
Предыдущие части: Часть 1
В предыдущей статье я рассказывал о том, как извлекать статические данные с помощью Node.js. В настоящее время сайты приобретают более динамический характер, то есть содержимое сайта отображается через JavaScript. К примеру, сделаем запрос на любой SPA-сайт, подобно шаблону vue-admin, и отключим javascript с помощью Chrome DevTools. В итоге, получаем подобный ответ:
<html lang="tr">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="https://fonts.googleapis.com/icon?family=Material+Icons" rel="stylesheet">
<link href="https://use.fontawesome.com/releases/v5.6.3/css/all.css" rel="stylesheet">
<link rel="shortcut icon" type="image/png" href="static/logo.png">
<title>Vue Admin Template</title>
<link href="static/css/app.48932a774ea0a6c077e59d0ff4b2bfab.css" rel="stylesheet">
</head><body data-gr-c-s-loaded="true" cz-shortcut-listen="true">
<div id="app"></div>
<script type="text/javascript" src="static/js/manifest.2ae2e69a05c33dfc65f8.js">
</script>
<script type="text/javascript" src="static/js/vendor.ef9a9a02a332d6b5e705.js">
</script>
<script type="text/javascript" src="static/js/app.3ec8db3ca107f46c3715.js">
</script>
<body data-gr-c-s-loaded="true" cz-shortcut-listen="true">
<div id="app"></div>
<script type="text/javascript" src="static/js/manifest.2ae2e69a05c33dfc65f8.js">
</script>
<script type="text/javascript" src="static/js/vendor.ef9a9a02a332d6b5e705.js">
</script>
<script type="text/javascript" src="static/js/app.3ec8db3ca107f46c3715.js">
</script>
</body>
</html>
Таким образом, фактическое содержание сайта, которое необходимо извлечь, отобразится в элементе div#app с помощью JavaScript, поэтому методы, которые мы использовали для извлечения данных в предыдущей статье, в данном случае не работают, поскольку нам нужно запустить файлы JavaScript, аналогичные нашим браузерам.
Нам потребуются инструменты для веб-автоматизации и библиотеки, такие как Selenium, Cypress, Nightmare, Puppeteer, x-ray, а также headless-браузеры, такие как phantomjs и т.д.
Почему именно эти инструменты и библиотеки? Потому что именно эти инструменты и библиотеки обычно используют тестировщики программного обеспечения. С их помощью можно открыть экземпляр браузера, в котором веб-сайт работает так же, как и в других браузерах, и, следовательно, запустить файлы javascript, отображающие динамическое содержимое сайта.
Что нам понадобится?
Как было сказано предыдущей статье, веб-скрапинг разделен на две простые части:
- Выборка данных с помощью HTTP-запроса
- Извлечение важных данных с помощью парсинга HTML DOM
Нам понадобится Node.js и библиотека автоматизации браузера:
- Nightmare — это высокоуровневая библиотека автоматизации браузера из Сегмента.
- cheerio — это аналог jQuery для работы с Node.js. Cheerio позволяет легко выбирать, редактировать и просматривать элементы DOM.
Установка
Установка довольно проста. Нужно создать новую папку и запустить команду внутри нее, чтобы создать файл package.json. Затем добавьте Nightmare и Cheerio из npm в качестве зависимостей.
npm init -y
npm install nightmare cheerio --unsafe-perm=true
Теперь включите их в файле `index.js`
const Nightmare = require('nightmare');
const cheerio = require('cheerio');
Библиотека Nightmare похожа на axios или любую другую библиотеку запросов, однако ее особенность заключается в использовании Electron, который схож с PhantomJS, но примерно в два раза быстрее и современнее. Nightmare использует Javascript для передачи/управления DOM с помощью функции evaluate, что сложно реализовать. Поэтому, мы будем использовать Cheerio для обработки содержимого DOM, извлекая innerHTML с помощью функции evaluate, и передавать содержимое (innerHTML) в Cheerio. Это простой и быстрый способ реализации. Помимо этого, Nightmare поддерживает прокси-сервера, промисы и конструкцию async-await.
Скрапинг статического содержимого
Мы уже извлекали статическое содержимое в предыдущей статье, но прежде чем продолжить, сделаем то же самое с Nightmare, чтобы получить более широкое представление и четкое понимание работы с этой библиотекой.
Мы извлекаем данные с веб-сайта HackerNews. Для этого потребуется сделать HTTP-запрос, чтобы получить содержимое веб-сайта и обработать данные с помощью cheerio.
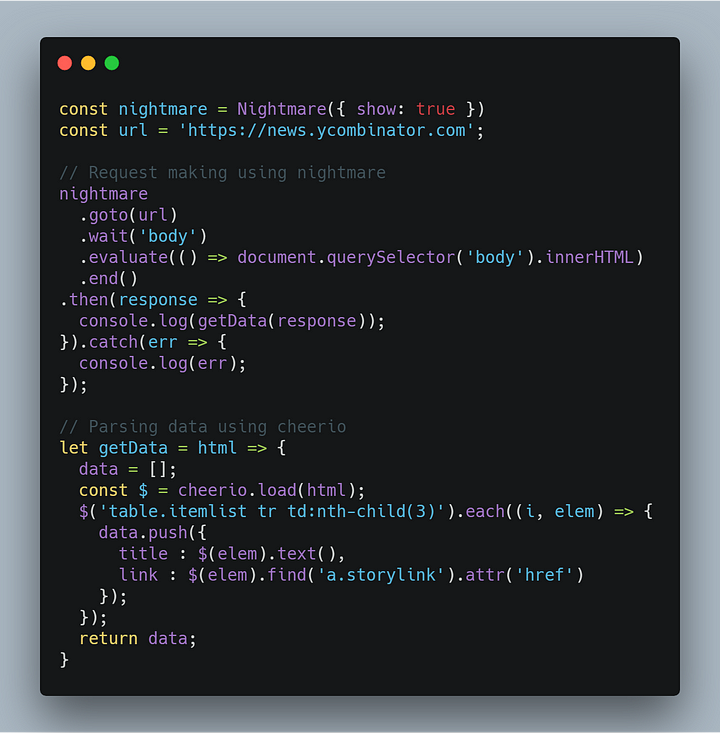
В первой строке мы инициализируем nightmare и устанавливаем значение true для свойства show, чтобы отслеживать действия браузера во время выполнения. Делаем запрос к url-адресу через функцию goto и ждем, когда DOM отобразится через функцию wait, иначе последующие шаги будут выполнены без полного отображения содержимого. После того, как тело полностью загрузится, извлекаем innerHTML с помощью функции evaluateи выполняем возврат данных. Наконец, закрываем браузер с помощью вызова функции end.
Можно использовать блоки try/catch, однако при наличии промисов, вызов .then() следует выполнить после .end(), чтобы запустить задачу .end().
Скрапинг динамического содержимого
Мы уже ознакомились с nightmare и научились работать с ней. Теперь попробуем извлечь содержимое с любого веб-сайта, который использует javascript для отображения данных. Помимо этого, nightmare также взаимодействует с веб-сайтами, к примеру, можно делать клики и заполнять формы. Приступим. Извлечем данные о товарах, перечисленных на сайте flipkart.com, но только тех, которые отображаются во время поиска nodejs books.
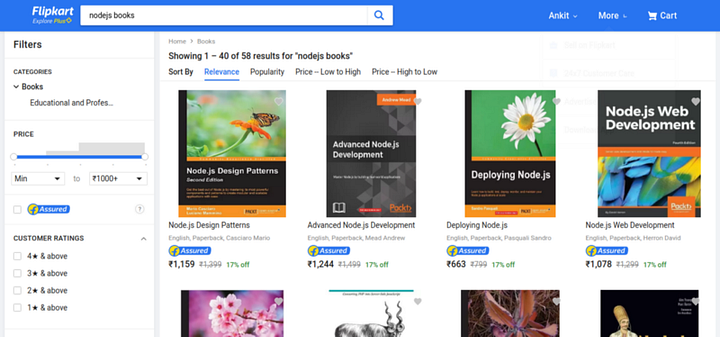
Для взаимодействия с веб-страницей используем функцию click and type.
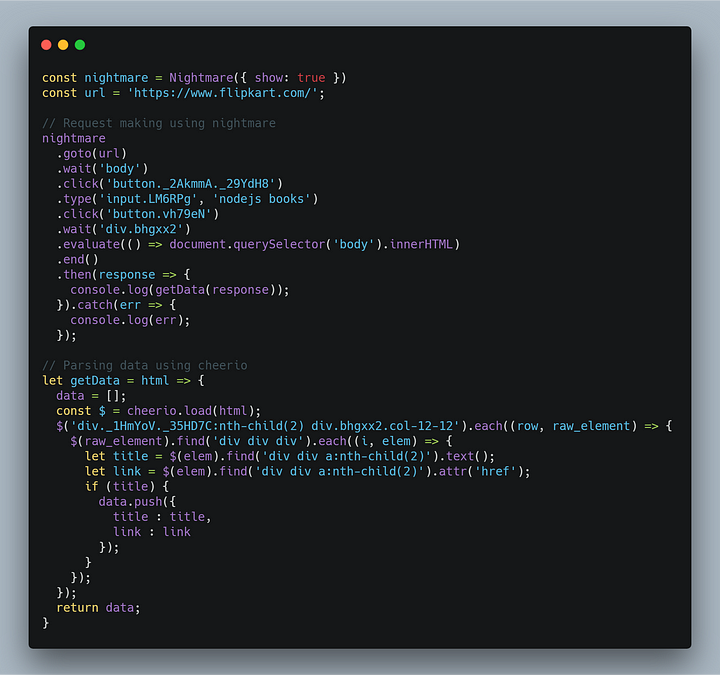
В первую очередь, делаем запрос на сайт Flipkart и вводим nodejs books в строке поиска, выбрав соответствующий HTML-селектор с помощью функции type. Необходимые HTML-селекторы можно найти, используя Chrome DevTools. После этого нажимаем на кнопку поиска, используя функцию click. При нажатии загружается запрашиваемое содержимое, как и в любом другом браузере, и мы получаем innerHTML извлеченного содержимого, как описано во второй части, с использованием cheerio.
Выходные данные будут выглядеть следующим образом:
[
{
title: 'Node.js Design Patterns',
link: '/node-js-design-patterns/p/itmfbg2fhurfy97n?pid=9781785885587&lid=LSTBOK9781785885587OWNSQH&marketplace=FLIPKART&srno=s_1_1&otracker=search&fm=SEARCH&iid=1b09be55-0fad-44c8-a8ad-e38656f3f1b0.9781785885587.SEARCH&ppt=Homepage&ppn=Homepage&ssid=dsiscm68uo0000001547989841622&qH=ecbb3518fc5ee1c0'
},
{
title: 'Advanced Node.js Development',
link: '/advanced-node-js-development/p/itmf4eg8asapzfeq?pid=9781788393935&lid=LSTBOK9781788393935UKCC4O&marketplace=FLIPKART&srno=s_1_2&otracker=search&fm=SEARCH&iid=b7ec6a1b-4e79-4117-9618-085b894a11dd.9781788393935.SEARCH&ppt=Homepage&ppn=Homepage&ssid=dsiscm68uo0000001547989841622&qH=ecbb3518fc5ee1c0'
},
{
title: 'Deploying Node.js',
link: '/deploying-node-js/p/itmehyfmeqdbxwg5?pid=9781783981403&lid=LSTBOK9781783981403BYQFE4&marketplace=FLIPKART&srno=s_1_3&otracker=search&fm=SEARCH&iid=7824aa08-f590-4b8d-96ec-4df08cc1a4bb.9781783981403.SEARCH&ppt=Homepage&ppn=Homepage&ssid=dsiscm68uo0000001547989841622&qH=ecbb3518fc5ee1c0'
},
.
.
]
Мы получили массив объекта JavaScript, содержащий название и ссылки на товары (учебники) с сайта Flipkart. Таким способом можно извлекать данные с любого динамического веб-сайта.
Заключение
В этой статье мы ознакомились с динамическими веб-сайтами и способом извлечения данных с помощью nightmare и cheerio с веб-сайта любого типа. Весь код доступен в репозитории Github.
Перевод статьи Ankit Jain: How to Perform Web-Scraping using Node.js- Part 2





