
Подобно тому, как лабиринт железнодорожных путей запутанно соединяет оживленные станции в разных географических регионах, образуя сеть путей и возможностей, связи в графовых базах данных служат для соединения узлов в сложной, но упорядоченной сети данных. Каждая станция в этой сети может похвастаться несколькими соединениями, отражающими многогранные отношения, которые могут существовать между узлами графовой базы данных.
Представьте это так: каждое сообщение между станциями уникально и характеризуется различными свойствами, такими как пересекающие его линии метро, преодолеваемое расстояние и количество пассажиров, которые оно переправляет ежедневно. Эти связи — не просто линии на карте; это жизненно важные артерии, которые поддерживают жизнь и движение города. Точно так же в мире графовых баз данных отношения между узлами обогащаются свойствами, которые добавляют сети глубину, контекст и смысл.
Система берлинского метро, с ее сложностью и эффективностью, служит захватывающей аналогией и идеальным введением в мир графов. Это наглядный пример того, как связи и отношения формируют основу транспортных сетей и графовых баз данных. В этом посте мы исследуем систему берлинского метро с помощью Memgraph Lab. Вместе мы раскроем секреты, скрытые в данных, научимся визуализировать сложные взаимосвязи и получим информацию, которую можно получить только с графоцентричной точки зрения.
Получение данных о берлинском метро
Прежде чем начать исследование, нужно получить данные. Когда я искал данные о берлинском метро, я наткнулся на разные наборы данных, связанные с берлинским метро. Мне очень понравились GitHub gist Клиффорда Андерсона о берлинском метро, данные OpenStreetMap, отдельные страницы о каждой станции и линии метро в Википедии, а также я немного пообщался с ChatGPT. Имея так много доступных данных, первое, что мне нужно было решить, что я хочу делать с данными и какие данные мне нужно подготовить. Я решил начать с малого. Данные о станциях метро и соединяющих их линиях я собрал в файлы CSV.
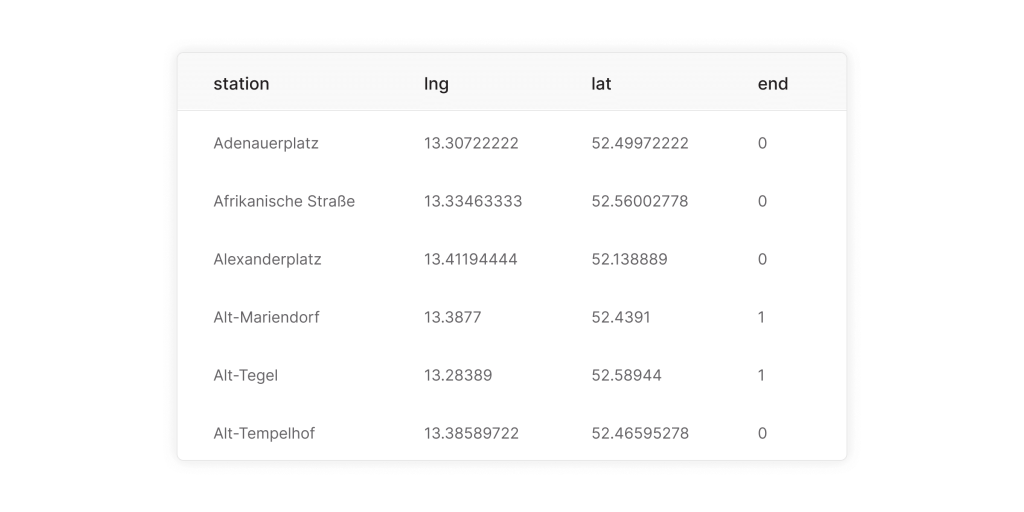
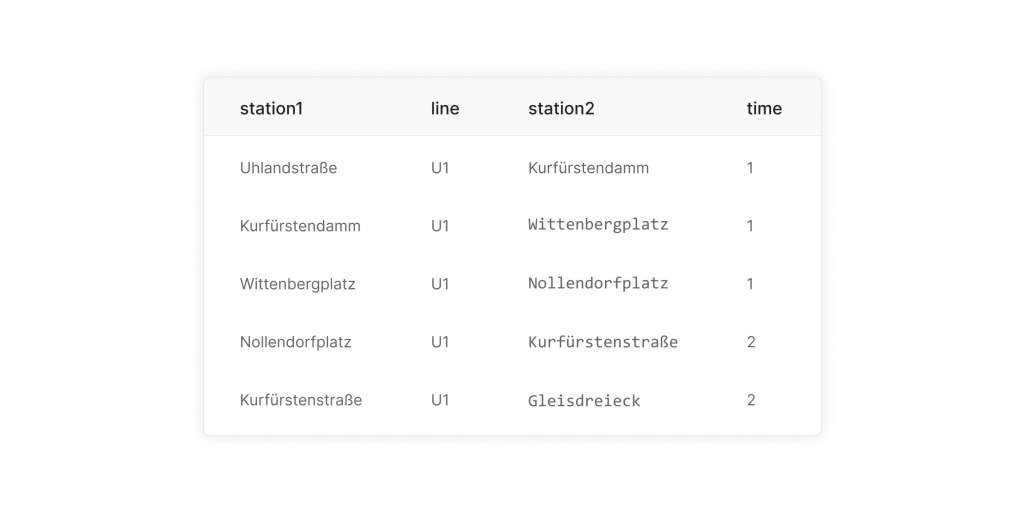
Файл berlin-stations.csv содержит информацию о каждой станции, включая ее название, широту, долготу и флаг, указывающий, является ли она конечной. Файл berlin-lines.csv описывает соединения между станциями, линии метро, к которым они принадлежат, и время в пути.
Чтобы гарантировать, что станции будут отображаться на карте, столбцы, содержащие географические долготу и широту, я назвал lng и lat.
Теперь, когда данные в порядке, пришло время перенести их в Memgraph. Чтобы получить данные об узлах (станциях метро) и связях (линиях метро) из файлов CSV в Memgraph, используйте оператор языка Cypher LOAD CSV. Вы можете скачать эти CSV-файлы или импортировать их прямо с сайта:
Неважно, какую линию вы выберете, вы окажетесь в одном и том же пункте назначения — в экземпляре Memgraph, загруженном данными берлинского метро.
Импорт данных о берлинском метро
Я решил использовать образ Docker с Memgraph Platform, поскольку в Memgraph Platform есть все, что мне нужно: база данных, алгоритмы и инструмент визуализации. Вы также можете использовать Memgraph Cloud. В этом случае вы можете импортировать данные только с помощью URL-адреса файла CSV. Если вы решите использовать образ Docker, оба метода, упомянутые ниже, допустимы.
Если вы впервые слышите о Docker, ознакомьтесь с первыми шагами по применению Docker на странице документации Memgraph. После того, как вы установили Docker, пришло время загрузить в Docker последнюю версию платформы Memgraph:
docker run -ti -p 3000:3000 -p 7687:7687 -p 7444:7444 --name berlin-subway memgraph/memgraph-platform:latestС помощью этой команды вы создадите Docker-контейнер с именем berlin-subway. Это облегчит копирование файлов в контейнер или остановку и запуск контейнера Docker. Возможно, сейчас не время говорить об остановке и просмотре контейнеров, но раз уж я затронул эту тему, вот как это делается. Чтобы остановить контейнер, выполните в терминале команду docker stop berlin-subway, а чтобы запустить его — docker start berlin-subway. Остановка и запуск контейнеров с помощью этих команд гарантирует, что вы всегда будете работать с контейнером с данными Берлина, а не создавать новый пустой контейнер.
Импортируйте данные в Memgraph
Чтобы загрузить данные прямо с веб-сайта Memgraph, вы можете использовать команду LOAD CSV с соответствующим URL. Запрос выглядит следующим так:
LOAD CSV FROM "https://public-assets.memgraph.com/berlin-subway/berlin-stations.csv" WITH HEADER AS row
CREATE (n:Station {name: row.station, lat: toFloat(row.lat), lng: toFloat(row.lng), end: toInteger(row.end )});
LOAD CSV FROM "https://public-assets.memgraph.com/berlin-subway/berlin-lines.csv" WITH HEADER AS row
MATCH (s1:Station {name: row.station1}), (s2:Station {name: row.station2})
CREATE (s1)-[:CONNECTED_VIA {line: row.line, time: ToInteger(row.time)}]->(s2);Если у вас нет подключения к интернету из вашего контейнера Docker, вы можете загрузить файлы CSV, содержащие информацию о станции метро и линиях. Загрузив их на свой локальный компьютер, используйте следующие команды Docker, чтобы скопировать их в соответствующий каталог в контейнере Memgraph:
docker cp berlin-stations.csv berlin-suwbay:/usr/lib/memgraph/berlin-stations.csv
docker cp berlin-lines.csv berlin-subway:/usr/lib/memgraph/berlin-lines.csvТеперь откройте Memgraph по адресу https://localhost:3000 и, чтобы получить данные в Memgraph, запустите следующий запрос на Cypher:
LOAD CSV FROM "/usr/lib/memgraph/berlin-stations.csv" WITH HEADER AS row
CREATE (n:Station {name: row.station, lat: toFloat(row.lat), lng: toFloat(row.lng), end: toInteger(row.end )});
LOAD CSV FROM "/usr/lib/memgraph/berlin-lines.csv" WITH HEADER AS row
MATCH (s1:Station {name: row.station1}), (s2:Station {name: row.station2})
CREATE (s1)-[:CONNECTED_VIA {line: row.line, time: ToInteger(row.time)}]->(s2);Визуализация данных в Memgraph Lab
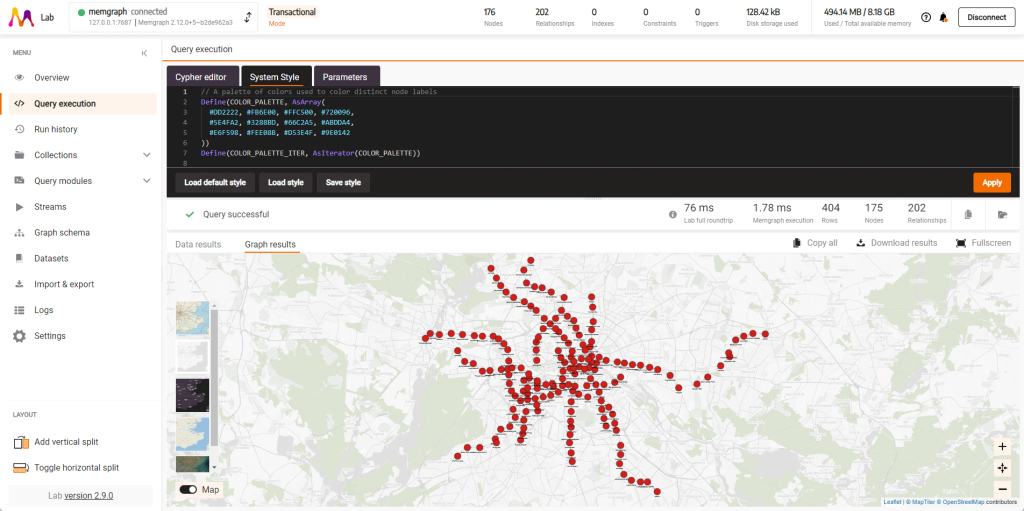
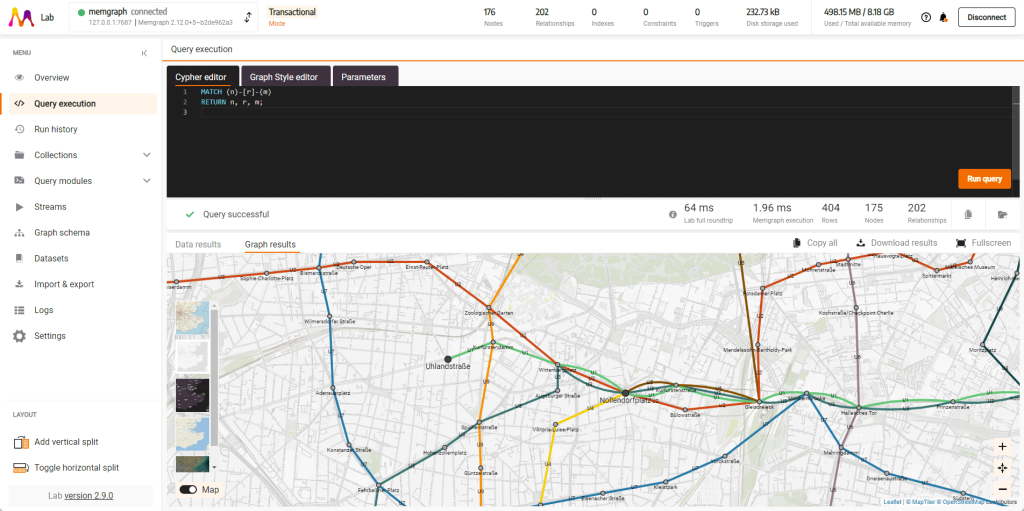
После успешного импорта данных перейдем к самой интересной части — визуализации! Начнем с простого. Чтобы увидеть все станции (узлы) и линии (отношения), выполните этот запрос:
MATCH (n)-[r]-(m)
RETURN n, r, m;Вы должны получить результат, подобный этому:
MATCH path = (s1:Station)-[r:CONNECTED_VIA {line: 'U1'}]->(s2:Station) RETURN path;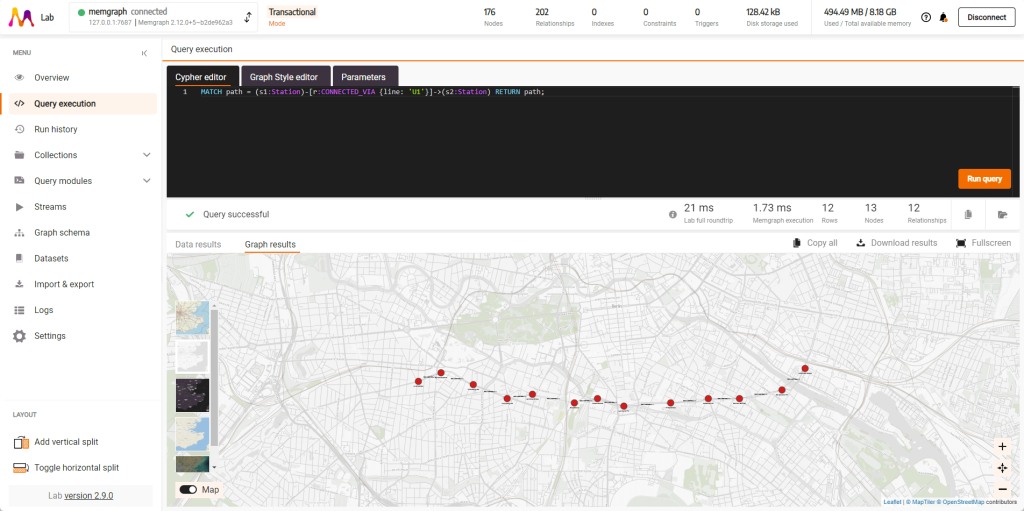
Если вы хотите увидеть две строки (U1 и U6) одновременно, выполните этот запрос:
MATCH path = (s1:Station)-[r1:CONNECTED_VIA {line: 'U1'}]->(s2:Station)
RETURN path
UNION
MATCH path = (s3:Station)-[r2:CONNECTED_VIA {line: 'U6'}]->(s4:Station)
RETURN path;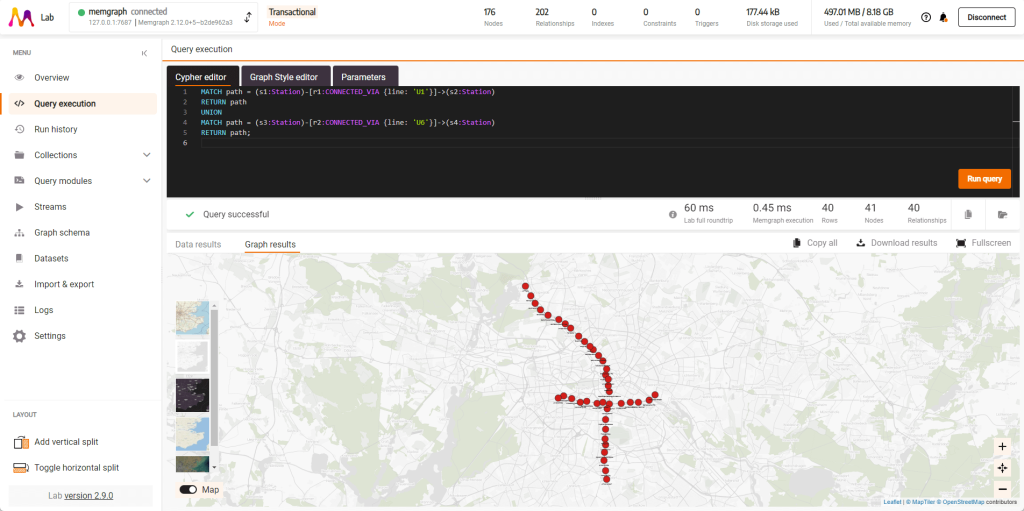
Если вы хотите узнать, какие станции общие у U1 и U6, запустите этот запрос:
MATCH (s:Station)-[r1:CONNECTED_VIA {line: 'U1'}]->(s2:Station),
(s)-[r2:CONNECTED_VIA {line: 'U2'}]->(s3:Station)
RETURN s;
Вы можете использовать алгоритмы, такие как взвешенный кратчайший путь:
MATCH path=(s1:Station {name: "Uhlandstraße"})-[:CONNECTED_VIA *WSHORTEST (r, n | r.time)]-(s2:Station {name: "Spittelmarkt"}) RETURN path;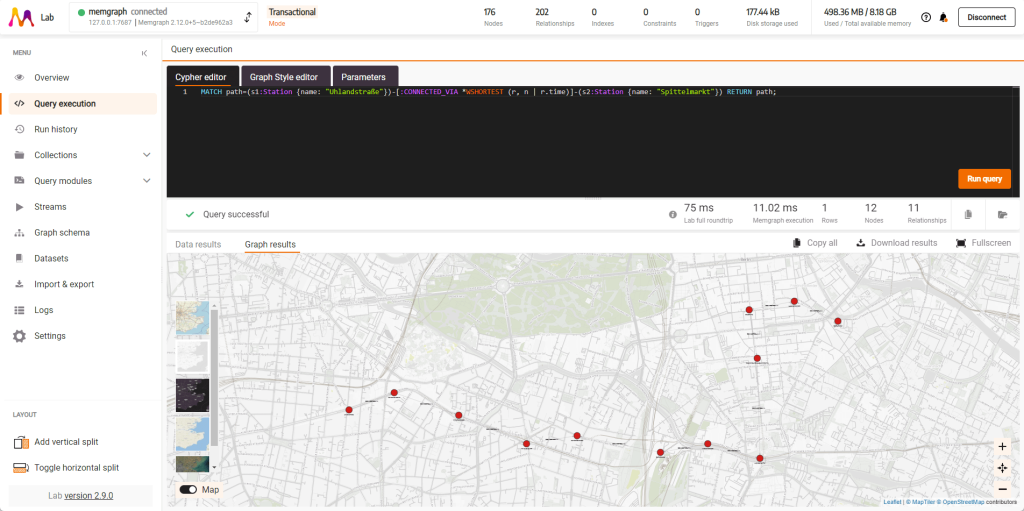
Если вы хотите узнать, какие станции находятся на расстоянии до двух пересадок от станции Штадтмитте, вы можете запустить этот запрос:
MATCH ({name: 'Stadtmitte'})-[:CONNECTED_VIA*1..2]-(n:Station)
RETURN n;Наверное, вы заметили, что станция Stadtmitte не показана на карте. Если хотите включить ее в карту, нужно немного изменить запрос:
MATCH (stadtmitte {name: 'Stadtmitte'}), path=(stadtmitte)-[:CONNECTED_VIA*1..2]-(n:Station)
RETURN stadtmitte, n;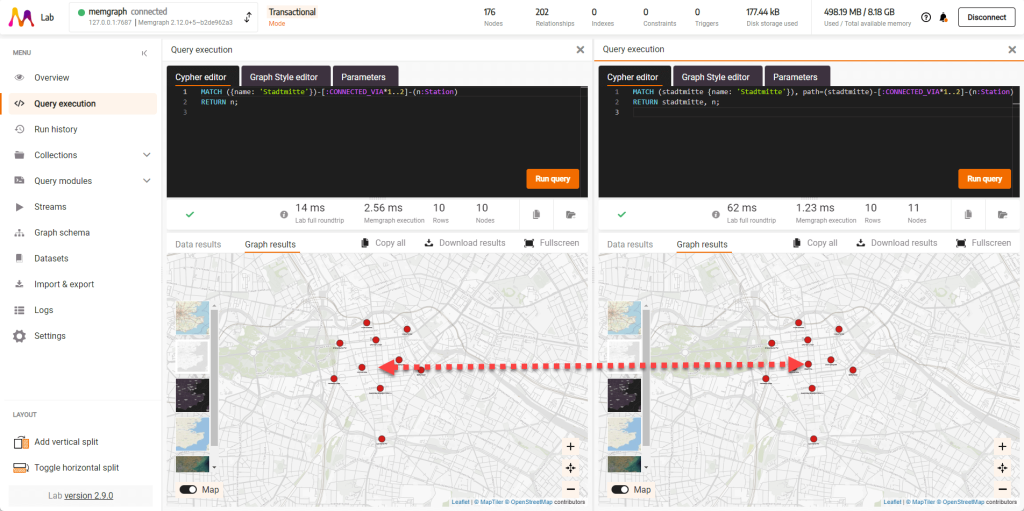
Стилизация графов
Приятно видеть данные на карте, но из-за такого большого количества разных линий может быть сложно увидеть соединение станций, которые вы ищете. Давайте исправим это, добавив к данным несколько цветов! Для начала убедимся, что все станции выглядят одинаково, кроме начальной и конечной: их мы сделаем немного больше. Откройте вкладку Graph Style editor. Как только вы нажмете на нее, имя вкладки изменится на имя используемого в данный момент стиля: System Style. Воспользуемся кодом GSS для оформления графов. Сначала сделайте так, чтобы все узлы были серыми (#aaaaaa) и с размером 4 пикселя, а метки имели размер 10. Для начальной и конечной станций используйте оттенок серого темнее (#444444). Они будут иметь размер 6 пикселей и размер метки 14 пикселей.
Теперь в качестве конца кода добавьте эти строки:
@NodeStyle {
border-color: #000000
border-width: 1
color: #aaaaaa
color-hover: #aaaaaa
color-selected: #aaaaaa
size: 4
font-size: 10
}
@NodeStyle Equals(Property(node, "end"), 1) {
border-color: #000000
border-width: 1
color: #444444
color-hover: #444444
color-selected: #444444
size: 6
font-size: 14
}
Пока мы в редакторе, добавим линиям немного цвета. На странице Википедии о берлинском метро я нашел значения цветов RAL для каждой из девяти линий, преобразовал их в значения RGB и присвоил цвета линиям.
@EdgeStyle {
label: Property(edge, "line")
width: 4
width-hover: 8
arrow-size: 0
font-size: 10
}
@EdgeStyle Equals(Property(edge, "line"), "U1") {
color: #50C878 /* RAL 6018 */
color-hover: #50C878
color-selected: #50C878
}
@EdgeStyle Equals(Property(edge, "line"), "U2") {
color: #D84B20 /* RAL 2002 */
color-hover: #D84B20
color-selected: #D84B20
}
@EdgeStyle Equals(Property(edge, "line"), "U3") {
color: #317873 /* RAL 6016 */
color-hover: #317873
color-selected: #317873
}
@EdgeStyle Equals(Property(edge, "line"), "U4") {
color: #FAD201 /* RAL 1023 */
color-hover: #FAD201
color-selected: #FAD201
}
@EdgeStyle Equals(Property(edge, "line"), "U5") {
color: #885000 /* RAL 8007 */
color-hover: #885000
color-selected: #885000
}
@EdgeStyle Equals(Property(edge, "line"), "U6") {
color: #9C7C8B /* RAL 4005 */
color-hover: #9C7C8B
color-selected: #9C7C8B
}
@EdgeStyle Equals(Property(edge, "line"), "U7") {
color: #007AA5 /* RAL 5012 */
color-hover: #007AA5
color-selected: #007AA5
}
@EdgeStyle Equals(Property(edge, "line"), "U8") {
color: #004547 /* RAL 5010 */
color-hover: #004547
color-selected: #004547
}
@EdgeStyle Equals(Property(edge, "line"), "U9") {
color: #FF9500 /* RAL 2003 */
color-hover: #FF9500
color-selected: #FF9500
}Сохраните стиль, а затем, чтобы увидеть результаты, выполните следующий запрос Cypher:
MATCH (n)-[r]-(m)
RETURN n, r, m;Выглядит неплохо.
Приятного программирования!
Читайте также:
- Сетка данных с точки зрения баз данных и на практике
- Alteryx - достойная платформа обработки данных?
- Инженерия геопространственных данных: пространственное индексирование
Читайте нас в Telegram, VK и Дзен
Перевод статьи Memgraph: Riding the Berlin subway: a Graph Database Adventure with Memgraph Lab




