
Должен признаться, что поначалу скептически относился к способности больших языковых моделей (LLM) генерировать действительно работающие фрагменты кода. Поэтому, решив поэкспериментировать с LLM, приготовился к худшему, но был приятно удивлен. Как и при любом взаимодействии с чат-ботом, способ формулирования запроса имеет значение, но со временем приходит понимание, как определить границы задачи, в решении которой нужна помощь.
Я уже стал привыкать к тому, что чат-боты всегда доступны во время написания кода, когда мой работодатель ввел общекорпоративное правило, запрещающее сотрудникам пользоваться этим сервисом. Тогда я решил создать локально работающий сервис LLM, который можно было бы опросить без утечки информации за пределы компании. Благодаря предложению LLM с открытым исходным кодом на HuggingFace и проекту chainlit, мне удалось собрать сервис, помогающий в написании кода.
Следующим логическим шагом было добавление голосового взаимодействия. Хотя голос — не совсем то, что ожидается от помощника в написании кода (вам нужно видеть сгенерированные фрагменты кода, а не слышать их), в некоторых творческих проектах требуется помощь в обретении вдохновения. Ощущение того, что вам рассказывают историю, придает рабочему процессу дополнительную ценность. Особенно это важно в ситуациях, когда вы не хотите пользоваться онлайн-сервисом, чтобы сохранить конфиденциальность своих действий.
В этой статье я расскажу о том, как создать помощника, который позволит вокально взаимодействовать с LLM с открытым исходным кодом. Все компоненты будут работать локально на вашем компьютере.
Архитектура
Архитектура включает три отдельных компонента:
- сервис обнаружения “пробуждающего” слова, активирующего голосового помощника (wake-word detection service);
- сервис голосового помощника (voice assistant service);
- чат-сервис (chat service).
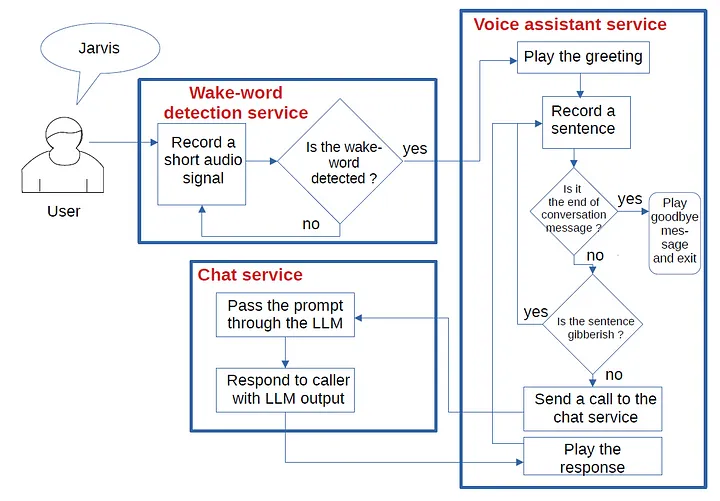
Все три компонента являются отдельными проектами, каждый из которых имеет свой репозиторий на GitHub. Ознакомимся с каждым компонентом и посмотрим, как они взаимодействуют.
Чат-сервис
Чат-сервис запускает LLM с открытым исходным кодом под названием HuggingFaceH4/zephyr-7b-alpha. Сервис получает промпт через POST-вызов, передает его через LLM и возвращает результат в виде ответа на вызов.
Код можно найти здесь.
В папке …/chat_service/server/ переименуйте chat_server_config.xml.example в chat_server_config.xml.
После этого можете запустить чат-сервер следующей командой:
python .\chat_server.py
Первый запуск сервиса занимает несколько минут, поскольку большие файлы загружаются с сайта HuggingFace и сохраняются в каталоге локального кэша.
В терминале получите подтверждение, что сервис запущен:

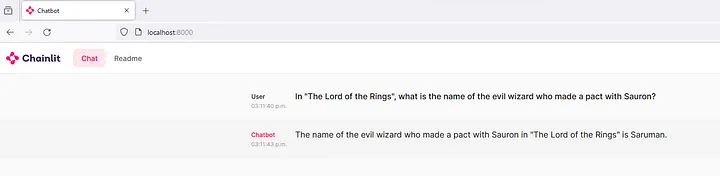
Чтобы проверить взаимодействие с LLM, перейдите по ссылке …/chat_service/chainlit_interface/.
Переименуйте app_config.xml.example в app_config.xml. Запустите сервис веб-чата с помощью:
.\start_interface.sh
Перейдите на локальный адрес localhost:8000.
Возможность взаимодействовать с локально запущенной LLM обеспечит текстовый интерфейс:
Сервис голосового помощника
Сервис голосового помощника — это место, где происходит преобразование речи в текст и текста в речь. Код можно найти здесь.
Перейдите на …/voice_assistant/server/.
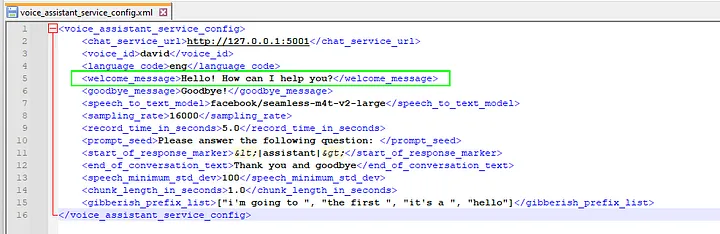
Переименуйте voice_assistant_service_config.xml.example в voice_assistant_service_config.xml.
Помощник начнет воспроизводить приветствие, показывая, что слушает пользователя. Текст приветствия настраивается в файле voice_assistant_config.xml в элементе <welcome_message>:
Модуль речевого воспроизведения текста, позволяющий программе озвучивать текст голосом, который можно услышать через устройство вывода звука, — это pyttsx3. Я убедился в том, что этот модуль достаточно естественно интонирует речь, как английскую, так и французскую. В отличие от других пакетов, которые полагаются на вызов API, он работает локально.
Модель под названием facebook/seamless-m4t-v2-large выполняет преобразование речи в текст. Веса модели загружаются при первом запуске voice_assistant_service.py.
В основном цикле voice_assistant_service.main() выполняются следующие задачи.
- Получение предложения от микрофона. Преобразование его в текст с помощью модели преобразования речи в текст.
- Проверка того, произнес ли пользователь сообщение, заданное в элементе <end_of_conversation_text> из файла конфигурации. Если да, разговор заканчивается, и программа завершает работу после воспроизведения сообщения о прощании.
- Проверка того, не является ли предложение информационным мусором. Часто модуль преобразования речи в текст выдавал правильное английское предложение, даже если я ничего не говорил. По случайности эти нежелательные результаты имеют тенденцию повторяться. Например, предложения иногда начинаются с “[“ или “i’m going to”. Я собрал список префиксов, часто ассоциирующихся с такими предложениями, в элементе <gibberish_prefix_list> файла конфигурации (этот список, вероятно, изменится для другой модели преобразования речи в текст). Если входящие аудиоданные начинаются с одного из префиксов в списке, то предложение игнорируется.
- Если предложение не кажется информационным мусором, отправка запроса в службу чата. Воспроизведение ответа.
Основной цикл в файле voice_assistant_service.main():
end_of_conversation = False
while not end_of_conversation:
transcription = get_sentence(
mic_stream, stt_processor, stt_model, device, config.sampling_rate,
config
)
if transcription.lower().replace('.', '').replace('!', '') == config.end_of_conversation_text.lower():
logging.info(f"voice_assistant_service.main(): End of conversation")
end_of_conversation = True
else:
sentence_is_gibberish = False
if transcription[0] == '[':
sentence_is_gibberish = True
for prefix in config.gibberish_prefix_list:
if transcription.lower().startswith(prefix):
sentence_is_gibberish = True
if len(transcription) > 15 and not sentence_is_gibberish:
response = send_request_to_chat_service(config, transcription)
logging.info(f"voice_assistant_service.main(): response = {response}")
play_message(response, engine, config)
goodbye(engine, config)
Сервис обнаружения “пробуждающего” слова
Последний компонент — это сервис, который постоянно прослушивает микрофон пользователя. Когда пользователь произносит “пробуждающее” слово, системный вызов запускает сервис голосового помощника. Сервис обнаружения “пробуждающего” слова запускает меньшую модель, чем модели сервиса голосового помощника. По этой причине имеет смысл сделать так, чтобы сервис обнаружения “пробуждающего” слова работал постоянно, в то время как сервис голосового помощника запускался только при необходимости.
Код сервиса обнаружения “пробуждающего” слова можно найти здесь.
После клонирования проекта перейдите в …/wakeword_service/server.
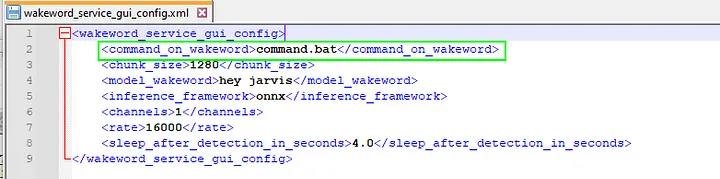
Переименуйте wakeword_service_gui_config.xml.example в wakeword_service_gui_config.xml.
Переименуйте command.bat.example в command.bat. Вам придется отредактировать command.bat так, чтобы активация виртуальной среды и вызов voice_assistant_service.py соответствовали вашей структуре каталогов.
Запустить сервис можно следующим вызовом:
python gui.py
В основе сервиса обнаружения “пробуждающего” слова лежит проект openwakeword. Из нескольких подобных моделей я выбрал модель “hey jarvis” (“Привет, Джарвис”). При этом узнал, что достаточно просто произнести “Jarvis?” для обнаружения “пробуждающего” слова.
При обнаружения “пробуждающего” слова вызывается командный файл, указанный в элементе <command_on_wakeword> конфигурационного файла. В нашем случае файл command.bat активирует виртуальную среду и запускает сервис голосового помощника.
Если вам понадобится использовать сервис обнаружения “пробуждающего” слова для чего-то другого, можете отредактировать файл command.bat, чтобы он запускал любую нужную вам программу.
При обнаружения “пробуждающего” слова сервис издаст двойной звуковой сигнал, указывающий на то, что он сработал. Этот быстрый отклик сообщает пользователю, что он должен подождать, пока модели преобразования текста в речь и речи в текст загрузятся в графический процессор компьютера, что может занять несколько секунд. Когда обе модели загружены, сервис голосового помощника воспроизводит приветствие, и можно начинать разговор. По окончании разговора сервис голосового помощника завершает работу, а сервис обнаружения “пробуждающего” слова издает еще один двойной сигнал.
Когда все три компонента установлены и протестированы, можно запустить чат и сервис обнаружения “пробуждающего” слова. Последний будет постоянно прослушивать микрофон и при обнаружении “пробуждающего” слова (“Джарвис?”) запустит сервис голосового помощника. Можете произносить вопросы вслух и получать на них озвученные ответы. Когда будет обнаружена фраза окончания разговора (“Thank you and goodbye” — “Спасибо, до свидания”), сервис голосового помощника завершит работу.
Пример взаимодействия с голосовым помощником
Вот пример взаимодействия с голосовым помощником:
“Джарвис?”
[пауза в несколько секунд, во время которой загружаются модели сервиса голосового помощника]
“Здравствуйте! Чем я могу вам помочь?”
“Из чего состоят кольца Сатурна?”
“Кольца Сатурна состоят в основном из частиц льда, причем большая часть состоит из водяного льда. Однако в меньшем количестве в кольцах присутствуют и другие виды льда, например аммиачный лед и каменистые обломки. Точный состав колец зависит от расстояния до Сатурна: внутренние кольца плотнее и состоят из мелких частиц, а внешние кольца более разбросаны и содержат более крупные частицы льда”.
“Расскажи мне сюжет фильма “Назад в будущее”.
“В фильме “Назад в будущее” рассказывается история Марти Макфлая, школьника, который случайно переносится в 1955 год на машине DeLorean, созданной его эксцентричным другом-ученым Доком Брауном. Марти должен справиться с проблемами прошлого, одновременно пытаясь восполнить ущерб, нанесенный настоящему, и не дать матери-подростку влюбиться в его отца-подростка. Попутно Марти дружит с более молодой версией Дока Брауна и помогает ему преодолеть личную трагедию. Фильм затрагивает темы судьбы, семьи и последствий изменения прошлого”.
“Спасибо, до свидания”.
“До свидания”.
Заключение
В этом проекте мы реализовали систему голосового помощника, состоящую из сервиса обнаружения “пробуждающего” слова, сервиса голосового помощника и чат-сервиса. Каждый из этих компонентов представляет собой отдельный компоновочный блок, который можно использовать в других проектах.
Среди множества удивительных открытий, которые я испытал во время работы над этим голосовым помощником, больше всего меня поразило качество преобразования речи в текст. Вам, как и мне, наверняка приходилось сталкиваться с системами автоматического распознавания голоса, которые не могут расшифровать такие простые команды, как “Убавь звук!” Поэтому я ожидал, что преобразование речи в текст станет главным камнем преткновения в работе конвейера. Однако, поэкспериментировав с несколькими неудовлетворительными моделями и остановившись на facebook/seamless-m4t-v2-large, был впечатлен качеством результатов. Можно даже произнести предложение на французском языке, и нейронная сеть автоматически переведет его на английский.
Читайте также:
- ExLlamaV2: самая быстрая библиотека для работы с LLM
- Создание чат-бота с помощью LLM и LangChain
- Как я создал расширение браузера и обучил ChatGPT обращаться к внешним сайтам за информацией о текущих событиях
Читайте нас в Telegram, VK и Дзен
Перевод статьи Sébastien Gilbert: Build a Locally Running Voice Assistant


")


