
Одним из основных плюсов динамически интерпретируемых языков (включая Python) является то, что с ними можно легко управлять памятью. По мере необходимости объекты (массивы и строки) динамически растут, а их память очищается, когда ей никто не пользуется. Поскольку управление памятью осуществляется самим языком, то ее утечки встречаются реже, чем в С и С++, в которых программист сам запрашивает и высвобождает память.
Например, технологический стек BuzzFeed включает в себя архитектуру микросервисов, поддерживающих более ста сервисов, большая часть которых написана на Python. Мы изучаем такие системные свойства сервисов, как память и нагрузка. В первом случае хороший сервис будет использовать и освобождать память. Он работает так, как показано на графике ниже, сообщая об использовании памяти за 3-месячный период.
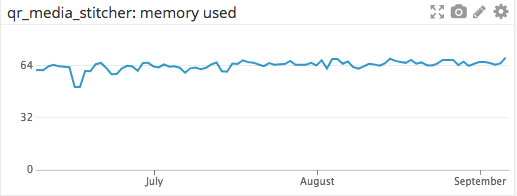
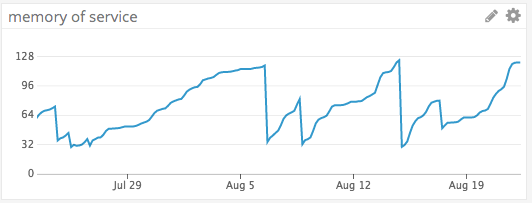
Микросервис, в котором со временем возникает утечка памяти, демонстрирует на графике пилообразные скачки. Они возникают при увеличении используемой памяти до определенного значения (например, максимальной доступной памяти), при котором сервис отключается, высвобождается вся память и происходит перезапуск.
Иногда анализ кода помогает обнаружить участки программы, в которых основные ресурсы операционных систем (напр., дескриптор) выделяются, но не освобождаются. Такие ресурсы ограничены и в своей работе выделяют небольшое количество памяти. Эту память необходимо освободить после использования ресурса, чтобы другие могли с ним работать.
В начале статьи описываются инструменты для вычисления источников утечки памяти. Затем разбирается реальный пример приложения на Python и демонстрируется работа специальных инструментов для обнаружения утечек памяти.
Инструменты
Если анализ кода не находит существенных изъянов, то утечки памяти отслеживают с помощью специальных инструментов. Один из них составляет временную шкалу с графиком использования памяти. DataDog мониторит производительность микросервисов. Утечки могут накапливаться постепенно — по нескольку байт за раз. В таком случае необходимо отследить динамику роста памяти.
Еще один инструмент — tracemalloc. Он является частью системной библиотеки Python. По большому счету, tracemalloc используется для создания снимков Python памяти. Для инициализации tracemalloc вызовите tracemalloc.start(). Затем сделайте снимок через:
snapshot=tracemalloc.take_snapshot()
С помощью метода statistics() tracemalloc может отобразить на снимке упорядоченный список всех основных выделений ресурсов. В данном фрагменте кода отмечаются пять основных источников выделений памяти, которые группируются по имени файла источника.
for i, stat in enumerate(snapshot.statistics(‘filename’)[:5], 1):
logging.info(“top_current”,i=i, stat=str(stat))
Результат выглядит примерно так:

В нем показан размер выделяемой памяти, количество выделенных объектов и средний размер каждого из них с разбивкой на модули.
Мы сделали снимок при запуске программы и реализовали обратный вызов, который запускается через каждые несколько минут и делает снимок памяти. Сравнение двух снимков показало разницу в распределении памяти. Мы сопоставили каждый снимок с данными, полученными при запуске программы. Динамическое отслеживание возрастаний выделенной памяти позволило идентифицировать объект с утечкой памяти. Для сравнения значений с другим снимком был вызван метод compare_to().
Объединение всех выделенных ресурсов по модулям делалось через параметр 'filename'. Таким образом, мы смогли сузить поиск и найти модуль с утечкой памяти.
current = tracemalloc.take_snapshot()
stats = current.compare_to(start, ‘filename’)
for i, stat in enumerate(stats[:5], 1):
logging.info(“since_start”, i=i, stat=str(stat))
Результат получился следующим:

Здесь показаны размер и количество объектов, их сравнение и средний размер выделения памяти по каждому модулю.
При обнаружении подозрительного модуля, следует найти точную строку кода, ответственную за выделение памяти. В tracemallocможно просматривать трассировку стека для любого выделения памяти. Как и в случае с обратной трассировкой в Python, здесь нам показывается строка и модуль с выделением памяти, а также все предшествующие вызовы.

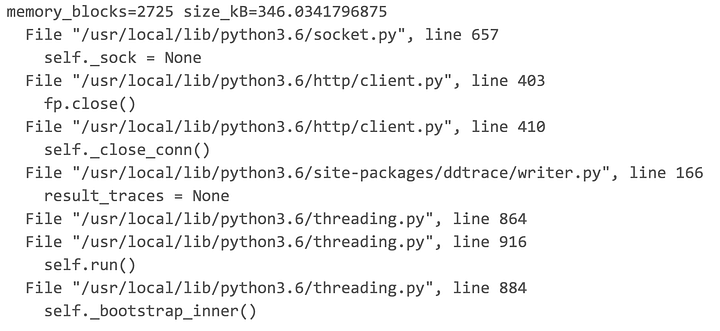
Читая код снизу вверх, мы выходим на нужную строку в модуле socket, в котором отмечалось выделение памяти. Благодаря этим данным мы сможем изолировать причину утечки памяти.
В первой части статьи мы увидели, чтоtracemalloc делает снимки памяти и предоставляет статистические данные о выделении памяти. В следующей части описываются этапы поиска утечки памяти в одном из микросервисов.
Поиск утечки данных
Несколько месяцев мы наблюдали за классическими пилообразными скачками приложения с утечкой памяти.
Мы снабдили микросервис вызовом к trace_leak(). Это функция, которую мы создали для логирования данных из снимков tracemalloc. Код зацикливается и немного «отдыхает» в каждом цикле.

Микросервис создан с помощью tornado. Поэтому его можно вызвать через spawn_callback() и передать параметры delay, top иtrace:
tornado.ioloop.IOLoop.current().spawn_callback(trace_leak, delay=300, top=5, trace=1)
По логам одной итерации видно, что выделение памяти происходит в нескольких модулях.

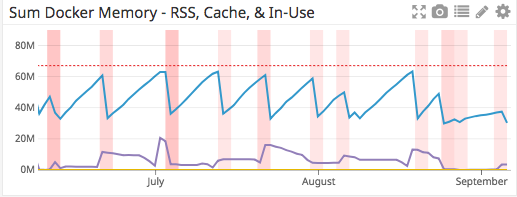
tracemallocне является источником утечки памяти! Он попал в этот список только потому, что для своей работы ему требуется определенное количество памяти. Мы запустили сервис на пару часов, использовали DataDog для сортировки логов по модулям и обнаружили некую тенденцию роста в socket.py:
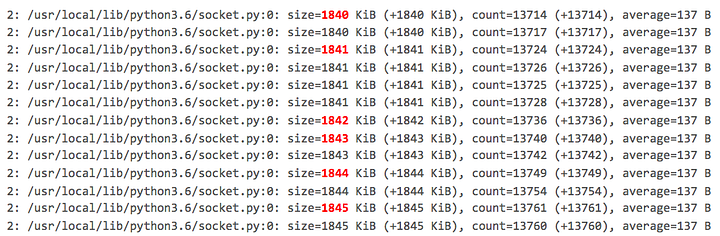
Размер выделенной памяти в socket.py увеличивался с 1840 КиБ до 1845 КиБ. Ни в одном другом модуле такого не наблюдалось. Далее выполняем обратную трассировку socket.py.
Мы нашли возможную причину
Через tracemallocмы получаем трассировку стека для модуля socket.
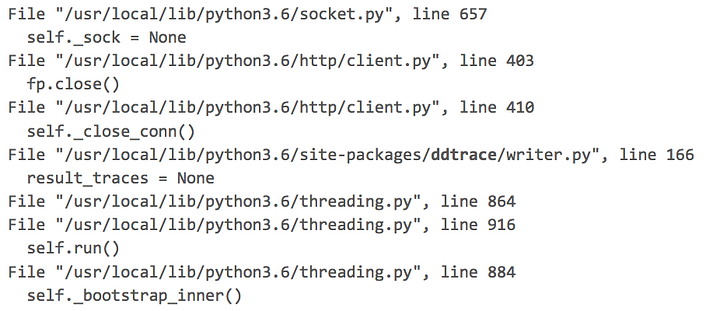
Изначально я предполагал, что Python и стандартная библиотека — стабильны и не имеют утечки памяти. В этой трассировке стандартной библиотекой Python 3.6 является все, кроме пакета из DataDog ddtrace/writer.py. С учетом моего предположения о целостности Python, пакет, предоставленный сторонним ресурсом, становится достойным кандидатом для дальнейшего изучения.
Все еще подтекает
Мы нашли, когда к нашему сервису добавлялся ddtrace, и сделали быстрый откат, а затем повторно понаблюдали за памятью.
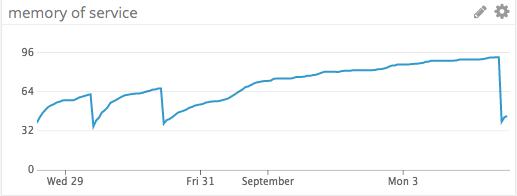
Еще один просмотр логов
В течение нескольких дней память продолжала расти. Удаление модуля не ликвидировало утечку. А главный виновник так и остался не обнаруженным. Поэтому вновь возвращаемся к логам и ищем другого подозреваемого.

Вроде, ничего в этих логах не вызывает подозрений. Однако под ssl.pyпочему-то отдается самый большой объем памяти — целых 2,5 МБ. Логи показывают, что с течением времени данное значение всегда постоянно; оно не увеличивается и не уменьшается. За неимением вариантов начинаем проверку обратной трассировки ssl.py.
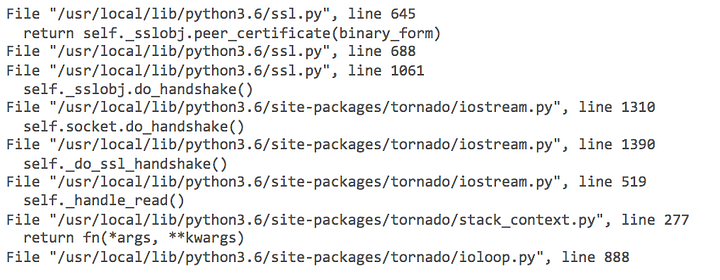
Четкая наводка
Верхушка стека показывает в ssl.py вызов к peer_certificate()в строке 645. На всякий случай, хорошенько гуглим «python утечка памяти ssl peer_certificate». Там нам попадается ссылка на отчеты об ошибках в Python. К счастью, этот баг починили. Дело остается за малым — обновить образ контейнера с Python 3.6.1 до Python 3.6.4, поставить исправленную версию и проверить, прекратилась ли утечка памяти.
Все хорошо
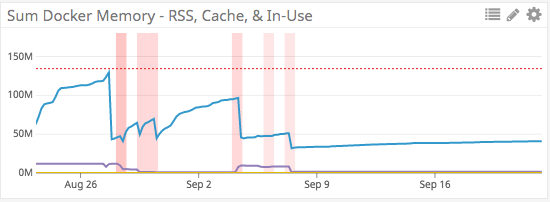
После обновления образа мы еще раз мониторим память через DataDog. После свежего развертывания от 9 сентября выделение памяти работает без нареканий.
Заключение
Наличие правильных инструментов в работе позволяет прочувствовать разницу между решением проблемы и бездействием. На поиск утечки памяти у нас ушло целых два месяца. tracemallocпозволяет увидеть динамику памяти в Python. Однако он не знает о распределении памяти в пакетах на С и С++. В конечном счете обнаружение утечек памяти требует терпения, настойчивости и небольшой сыскной работы.
Перевод статьи Peter Karp: Finding and Fixing Memory Leaks in Python





