

Итак, у нас есть обученная модель Detectron2 (см. часть 1). Теперь развернем ее как часть приложения, обладающего возможностями логического вывода.
Модель Detectron2, упоминаемая в 1-й и 2-й частях статьи, применяется для обнаружения объектов. Тем не менее обсуждаемые здесь темы, касающиеся развертывания моделей, будут полезны всем разработчикам процессов машинного обучения независимо от сферы применения (компьютерное зрение, обработка естественного языка, глубокое обучение и т. д.) и используемой библиотеки МО (Detectron, Yolo, PyTorch, Tensorflow и т. д.).
Хотя дата-сайенс (DS) и компьютерные науки (CS) во многом пересекаются, процесс обучения и развертывания модели МО позволяет объединить оба эти направления. Дело в том, что разработчики эффективных и точных моделей обычно не занимаются их развертыванием. С другой стороны, у специалистов, ориентированных на компьютерные науки, нет достаточного представления о МО и связанных с ним библиотеках, чтобы устранить узкие места в приложении с помощью настроек процесса МО или, скорее, бэкенда и хостинга/ов.
Для облегчения попыток развернуть приложение, использующее МО, начнем эту часть статьи с обсуждения:
- концепций высокоуровневого CS-проектирования, которые помогут, особенно представителям DS, в принятии решений для сбалансирования нагрузки и устранения узких мест;
- низкоуровневого проектирования — развертывания на Python процесса логического вывода Detectron2 с помощью веб-фреймворка Django, API с применением Django Rest Framework, распределенной очереди задач Celery, Docker, Heroku и AWS S3.
Для понимания предлагаемого материала необходимо:
- уверенное владение Python;
- усвоение принципов работы Django, Django Rest Framework, Docker, Celery и AWS;
- ознакомление с Heroku.
Высокоуровневое проектирование
Чтобы углубиться в высокоуровневое проектирование, определим его ключевые проблемы и их потенциальные решения.
Проблема 1: память
Сохраненная модель МО из 1-й части, названная model_final.pth, будет занимать примерно 325 МБ. Кроме того, приложение, основанное на (1) среде выполнения Python, (2) Detectron2, (3) больших зависимостях, таких как Torch, и (4) веб-фреймворке Django, будет использовать примерно 150 МБ памяти при развертывании.
Таким образом, получаем, как минимум, 475 МБ памяти, используемой сразу после запуска.
Что, если загружать модель Detectron2 только при необходимости запустить процесс МО? В этом случае приложение все равно в конечном итоге съест около 475 МБ. При жестком бюджете и невозможности вертикального масштабирования приложения, память становится существенным ограничением на многих хостинговых платформах. Например, Heroku предлагает для запуска приложений контейнеры под названием “dyno” (с 512 МБ RAM для базового тарифного плана), которые начинают записывать на диск при превышении порога в 512 МБ, а при 250%-ном использовании (1280 МБ) выходят из строя и требуют перезапуска.
Что же касается расхода памяти при использовании метода Detectron2, то сбои могут возникнуть при увеличении количества объектов, обнаруживаемых на изображении. Поэтому важно обеспечить достаточный объем памяти во время этого процесса.
Тем, кто пытается ускорить процесс логического вывода, опасаясь нехватки памяти, пакетированный вывод также не помогает. Вот что написал о пакетированном выводе один из контрибьюторов репозитория Detectron2:
“N изображений используют в N раз больше памяти, чем 1 изображение… Вместо этого можно делать прогнозы на N изображениях по одному в цикле”.
Все вышесказанное сводится к проблеме № 1:
Выполнение длительных процессов МО в составе приложения, скорее всего, будет требовать большого объема памяти, определяемого размером модели, зависимостями МО и процессом логического вывода.
Проблема 2: время
Проектирование развертываемого приложения, использующего модель МО, должно быть нацелено на управление долго выполняемым процессом.
Для примера возьмем приложение, использующее Detectron2. Для логического вывода модели предоставляют изображение в качестве входных и выходных координат. При использовании одного изображения вывод может занять всего несколько секунд, но обработка длинного PDF-документа с одним изображением на странице (как в обучающих данных в части 1) потребует больше времени.
В течение этого процесса логический вывод Detectron2 будет привязан либо к CPU, либо к GPU — в зависимости от пользовательских конфигураций. Изменить настройки поможет приведенный ниже блок кода Python (CPU вполне подходит для логического вывода, тогда как GPU/Cuda требуется для обучения, как упоминалось в части 1):
from detectron2.config import get_cfg
cfg = get_cfg()
cfg.MODEL.DEVICE = "cpu" #or "cuda"Кроме того, сохранение изображений после логического вывода, скажем, в AWS S3, приведет к появлению процессов, связанных с ограничением ввода-вывода. В целом, это может вызвать засорение бэкенда, что влечет за собой проблему № 2:
Во время выполнения процесса однопоточные приложения Python не будут обрабатывать дополнительные HTTP-запросы одновременно или иным образом.
Проблема 3: масштабирование
Рассматривая горизонтальную масштабируемость Python-приложения, важно отметить, что Python (при условии, что он компилируется/интерпретируется CPython) страдает от ограничений глобальной блокировки интерпретатора (GIL), которая позволяет только одному потоку удерживать управление Python-интерпретатором. Таким образом, применение парадигмы многопоточности по отношению к Python не совсем корректно. Дело в том, что Python-приложения могут реализовать многопоточность, используя веб-серверы, такие как Gunicorn, но при этом обрабатывают потоки одновременно, а не параллельно.
Понимаю, насколько абстрактно это звучит, особенно для дата-сайентистов, поэтому приведу пример для иллюстрации вышесказанного.
Представьте, что вы — приложение, и прямо сейчас ваше аппаратное устройство, мозг, обрабатывает два запроса: очистка счетчика и набор текста СМС-сообщения на телефоне. Наличие двух рук делает вас многопоточным Python-приложением, выполняющим оба действия одновременно. Но на самом деле вы не думаете одновременно о каждом из выполняемых действий: сначала одна ваша рука запускает очистку счетчика; потом вы переключаете внимание на телефон, проверяя набранный другой рукой текст; затем снова смотрите на счетчик, чтобы убедиться в его полной очистке.
Фактически вы обрабатываете одновременно два действия, выполняя каждое их них за раз.
GIL функционирует аналогичным образом, обрабатывая один поток за раз, но переключаясь между потоками для обеспечения их совместного выполнения. Это означает, что многопоточность в приложении Python требуется для выполнения фоновых или связанных с вводом-выводом задач, таких как загрузка файла, в то время как выполнение основного потока все еще продолжается. Вернемся к нашей аналогии: фоновая задача очистки счетчика (или загрузка файла) продолжается, пока вы думаете о СМС, но для выполнения следующего шага вам все равно нужно переключить фокус на руку, занимающуюся очисткой.
Подобное “изменение фокуса” может показаться не таким уж важным при совместной обработке нескольких запросов. Но при необходимости обрабатывать сотни запросов одновременно, оно внезапно становится ограничивающим фактором для крупномасштабных приложений, которые должны адекватно реагировать на запросы конечных пользователей.
Отсюда возникает проблема № 3:
GIL не позволяет считать многопоточность хорошим решением для масштабирования Python-приложений.
Решения
Теперь, определив ключевые проблемы, рассмотрим их потенциальные решения.
Вышеупомянутые проблемы изложены по степени важности: в первую очередь нужно наладить управление памятью (проблема №1), чтобы приложение не вышло из строя; затем необходимо предусмотреть возможность обработки приложением более одного запроса за раз (проблема №2) и при этом обеспечить эффективность средств одновременной обработки запросов при масштабировании (проблема №3).
Итак, перейдем к решению проблемы № 1.
В зависимости от платформы хостинга, вам следует знать все о доступных конфигурациях для масштабирования. Поскольку мы будем использовать Heroku, ознакомьтесь с руководством по масштабированию dyno. Если нет необходимости вертикально масштабировать dyno, можно масштабировать его, добавив другой процесс. Например, при использовании базового dyno можно развернуть на одном контейнере и веб-процесс, и рабочий процесс. Это полезно по нескольким причинам:
- Можно реализовать многопроцессорность.
- Ресурсы dyno теперь дублируются, учитывая, что для каждого процесса установлен порог в 512 МБ RAM.
- По стоимости это обойдется в $7 в месяц на процесс ($14 в месяц с веб- и рабочим процессом). Это гораздо дешевле, чем вертикальное масштабирование dyno, для получения большего объема оперативной памяти: $50 в месяц за dyno при желании увеличить объем выделенных 512 МБ до 1024 МБ.
Вернемся снова к аналогии с очисткой счетчика и набором СМС. Вместо того чтобы утяжелять себя за счет добавления к телу дополнительных рук, вы можете задействовать двух человек (параллельную многопроцессорную обработку) для выполнения отдельных задач. Масштабирование происходит за счет повышения разнообразия рабочей нагрузки, а не наращивания ее, что, в свою очередь, экономит деньги.
Хорошо, но в чем разница между двумя отдельными процессами?
При использовании Django веб-процесс будет инициализирован с помощью команды:
python manage.py runserverА при использовании распределенной очереди задач, например Celery, рабочий процесс будет инициализирован следующим образом:
celery -A <DJANGO_APP_NAME_HERE> workerКак указано в документации Heroku, веб-процесс — это сервер для основного веб-фреймворка, а рабочий процесс предназначен для постановки в очередь библиотек, заданий cron или другой работы, выполняемой в фоновом режиме. Оба процесса представляют собой экземпляр развернутого приложения, поэтому с учетом основных зависимостей и времени выполнения они будут занимать ~150 МБ. Однако можно сделать так, чтобы рабочий (воркер) был единственным процессом, выполняющим задачи МО, что избавит веб-процесс от использования ~325 МБ+ оперативной памяти. Это дает множество преимуществ.
- Использование памяти, хотя и остается высоким для рабочего процесса, будет распределено на узел вне системы. Так что любые проблемы, возникающие во время выполнения задачи МО, могут быть обработаны и отслежены отдельно от веб-процесса. В результате минимизируется проблема № 1.
- Недавно найденные средства параллелизма гарантируют, что веб-процесс сможет отвечать на запросы во время длительного выполнения задачи МО. Это помогает справиться с проблемой № 2.
- Подготовка к масштабированию предполагает внедрение средств многопроцессорной обработки, что позволяет решить проблему № 3.
Поскольку ключевые проблемы еще не до конца решены, углубимся в них, прежде чем переходить к деталям. Разработчики Heroku утверждают:
Веб-приложения, обрабатывающие входящие HTTP-запросы одновременно, используют ресурсы dyno гораздо эффективнее, чем веб-приложения, обрабатывающие только один запрос за раз. Поэтому при разработке и запуске производственных сервисов рекомендуется использовать веб-серверы, поддерживающие одновременную обработку запросов.
В веб-фреймворках Django и Flask есть удобные встроенные веб-серверы, но эти блокирующие серверы обрабатывают только один запрос за раз. Если вы развернете на Heroku один из таких серверов, ваши ресурсы dyno будут использоваться недостаточно эффективно, а приложение будет работать неотзывчиво.
Мы уже опережаем события, используя многопроцессорную обработку рабочего процесса для задачи МО, но можем сделать еще один шаг вперед, используя Gunicorn.
Gunicorn — это основанный на чистом Python HTTP-сервер для WSGI-приложений. Он позволяет запускать любые Python-приложения одновременно с выполнением нескольких Python-процессов в рамках одного dyno. Он обеспечивает идеальный баланс производительности, гибкости и простоты настройки.
Отлично, теперь можно задействовать еще больше процессов. Но есть одна загвоздка: каждый новый рабочий процесс, запущенный на Gunicorn, будет представлять собой копию приложения. Это значит, что все новые процессы тоже будут использовать базовые ~150 МБ RAM в дополнение к процессу Heroku. Итак, допустим, мы установили Gunicorn с помощью pip и теперь инициализируем веб-процесс Heroku следующей командой:
gunicorn <DJANGO_APP_NAME_HERE>.wsgi:application --workers=2 --bind=0.0.0.0:$PORTБазовые ~150 МБ RAM в веб-процессе превращаются в ~300 МБ RAM (базовое использование памяти, умноженное на количество gunicorn workers — рабочих процессов, запущенных в Gunicorn).
Помня об ограничениях многопоточности в Python-приложениях, добавим потоки и в рабочие процессы:
gunicorn <DJANGO_APP_NAME_HERE>.wsgi:application --threads=2 --worker-class=gthread --bind=0.0.0.0:$PORTДаже с учетом проблемы № 3, можно найти применение потокам, чтобы убедиться в способности веб-процесса обрабатывать более одного запроса за раз, экономя при этом память приложения. Наши потоки могут обрабатывать небольшие запросы, обеспечивая при этом распределение задачи МО в другом месте.
В любом случае при использовании рабочих процессов Gunicorn, потоков или и того, и другого Python-приложение можно настроить на обработку более чем одного запроса за раз. Проблема № 2 будет более или менее решена с помощью различных способов реализации одновременной и/или параллельной обработки задач. При этом выполнению критически важной МО-задачи приложения не грозят потенциальные ловушки, такие как многопоточность. Теперь можно заняться настройкой масштабирования, добравшись до корня проблемы № 3.
А как быть с довольно непростой проблемой № 1? В конце концов, процессы МО обычно так или иначе нагружают аппаратное обеспечение, будь то память, CPU и/или GPU. Однако использование распределенной системы предполагает неразрывную связь основного веб-процесса с задачей МО, обрабатываемой параллельно с помощью рабочего процесса Celery. При этом можно отслеживать начало и завершение выполнения задачи МО через выбранного Celery Broker (брокера сообщений), а также просматривать отдельные метрики. Конфигурации рабочих процессов Celery и Heroku зависят от потребностей пользователя, в любом случае это отличная отправная точка для интеграции в приложение длительного процесса МО, занимающего много памяти.
Низкоуровневое проектирование и настройка
Теперь, получив представление о создаваемой системе на высоком уровне, соберем все воедино и сосредоточимся на деталях.
Для наглядности будем обращаться к этому репозиторию.
Начнем с установки Django и Django REST Framework (DRF), руководства по которым находятся здесь и здесь соответственно. Все требования для этого приложения можно найти в файле репозитория requirements.txt (а Detectron2 и Torch будут собраны из Python-колес (wheels), указанных в Dockerfile, чтобы сохранить небольшой размер Docker-образа).
Этот раздел будет посвящен настройке приложения Django, конфигурированию бэкенда для сохранения в AWS S3 и открытию конечной точки с помощью DRF. Если вы уже умеете все это делать, можете сразу переходить к разделу “Настройка и развертывание задач МО”.
Настройка Django
Создайте папку для проекта Django и перейдите в нее с помощью команды cd. Активируйте используемую вами виртуальную среду virtual/conda env, убедитесь, что Detectron2 установлена в соответствии с инструкциями по установке (указанными в части 1), а также установите все необходимые требования.
Выполните следующую команду в терминале:
django-admin startproject mltutorialЭто создаст корневой каталог проекта Django под названием “mltutorial”. Перейдите в него и с помощью cd найдите файл manage.py и подкаталог mltutorial (который является фактическим пакетом Python для проекта).
mltutorial/
manage.py
mltutorial/
__init__.py
settings.py
urls.py
asgi.py
wsgi.pyОткройте settings.py и добавьте ‘rest_framework’, ‘celery’ и ‘storages’ (необходимые для boto3/AWS) в список INSTALLED_APPS, чтобы зарегистрировать эти пакеты в проекте Django.
В корневом каталоге надо создать приложение, которое будет содержать основную функциональность бэкенда. Выполните еще одну команду в терминале:
python manage.py startapp docreaderЭто создаст приложение в корневом каталоге под названием docreader.
Теперь создайте файл в docreader под названием mltask.py. В нем определите простую функцию для тестирования установки, которая принимает переменную file_path и выводит ее:
def mltask(file_path):
return print(file_path)Переходим к структуре. Django-приложения используют паттерн проектирования Model View Controller (MVC), определяя модель в models.py, представление в views.py, а контроллер в Django Templates и urls.py. С помощью Django Rest Framework включим в этот конвейер сериализацию, которая обеспечивает способ сериализации и десериализации нативных структур данных Python в такие представления, как json. Таким образом, логика работы приложения с конечной точкой выглядит следующим образом:
База данных ← → models.py ← → serializers.py ← → views.py ← → urls.py.
В файле docreader/models.py напишите следующее:
from django.db import models
from django.dispatch import receiver
from .mltask import mltask
from django.db.models.signals import(
post_save
)
class Document(models.Model):
title = models.CharField(max_length=200)
file = models.FileField(blank=False, null=False)
@receiver(post_save, sender=Document)
def user_created_handler(sender, instance, *args, **kwargs):
mltask(str(instance.file.file))Это устанавливает модель Document, которая будет требовать title и file для каждой записи, сохраняемой в базе данных. После сохранения декоратор @receiver прослушивает сигнал post save, означающий, что указанная модель, Document, была сохранена в базе данных. После сохранения user_created_handler() берет поле file сохраненного экземпляра и передает его тому, что станет функцией машинного обучения.
Когда в models.py вносятся изменения, нужно будет выполнять следующие две команды:
python manage.py makemigrations
python manage.py migrateТеперь создайте в docreader файл serializers.py, позволяющий сериализовать и десериализовать поля Document “title” и “file”. Напишите в нем:
from rest_framework import serializers
from .models import Document
class DocumentSerializer(serializers.ModelSerializer):
class Meta:
model = Document
fields = [
'title',
'file'
]В файле views.py, где можно определять CRUD-операции, определите возможность создавать, а также перечислять записи в Document с помощью обобщенных представлений (это позволит быстро писать представления, используя абстракцию общих шаблонов представлений):
from django.shortcuts import render
from rest_framework import generics
from .models import Document
from .serializers import DocumentSerializer
class DocumentListCreateAPIView(
generics.ListCreateAPIView):
queryset = Document.objects.all()
serializer_class = DocumentSerializerОбновите urls.py в mltutorial:
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path("admin/", admin.site.urls),
path('api/', include('docreader.urls')),
]Наконец, создайте файл urls.py в каталоге приложения docreader и запишите:
from django.urls import path
from . import views
urlpatterns = [
path('create/', views.DocumentListCreateAPIView.as_view(), name='document-list'),
]Теперь все готово для сохранения записи Document с полями title и field в конечной точке /api/create/, которая вызовет mltask() после сохранения! Протестируем это.
Для визуализации тестирования зарегистрируйте модель Document в интерфейсе администратора Django, чтобы видеть создание новой записи.
В файле docreader/admin.py напишите:
from django.contrib import admin
from .models import Document
admin.site.register(Document)Создайте пользователя, который сможет входить в интерфейс администратора Django:
python manage.py createsuperuserТеперь протестируем открытую нами конечную точку.
Чтобы сделать это без фронтенда, запустите сервер Django и перейдите в Postman. Отправьте следующий POST-запрос с прикрепленным PDF-файлом:
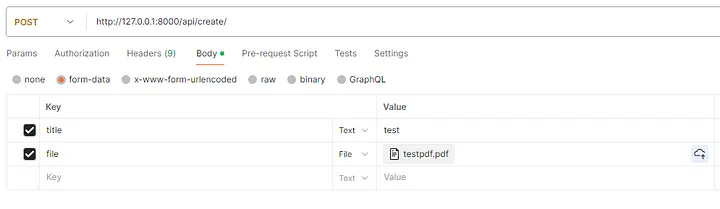
Проверка логов Django показывает, что путь к файлу выведен, как указано в вызове функции post save mltask().
Настройка AWS
Как вы заметили, PDF-файл был сохранен в корневом каталоге проекта. Теперь нужно убедиться в сохранении всех медиафайлов в AWS S3, чтобы приложение было готово к развертыванию.
Перейдите в консоль S3 (создайте учетную запись и получите ключи доступа (Access keys) и секретные ключи (Secret keys), если этого еще не сделали). Создайте новый бакет (bucket) — здесь назовем его ‘djangomltest’. Обновите права доступа, чтобы бакет был открытым для тестирования (при необходимости, вернитесь назад для необходимых действий).
Теперь настроим Django для работы с AWS.
Добавьте файл model_final.pth, созданный в части 1, в каталог docreader. Создайте файл .env в корневом каталоге и напишите в нем следующее:
AWS_ACCESS_KEY_ID = <Add your Access Key Here>
AWS_SECRET_ACCESS_KEY = <Add your Secret Key Here>
AWS_STORAGE_BUCKET_NAME = 'djangomltest'
MODEL_PATH = './docreader/model_final.pth'Обновите settings.py для включения конфигураций AWS:
import os
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv())
# AWS
AWS_ACCESS_KEY_ID = os.environ['AWS_ACCESS_KEY_ID']
AWS_SECRET_ACCESS_KEY = os.environ['AWS_SECRET_ACCESS_KEY']
AWS_STORAGE_BUCKET_NAME = os.environ['AWS_STORAGE_BUCKET_NAME']
#AWS Config
AWS_DEFAULT_ACL = 'public-read'
AWS_S3_CUSTOM_DOMAIN = f'{AWS_STORAGE_BUCKET_NAME}.s3.amazonaws.com'
AWS_S3_OBJECT_PARAMETERS = {'CacheControl': 'max-age=86400'}
#Boto3
STATICFILES_STORAGE = 'mltutorial.storage_backends.StaticStorage'
DEFAULT_FILE_STORAGE = 'mltutorial.storage_backends.PublicMediaStorage'
#AWS URLs
STATIC_URL = f'https://{AWS_S3_CUSTOM_DOMAIN}/static/'
MEDIA_URL = f'https://{AWS_S3_CUSTOM_DOMAIN}/media/'Учитывая то, что AWS обслуживает статические и медиафайлы, выполните следующую команду для обслуживания статических активов в интерфейсе администратора с помощью S3:
python manage.py collectstaticЕсли снова запустить сервер, ваша админка должна выглядеть так же, как и при локальном обслуживании статических файлов.
Еще раз запустите Django-сервер и протестируйте конечную точку, чтобы убедиться, что файл теперь сохраняется в S3.
Настройка и развертывание задачи МО
После установки Django и AWS настроим процесс МО в файле mltask.py. Поскольку файл длинный, воспользуйтесь для справки этим репозиторием (с комментариями, добавленными для понимания различных блоков кода).
Важно отметить, что Detectron2 импортируется, а модель загружается только при вызове функции. Здесь будем вызывать функцию только через задачу Celery. Таким образом, память, используемая во время вывода заключений, будет изолирована от рабочего процесса Heroku.
Итак, настроим Celery, а затем развернем на Heroku.
В файле mltutorial/_init__.py напишите:
from .celery import app as celery_app
__all__ = ('celery_app',)Создайте файл celery.py в папке mltutorial и напишите:
import os
from celery import Celery
# Установите модуль настроек Django по умолчанию для программы 'celery'.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'mltutorial.settings')
# Укажем Broker_URL на Heroku
app = Celery('mltutorial', broker=os.environ['CLOUDAMQP_URL'])
# Использование строки тут означает, что воркеру не нужно сериализовать
# объект конфигурации для дочерних процессов.
# - namespace='CELERY' означает, что все ключи конфигурации, связанные с celery,
# должны иметь приставку `CELERY_`.
app.config_from_object('django.conf:settings', namespace='CELERY')
# Загрузите модули задач из всех зарегистрированных приложений Django.
app.autodiscover_tasks()
@app.task(bind=True, ignore_result=True)
def debug_task(self):
print(f'Request: {self.request!r}')
Наконец, создайте файл tasks.py в docreader и напишите:from celery import shared_task
from .mltask import mltask
@shared_task
def ml_celery_task(file_path):
mltask(file_path)
return "DONE"Эта задача Celery, ml_celery_task(), теперь должна быть импортирована в models.py и использоваться с сигналом post save вместо функции mltask, взятой непосредственно из mltask.py. Обновите блок сигнала post_save до следующего вида:
@receiver(post_save, sender=Document)
def user_created_handler(sender, instance, *args, **kwargs):
ml_celery_task.delay(str(instance.file.file))Чтобы протестировать Celery, развернем проект!
В корневой каталог проекта включите Dockerfile и файл heroku.yml, указанные в репозитории. Что особенно важно, редактирование команд heroku.yml позволит вам настроить веб-процесс Gunicorn и рабочий процесс Celery. Это поможет в дальнейшей минимизации потенциальных проблем.
Заведите аккаунт на Heroku, создайте новое приложение под названием “mlapp” и примените команду gitignore к файлу .env. Затем инициализируйте git в корневой папке проекта и измените heroku stack (стек приложения Heroku) на container (контейнер), чтобы развернуть с помощью Docker:
$ heroku login
$ git init
$ heroku git:remote -a mlapp
$ git add .
$ git commit -m "initial heroku commit"
$ heroku stack:set container
$ git push heroku masterПосле пушинга нужно добавить переменные env в приложение Heroku.
Перейдите к настройкам в онлайн-интерфейсе, прокрутите вниз до Config Vars, нажмите Reveal Config Vars и добавьте каждую строку, указанную в файле .env.

Возможно, вы заметили, что в файле celery.py указана переменная CLOUDAMQP_URL. Вам нужно обеспечить Celery Broker на Heroku, для чего предлагается множество вариантов. Я использовал CloudAMQP — брокер бесплатного уровня (free tier). Можете добавить его в свое приложение. После добавления переменная среды CLOUDAMQP_URL будет автоматически включена в Config Vars.
Теперь протестируйте конечный продукт.
Чтобы отследить запросы, выполните команду:
$ heroku logs --tailОтправьте еще один POST-запрос Postman к url приложения Heroku в конечной точке /api/create/. Вы увидите, как POST-запрос достигнет свой цели, Celery получит задание, загрузит модель и начнет запускать страницы:

Вы будете видеть сообщение “Running for page…” (“Запуск страницы…”) до конца процесса и сможете проверять бакет AWS S3 по мере выполнения.
Поздравляем! Вы развернули и запустили бэкенд на Python с использованием машинного обучения как часть распределенной очереди задач, работающей параллельно с основным веб-процессом!
Как уже говорилось, вам следует скорректировать команды heroku.yml, чтобы включить потоки и/или рабочие процессы Gunicorn и тонко настроить Celery.
Читайте также:
- Как исследовать и визуализировать данные МО для обнаружения объектов на изображениях
- ULTRA: базовые модели для формирования рассуждений на графах знаний
- Почему стоит упрощать проекты МО
Читайте нас в Telegram, VK и Дзен
Перевод статьи Noah Haglund: Designing and Deploying a Machine Learning Python Application (Part 2)





