
Представьте следующие ситуации. Вы только что создали модель машинного обучения и должны протестировать ее на конкретных сценариях. Или вам надо опубликовать научную статью о пользовательском решении в области дата-сайенс, а доступные наборы данных имеют ограничения по авторским правам. Или же ваш проект машинного обучения находится на этапе отладки и для устранения проблем вам нужны данные.
Во всех этих и многих других ситуациях помогут синтетические данные. Зачастую реальные данные недоступны, дороги или приватны. Поэтому создание синтетических данных — полезный навык для практикующих и квалифицированных дата-сайентистов.
В этой статье речь пойдет о некоторых методах и приемах создания с нуля синтетических данных, экспериментальных наборов данных и фиктивных значений с помощью Python. В одних решениях используются методы из библиотек Python, в других — встроенные функции Python.
Все упомянутые здесь методы пригодились мне при решении исследовательских задач, написании научных работ, обучении или тестировании моделей. Надеюсь, читатель изучит ноутбук, представленный в конце статьи, и использует его в качестве руководства или сохранит как справочник для будущих проектов.
1. Использование NumPy
Самая известная библиотека Python для работы с линейной алгеброй и численными вычислениями также полезна для генерации данных.
- Генерация линейных данных
В этом примере показано, как создать набор данных с шумом, имеющим линейную связь с целевыми значениями. Это может быть полезно для тестирования моделей линейной регрессии.
# Импорт модулей
from matplotlib import pyplot as plt
import numpy as np
def create_data(N, w):
"""
Создает набор данных с шумом, имеющим линейную связь с целевыми значениями
N: количество образцов
w: целевые значения
"""
# Матрица признаков со случайными данными
X = np.random.rand(N, 1) * 10
# целевые значения с шумом (нормальное распределение)
y = w[0] * X + w[1] + np.random.randn(N, 1)
return X, y
# Визуализация данных
X, y = create_data(200, [2, 1])
plt.figure(figsize=(10, 6))
plt.title('Simulated Linear Data')
plt.xlabel('X')
plt.ylabel('y')
plt.scatter(X, y)
plt.show()
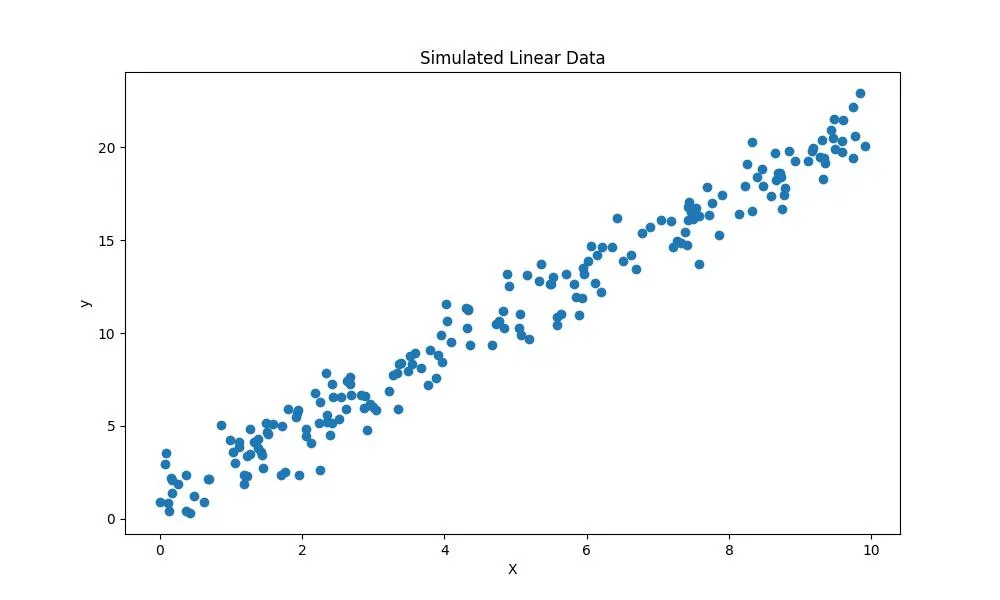
- Данные временного ряда
В этом примере используется NumPy для создания синтетических данных временного ряда с линейным трендом и сезонной составляющей. Данный подход полезен для финансового моделирования и прогнозирования фондового рынка.
def create_time_series(N, w):
"""
Создание данных временного ряда с линейным трендом и сезонной составляющей
N: количество образцов
w: целевые значения
"""
# временные значения
time = np.arange(0,N)
# линейный тренд
trend = time * w[0]
# сезонная составляющая
seasonal = np.sin(time * w[1])
# шум
noise = np.random.randn(N)
# целевые значения
y = trend + seasonal + noise
return time, y
# Визуализация данных
time, y = create_time_series(100, [0.25, 0.2])
plt.figure(figsize=(10, 6))
plt.title('Simulated Time Series Data')
plt.xlabel('Time')
plt.ylabel('y')
plt.plot(time, y)
plt.show()
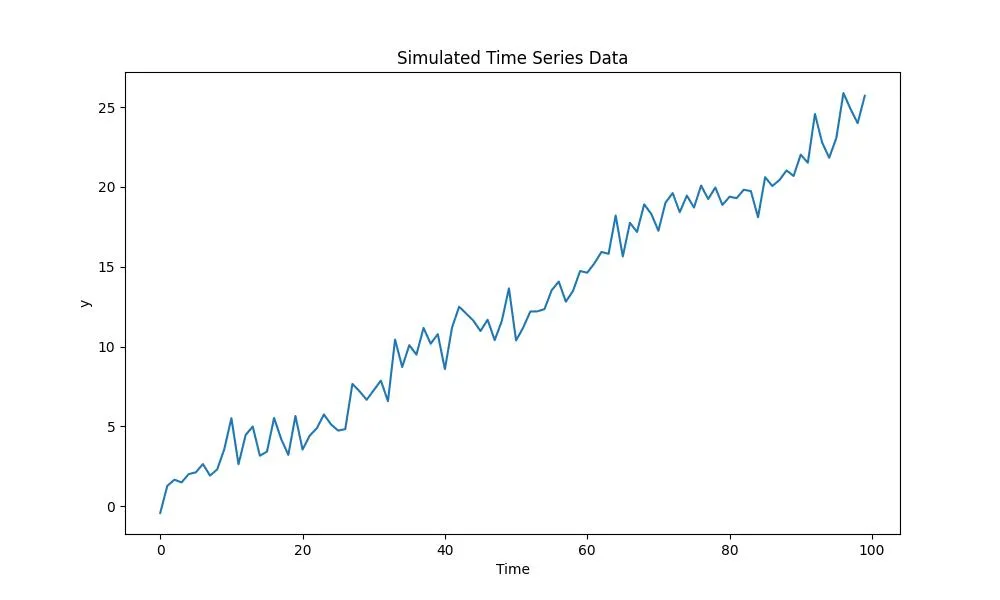
- Пользовательские данные
Иногда требуются данные с особыми характеристиками. Например, для задач снижения размерности может потребоваться высокоразмерный набор данных, содержащий лишь несколько информативных измерений. В этом случае, как показано в следующем примере, используется адекватный метод генерации таких наборов данных.
# Создание моделированных данных для анализа
np.random.seed(42)
# Генерация низкоразмерного сигнала
low_dim_data = np.random.randn(100, 3)
# Создание матрицы случайных проекций для проецирования в более высокие измерения
projection_matrix = np.random.randn(3, 6)
# Проецирование низкоразмерных данных на более высокие измерения
high_dim_data = np.dot(low_dim_data, projection_matrix)
# Добавление шума в высокоразмерные данные
noise = np.random.normal(loc=0, scale=0.5, size=(100, 6))
data_with_noise = high_dim_data + noise
X = data_with_noise
Приведенный выше фрагмент кода создает набор данных со 100 наблюдениями и 6 признаками на основе массива меньшей размерности, состоящего всего из 3 измерений.
2. Использование Scikit-learn
Помимо моделей машинного обучения, в библиотеке Scikit-learn есть генераторы данных, полезные для создания искусственных наборов данных контролируемого размера и сложности.
- make_classification
Метод make_classification можно использовать для создания случайного набора данных с n-классами. Этот метод позволяет создавать наборы данных с произвольным количеством наблюдений, признаков и классов.
Он может быть полезен для тестирования и отладки моделей классификации, таких как метод опорных векторов, деревья решений и алгоритм Naive Bayes.
X, y = make_classification(n_samples=1000, n_features=5, n_classes=2)
# Визуализация первых строк синтетического набора данных
import pandas as pd
df = pd.DataFrame(X, columns=['feature1', 'feature2', 'feature3', 'feature4', 'feature5'])
df['target'] = y
df.head()
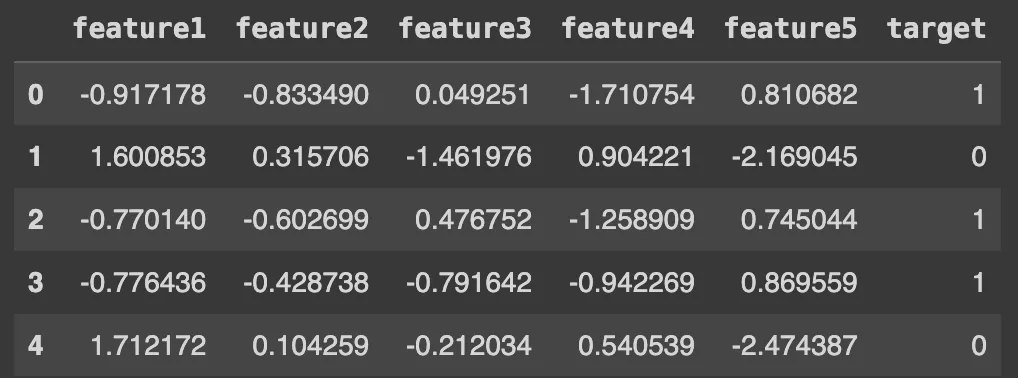
- make_regression
Аналогично метод make_regression хорошо подойдет для создания наборов данных для регрессионного анализа. Он позволяет задать количество наблюдений, количество признаков, смещение и шум результирующего набора данных.
from sklearn.datasets import make_regression
X,y, coef = make_regression(n_samples=100, # количество наблюдений
n_features=1, # количество признаков
bias=10, # составляющая смещения
noise=50, # уровень шума
n_targets=1, # количество целевых значений
random_state=0, # случайное начальное число
coef=True # коэффициенты возврата
)
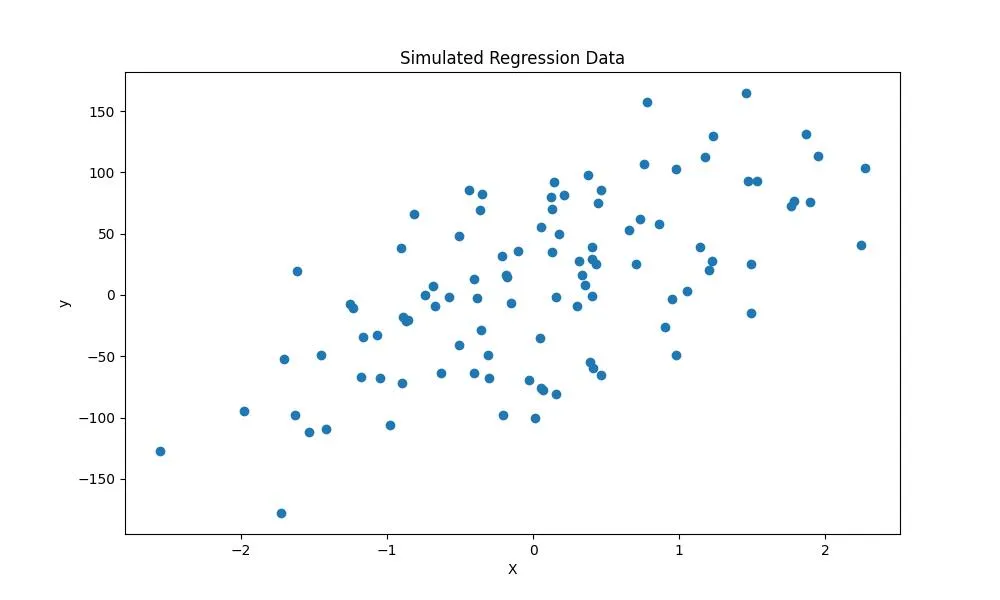
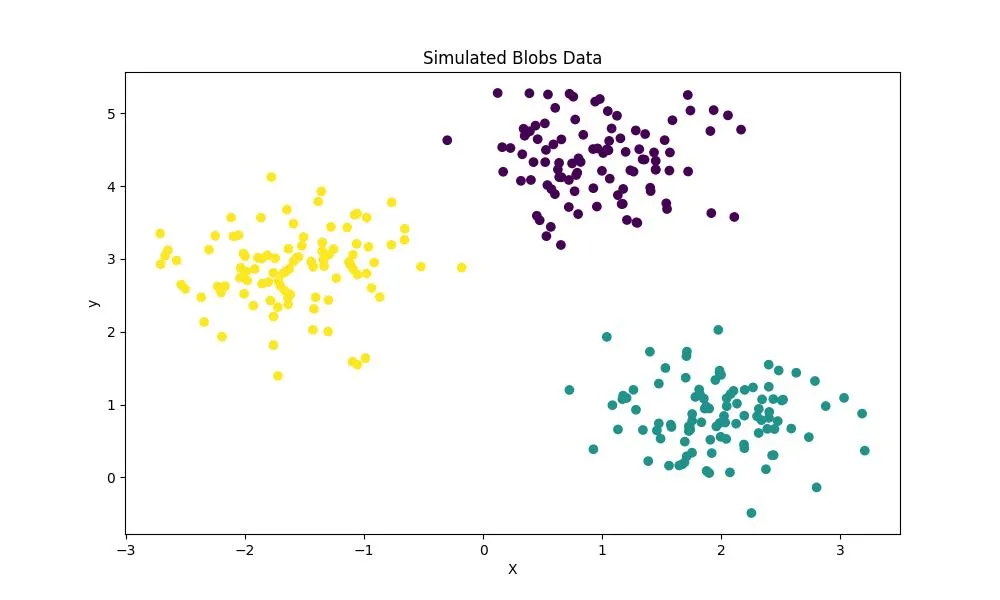
- make_blobs
Метод make_blobs позволяет создавать искусственные «куски» данных (блобы), которые можно использовать для задач кластеризации. Он помогает задать общее количество точек в наборе данных, количество кластеров и внутрикластерное стандартное отклонение.
from sklearn.datasets import make_blobs
X,y = make_blobs(n_samples=300, # количество наблюдений
n_features=2, # количество признаков
centers=3, # количество кластеров
cluster_std=0.5, # стандартное отклонение кластеров
random_state=0)
3. Использование SciPy
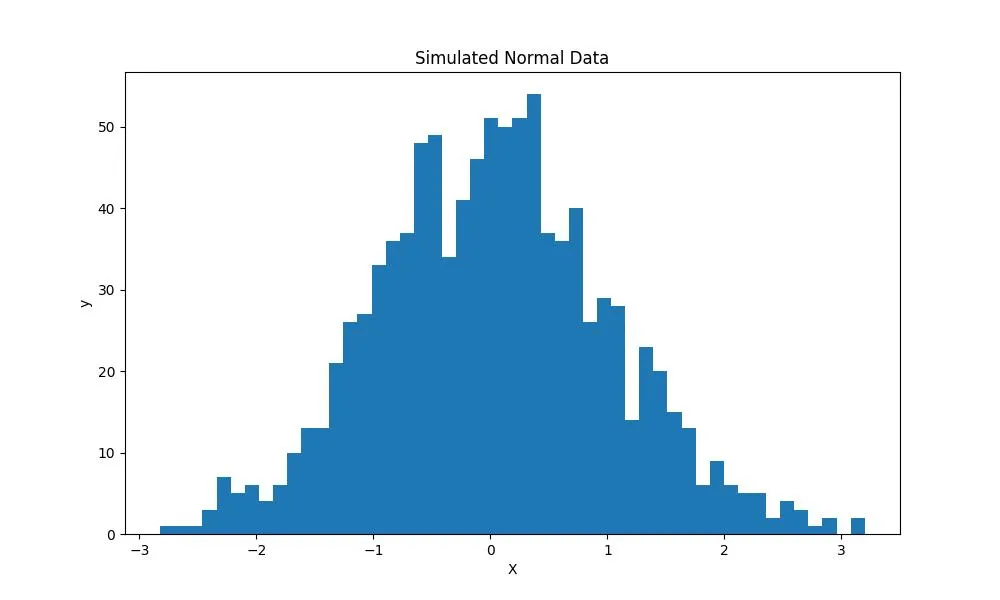
SciPy (сокращение от Scientific Python — научный Python), наряду с NumPy, является одной из лучших библиотек для проведения численных вычислений, оптимизации, статистического анализа и многих других математических задач. StatsModels — пакет Python, который является дополнением к SciPy для статистических вычислений, — может создавать симуляцию данных из многих статистических распределений, таких как нормальное, биномиальное и экспоненциальное.
from scipy.stats import norm, binom, expon
# Нормальное распределение
norm_data = norm.rvs(size=1000)
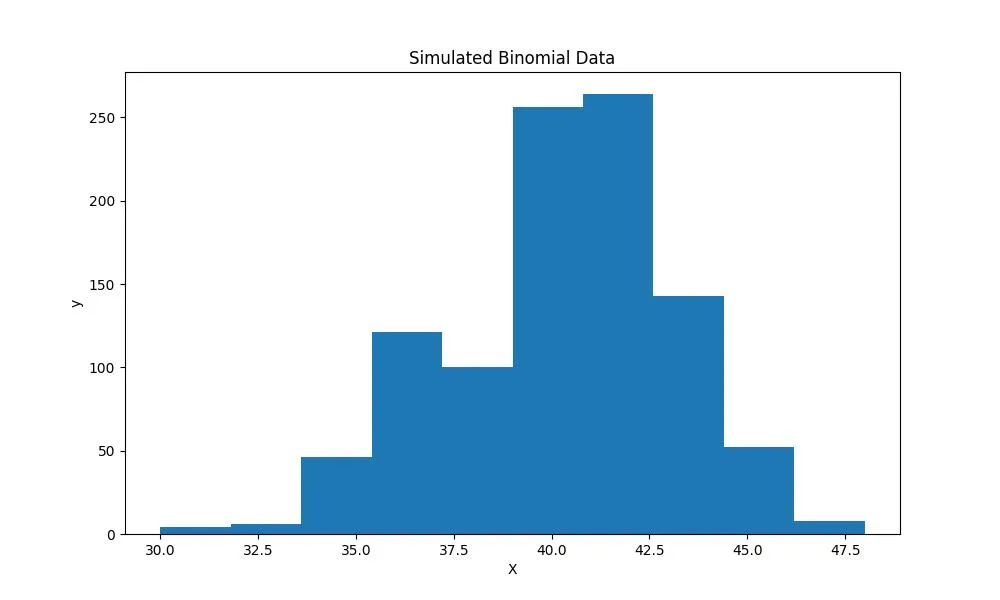
# Биномиальное распределение
binom_data = binom.rvs(n=50, p=0.8, size=1000)
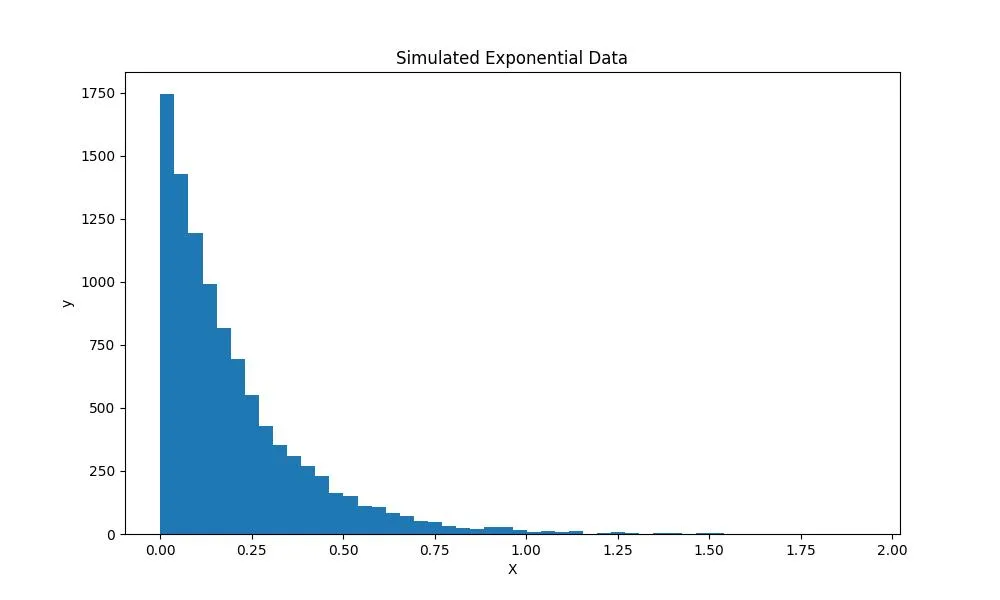
# Экспоненциальное распределение
exp_data = expon.rvs(scale=.2, size=10000)
4. Использование Faker
А как быть с нечисловыми данными? Часто требуется обучить модель на нечисловых или пользовательских данных, таких как имя, адрес и электронная почта. Решением для создания реалистичных данных, похожих на информацию о пользователе, является использование библиотеки Faker Python.
Библиотека Faker позволяет генерировать убедительные данные, которые можно использовать для тестирования приложений и классификаторов машинного обучения. В приведенном ниже примере показано, как создать фиктивный набор данных с информацией об имени, адресе, номере телефона и электронной почте.
from faker import Faker
def create_fake_data(N):
"""
Создает набор данных с фиктивными данными.
N: количество образцов
"""
fake = Faker()
names = [fake.name() for _ in range(N)]
addresses = [fake.address() for _ in range(N)]
emails = [fake.email() for _ in range(N)]
phone_numbers = [fake.phone_number() for _ in range(N)]
fake_df = pd.DataFrame({'Name': names, 'Address': addresses, 'Email': emails, 'Phone Number': phone_numbers})
return fake_df
fake_users = create_fake_data(100)
fake_users.head()
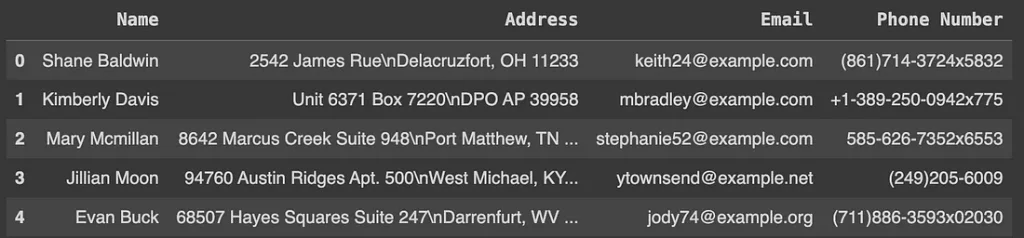
5. Использование SDV
Как быть, если у вас есть набор данных, в котором недостаточно наблюдений, или вам нужно больше данных, похожих на существующий датасет, чтобы дополнить этап обучения модели МО? SDV (Synthetic Data Vault — хранилище синтетических данных) — библиотека Python, которая позволяет создавать синтетические наборы данных с помощью статистических моделей.
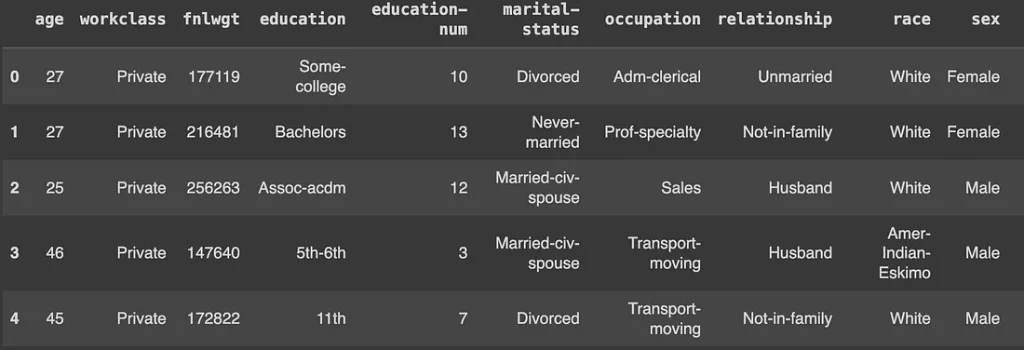
В приведенном ниже примере используется SDV для расширения демонстрационного набора данных:
from sdv.datasets.demo import download_demo
# Загрузка набора данных 'adult'
adult_data, metadata = download_demo(dataset_name='adult', modality='single_table')
adult_data.head()
from sdv.single_table import GaussianCopulaSynthesizer
# Используйте GaussianCopulaSynthesizer для обучения на данных
model = GaussianCopulaSynthesizer(metadata)
model.fit(adult_data)
# Генерация синтетических данных
simulated_data = model.sample(100)
simulated_data.head()
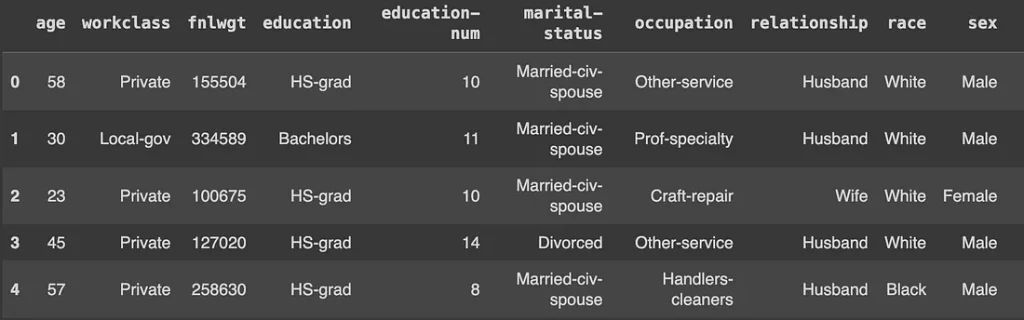
Обратите внимание: во второй таблице данные очень похожи на исходный набор, но это все же синтетические данные.
Выводы и дальнейшие шаги
В статье было представлено 5 способов создания имитационных и синтетических наборов данных, которые можно использовать для проектов машинного обучения, статистического моделирования и других задач, связанных с данными. Приведенные примеры просты в исполнении, поэтому рекомендую изучить соответствующие фрагменты кода, ознакомиться с доступной документацией и разработать другие методы генерации данных, более подходящие для любых задач.
Как уже говорилось, дата-сайентисты, специалисты по машинному обучению и разработчики могут выиграть от использования синтетических наборов данных, повысив производительность моделей и снизив затраты на производство и тестирование приложений.
Все методы, рассмотренные в статье, можно найти в этом ноутбуке.
Читайте также:
- Автоматический импорт библиотек в IPython или Jupyter Notebook
- Как обнаружить выбросы в проекте по исследованию данных
- Правила PRISM на языке Python
Читайте нас в Telegram, VK и Дзен
Перевод статьи Marcus Sena: Step-by-Step Guide to Creating Simulated Data in Python





