
Я очень хорошо помню, как еще несколько месяцев назад «Быстрое проектирование» было в центре внимания. Весь рынок труда был заполнен вакансиями промпт-инженеров, но это уже не так. Промпт-инжинириг не был каким-либо искусством или наукой, это был просто любопытный феномен Ганса: люди создавали необходимый контекст, чтобы система могла отвечать лучшим образом. Люди даже писали книги/блоги вроде «Топ-50 промптов, чтобы получить максимум от GPT» и так далее, и тому подобное. Но крупномасштабные эксперименты ясно показали, что единого промпта или стратегии, работающих для всех видов задач, не существует. Просто некоторые промпты по отдельности кажутся лучше, но при всестороннем анализе оказывается, что они срабатывают случайно.

Введение
Как я уже упоминал выше, интернет наполнен рекламными книгами и блогами. Некоторые из них действительно могут работать, но это не очень хороший способ создавать приложения. Не зная, когда что-то не работает, важно определить безопасное пространство гипотез, где система работает и не работает.
Есть даже работы, где показано, что при определенных эмоциональных промптах результативность LLM увеличивается. Что касается меня, у меня до сих пор есть сомнения относительно достоверности такой работы. Как долго держится метод? Это верно для каждой темы? Есть ли темы, где использование такого эмоционального промпта может привести к худшим результатам? Во многих подробных работах непреднамеренно выкладывают полусырые исследования. Еще одна подобная статья называлась «Угли авторегрессии». Позже была доказана ошибочность многих утверждений оттуда.

Но более серьезный вопрос заключается в том, каким научным/систематическим способом я должен сказать системе, что «Меня могут уволить, если ты сразу не сдашь ответ, или моя бабушка больна и так далее, и тому подобное». Люди просто случайным образом пытаются взломать поведение LLM.
Разбор проблемы промптинга
Например, когда я говорю «Пять раз добавь CoT (цепочку рассуждений) с помощью RAG (генерации, дополненной поиском), используя жесткие негативные примеры», концептуально это довольно ясно, но очень сложно реализовать на практике. LLM довольно чувствительны к промптам, поэтому использование такой структуры в промпте в большинстве случаев не работает. Поведение LLM очень чувствительно к тому, как написан промпт, и это затрудняет управление ими.
Итак, когда мы строим конвейер, я не только пытаюсь убедить LLM выдавать выходные данные определенным образом, но большая часть выходных данных должна быть ограничена так, чтобы они могли работать в качестве входных данных для других модулей в большем конвейере.
Для решения этой проблемы уже проводится множество исследований, но во многих отношениях они весьма ограничены. Большинство из них используют строковые шаблоны, которые хрупки и немасштабируемы. Языковая модель со временем меняется, и промпт ломается. Если мы захотим подключить наш модуль к другому конвейеру, это не сработает. Хочется, чтобы он взаимодействовал с новыми инструментами, новой базой данных или инструментом извлечения, но это не работает.
Это именно та проблема, которую DSPy стремится решить, рассматривая LLM как модуль, автоматически адаптируя его поведение в зависимости от того, как он взаимодействует с другими компонентами в конвейере.
Парадигма DSPy: давайте программировать, а не промптить языковые модели
Итак, цель DSPy — сместить фокус с настройки LLM на хороший комплексный дизайн системы.
Но как это сделать?
LLM можно представить как устройства, которые выполняют инструкции и работают через абстракцию, подобную глубокой нейронной сети.
Например, мы определяем слой свертки в PyTorch, и им можно управлять через набор входных данных, поступающих из других слоев. Концептуально можно объединить эти уровни и достичь желаемого уровня абстракции исходных входных данных, не нужно определять какое-либо ядро CUDA и множество других инструкций. Все это уже абстрагировано в определении слоя свертки. Это то, что мы хотим сделать с LLM, где LLM — это абстрактные модули, собранные в разные комбинации, чтобы достичь определенного типа поведения, будь то CoT, ReAct или что-то еще.
Чтобы получить желаемое поведение, нам нужно изменить несколько вещей:

Сигнатуры NLP — обработки естественного языка
Это просто декларации поведения, которого мы хотим от LLM. Она только определяет, чего необходимо достичь. Это не спецификация о том, как этого достигать. Она сообщает DSPy, что делает преобразование, а не как спрашивать LLM, чтобы добиться поведения.

- Сигнатура обрабатывает структурированное форматирование и логику синтаксического анализа.
- Сигнатуры можно компилировать в самосовершенствуемые и адаптируемые к конвейеру промпты или тонкие настройки.
DSPY определяет роль полей, используя:
- Их имена, например. DSPy будет использовать контекстное обучение для интерпретации вопросов не так, как ответов.
- Их трассировки (примеры ввода/вывода).
Примечание: Все это не запрограммировано жестко, но система определяет это во время соединения.
Модули
Здесь мы используем подписи для создания наших модулей, скажем, если мы хотим создать модуль CoT, то используем эти сигнатуры для его сборки. Что автоматически создает промпты высокого качества, достигающие поведения как от определенных методов промптинга.
Более техническое определение: модуль — это параметризованный слой, который выражает сигнатуру путем абстрагирования метода промптинга

После объявления модуль ведет себя как вызываемая функция.
Параметры. Чтобы выразить конкретную сигнатуру, любой вызов LLM нужно указать:
- Конкретную LLM, которую нужно вызвать.
- Инструкции промпта.
- Строковый префикс каждого поля сигнатуры.
- В демонстрациях использовались промпты для нескольких попыток и/или данные для тонкой настройки.
Оптимизаторы
Чтобы эта система работала, оптимизатор, по сути, берет весь конвейер, оптимизирует его по определенной метрике и в процессе автоматически выдает лучшие промпты. Более того, обновляются веса языковой модели.
Идея на высоком уровне абстракции заключается в том, что мы будем использовать оптимизатор для компиляции нашего кода, который выполняет вызовы языковой модели, чтобы каждый модуль в нашем конвейере оптимизировался в промпт, автоматически генерируемый для нас. Или оптимизировался в новый точно настроенный набор весов для нашей языковой модели, соответствующей нашей задаче.
Практический пример
Для сложных задач контроля качества одного поискового запроса часто бывает недостаточно. Пример в HotPotQA содержит вопрос о городе рождения автора Right Back At It Again. Поисковый запрос часто правильно идентифицирует автора как Джереми Маккиннона, но не позволяет составить предполагаемый ответ в плане определения, когда он родился.
Стандартный подход к решению этой задачи в литературе по дополненной поиском NLP — создать многошаговые поисковые системы, такие как у GoldEn (Qi et al., 2019) и Baleen (Khattab et al., 2021). Прежде чем прийти к окончательному ответу, эти системы считывают полученные результаты, а затем при необходимости генерируют дополнительные запросы для сбора дополнительной информации. При помощи DSPy, можно легко смоделировать такие системы в несколько строк кода.
В настоящее время, чтобы добиться этого, нужно писать очень сложные промпты и очень запутанно их структурировать. Плохо то, что как только я изменю тип вопросов, мне, возможно, придется полностью изменить дизайн системы. Но не с DSPy.
Настройка языковой модели и модели извлечения данных
import dspy
turbo = dspy.OpenAI(model='gpt-3.5-turbo')
colbertv2_wiki17_abstracts = dspy.ColBERTv2(url='http://20.102.90.50:2017/wiki17_abstracts')
dspy.settings.configure(lm=turbo, rm=colbertv2_wiki17_abstracts)Загрузка набора данных
Используем упомянутый набор данных HotPotQA — набор сложных пар вопрос-ответ, на которые обычно отвечают в стиле многошагового поиска. Загрузить этот предоставленный DSPy набор данных можно через класс HotPotQA:
from dspy.datasets import HotPotQA
# Загружаем набор данных
dataset = HotPotQA(train_seed=1, train_size=20, eval_seed=2023, dev_size=50, test_size=0)
# Сообщаем DSPy, что поле question является входными данными. Любые другие поля — метки и/или метаданные.
trainset = [x.with_inputs('question') for x in dataset.train]
devset = [x.with_inputs('question') for x in dataset.dev]
len(trainset), len(devset)
#Вывод
(20, 50)Построение сигнатуры
Теперь, когда у нас есть загруженные данные, начнем определять сигнатуры для подзадач конвейера Baleen.
Начнем с создания сигнатуры GenerateAnswer, которая будет принимать context и question в качестве входных данных и давать answer в качестве входных данных.
class GenerateAnswer(dspy.Signature):
"""Ответ на вопрос краткими фактами."""
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
answer = dspy.OutputField(desc="often between 1 and 5 words")
class GenerateSearchQuery(dspy.Signature):
"""Написание простого поискового запроса, который поможет ответить на сложный вопрос."""
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
query = dspy.OutputField()Построение конвейера
Определим саму программу SimplifiedBaeen. Есть много возможных способов реализовать ее, мы ограничим эту версию ключевыми элементами.
from dsp.utils import deduplicate
class SimplifiedBaleen(dspy.Module):
def __init__(self, passages_per_hop=3, max_hops=2):
super().__init__()
self.generate_query = [dspy.ChainOfThought(GenerateSearchQuery) for _ in range(max_hops)]
self.retrieve = dspy.Retrieve(k=passages_per_hop)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
self.max_hops = max_hops
def forward(self, question):
context = []
for hop in range(self.max_hops):
query = self.generate_query[hop](context=context, question=question).query
passages = self.retrieve(query).passages
context = deduplicate(context + passages)
pred = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=pred.answer)Как видите, метод __init__ определяет несколько ключевых подмодулей:
generate_query: для каждого перехода у нас будет один предикторdspy.ChainOfThoughtс сигнатуройGenerateSearchQuery.retrieve: этот модуль с помощью модуляdspy.Retieveсгенерировалрированных запросов будет выполнять поиск по нашему поисковому индексу, определенному ColBERT RM.generate_answer: чтобы получить окончательный ответ, будет использоваться модульdspy.Predictс сигнатуройGenerateAnswer.
Метод forward использует эти подмодули в простом потоке управления.
- Сначала выполняет цикл
self.max_hopsраз. - На каждой итерации генерирует поисковый запрос с предиктором
self.generate_query[hop]. - Используя этот запрос, получает топ-k отрывков.
- Добавляет (дедуплицированные) отрывки в наш аккумулятор
context. - Чтобы получить ответ, после цикла использует
self.generate_answer. - Возвращает прогноз с полученным
contextи предсказаннымanswer.
Выполнение конвейера
Выполним эту программу в ее первой — zero-shot — или же некомпилированной настройке.
Это не обязательно означает, что производительность будет плохой, скорее это означает, что мы напрямую ограничены надежностью языковой модели под капотом, ее пониманием наших подзадач из минимума инструкций. Зачастую это вполне нормально при использовании самых дорогих/мощных моделей (например, GPT-4) для самых простых и стандартных задач (например, ответов на простые вопросы о распространенных сущностях).
# Спрашиваем любой интересующий вас вопрос в этой простой программе RAG.
my_question = "How many storeys are in the castle that David Gregory inherited?"
# Получаем предсказание. Оно содержит `pred.context` и `pred.answer`..
uncompiled_baleen = SimplifiedBaleen() # uncompiled (i.e., zero-shot) program
pred = uncompiled_baleen(my_question)
# Выводим контексты и ответ.
print(f"Question: {my_question}")
print(f"Predicted Answer: {pred.answer}")
print(f"Retrieved Contexts (truncated): {[c[:200] + '...' for c in pred.context]}")
#Вывод
Question: How many storeys are in the castle that David Gregory inherited?
Predicted Answer: five
Retrieved Contexts (truncated): ['David Gregory (physician) | David Gregory (20 December 1625 – 1720) was a Scottish physician and inventor. His surname is sometimes spelt as Gregorie, the original Scottish spelling. He inherited Kinn...', 'The Boleyn Inheritance | The Boleyn Inheritance is a novel by British author Philippa Gregory which was first published in 2006. It is a direct sequel to her previous novel "The Other Boleyn Girl," an...', 'Gregory of Gaeta | Gregory was the Duke of Gaeta from 963 until his death. He was the second son of Docibilis II of Gaeta and his wife Orania. He succeeded his brother John II, who had left only daugh...', 'Kinnairdy Castle | Kinnairdy Castle is a tower house, having five storeys and a garret, two miles south of Aberchirder, Aberdeenshire, Scotland. The alternative name is Old Kinnairdy....', 'Kinnaird Head | Kinnaird Head (Scottish Gaelic: "An Ceann Àrd" , "high headland") is a headland projecting into the North Sea, within the town of Fraserburgh, Aberdeenshire on the east coast of Scotla...', 'Kinnaird Castle, Brechin | Kinnaird Castle is a 15th-century castle in Angus, Scotland. The castle has been home to the Carnegie family, the Earl of Southesk, for more than 600 years....']Оптимизация конвейера
Однако подход без попыток быстро оказывается неэффективным для более специализированных задач, новых доменов/настроек и более эффективных (или открытых) моделей. Чтобы решить эту проблему, DSPy предлагает компиляцию. Скомпилируем нашу многошаговую программу (SimplifiedBaleen).
Сначала определим логику проверки для компиляции:
- Прогнозируемый ответ соответствует золотому ответу.
- Полученный контекст содержит золотой ответ.
- Ни один из сгенерированных запросов не хаотичен. То есть не превышает длину в 100 символов.
- Ни один из сгенерированных запросов не повторяется приблизительно. То есть не находится в пределах 0,8 или выше оценки F1 от предыдущих запросов.
def validate_context_and_answer_and_hops(example, pred, trace=None):
if not dspy.evaluate.answer_exact_match(example, pred): return False
if not dspy.evaluate.answer_passage_match(example, pred): return False
hops = [example.question] + [outputs.query for *_, outputs in trace if 'query' in outputs]
if max([len(h) for h in hops]) > 100: return False
if any(dspy.evaluate.answer_exact_match_str(hops[idx], hops[:idx], frac=0.8) for idx in range(2, len(hops))): return False
return TrueЧтобы оптимизировать предикторы в конвейере с помощью примеров с несколькими попытками, будем использовать один из самых простых teleprompter в DSPy, а именно BootstrapFewShot.
from dspy.teleprompt import BootstrapFewShot
teleprompter = BootstrapFewShot(metric=validate_context_and_answer_and_hops)
compiled_baleen = teleprompter.compile(SimplifiedBaleen(), teacher=SimplifiedBaleen(passages_per_hop=2), trainset=trainset)Оценка конвейера
Теперь определим функцию оценки и сравним производительность компилированных и некомпилированных конвейеров Baleen. Хотя этот набор данных не является полностью надежным эталоном, его полезно применить в этом руководстве.
from dspy.evaluate.evaluate import Evaluate
# Определяем метрику проверки того, получили ли мы подходящие документы
def gold_passages_retrieved(example, pred, trace=None):
gold_titles = set(map(dspy.evaluate.normalize_text, example["gold_titles"]))
found_titles = set(
map(dspy.evaluate.normalize_text, [c.split(" | ")[0] for c in pred.context])
)
return gold_titles.issubset(found_titles)
# Настроим функцию `evaluate_on_hotpotqa`. Ниже будем много раз использовать ее.
evaluate_on_hotpotqa = Evaluate(devset=devset, num_threads=1, display_progress=True, display_table=5)
uncompiled_baleen_retrieval_score = evaluate_on_hotpotqa(uncompiled_baleen, metric=gold_passages_retrieved, display=False)
compiled_baleen_retrieval_score = evaluate_on_hotpotqa(compiled_baleen, metric=gold_passages_retrieved)
print(f"## Retrieval Score for uncompiled Baleen: {uncompiled_baleen_retrieval_score}")
print(f"## Retrieval Score for compiled Baleen: {compiled_baleen_retrieval_score}")
#Вывод
## Retrieval Score for uncompiled Baleen: 36.0
## Retrieval Score for compiled Baleen: 60.0Заключение
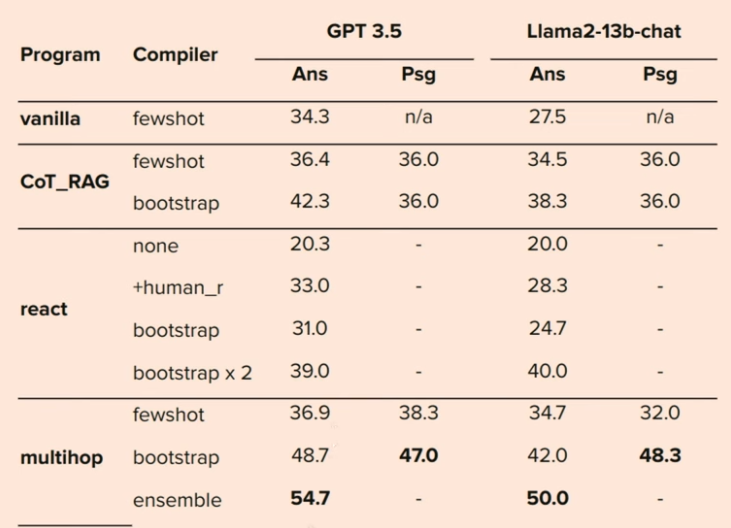
Эти результаты показывают, что сочетание настроек многошаговости в DSPy может даже превзойти отзывы от людей. Более того, они показали, что даже гораздо меньшая модель, такая как T5, при использовании в обстоятельствах с DSPy сравнивалась с GPT. Библиотека DSPy — одна из самых крутых, с которыми я столкнулся после выпуска LangChain. Она многое обещает в плане создания гораздо лучшей системы, спроектированной систематически, а не в беспорядочном включении по кусочку в большой конвейер LLM.
Читайте также:
Читайте нас в Telegram, VK и Дзен
Перевод статьи Vishal Rajput: Prompt Engineering Is Dead: DSPy Is New Paradigm For Prompting





