
Цель статьи — сравнить различные библиотеки с открытым исходным кодом, предназначенные для вывода в производственную среду и обслуживания LLM. Рассмотрим их преимущества и недостатки на примерах развертывания в реальном мире. В список упоминаемых здесь фреймворков вошли vLLM, Text Generation Inference, OpenLLM, Ray Serve и другие.
Дисклеймер: информация актуальна по состоянию на август 2023 года, однако следует иметь в виду, что в дальнейшем возможны изменения и дополнения.
Краткое резюме
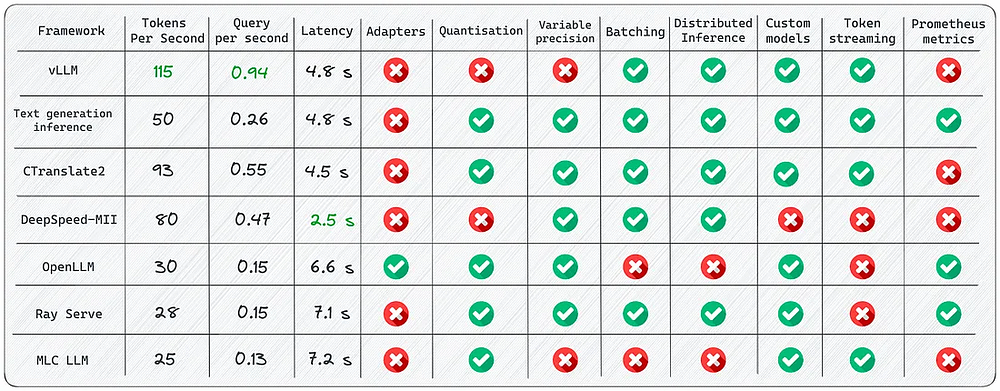
Несмотря на обилие фреймворков для вывода в производственную среду LLM, каждый из них служит конкретной цели. Вот некоторые ключевые моменты, на которые следует обратить внимание.
- Используйте vLLM , когда требуется максимальная скорость для пакетной оперативной доставки.
- Если вам нужна встроенная поддержка HuggingFace и вы не планируете использовать несколько адаптеров для базовой модели, то лучше выбрать Text Generation Inference.
- Рассмотрите вариант CTranslate2, если для вас важна скорость и вы планируете выполнять вывод на центральном процессоре.
- Выберите OpenLLM, если хотите подключить адаптеры к основной модели и использовать HuggingFace Agents, особенно если не полагаетесь только на PyTorch.
- Рассмотрите вариант Ray Serve для стабильного конвейера и гибкого развертывания. Он лучше всего подходит для более зрелых проектов.
- Используйте MLC LLM, если хотите развернуть LLM на стороне клиента (edge computing, периферийные вычисления), например на платформах Android или iPhone.
- Используйте DeepSpeed-MII, если уже имеете опыт работы с библиотекой DeepSpeed и хотите продолжать использовать ее для развертывания LLM.
Если эти библиотеки привлекли ваше внимание, приглашаю вас углубиться и изучить их более подробно.
Для аппаратной настройки я использовал один графический процессор A100 с объемом памяти 40 Гбайт. В качестве модели применял LLaMA-1 13b, так как она поддерживается всеми библиотеками из приведенного выше списка.
В статье не будут рассматриваться традиционные библиотеки для поддержания моделей глубокого обучения, такие как TorchServe, KServe и Triton Inference Server. Хотя с помощью этих библиотек и можно выводить LLM, я сосредоточился только на фреймворках, явно предназначенных для работы с LLM.
1. vLLM

vLLM — быстрая и простая в использовании библиотека для вывода и поддержания LLM. Достигается 14-кратное — 24-кратное увеличение производительности по сравнению с HuggingFace Transformers (HF) и 2,2-кратное — 2,5-кратное по сравнению с HuggingFace Text Generation Inference (TGI).
Использование
Пакетный вывод в режиме оффлайн:
# pip install vllm
from vllm import LLM, SamplingParams
prompts = [
"Funniest joke ever:",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.95, top_p=0.95, max_tokens=200)
llm = LLM(model="huggyllama/llama-13b")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
API-сервер:
# Запуск сервера:
python -m vllm.entrypoints.api_server --env MODEL_NAME=huggyllama/llama-13b
# Запрос к модели из оболочки:
curl http://localhost:8000/generate \
-d '{
"prompt": "Funniest joke ever:",
"n": 1,
"temperature": 0.95,
"max_tokens": 200
}'
Основные возможности
- Непрерывное пакетное выполнение — планирование на уровне итераций, при котором размер пакета определяется на каждой итерации. Благодаря пакетной обработке vLLM может хорошо работать при высоком уровне загрузки запросами.
- PagedAttention — алгоритм внимания, вдохновленный классическими идеями виртуальной памяти и разбивки памяти на страницы в операционных системах. Эта уникальная особенность обеспечивает ускорение модели.
Преимущества
- Скорость генерации текста. Я провел несколько экспериментов с этой библиотекой и был восхищен результатами. На данный момент вывод с использованием vLLM является самым быстрым из всех возможных вариантов.
- Высокая производительность. Оснащение различными алгоритмами декодирования, включая параллельную выборку, лучевой поиск и др.
- OpenAI-совместимый API-сервер. Если вы использовали API OpenAI, вам нужно будет просто подставить URL конечной точки.
Ограничения
- Добавление пользовательских моделей. Несмотря на возможность добавления собственной модели, процесс усложняется, если модель не использует архитектуру, аналогичную существующей модели в vLLM. Например, я столкнулся с запросом на включение изменений при добавлении поддержки Falcon, что оказалось довольно сложным.
- Отсутствие поддержки адаптеров (LoRA, QLoRA и т. д.). LLM с открытым исходным кодом имеют значительную ценность при тонкой настройке под конкретные задачи. Однако в текущей реализации отсутствует возможность раздельного использования весов модели и адаптера, что ограничивает гибкость эффективного использования таких моделей.
- Отсутствие квантования веса. В некоторых случаях модели может не хватить доступной памяти GPU, поэтому приходится уменьшать потребление памяти.
Это самая быстрая библиотека для вывода LLM. Благодаря внутренним оптимизациям она значительно превосходит своих конкурентов. Тем не менее ее недостатком является поддержка ограниченного числа моделей.
С дорожной картой развития vLLM можно ознакомиться здесь.
2. Text Generation Inference

Text Generation Inference — сервер для вывода текстов, написанных на Rust, Python и gRPC. Используется в производстве в HuggingFace для управления виджетами API-вывода LLM.
Использование
Запуск веб-сервера с помощью docker:
mkdir data
docker run --gpus all --shm-size 1g -p 8080:80 \
-v data:/data ghcr.io/huggingface/text-generation-inference:0.9 \
--model-id huggyllama/llama-13b \
--num-shard 1
Создание запросов:
# pip install text-generation
from text_generation import Client
client = Client("http://127.0.0.1:8080")
prompt = "Funniest joke ever:"
print(client.generate(prompt, max_new_tokens=17 temperature=0.95).generated_text)
Основные возможности
- Встроенные метрики Prometheus — можно отслеживать нагрузку на сервер и получать информацию о его производительности.
- Оптимизированный код трансформаторов для выводов с использованием flash-attention (и v2) и Paged Attention. Важно отметить, что не все модели имеют встроенную поддержку этих оптимизаций. При работе с менее распространенной архитектурой могут возникнуть проблемы.
Преимущества
- Все зависимости устанавливаются в Docker. Вы сразу получаете готовую среду, которая обязательно будет работать на вашей машине.
- Нативная поддержка моделей от HuggingFace. Легко запустить собственную модель или использовать любую из HuggingFace Model Hub.
- Контроль над выводом модели. Фреймворк предлагает широкий набор опций для управления выводом модели, включая настройку точности, квантование, тензорный параллелизм, штраф за повторение и многое другое.
Ограничения
- Отсутствие поддержки адаптеров. Важно отметить, что, хотя развертывание LLM с помощью адаптера возможно (рекомендую обратиться к этому видео), официальной поддержки и соответствующей документации на данный момент нет.
- Необходимость компиляции из исходных текстов (Rust + ядро CUDA). Я ценю Rust, но не все DS-команды адаптированы к нему, что может затруднить внесение пользовательских изменений в библиотеку.
- Неполная документация. Вся информация доступна в README проекта. И хотя в нем описаны основные моменты, я сталкивался с ситуациями, когда приходилось искать дополнительные сведения о проблемах или исходном коде (сложнее всего было при работе с Rust).
Я считаю, что это одна из наиболее конкурентоспособных библиотек. Она хорошо написана, что минимизирует проблемы при развертывании модели. Если вы хотите получить нативную интеграцию с HuggingFace, вам определенно стоит рассмотреть этот вариант библиотеки. Обратите внимание, что команда проекта недавно изменила лицензию.
С дорожной картой развития TGI можно ознакомиться здесь.
3. CTranslate2

CTranslate2 — это библиотека, написанная на языках C++ и Python, для эффективного вывода данных с помощью моделей-трансформеров.
Использование
Начинаем с конвертирования модели:
pip install -qqq transformers ctranslate2
# Сначала модель должна быть преобразована в формат модели CTranslate2:
ct2-transformers-converter --model huggyllama/llama-13b --output_dir llama-13b-ct2 --force
Создание запросов:
import ctranslate2
import transformers
generator = ctranslate2.Generator("llama-13b-ct2", device="cuda", compute_type="float16")
tokenizer = transformers.AutoTokenizer.from_pretrained("huggyllama/llama-13b")
prompt = "Funniest joke ever:"
tokens = tokenizer.convert_ids_to_tokens(tokenizer.encode(prompt))
results = generator.generate_batch(
[tokens],
sampling_topk=1,
max_length=200,
)
tokens = results[0].sequences_ids[0]
output = tokenizer.decode(tokens)
print(output)
Основные возможности
- Быстрое и эффективное выполнение на CPU и GPU. Благодаря встроенному набору оптимизаций, включая слияние слоев, удаление паддинга, переупорядочивание пакетов, операции in-place, механизм кэширования, вывод LLM выполняется быстрее и требует меньше памяти.
- Динамическое использование памяти. Благодаря кэширующим аллокаторам на CPU и GPU, использование памяти динамически изменяется в зависимости от размера запроса, сохраняя при этом требования к производительности.
- Поддержка нескольких CPU-архитектур. Проект поддерживает процессоры x86–64 и AArch64/ARM64 и интегрирует несколько бэкендов, оптимизированных для таких платформ, как Intel MKL, oneDNN, OpenBLAS, Ruy и Apple Accelerate.
Преимущества
- Параллельное и асинхронное выполнение. Несколько пакетов могут обрабатываться параллельно и асинхронно с использованием GPU или ядер CPU.
- Кэширование промптов. Модель запускается один раз на статическом промпте, состояние модели кэшируется и повторно используется при последующих обращениях к тому же статическому промпту.
- Малый вес на диске. Квантование позволяет уменьшить размер моделей на диске в 4 раза с минимальной потерей точности.
Ограничения
- Отсутствие встроенного REST-сервера. Несмотря на возможность запуска REST-сервера, мне не хватало готового сервиса с возможностью логирования и мониторинга.
- Отсутствие поддержки адаптеров (LoRA, QLoRA и т. д.).
Я нахожу эту библиотеку интересной. Разработчики активно работают над ней, что видно по релизам и коммитам на GitHub, а также делятся информативными постами в блоге по поводу ее применения. Многочисленные оптимизации библиотеки впечатляют, главной же ее изюминкой является возможность выполнять LLM-вывод на CPU.
4. DeepSpeed-MII

Благодаря DeepSpeed, MII обеспечивает вывод данных с низкой задержкой и высокой производительностью.
Использование
Запуск веб-сервера:
# НЕ УСТАНАВЛИВАЙТЕ с помощью pip install deepspeed-mii
# git-клон https://github.com/microsoft/DeepSpeed-MII.git
# git reset --hard 60a85dc3da5bac3bcefa8824175f8646a0f12203
# cd DeepSpeed-MII && pip install .
# pip3 install -U deepspeed
# ... и убедитесь в том, что версии CUDA одинаковы:
# python -c "import torch;print(torch.version.cuda)" == nvcc --version
import mii
mii_configs = {
"dtype": "fp16",
'max_tokens': 200,
'tensor_parallel': 1,
"enable_load_balancing": False
}
mii.deploy(task="text-generation",
model="huggyllama/llama-13b",
deployment_name="llama_13b_deployment",
mii_config=mii_configs)
Создание запросов:
import mii
generator = mii.mii_query_handle("llama_13b_deployment")
result = generator.query(
{"query": ["Funniest joke ever:"]},
do_sample=True,
max_new_tokens=200
)
print(result)
Основные особенности
- Балансировка нагрузки на нескольких репликах. Очень полезный инструмент для работы с большим количеством пользователей. Средство балансировки нагрузки эффективно распределяет входящие запросы между различными репликами, что приводит к оптимизации времени отклика приложения.
- Временное развертывание. Подход, при котором обновления не применяются постоянно к целевой среде. Это ценный выбор в сценариях, где важны эффективность использования ресурсов, безопасность, согласованность и простота управления. Он обеспечивает более контролируемую и стандартизированную среду при одновременном снижении операционных затрат.
Преимущества
- Различные репозитории моделей. Доступ через несколько репозиториев моделей с открытым исходным кодом, таких как Hugging Face, FairSeq, EluetherAI и т. д.
- Количественная оценка задержки и снижение затрат. MII может значительно снизить стоимость вывода очень дорогих языковых моделей.
- Интеграция с Native и Azure. Фреймворк MII, разработанный компанией Microsoft, обеспечивает отличную интеграцию с облачной системой.
Ограничения
- Отсутствие официальных релизов. Мне потребовалось несколько часов, чтобы найти нужный коммит с функциональным приложением. Некоторые страницы документации устарели и более не актуальны.
- Ограниченное количество моделей. Отсутствует поддержка Falcon, LLaMA 2 и других языковых моделей. Доступно лишь ограниченное количество моделей, которые вы можете запустить.
- Отсутствие поддержки адаптеров (LoRa, QLoRA и т. д.).
Проект основан на надежной библиотеке DeepSpeed, которая заслужила доверие в сообществе. Если вы стремитесь к стабильности и проверенным решениям, MII станет отличным вариантом. Судя по моим экспериментам, библиотека демонстрирует наилучшую скорость обработки одного запроса. Тем не менее я советую протестировать фреймворк на конкретных задачах, прежде чем внедрять его в систему.
5. OpenLLM

OpenLLM — это открытая платформа для работы с большими языковыми моделями (LLM) в производственной среде.
Использование
Запуск веб-сервера:
pip install openllm scipy
openllm start llama --model-id huggyllama/llama-13b \
--max-new-tokens 200 \
--temperature 0.95 \
--api-workers 1 \
--workers-per-resource 1
Создание запросов:
import openllm
client = openllm.client.HTTPClient('http://localhost:3000')
print(client.query("Funniest joke ever:"))
Основные особенности
- Поддержка адаптеров. Предполагает подключение нескольких адаптеров к одной развернутой LLM. Только представьте: у вас есть возможность использовать всего одну модель для нескольких специализированных задач.
- Реализация различных сред выполнения. Доступны такие реализации, как Pytorch (
pt), Tensorflow (tf) и Flax (flax). - Агенты HuggingFace. Привязка различных моделей к HuggingFace и управление ими с помощью LLM и естественного языка.
Преимущества
- Стабильная поддержка комьюнити. Библиотека постоянно развивается и пополняется новыми функциями.
- Возможность интегрирования новой модели. Разработчики предусмотрели руководство по добавлению собственной модели.
- Квантование. OpenLLM поддерживает квантование с помощью bitsandbytes и GPTQ.
- Интеграция с LangChain. Можно взаимодействовать с удаленным сервером OpenLLM с помощью LangChian.
Ограничения
- Отсутствие поддержки пакетной обработки. При значительном потоке сообщений это может стать узким местом в производительности приложения.
- Отсутствие встроенного распределенного вывода. При запуске больших моделей на нескольких GPU-устройствах придется дополнительно устанавливать Yatai — поддерживающий компонент OpenLLM.
Это хороший фреймворк с широким спектром функций. Он позволит создать гибкое приложение с минимальными затратами. Учитывая, что некоторые аспекты не полностью описаны в документации, в процессе ознакомления с библиотекой вас могут ждать приятные сюрпризы в плане открытия ее дополнительных возможностей.
6. Ray Serve

Ray Serve — это масштабируемая библиотека для создания API вывода в режиме онлайн. Serve не зависит от фреймворков, поэтому вы можете использовать один инструментарий для обслуживания любых моделей глубокого обучения.
Использование
Запуск веб-сервера:
# pip install ray[serve] accelerate>=0.16.0 transformers>=4.26.0 torch starlette pandas
# ray_serve.py
import pandas as pd
import ray
from ray import serve
from starlette.requests import Request
@serve.deployment(ray_actor_options={"num_gpus": 1})
class PredictDeployment:
def __init__(self, model_id: str):
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
self.model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
)
self.tokenizer = AutoTokenizer.from_pretrained(model_id)
def generate(self, text: str) -> pd.DataFrame:
input_ids = self.tokenizer(text, return_tensors="pt").input_ids.to(
self.model.device
)
gen_tokens = self.model.generate(
input_ids,
temperature=0.9,
max_length=200,
)
return pd.DataFrame(
self.tokenizer.batch_decode(gen_tokens), columns=["responses"]
)
async def __call__(self, http_request: Request) -> str:
json_request: str = await http_request.json()
return self.generate(prompt["text"])
deployment = PredictDeployment.bind(model_id="huggyllama/llama-13b")
# затем запуск из команды CLI:
# serve run ray_serve:deployment
Создание запросов:
import requests
sample_input = {"text": "Funniest joke ever:"}
output = requests.post("http://localhost:8000/", json=[sample_input]).json()
print(output)
Основные особенности
- Панель мониторинга и метрики Prometheus. Использование панели мониторинга Ray позволит получить высокоуровневый обзор состояния Ray-кластера и приложения Ray Service.
- Автоматическое масштабирование по нескольким репликам. Ray адаптируется к скачкам трафика, отслеживая размеры очередей и принимая решения о масштабировании для добавления или удаления реплик.
- Динамическая пакетная обработка запросов. Это важно при применении дорогих моделей, чтобы использовать аппаратное оборудование с максимальной выгодой.
Преимущества
- Обширная документация. Стоит похвалить разработчиков за то, что они тщательно подошли к вопросу создания документации. Вы можете найти множество примеров практически для каждого варианта использования, что очень полезно.
- Готовность к производству. На мой взгляд, это самый зрелый фреймворк среди всех представленных в списке.
- Нативная LangChain-интеграция. Можно взаимодействовать с удаленным сервером OpenLLM с помощью LangChain.
Ограничения
- Отсутствие встроенной оптимизации модели. Ray Serve не ориентирован на LLM, это более широкая платформа для развертывания любых МО-моделей. Вам придется провести оптимизацию самостоятельно.
- Высокий порог входа. Библиотека иногда перегружается дополнительными функциональными возможностями, что затрудняет работу с ней.
Если вам нужно максимально готовое к работе решение, ориентированное не только на глубокое обучение, то Ray Serve — отличный вариант. Он лучше всего подходит для предприятий, где важны доступность, масштабируемость и наблюдаемость. Более того, вы можете использовать его обширную экосистему для обработки данных, обучения, тонкой настройки и обслуживания. Стоит добавить, что Ray Serve взят на вооружение многими компаниями, от OpenAI до Shopify и Instacart.
7. MLC LLM

MLC LLM (Machine Learning Compilation LLM, компиляция машинного обучения для LLM) — это универсальное решение для развертывания, которое позволяет LLM эффективно работать на потребительских устройствах, используя нативное аппаратное ускорение.
Использование
Запуск веб-сервера:
# 1. Убедитесь, что у вас установлен Python >= 3.9
# 2. Запускать его нужно с помощью conda:
conda create -n mlc-chat-venv -c mlc-ai -c conda-forge mlc-chat-nightly
conda activate mlc-chat-venv
# 3. Затем установите пакет:
pip install --pre --force-reinstall mlc-ai-nightly-cu118 \
mlc-chat-nightly-cu118 \
-f https://mlc.ai/wheels
# 4. Загрузите веса модели из HuggingFace и бинарные библиотеки:
git lfs install && mkdir -p dist/prebuilt && \
git clone https://github.com/mlc-ai/binary-mlc-llm-libs.git dist/prebuilt/lib && \
cd dist/prebuilt && \
git clone https://huggingface.co/huggyllama/llama-13b dist/ && \
cd ../..
# 5. Запустите сервер:
python -m mlc_chat.rest --device-name cuda --artifact-path dist
Создание запросов:
import requests
payload = {
"model": "lama-30b",
"messages": [{"role": "user", "content": "Funniest joke ever:"}],
"stream": False
}
r = requests.post("http://127.0.0.1:8000/v1/chat/completions", json=payload)
print(r.json()['choices'][0]['message']['content'])
Основные особенности
- Встроенные в платформу среды выполнения. Развертывание в нативной среде пользовательских устройств, которые могут не иметь легкодоступных Python- или других необходимых зависимостей. Разработчикам приложений нужно только ознакомиться со встроенными в платформу средами выполнения, чтобы интегрировать MLC-компилированные LLM в проекты.
- Оптимизация памяти. Вы можете компилировать, сжимать и оптимизировать модели, используя различные методы, что позволяет развертывать их на разных устройствах.
Преимущества
- Все настройки — в JSON config. В одном файле конфигурации можно определить конфигурацию среды выполнения для каждой скомпилированной модели.
- Готовые приложения. Можно скомпилировать используемую модель для разных платформ: C++ для командной строки, JavaScript для веб-пространства, Swift для iOS и Java/Kotlin для Android.
Ограничения
- Ограниченная функциональность использования моделей LLM. Нет поддержки адаптеров, невозможно изменить точность, нет потоковой передачи токенов и т. д. Библиотека в основном ориентирована на компиляцию моделей для различных устройств.
- Поддерживается только групповое квантование. Хотя этот метод показал хорошие результаты, другие подходы к квантованию (bitsandbytes и GPTQ) более популярны в сообществе. Вполне возможно, что члены комьюнити будут развивать именно их.
- Сложная установка. Мне потребовалось несколько часов, чтобы правильно установить библиотеку. Скорее всего, этот вариант не подойдет для начинающих разработчиков.
Если вам нужно развернуть приложение на устройстве iOS или Android, библиотека MLC LLM — именно то, что вам нужно. Она позволит быстро и нативно скомпилировать и развернуть модель на устройстве. Если же вам нужен высоконагруженный сервер, я бы не рекомендовал выбирать этот фреймворк.
Выводы
Выбор явного фаворита стал для меня непростой задачей. Каждая библиотека имеет свои уникальные преимущества и недостатки. LLM все еще находятся на ранних стадиях разработки, поэтому единого стандарта, которому нужно следовать, пока нет.
Призываю вас использовать мою статью в качестве отправной точки при выборе наиболее подходящего инструмента для ваших потребностей.
Я не касался темы затрат на вывод модели, поскольку они значительно варьируются в зависимости от производителя GPU и используемой модели. Однако некоторые полезные ресурсы по сокращению расходов можно найти в разделе “Бонус”.
Бонус
При проведении экспериментов я использовал сервисы и библиотеки, которые могут оказаться полезными и вам.
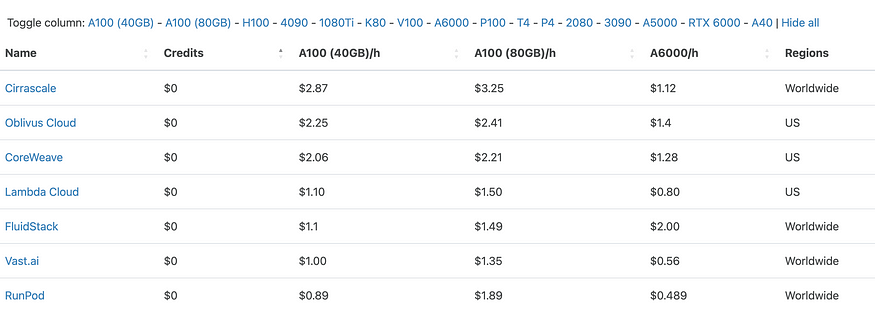
- Cloud GPU Comparison. Здесь можно найти лучшие цены от разных поставщиков на серверы с GPU.
- dstack. Позволяет настроить среду для вывода LLM и запустить ее с помощью одной команды. Мне это помогло снизить расходы на простаивающие серверы GPU. Вот лишь пример того, как быстро вы можете развернуть LLaMA:
type: task
env:
- MODEL=huggyllama/llama-13b
# (Необязательно) Укажите свой токен Hugging Face
- HUGGING_FACE_HUB_TOKEN=
ports:
- 8000
commands:
- conda install cuda # Требуется, поскольку vLLM будет перестраивать ядро CUDA
- pip install vllm
- python -m vllm.entrypoints.openai.api_server --model $MODEL --port 8000
После этого нужно просто выполнить команду:
dstack run . -f vllm/serve.dstack.yml
Читайте также:
- Промпт-инжиниринг: как использовать LLM для создания приложений
- YAML против JSON: какой формат эффективнее для работы с LLM?
- Как создать простой агент с Guidance и локальной моделью LLM
Читайте нас в Telegram, VK и Дзен
Перевод статьи Sergei Savvov: Frameworks for Serving LLMs. A comprehensive guide into LLMs inference and serving





