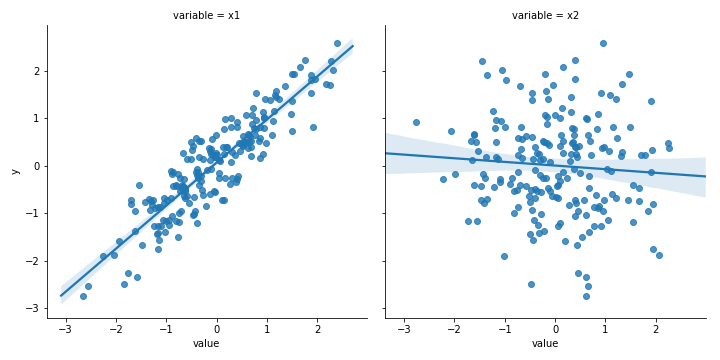
3. Вы не смотрите на данные до интерпретации
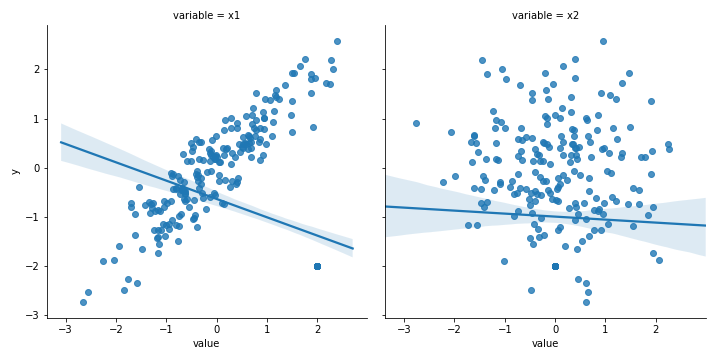
Ещё одна подобная проблема: ваши результаты могут быть обусловлены выбросами и другими артефактами. Это особенно актуально для моделей, минимизирующих суммы квадратов. Даже без выбросов возникают проблемы с балансом, отброшенными или отсутствующими значениями и другими аномалиями реальных данных, которые вы не разбирали в университете.
Решение: повторяю, смотрите на данные — это очень важно! Поймите, как их природа влияет на результат.
Пример: с выбросами наклон x1 изменился с 0,906 до -0,375!
4. У вас нет простейшей базовой модели
Современные библиотеки ML упрощают задачу. Почти. Просто измените одну строчку кода и запускайте модель. И другую. И ещё одну. Метрики ошибок уменьшаются, ещё настройка. Великолепно — они снижаются ещё… При всей изощрённости модели вы можете забыть о глупом способе прогнозирования. Без этого примитивного теста у вас нет абсолютного показателя качества моделей, а они могут быть плохими в абсолютном выражении.
Решение: какой простейший способ, предсказывающий значения? Создайте модель, используя последнее известное значение, (скользящее) среднее или постоянную вроде 0. Сравните производительность с прогнозом какой-нибудь обезьяны!
Пример: с этим набором временных рядов первая модель должна быть лучше второй: среднеквадратичная ошибка (далее — СКО) 0,21 и 0,45. Но подождите! Принимая во внимание только последнее известное значение, СКО падает до 0,003!
ols CV mse 0.215rf CV mse 0.428last out-sample mse 0.0035. Неправильное тестирование вне выборки
Это может разрушить карьеру! Модель выглядела великолепно в исследованиях и разработках, но ужасно проявила себя на реальных данных. Такая модель приводит к очень плохим результатам, она может стоить компании миллионов. Это самая грубая ошибка из всех!
Решение: убедитесь, что работаете с моделью в реалистичных условиях и понимаете, когда она будет работать, а когда — нет.
Пример: внутри выборки случайный лес работает намного лучше линейной регрессии: СКО 0,048 в сравнении с 0,183, но вне выборки случайный лес намного хуже: 0,259 против 0,187. Случайный лес переобучен и провалится в реальных условиях!
in-samplerf mse 0.04 ols mse 0.183out-samplerf mse 0.261 ols mse 0.1876. Предварительная обработка всего набора
Вы уже знаете, что мощная модель может переобучиться. Это означает, что она хорошо работает в выборке, но плохо вне выборки. То есть нужно знать об утечках обучающих данных в тестовые. Если не будете внимательны, то каждый раз, когда выполняете проектирование или перекрёстную проверку, тренировочные данные могут проникать в тестовые, снижая производительность.
Решение: убедитесь, что у вас есть настоящий тестовый набор без примесей тренировочного. Особенно остерегайтесь любых зависящих от времени отношений, возникающих в реальных условиях.
Пример: это случается часто. Предварительная обработка применяется ко всему набору данных до разделения на обучающие и тестовые данные, то есть у вас не будет пригодного для теста набора. Предварительная обработка должна применяться после разделения и отдельно к каждому набору, чтобы у вас был настоящий тестовый набор.
СКО между двумя выборками (0,187 смешанной выборки против 0,181 истинной) не сильно отличается: свойства распределения у наборов тоже не так уж различны, но это дело случая.
mixed out-sample CV mse 0.187 true out-sample CV mse 0.1817. Перекрёстная проверка и панельный анализ
Вас учили, что перекрёстная проверка — всё, что нужно. Sklearn даже предоставляет несколько удобных функций для неё, поэтому вы думаете, что сделали всё. Но большинство методов перекрёстной проверки используют случайную выборку, а значит, можно получить смешение наборов с завышением производительности.
Решение: создавайте данные, точно отражающие те, на которых можно делать предсказания в реальном использовании. Особенно с временными рядами и панельными данными. В этом случае, вероятно, для перекрёстной проверки придётся генерировать пользовательские данные или делать пошаговую оптимизацию.
Пример: есть панельные данные для двух разных объектов (например, компаний) и они сильно пересечены друг с другом. Если разделение случайно, то вы делаете точные прогнозы, используя данные, что на самом деле не были доступны во время тестирования. Это приводит к завышению производительности. Вы думаете, что избежали ошибки #5 с перекрёстной проверкой и видите, что случайный лес работает намного лучше линейной регрессии. Но после пошагового тестирования, предотвращающего утечку будущих данных в тестовый набор, случайный лес снова работает хуже! (СКО от 0,047 до 0,211. Выше, чем у линейной регрессии!)
normal CV
ols 0.203 rf 0.051
true out-sample error
ols 0.166 rf 0.229
8. Какие данные доступны при принятии решения?
Когда вы запускаете модель в реальных условиях, она получает доступные именно в этот момент данные. Они могут отличаться от тех, что предполагалось использовать в обучении. Например, они опубликованы с задержкой, поэтому к моменту запуска другие входные данные изменились. Значит, вы делаете прогнозы с неверными данными или ваша истинная переменная y теперь ложна.
Решение: проведите пошаговое тестирование вне выборки. Если бы модель испытывалась в реальных условиях, то как бы выглядел обучающий набор? Какие данные имеются для прогнозирования? Кроме того, подумайте вот о чём: если бы вы действовали на основании прогноза, то какой результат был бы в момент принятия решения?
9. Переобучение
Чем больше времени вы тратите на набор данных, тем вероятнее переобучение. Вы работали с функциями, оптимизировали параметры, использовали перекрёстную проверку, поэтому всё должно быть хорошо.
Решение: закончив построение модели, попробуйте найти другую версию наборов данных. Она может быть суррогатом для настоящего набора вне выборки. Если вы менеджер, сознательно скрывайте данные, чтобы они не использовались для обучения.
Пример: применение моделей, обученных на первом наборе данных ко второму набору, показывает: СКО более чем удвоилось. Это приемлемо? Решение за вами, но результаты #4 могут помочь.
первый наборrf mse 0.261 ols mse 0.187новый наборrf mse 0.681 ols mse 0.49510. Нужно больше данных?
Интуитивно это покажется странным, но зачастую лучший способ начать анализ — работать с репрезентативной выборкой. Это позволяет ознакомиться с данными и построить конвейер, не дожидаясь их обработки и обучения модели. Но аналитикам, похоже, это не нравится: лучше больше данных.
Решение: начните работу с небольшой репрезентативной выборкой и посмотрите, сможете ли вы получить из нее что-то полезное. Верните выборку конечным пользователям. Они могут её использовать? Это решает реальную проблему? Если нет, то проблема скорее всего не в количестве данных, а в подходе.
Дополнительно посмотрите вывод и код для каждого примера на github и Jupyter Notebook.
Читайте также:
- Алгоритмы машинного обучения простым языком. Часть 1
- Алгоритмы машинного обучения простым языком. Часть 2
- Нейронная сеть с нуля при помощи numpy
Перевод статьи Norm Niemer: Top 10 Statistics Mistakes Made by Data Scientists





