
Введение: где может пригодиться пространственный индекс?
При работе с геоданными очень важно учитывать оптимизацию кода, который вы пишете. Как сделать так, чтобы наборы данных с сотнями миллионов строк быстрее агрегировались или соединялись? Здесь на помощь приходит такая концепция, как пространственное индексирование.
Я расскажу о том, как реализуется пространственный индекс, каковы его преимущества и ограничения, а также рассмотрю библиотеку индексирования с открытым исходным кодом H3 от компании Uber, предназначенную для приложений в области науки о пространственных данных.
Что такое пространственный индекс?
В конце некоторых книг можно найти указатель, который представляет собой список слов и мест, где они встречаются в тексте. Таким образом, вы быстро найдете любое упоминание интересующего вас слова в тексте. Без такого удобного инструмента пришлось бы вручную просматривать каждую страницу книги в поисках интересующего вас упоминания.
В контексте современных баз данных процессы запроса и поиска также очень актуальны. Индексирование часто ускоряет поиск данных (в отличие от той же фильтрации), причем индексы можно создавать на основе интересующего столбца. В частности, для оперирования геопространственными данными инженерам нередко требуются операции типа “пересечение” (intersection) или “находится рядом” (is nearby to). Как создать пространственный индекс, чтобы эти операции выполнялись максимально быстро? Для начала рассмотрим примеры геоданных:
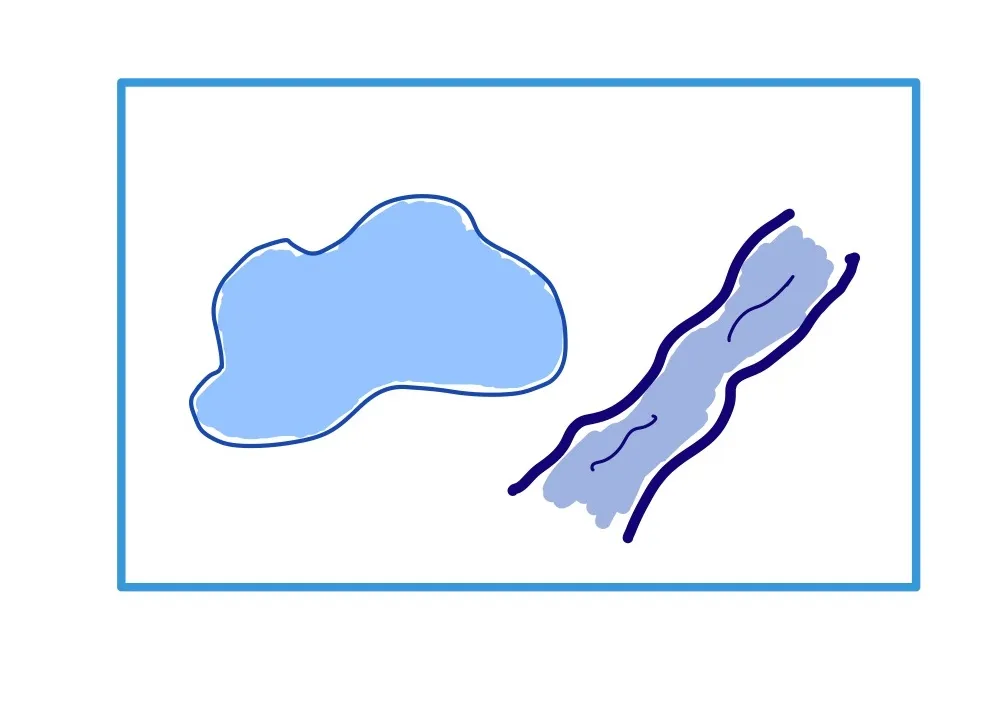
Допустим, мы хотим выполнить запрос, чтобы определить, пересекаются ли эти две фигуры. Конструкция пространственных баз данных позволяет создавать индекс с помощью ограничительной рамки, содержащей геометрию:
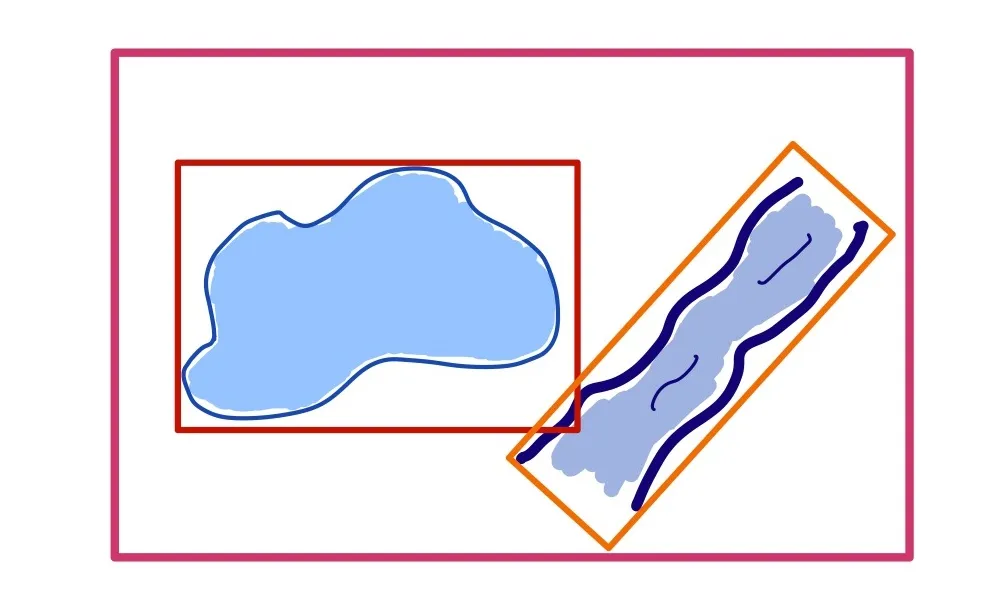
Чтобы дать ответ на вопрос, пересекаются ли эти два объекта, база данных сравнит, есть ли у двух ограничительных рамок общая область. Как видите, это может быстро привести к ложноположительным результатам. Для решения проблемы пространственные базы данных, такие как PostGIS, обычно разбивают большие ограничительные рамки на более мелкие:
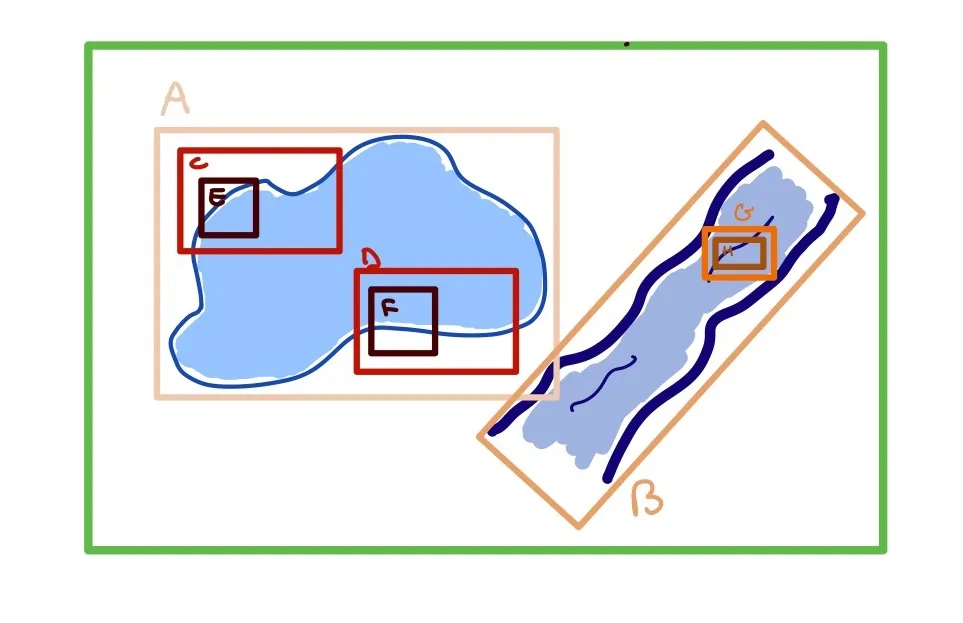
Эти мелкие части хранятся в R-деревьях. R-деревья представляют собой иерархическую структуру данных: в них хранятся данные о большой “родительской” ограничительной рамке, ее дочерних элементах, элементах дочерних элементов и так далее. Каждая родительская ограничительная рамка содержит дочерние ограничительные рамки:
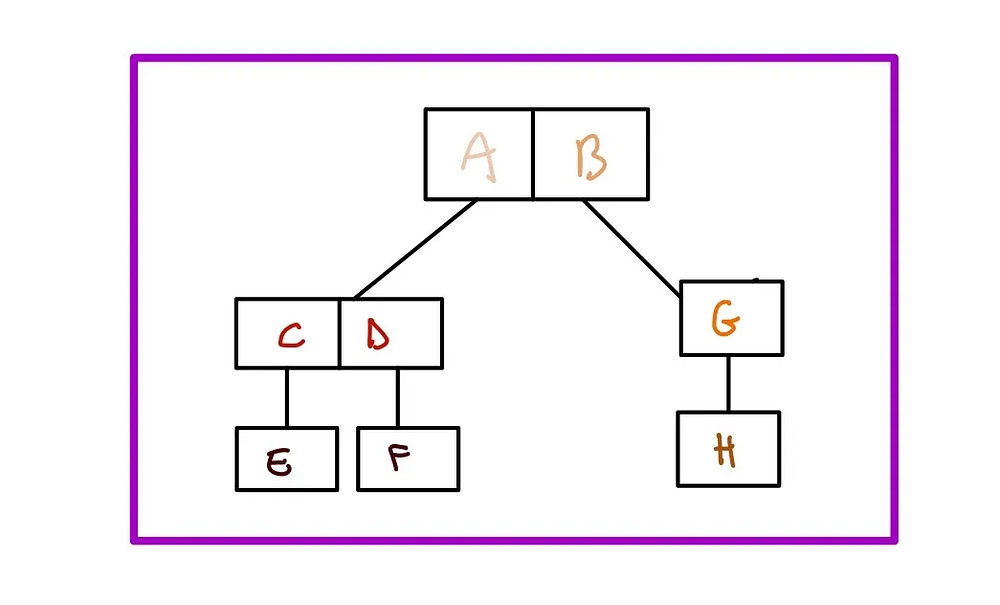
“Пересечение” является одной из ключевых операций, которая выигрывает от использования такой структуры. При запросе на пересечение база данных просматривает дерево и задает следующий вопрос: пересекает ли имеющаяся ограничительная рамка интересующий объект? Если да, то база просматривает дочерние элементы этой рамки и задает тот же вопрос. При этом она быстро проходит через дерево, пропуская ветви, не имеющие пересечения, и тем самым повышая производительность запроса. В конце концов, возвращается пересекающаяся геометрия, как и было задумано.
Переходим к практике: работа с пространственным индексом в GeoPandas
Теперь сравним на конкретном примере обычную построчную процедуру и применение пространственного индекса. Я буду использовать два набора данных: NYC’s Census Tracts (районы переписи населения Нью-Йорка) и City Facilities (городские объекты). Оба датасета имеют лицензию Open Data и доступны здесь и здесь.
Сначала опробуем операцию “пересечение” в GeoPandas на одной из геометрий Census Tract. Операция “пересечение” в GeoPandas — это построчная функция, которая проверяет каждую строку интересующего нас столбца на соответствие нашей геометрии и смотрит, пересекаются они или нет.
GeoPandas также предлагает операцию с применением пространственного индекса, использующую R-деревья и также позволяющую выполнять пересечения. Ниже приведено сравнение времени работы этих двух методов по результатам 100 прогонов операции пересечения. Примечание: поскольку функция пересечения по умолчанию работает медленно, я выбрал только около 100 геометрий из исходного набора данных.
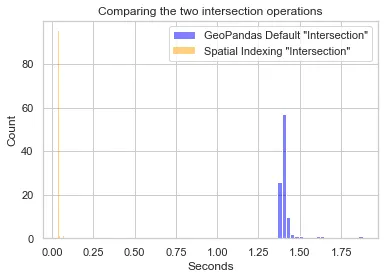
Подход с использованием пространственного индекса значительно превосходит по производительности ванильный метод пересечения. Вот 95% доверительных интервалов для времени работы каждого из этих способов:
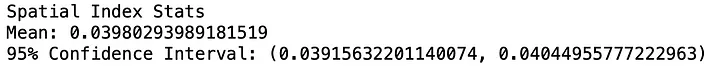
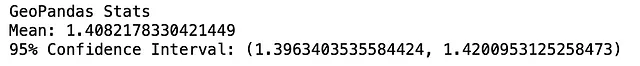
Отлично! Так почему же не использовать пространственное индексирование? Бывают ли случаи, когда оно не дает никаких преимуществ? Да, бывают. Отчасти это может быть связано со способом хранения листьев в данных, который наблюдается при пространственном индексировании. Оказывается, метод распределения необработанных данных влияет на то, как размещаются ограничительные рамки в R-дереве. В частности, если большая часть данных сосредоточена в одном географическом пространстве, то они будут иметь общих родителей и, следовательно, будут сгруппированы в одних и тех же ветвях. Это может привести к искаженным деревьям, что не позволит повысить оптимизацию при осуществлении запросов.
Как выглядят другие пространственные индексы?
Многие компании приспособили пространственные индексы для собственных нужд. Так, Uber использует H3 — гексагональную иерархическую систему индексирования, которая разбивает мир на шестиугольники равной площади. Шестиугольники обладают рядом преимуществ при моделировании передвижения людей по городу или при решении таких задач, как вычисление радиуса.
Геопространственные данные группируются по шестиугольникам, которые служат основной единицей анализа для компании. Сетка строится путем наложения 122 шестиугольных ячеек на проекцию икосаэдрической карты. Такая конструкция поддерживает широкий спектр функций, включая агрегирование, объединение и задействование приложений машинного обучения.
Эта система, а также многие ее функциональные возможности являются открытыми и доступны на GitHub для анализа. Одной из функций API H3 является преобразование точек широты и долготы в строки, представляющие уникальный шестиугольник в соответствии с заданным разрешением. Выполним эту операцию в отношении всей базы данных Facilities, а также преобразуем строки шестиугольников в многоугольники:
import h3
fac_db['h3'] = fac_db['geometry'].apply(lambda point: h3.geo_to_h3(lat = point.y, lng = point.x, resolution = 5))
h3_agency = fac_db.groupby(['h3', 'AGENCY'], as_index = False).count().sort_values('OBJECTID', ascending = False)
highest_agency = h3_agency.groupby('h3').first().reset_index()
highest_agency['geometries_h3'] = highest_agency['h3'].apply(lambda x: Polygon(h3.h3_to_geo_boundary(x, geo_json = True)))
При анализе пространственных данных часто возникает такой вопрос: сколько проектов в шестиугольниках классифицируется по какому-либо столбцу, например “agency” (“агентство”)? К счастью, это легко вычислить и наглядно представить, когда мы имеем данные, сгруппированные по H3-шестиугольникам:
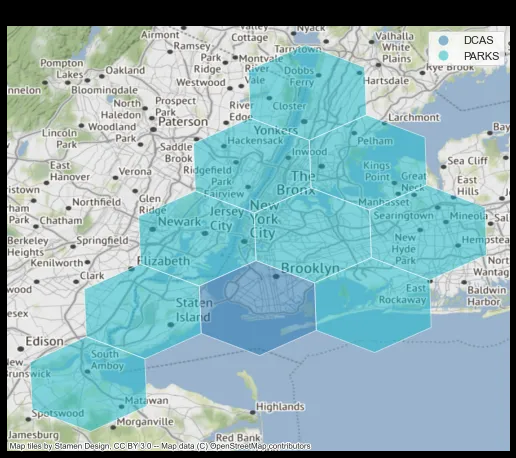
В данном случае видно, что наибольшее количество объектов на каждый шестиугольник приходится на DCAS (Department of Citywide Administrative Services, Департамент административных служб города) и PARKS (Department of Parks and Recreation, Департамент парков и зон отдыха). Вполне логично, поскольку эти два ведомства имеют больше физических объектов (например, административных зданий и зон отдыха, таких как парки).
Заключение
Как вы убедились, пространственные индексы — очень полезный инструмент оптимизации в сфере изучения и анализа геоданных. При выполнении простого запроса на пересечение использование пространственного индекса значительно улучшило производительность запроса по сравнению со стандартной функцией пересечения от GeoPandas. Реализация этого индекса связана со многими нюансами. Также необходимо помнить о последствиях, например о появлении огромных ветвей кластеризованных данных.
Как мы видели, компании разработали собственные решения. Один из примеров — индекс H3 с открытым исходным кодом от компании Uber, который позволяет отвечать на различные вопросы пространственного анализа. Хотя я продемонстрировал работу по подсчету объектов по агентствам, H3 служит основой и для других, более сложных задач машинного обучения.
Читайте также:
- Как овладеть наукой о геопространственных данных в 2023 году
- Kepler.gl — инструмент для визуализации геоданных на Python
- Как дата-аналитику стать дата-сайентистом в 2023 году
Читайте нас в Telegram, VK и Дзен
Перевод статьи Dea Bardhoshi: Geospatial Data Engineering: Spatial Indexing





