
Из статьи вы узнаете:
- Что такое бессерверный подход и как его применять.
- Какие провайдеры поддерживают бессерверные технологии.
- Как настроить проект с помощью Netlify.
- Как создать пример приложения с бессерверными функциями Netlify.
- Как провести развертывание.
Понятие бессерверного подхода и случаи его применения
При взгляде на термин “бессерверный” можно подумать, что для запуска кода не нужен сервер. Но на самом деле это не так. А иначе каким образом будет выполняться программа?
В своей книге “Бессерверные приложения на JavaScript” Слободан Стоянович сравнивает их со стиральной машиной, которая используется лишь от 5 до 15 часов в неделю. При этом она занимает место на кухне и потребляет энергию даже в состоянии бездействия. По этой причине некоторые предпочитают пользоваться прачечными, где оплачивается только непосредственное время стирки.
Вполне возможно, что и ваш сервер работает впустую в ожидании запросов. Даже если изредка через него проходит трафик, он все равно обходится в копеечку. А было бы лучше платить только за время, потраченное сервером на обработку запросов.
В этом случае бессерверный подход оказывается как нельзя кстати. Он позволяет реализовывать проекты в облаке на основе оплаты по факту применения. А самое главное преимущество в том, что вы концентрируетесь только на написании кода, не беспокоясь о среде хостинга и базовой ОС. Облачный провайдер встанет на стражу вашего покоя и все сделает за вас.
Какие провайдеры поддерживают бессерверные технологии?
Почти все провайдеры облачных хостингов предоставляют возможности для создания бессерверных приложений. К числу самых известных из них относятся AWS Lambda, Google Cloud Functions и Netlify.
В статье мы создадим бессерверную функцию с помощью Netlify. В качестве аргумента она примет ссылку на веб-сайт и воспользуется API Readability от Mozilla для предоставления его контента. Поскольку она будет находиться на веб-сервере, мы сможем вызывать ее с помощью конечной точки API. Перед вами итоговый результат предстоящей работы:
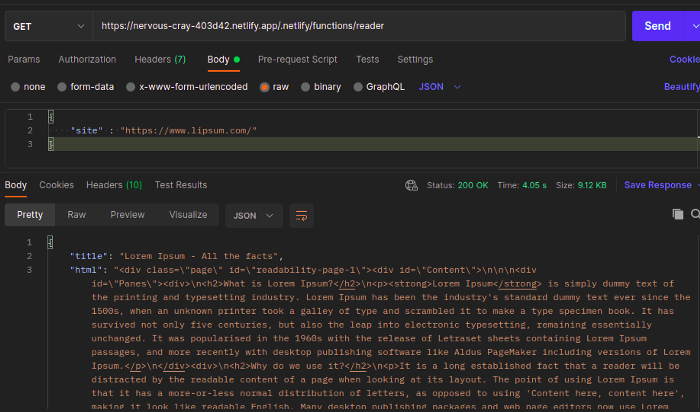
Приступим!
Настройка проекта
Клонирование репозитория шаблона
Основой для данной программы послужит репозиторий Netlify Up And Running. Клонируем его, нажимая на Use this template.
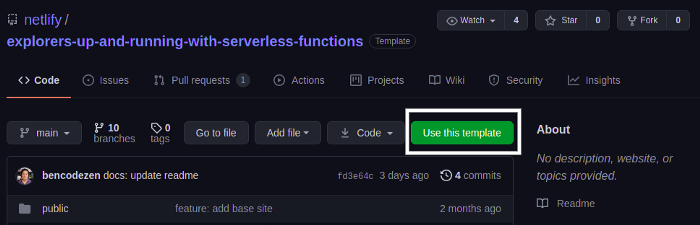
После этого GitHub попросит назвать приложение. Присвоив ему имя, нажимаем на Create repository from this template для создания репозитория на основе имеющегося шаблона.
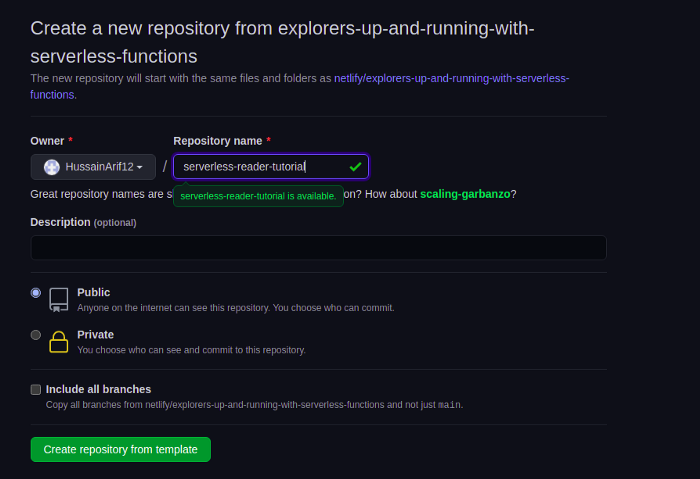
Проект успешно создан. Теперь нужно скачать его код в компьютер.
Но прежде проинформируем Git о месте расположения проекта. Нажимаем на Code для получения URL созданного репозитория.
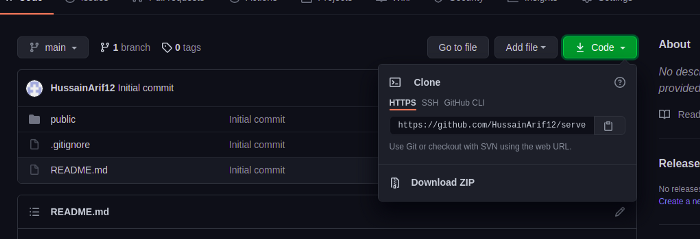
Затем выполняем следующую команду терминала на компьютере:
git clone <url> #url is your project location
Установка CLI Netlify
На следующем этапе необходимо установить инструмент командной строки Netlify. Для этого выполняем команду:
npm install netflify-cli -gДалее авторизуемся с помощью ntl login:
ntl loginПо завершении этого процесса инструктируем Netlify создать веб-сайт с репозиторием. В каталоге проекта выполняем данную bash-инструкцию:
ntl init #выполняем в репозитории проекта Проверяем, что выбраны следующие опции:
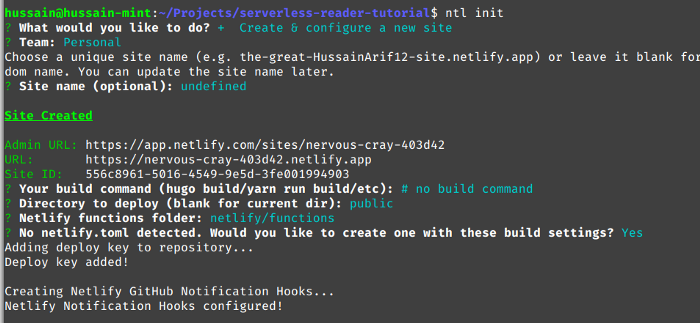
Теперь протестируем настройки и запустим веб-приложение следующим образом:
ntl devКак видим, веб-сервер приведен в состояние готовности для реализации намеченных целей разработки.

Это означает, что настройки заданы корректно! Нажимаем на клавиатуре CTRL + C для завершения работы сервера.
Структура проекта
В каталоге netlify/functions создаем файлы:
reader.js— точка входа функции.utils/readerUtilsхранит логику приложения и другие вспомогательные методы.
В итоге каталог проекта должен выглядеть следующим образом:
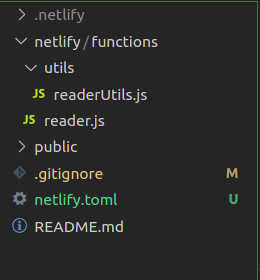
А теперь приступаем к программированию!
Создание приложения
Установка зависимостей
Для приложения потребуются такие модули:
@mozilla/readabilityизвлекает текстовой контент с нужной страницы.gotнеобходим для получения HTML-кода сайта.dompurifyиjsdomудаляют вредоносный JavaScript из исходного кода страницы, таким образом предотвращая XSS-атаки.
Для получения этих зависимостей выполняем команды:
npm init -y # Инициализирует NPM для проекта
npm install @mozilla/readability got dompurify jsdomПарсинг сайта
В данном разделе создадим функцию, которая проинструктирует Node.js извлечь основное содержимое с нужной страницы.
Переходим к файлу netlify/functions/utils/readerUtils.js и пишем в нем следующий код:
const { Readability, isProbablyReaderable } = require("@mozilla/readability");
const got = require("got");
const { JSDOM } = require("jsdom");
const window = new JSDOM("").window;
const DOMPurify = require("dompurify")(window);- Строка 5. Передаем экземпляр
JSDOMвDOMPurifyдля санации входящего HTML-кода.
Далее добавляем в этот файл нижеуказанный код:
async function parseURL(site) {
const response = await got(site);
const doc = new JSDOM(response.body);
if (isProbablyReaderable(doc.window.document)) {
let reader = new Readability(doc.window.document);
let article = reader.parse();
const markup = DOMPurify.sanitize(article.content);
return {
title: article.title,
html: markup,
};
} else {
return { error: "The site was not readable" };
}
}Несколько пояснений к нему:
- Строка 2. Получаем исходный код с нужного сайта.
- Строки 5–13. Если сайт доступен для чтения, проводим парсинг и санируем его HTML-код. Затем отправляем поле
titleи очищенный HTML в качестве ответа клиенту. - Строки 14–15. В противном случае сообщаем клиенту о возникшей ошибке.
Проверка валидности ввода пользователя
Здесь мы прописываем метод, выполняющий проверку на валидность, которая покажет, ввел ли пользователь корректный URL.
Для этого пишем следующий код в readerUtils.js:
function isValidURL(str) {
var pattern = new RegExp(
"^(https?:\\/\\/)?" + // протокол
"((([a-z\\d]([a-z\\d-]*[a-z\\d])*)\\.)+[a-z]{2,}|" + // доменное имя
"((\\d{1,3}\\.){3}\\d{1,3}))" + // ИЛИ адрес ip (v4)
"(\\:\\d+)?(\\/[-a-z\\d%_.~+]*)*" + // порт и путь
"(\\?[;&a-z\\d%_.~+=-]*)?" + // строка запроса
"(\\#[-a-z\\d_]*)?$",
"i"
); // локатор фрагмента
return !!pattern.test(str);
}
//источник функции: https://stackoverflow.com/questions/5717093/check-if-a-javascript-string-is-a-url- Строки 2–10. Создаем простой шаблон регулярного выражения, который проверяет наличие формата URL у вводимых данных.
- Строка 11. Сопоставляем ввод пользователя с регулярным выражением. Если введенная строка является URL, функция вернет
true.
Отправка обработанных данных
После того как мы выполнили проверку на валидность и провели парсинг нужной пользователю веб-страницы, остается лишь отправить ответ клиенту.
Добавляем нижеуказанный блок в readerUtils.js:
async function sendData(site) {
if (isValidURL(site)) {
const { title, html, error } = await parseURL(site);
if (!error) {
return {
title,
html,
error,
};
} else {
return {
error: "The site was not readable",
};
}
} else {
return {
error: "Your input was not a URL",
};
}
}
module.exports = sendData;Разберем данный код детально:
- Строка 2. Сначала проверяем, ввел ли пользователь корректный URL.
- Строка 3. Выполняем метод
parseURL. Здесь мы задействуем деструктуризацию объекта для извлечения полейtitle,htmlиerror. - Строки 4–14. Если операция проходит успешно, то отправляем поля
titleиhtmlв качестве ответа. - Строка 22. Экспортируем метод
sendData, тем самым обеспечивая возможность его использования в проекте.
Связывание утилит с приложением
На этом с кодом для утилит мы закончили. Теперь наша задача — связать эти функции с API.
В reader.js пишем код:
const sendData = require("./utils/readerUtils");
exports.handler = async function (event, context) {
const body = JSON.parse(event.body);
const data = await sendData(body.site);
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*", // Allow from anywhere
},
body: JSON.stringify(data),
};
};- Строка 3. При выполнении пользователем метода
readerзапускается весь код внутри данного обработчика. - Строка 4. Получаем тело полезной нагрузки запроса.
- Строка 5. Вызываем метод
sendData. В качестве его аргумента применяем свойствоsite. Результат сохраняем в переменнойdata. - Строка 11. Отправляем
dataв качестве запроса клиенту.
Тестирование
Перед публикацией API проверяем, все ли работает. Для локального запуска API, выполняем команду:
ntl dev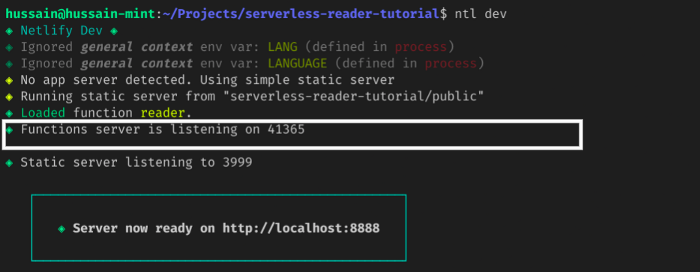
По результату в терминале узнаем расположение сервера функций. В данном случае он запущен на порту 41365.
Для выполнения запроса к API задействуем следующий синтаксис:
localhost:{PORT}/.netlify/functions/{FUNCTION_NAME}В нашем примере это localhost:41365/.netlify/functions/reader.
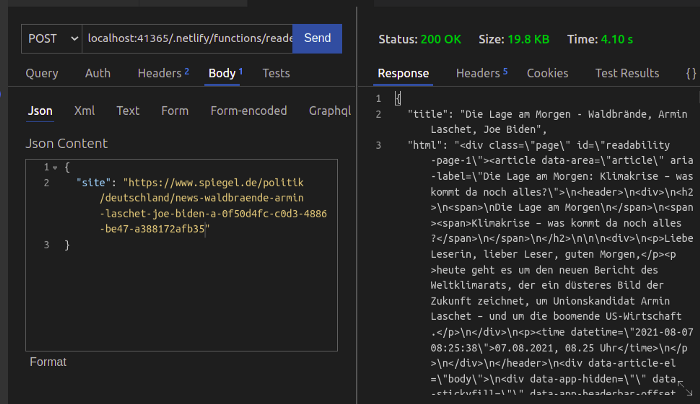
Как видно, код работает! Далее узнаем, как развернуть API с открытым доступом.
Развертывание
Netlify позволяет легко обновлять веб-сайт — просто отправляем код на GitHub:
git add . #добавляем в staging
git commit -m "All complete"
git push origin main #отправляем весь код в репозиторий GitHubТем самым Netlify получает указание изменить код и опубликовать его на сервере.
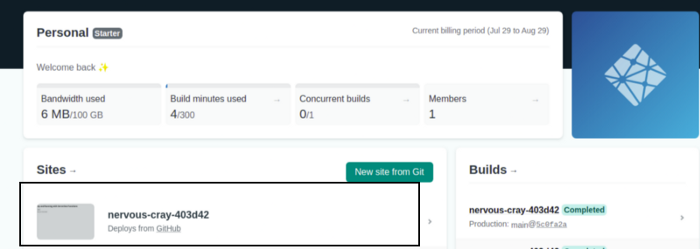
Теперь возвращаемся на домашнюю страницу Netlify и выбираем наш сайт:
Далее кликаем на Functions и получаем перечень функций, связанных с сайтом.
Выбираем имя функции. В данном случае это reader:
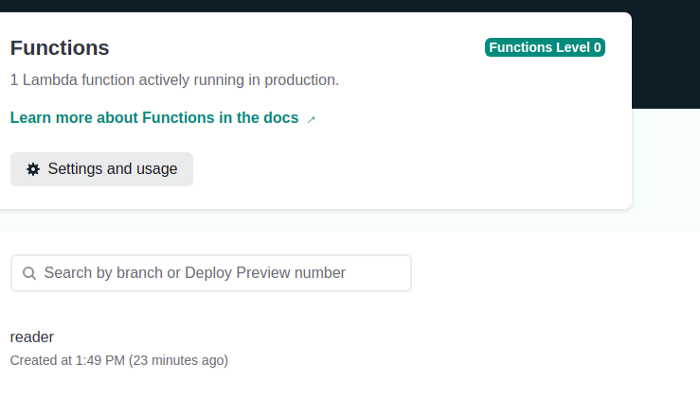
Вам будет предоставлена конечная точка API для вызова вашего метода.
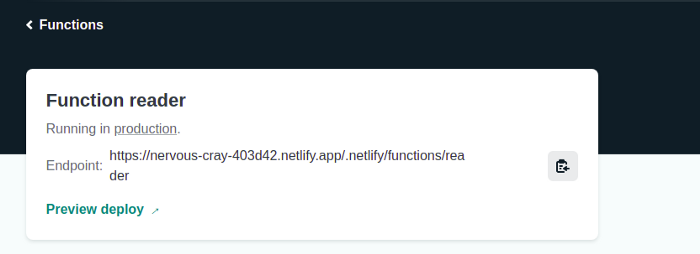
На старт, внимание, запуск!
Вызываем конечную точку API с помощью клиента API. Так мы убедимся, что все работает.
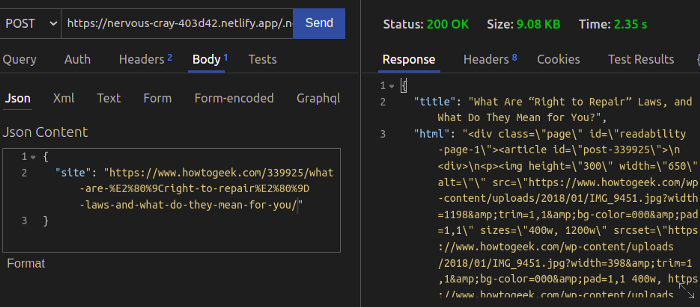
Поздравляю! С помощью Netlify мы создали работоспособную бессерверную функцию.
Репозиторий GitHub для данного проекта.
Заключение
С недавнего времени бессерверная архитектура несомненно приобрела популярность. Если трафик вашего приложения рассчитывается на основании фактического потребления, то бессерверные функции станут отличным решением.
Читайте также:
- Запуск с нуля: как я создала сайт с нуля при помощи Netlify + Gatsby
- Как развернуть React-приложение в Netlify
- 6 полезных библиотек JavaScript
Читайте нас в Telegram, VK и Дзен
Перевод статьи Hussain Arif: Build a Serverless App With Netlify and JavaScript





