
Больше полугода заняло у меня выполнение бизнес-кейса, для чего потребовалось сделать машиночитаемыми PDF-документы. Пришлось извлекать из них заголовки/тайтлы (тексты, определяющие разделы), а также связанный с ними контент, формируя таким образом некое подобие реляционной структуры данных.

Первоначально я использовал сверточную нейронную сеть (CNN), а также комбинацию CNN и рекуррентной нейронной сети (RNN) для классификации структуры документа с помощью текста и его характеристик (шрифта, размера шрифта, веса и т. д.). Фреймворк, реализованный для этих целей Рахманом и Финином, не ограничивается выводом структуры документа, а использует долгую краткосрочную память (LSTM) для семантической классификации определенных разделов. Проблема заключалась в том, что у меня не было ни времени, ни сил на подготовку и аннотирование достаточного количества данных, чтобы создать точные модели с использованием подобного фреймворка.
Применение компьютерного зрения помогло значительно упростить этот процесс. Вместо того чтобы извлекать текст с его характеристиками из PDF и таким образом выводить структуру документа, я преобразовывал PDF-страницы в изображения, выводил структуру документа визуально с помощью обнаружения объектов, а затем посредством оптического распознавания символов (OCR) получал соответствующие выводы, включая заголовки страниц и связанный с ними контент. В этой статье расскажу, как выполнить все это с помощью Detectron2.
Detectron2 — библиотека нового поколения от Facebook AI Research, которая упрощает процесс создания приложений компьютерного зрения. Используя возможности компьютерного зрения (распознавание изображений, семантическая сегментация, обнаружение объектов и сегментация экземпляров), я покажу, как обучить пользовательскую модель Detectron2 обнаружению объектов, которые легко отличить от других благодаря применению ограничительных рамок. Во второй части статьи вы узнаете, как контейнеризовать приложение и развернуть его на Heroku/AWS. Мы рассмотрим такие аспекты, как управление памятью и пакетный вывод, что позволит настроить скрипты и модель для конкретного случая использования.
Чтобы следовать этому руководству, необходимо предварительно изучить:
- Python.
- Django и Docker для процесса развертывания (рассматривается во второй части статьи).
- AWS.
Установка Detectron2
Если вы пользователь Mac или Linux, вам повезло. Процесс установки будет относительно простым — достаточно выполнить следующую команду:
pip install torchvision && pip install
"detectron2@git+https://github.com/facebookresearch/detectron2.git@v0.5#egg
=detectron2"Учтите, что эта команда компилирует библиотеку, поэтому вам придется немного подождать. Если хотите установить Detectron2 с поддержкой GPU, воспользуйтесь подробной информацией в официальной инструкции по установке Detectron2.
Если вы пользователь Windows, процесс установки будет несколько хлопотным, хотя я сам справился с этой задачей.
Следуйте изложенным здесь инструкциям по установке пакета Layout Parser для Python (этот пакет также полезно использовать, если вы не хотите обучать свою модель Detectron2 выводу структуры/контента PDF и полагаетесь на предварительно аннотированные данные; такой подход требует больше времени, но в отдельных случаях можно самостоятельно обучить гораздо более точную и компактную модель, что пригодится при управлении памятью во время развертывания, о чем я расскажу позже). Убедитесь, что вместе с Detectron2 установили pycocotools, так как этот пакет поможет реализовать загрузку, парсинг и визуализацию данных в формате COCO, необходимом для обучения модели Detectron2.
Во второй части будем рассматривать локальную установку Detectron2, а здесь сосредоточимся на экземпляре AWS EC2 для обучения Detectron2.
Аннотирование с помощью LabelMe
Для аннотирования изображений необходимы изображения, которые нужно аннотировать, и сам инструмент для аннотирования. Соберите каталог с изображениями, которые нужно аннотировать. Если хотите следовать моему примеру и использовать PDF-изображения, соберите каталог с PDF-файлами. Установите пакет pdftoimage:pip install pdf2image
Затем используйте следующий скрипт для конвертирования каждой PDF-страницы в изображение:
import os
from pdf2image import convert_from_path
# Присвойте input_dir каталогу с PDF, например "C://Users//user//Desktop//pdfs"
input_dir = "##"
# Присвойте output_dir каталогу, в котором хотите сохранять изображения
output_dir = "##"
dir_list = os.listdir(input_dir)
index = 0
while index < len(dir_list):
images = convert_from_path(f"{input_dir}//" + dir_list[index])
for i in range(len(images)):
images[i].save(f'{output_dir}//doc' + str(index) +'_page'+ str(i) +'.jpg', 'JPEG')
index += 1Теперь, когда у вас есть каталог с изображениями, можно воспользоваться инструментом LabelMe (инструкции по его установке приведены здесь). После установки запустите команду labelme из командной строки или терминала. Откроется окно с таким шаблоном:
Кликните на “Open Dir” (“Открыть каталог”) слева и откройте каталог, в котором сохранены изображения. Назовем этот каталог “Train” (“обучающие данные”). LabelMe откроет первое изображение в каталоге и позволит сделать аннотацию к каждому из них. Кликнув правой кнопкой мыши на изображении, увидите различные варианты аннотаций. Например, опция “Create Polygons” (“Создать многоугольники”) позволяет кликнуть по каждой точке многоугольника вокруг определенного объекта на изображении, а “Create Rectangle” (“Создать прямоугольник”) — захватить объект фигурой с углами в 90 градусов.
После размещения ограничительной рамки/многоугольника LabelMe попросит ввести метку. В примере ниже я указал заголовок метки для каждого экземпляра заголовка на странице. Можете использовать несколько меток, идентифицируя различные объекты, найденные на изображении (в PDF-документе это могут быть заголовки/тайтлы, таблицы, абзацы, списки и т. д.). В данном примере будем просто идентифицировать заголовки/тайтлы и алгоритмически связывать каждый заголовок с соответствующим ему контентом после вывода модели (см. часть 2).
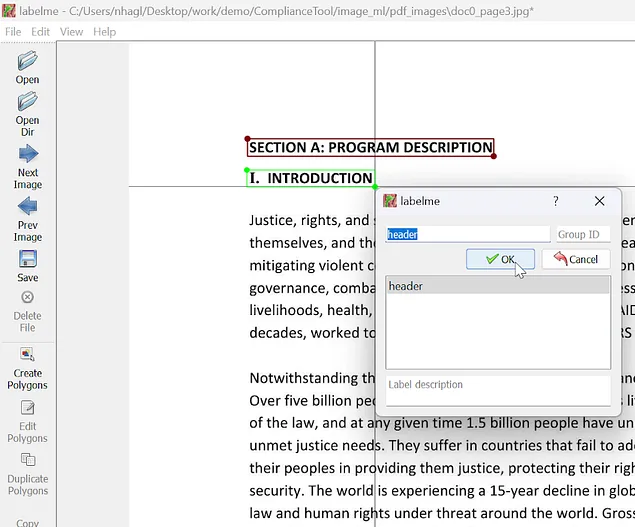
После введения меток нажмите кнопку “Save” (“Сохранить”), а затем кнопку “Next Image” (Следующее изображение”), чтобы перейти к аннотированию следующего изображения в данном каталоге. Detectron2 отлично справляется с определением выводов при минимальном количестве данных, поэтому можете аннотировать до 100 изображений для первоначального процесса обучения и тестирования, а затем продолжить аннотирование и обучение, чтобы повысить точность модели. Только имейте в виду, что обучение модели на более чем одной категории меток немного снижает точность, поэтому для повышения точности требуется больший набор данных.
После аннотирования каждого изображения в каталоге “Train”, возьмем около 20% пар “изображение/аннотация” и перенесем их в отдельный каталог, помеченный как “Test” (тестируемые данные).
Если вы знакомы с машинным обучением, то знаете, что, согласно простому эмпирическому правилу, необходимо разделение данных для тестирования/обучения/оценки (10–20% — для тестирования, 60–80% — для обучения, 10–20% — для оценки). В данном случае выполним разделение данных на две группы: 20% для тестирования и 80% для обучения.
Формат COCO
Теперь займемся преобразованием аннотаций labelme в формат COCO. Это можно сделать с помощью файла labelme2coco.py в репозитории, размещенном здесь. Я выполнил рефакторинг скрипта Tony607, который теперь конвертирует как полиграммные, так и прямоугольные аннотации (первоначальный скрипт не конвертировал прямоугольные аннотации в формат COCO надлежащим образом).
После загрузки файла labelme2coco.py запустите его в терминале с помощью команды:
python labelme2coco.py path/to/train/folderБудет выведен файл train.json. Запустите команду второй раз для папки “Test” и отредактируйте строку 172 в файле labelme2coco.py, чтобы изменить имя вывода по умолчанию на test.json (иначе перепишется файл train.json).
EC2
После завершения утомительного процесса аннотирования приступим к самой интересной части — обучению!
Если ваш компьютер не оснащен видеокартой Nvidia, потребуется развернуть экземпляр EC2 на AWS. Модель Detectron2 можно обучить на процессоре, но это займет очень много времени, тогда как при использовании Nvidia CUDA для экземпляра на GPU обучение модели занимает считанные минуты.
Для начала войдите в консоль AWS, затем найдите EC2 в строке поиска, чтобы перейти на панель EC2. Здесь в левой части экрана кликните “Instances” (“Экземпляры”), а затем нажмите кнопку “Launch Instances” (Запуск экземпляров”).
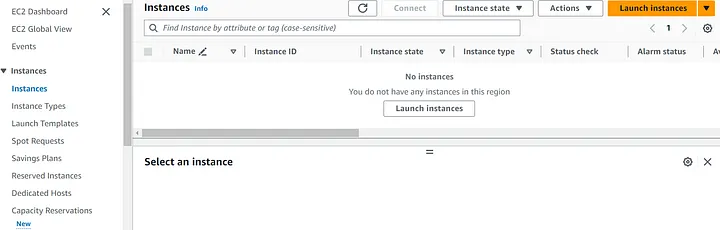
Минимальное количество параметров, необходимое для запуска экземпляра:
- Name (Имя).
- Amazon Machine Image (AMI): здесь указывается конфигурация программного обеспечения. Убедитесь, что используете AMI с возможностями GPU и PyTorch, поскольку в этом случае будут содержаться пакеты, необходимые для CUDA, и дополнительные зависимости для Detectron2, такие как Torch. Чтобы следовать этому руководству, также воспользуйтесь AMI Ubuntu. Я использовал AMI — Deep Learning AMI GPU PyTorch 2.1.0 (Ubuntu 20.04).
- Instance type (Тип экземпляра), который определяет конфигурацию оборудования. Ознакомьтесь с руководством по различным типам экземпляров здесь. Нам надо использовать экземпляр, оптимизированный с целью повышения производительности, например из семейства экземпляров P или G. Я использовал p3.2xlarge, который обладает всей вычислительной мощностью, а точнее возможностями GPU, которые нам понадобятся.
Примечание: экземпляры семейства P потребуют обращения в службу поддержки AWS для увеличения квоты (поскольку базовым пользователям не сразу предоставляется доступ к более производительным экземплярам из-за связанных с этим расходов). При использовании экземпляра p3.2xlarge нужно будет запросить увеличение квоты до 8 vCPU.
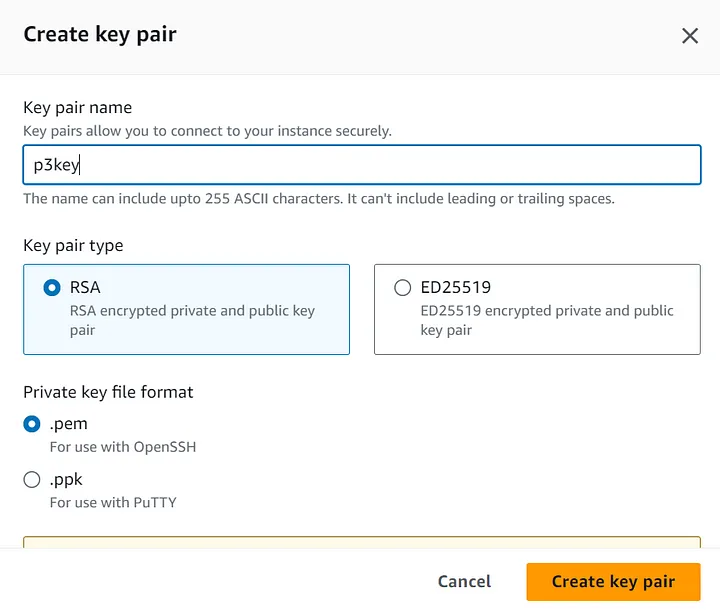
- Key pair (login) — пара ключей (логин). Создайте свой логин, если у вас его еще нет, или воспользуйтесь моим — p3key.
- Configure Storage — настройка хранилища. Если вы использовали те же AMI и тип экземпляра, что и я, то увидите, что размер начального хранилища по умолчанию составляет 45 Гб. Можете увеличить это значение до 60 Гб и больше в зависимости от размера обучающего набора данных, чтобы обеспечить экземпляру достаточно места для хранения изображений.
Запустите экземпляр и щелкните по гиперссылке с идентификатором экземпляра, чтобы увидеть его на панели EC2. Когда экземпляр будет запущен, откройте окно командной строки и выполните вход по SSH в экземпляр EC2 с помощью следующей команды (не забудьте заменить текст, выделенный жирным, на (1) путь к паре ключей .pem и (2) адрес экземпляра EC2):

Поскольку это новый хост, ответьте “yes” (“да”) на следующее сообщение:

После этого Ubuntu запустится вместе с готовой виртуальной средой PyTorch (из AWS AMI). Активируйте venv и запустите предустановленный ноутбук Jupyter с помощью следующих двух команд:

В результате получите URL-адреса, которые нужно скопировать и вставить в браузер. Скопируйте в браузер URL с localhost и измените 8888 на 8000. Это приведет вас в ноутбук Jupyter, который выглядит примерно так:
Из репозитория на GitHub загрузите файл Detectron2_Tutorial.ipynb в ноутбук. Отсюда выполните строки под заголовком Installation (“Установка”), чтобы полностью установить Detectron2. Затем перезапустите среду выполнения для активации.
Вернувшись в перезапущенный ноутбук, загрузите несколько дополнительных файлов, прежде чем начать процесс обучения.
- Файл utils.py из репозитория GitHub. Он содержит файлы .ipynb с деталями конфигурации для Detectron2 (если вас интересуют особенности конфигурации, посмотрите документацию здесь). Также в этот файл включена функция plot_samples, на которую есть ссылка в файле .ipynb, хотя она была закомментирована в обоих файлах. Можете раскомментировать ее и использовать для построения графов обучающих данных, чтобы увидеть визуальное отображение образцов в процессе работы. Имейте в виду, что для использования функции plot_samples потребуется дополнительно установить cv2.
- Файлы train.json и test.json, созданные с помощью скрипта labelme2coco.py.
- zip-файлы с каталогами изображений “Train” и “Test” (архивирование позволяет загрузить в ноутбук только один элемент; можете сохранить файлы аннотаций labelme в каталоге, это не повлияет на процесс обучения). После загрузки обоих zip-файлов откройте терминал в ноутбуке, нажав (1) “New” (“Новый”), а затем (2) “Terminal” (“Терминал”) в правом верхнем углу ноутбука, и с помощью следующих команд разархивируйте каждый из файлов, создав в ноутбуке отдельные каталоги изображений “Train” и “Test”:
! unzip ~/train.zip -d ~/
! unzip ~/test.zip -d ~/Наконец, запустите ячейки ноутбука в разделе “Training” (“Обучение”) в файле .ipynb. Последняя ячейка выдаст ответы, похожие на следующие:
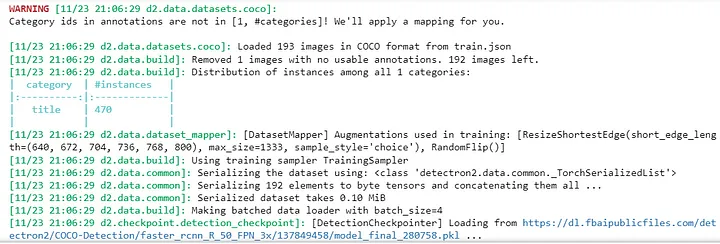
Так вы увидите количество изображений, используемых для обучения, а также количество экземпляров, которые вы аннотировали в обучающем наборе данных (здесь было найдено 470 экземпляров категории “title” до обучения). Затем Detectron2 сериализует данные и загружает их партиями, как указано в конфигурациях (utils.py).
Как только начнется обучение, вы увидите, как Detectron2 выводит события:
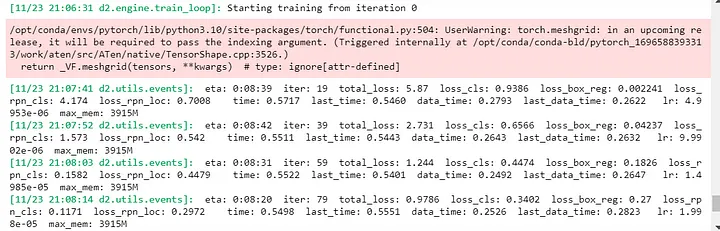
Так вы узнаете следующие данные: предполагаемое оставшееся время обучения, количество итераций, выполненных Detectron2, и, что наиболее важно для контроля точности, total_loss — индекс других вычислений потерь, показывающий, насколько плохим было предсказание модели на одном примере. Если предсказание модели идеально, то потери равны нулю, в противном случае потери больше. Не расстраивайтесь, если модель не окажется идеальной! Вы всегда можете добавить больше аннотированных данных, чтобы повысить точность модели, или использовать выводы финальной обученной модели, которые получили высокий балл (показывающий, насколько модель уверена в точности вывода) в приложении.
После завершения работы в ноутбуке будет создан каталог с названием “Output” (“Вывод”), в котором будет подкаталог “Object detection” (“Обнаружение объектов“), содержащий файлы, связанные с событиями обучения и метриками, файл, фиксирующий контрольную точку для модели, и файл .pth с названием model_final.pth. Последний файл — это сохраненная и обученная модель Detectron2, которую теперь можно использовать для выводов в развернутом приложении! Обязательно загрузите этот файл перед выключением или завершением работы экземпляра AWS EC2.
Теперь, когда у вас есть model_final.pth, не пропустите 2-ю часть статьи, в которой будет рассмотрен процесс развертывания приложения, использующего модель машинного обучения, а также даны несколько ключевых советов о том, как сделать этот процесс эффективным.
Читайте также:
- Как освоить машинное обучение
- Как исследовать и визуализировать данные МО для обнаружения объектов на изображениях
- Как выбрать язык программирования для проекта машинного обучения
Читайте нас в Telegram, VK и Дзен
Перевод статьи Noah Haglund: Training and Deploying a Custom Detectron2 Model for Object Detection Using PDF Documents (Part 1: Training)





