
Конвейеры данных в Geoblink
Кто в Geoblink не любит видео игры! И нет смысла отрицать. Мы любим их настолько, что каждый раз называем в их честь наши спринты ПО. Почему я вам это рассказываю? Да я и сам не знаю. Просто потому, что мы по уши влюблены в свое дело. А еще верим в то, что наша ежедневная работа очень сильно напоминает приключения и предполагает принятие “судьбоносных” решений.
Итак, вся деятельность инженеров данных — это бесконечные приключения. Иногда мы представляем себя умником Гайбрашем Трипвудом, исследующим секреты Острова обезьян. Ведь в нашей сфере тоже встречаются подобные “секреты”, таящиеся за завесой квеста под названием “собери новую ценную информацию из разных источников для пополнения нашей самой любимой сокровищницы — базы данных”. В Geoblink мы занимаемся пространственной аналитикой, которая подразумевает объединение множества датасетов разных форм, размеров и временных характеристик в понятные для наших клиентов данные.
Изначально с ростом компании развивался и процесс сбора данных. На первых порах хватало нескольких общедоступных источников для имеющихся тогда сценариев применения. С течением времени новые источники, разные страны и виды информации постоянно требовали поиска свежих решений.
В этой статье предпринята попытка отразить процесс развития от применения одного основного инструмента для всех задач до более сложного подхода, учитывающего преимущества разных инструментов, разработанных для конкретных ситуаций.
Экскурс в историю Geoblink: Jenkins
Как и в случае с большинством стартапов, самое важное — найти инструмент, подходящий для решения сразу нескольких задач. Обнаружив что-то стоящее, сохраните это и переходите к следующему вопросу. Будни Geoblink такие же суровые, как и в других стартапах: нашел верное работающее средство для достижения цели — сохрани. Для нас такой находкой стал Jenkins.
Jenkins — это автономный сервер с открытым ПО для автоматизации всех процессов, связанных со сборкой, тестированием, поставкой или развертыванием ПО. Несмотря на то, что определение не расходится с действительностью, и этот инструмент стал успешно применяться для конвейеров данных, мы поняли, что Jenkins не совсем подходит для намеченной цели.
С помощью Jenkins мы аккуратно запускали новые конвейеры и решали большинство наших задач, но в какой-то момент столкнулись с ситуацией, когда сервер несколько раз в результате перегрузки выходил из строя, после чего возникали сложности с возобновлением рабочего процесса с места сбоя. В таких случаях нам приходилось вручную удалять загруженные на предыдущих этапах данные и перезапускать весь конвейер. В связи с этим стало понятно, что, несмотря на возможность решения ряда задач с помощью Jenkins, существуют другие инструменты, более подходящие для наших конвейеров данных. В то же время нельзя отрицать, что Jenkins по-прежнему является идеальным вариантом для конвейеров CI/CD.
Попрощавшись с Jenkins, мы обратились к методологии экстремального программирования, использующего простейшие программы для поиска возможных решений, и применили его метод тестирования продукта к различным технологиям в стремлении найти новый инструмент, удовлетворяющий нашим целям. Команда Geoblink успела поэкспериментировать с Jenkins X, Luigi, Airflow и многими другими, не прошедшими жесткий отбор. В конечном итоге мы пошли на риск и выбрали Airflow, который больше всего соответствовал установленным критериям.
Apache Airflow
Согласно документации Airflow является платформой, созданной сообществом для программной разработки, планирования и управления рабочими процессами. Она описывается как масштабируемый, динамический, расширяемый и качественный инструмент, написанный на чистом Python с понятным пользовательским интерфейсом и множеством интеграций.
Прежде всего нашей команде понравились интеграции с внешними сервисами, такими как AWS, GCP, Postgres и т. д., которые изначально предоставляет Airflow. Были охвачены почти все инструменты, в то время практикуемые в Geoblink. Более того, платформа была написана на Python, на котором мог программировать почти каждый участник команды.
Также стоит отметить простоту UI и способы урегулирования сбоев. И хотя понять обработку start date/execution date в Airflow было не так просто, все остальные функциональные возможности (операторы, хуки и т. д.) в точности отвечали нашим требованиям.
Kubernetes
Kubernetes предоставляет гибкие возможности и свободу, необходимые для качественного развертывания и масштабирования сервисов. Для этих же целей она нужна нам и в Geoblink.
Kubernetes — это портативная расширяемая платформа с открытым исходным кодом для управления контейнеризованными рабочими нагрузками и сервисами, которая облегчает как декларативную настройку, так и автоматизацию. У платформы есть большая, быстро растущая экосистема. Сервисы, поддержка и инструменты Kubernetes широко доступны.
Она давно уже вошла в нашу практику и активно применяется всеми командами.
Курс на Остров обезьян: Airflow на Kubernetes
Вернемся к нашей миссии. Распутье и тупики… Остался позади Остров вечной борьбы, также известный как “конвейеры данных на Jenkins”, и, несмотря на осторожность и продуманные решения, на пути к Острову обезьян не замедлили появиться новые препятствия. Нас обуревали сомнения по поводу поведения Airflow при запуске на Kubernetes. Как известно, все, что выполняется на этой платформе, должно быть отказоустойчивым, позволяя продолжать рабочий процесс как ни в чем не бывало, когда под выходит из строя. А можете быть уверены, что такое когда-нибудь произойдет.
Не успели мы принять решение о развертывании Airflow на Kubernetes, как на горизонте возникло самое первое испытание. Наши первые тесты на Airflow всегда выполнялись на локальных машинах, запускающих docker-контейнеры. Ограничившись лишь знакомством с документацией, нам нужно было определить, какой исполнитель — механизм Airflow, отвечающий за выполнение экземпляров задач — подойдет нам лучше всего.
Поскольку большинство разработчиков команды отлично владели Python, на котором также написан и Airflow, было принято решение в пользу LocalExecutor, к помощи которого мы уже прибегали в первых тестах на локальном уровне.
LocalExecutor
Этот планировщик периодически включается в работу и решает, какая задача должна выполняться, порождая каждую из них в виде локального процесса с собственным PID. LocalExecutor рассматривает запускаемый под как один экземпляр, в котором все процессы могут осуществляться параллельно, при этом распараллеливание должно выполняться ОС в обычном для процессов режиме — с конкурированием за CPU и/или память. Как вы уже догадались, этот вариант далек от оптимального. Несколько процессов сражаются за главный трофей CPU: блокировки, семафоры… Что ж, это мы переживем, ведь никто не говорил, что будет легко.
Работая с LocalExecutor, мы столкнулись еще с рядом проблем. Суть первой заключалась в том, что все конвейеры (в Airflow они представлены в виде ориентированных ациклических графов — DAG’ов) были ограничены версией Airflow и его зависимостями, в связи с чем при их обновлении/установке у команды возникали определенные сложности. Какое-то время мы могли с этим справляться, хотя понимали, что улучшений будет добиться сложнее.
Еще одна проблема, на этот раз повышенной важности, возникла, когда мы стремились к поддержке непрерывности потока разработки с помощью принципа CI/CD, позволяющего нам развертывать новые возможности сразу после подтверждения командой их готовности к слиянию. Когда новый под Airflow с новыми возможностями достигает этой стадии готовности, его текущая активная версия со всеми выполняющимися процессами удаляется из Kubernetes. Несмотря на то, что наша внешняя база данных Airflow содержит информацию обо всех этих процессах, все выполняющиеся задачи удаляются, в связи с чем оказываются в состоянии сбоя.
Пример
Рассмотрим пример насторожившей нас проблемы. Воспроизведем новое развертывание Airflow в определенный момент выполнения задачи, чтобы определить, отвечает ли LocalExecutor нашим требованиям.
Обратите внимание, что у нас используется KubernetesPodOperator — в следующих разделах вы узнаете, почему выбор был сделан в его пользу — поэтому все выполняемые задачи создадут новый под, с помощью которого мы увидим, что происходит в кластере.
Сначала необходимо выполнить DAG и проверить запущенные поды:
> kubectl get pods
NAME READY STATUS RESTARTS AGE
svc-airflow-db-76c744b454-qs7ds 1/1 Running 0 5m46s
svc-airflow-master-79f8c4d87d-tm8s5 1/1 Running 0 5m46s
test1–06144c19 0/1 ContainerCreating 0 1sКак и ожидалось, Airflow выполняется в выделенном поде с именем svc-airflow-master-79f8c4d87d-tm8s5, тогда как база данных — в отдельном экземпляре под именем svc-airflow-db-76c744b454-qs7ds. Такое разделение служб позволяет удалить мастера, не внося беспорядок в базу данных. И, наконец, у нас есть test1-06144c19, т. е. текущая задача, порожденная KubernetesPodOperator.
Как только контейнер test1-06144c19 переходит в состояние Running, мы удаляем мастера Airflow:
> kubectl delete pod svc-airflow-master-79f8c4d87d-tm8s5
pod “svc-airflow-master-79f8c4d87d-tm8s5” deletedПо прошествии нескольких секунд Kubernetes автоматически перезапускает мастера.
> kubectl get pods
NAME READY STATUS RESTARTS AGE
svc-airflow-db-76c744b454-qs7ds 1/1 Running 0 6m8s
svc-airflow-master-79f8c4d87d-4mdqv 0/1 Running 0 15s
test1–06144c19 1/1 Running 0 23sНа подготовку процесса мастера требуется время, поэтому в доступе к UI отказано:
По мере готовности пода мастера UI отображает корректную информацию, так как база данных знает, что был выполняющийся контейнер с указанным PID:

Ниже частично представлена информация о задаче, содержащая в том числе и PID:
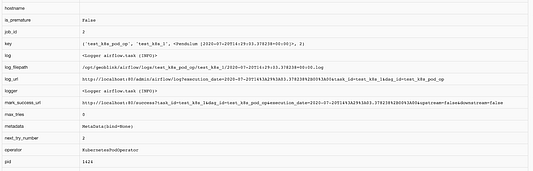
К сожалению, спустя некоторое время — которое зависит от длительности процесса, использующего старый PID в новом поде — UI показывает сбой, т. е. несмотря на то, что задача была успешна — она выполнила только команду sleep.

Достигнув этого момента, мы поняли, что первоначально избранный путь завел нас в тупик. В одних случаях данный способ срабатывал, а в других усложнял автоматическое развертывание изменений, например блокировал развертывание при выполняющихся DAG’ах/задачах. Так не пойдет! Ради счастья и мотивации нашей команды необходимо было найти исполнителя получше, чтобы развертывание кода происходило без упомянутых проблем.
KubernetesExecutor
Начиная с версии 1.10.0, Airflow предоставляет новый вид исполнителя, а именно KubernetesExecutor, позволяющего запускать в поде одну любую задачу. Он никак не влияет на работу нашей команды, поскольку запускает тот же код, который был написан для LocalExecutor, но только в других подах. Как раз то, что надо! Airflow подключается к исполняемой задаче, т. е. поду, через имя хоста, созданное одновременно с подом.
Тем не менее мы по-прежнему ограничены зависимостями, установленными в репозитории Airflow. Что делать? Как уже упоминалось, Airflow порождает новый под для каждой задачи. И для всех задач существует один docker-образ, определяемый параметром worker_container_repository в конфигурации Airflow. Следовательно, все запущенные поды будут использовать общие зависимости.
Теперь нужно убедиться, что KubernetesExecutor поможет решить нашу актуальную проблему. Для этого мы сымитируем ту же ситуацию, т. е. удалим мастера и посмотрим, как он себя поведет во время выполнения задачи.
Пример
При запуске DAG’а можно увидеть следующее:
> kubectl get pods
NAME READY STATUS RESTARTS AGE
svc-airflow-db-76c744b454-m7lcl 1/1 Running 0 3m6s
svc-airflow-master-7dcbbcc86d-6f5x8 1/1 Running 1 3m6s
test1–49c3bb06 0/1 ContainerCreating 0 2s
testk8spodoptestk8s1-e792... 1/1 Running 0 6sКак видно, здесь присутствуют 2 созданных пода. Один из них — это сама задача контроллера testk8podoptestk8s1-e792..., созданная Airflow KubernetesExecutor, а другой — это уже текущая задача, порожденная задачей с именем test1-49c3bb06 — учитывайте, что мы задействуем KubernetesPodOperator.
Как только происходит удаление мастера,
> kubectl delete pod svc-airflow-master-7dcbbcc86d-6f5x8
pod “svc-airflow-master-7dcbbcc86d-6f5x8” deleted
> kubectl get pods
NAME READY STATUS RESTARTS AGE
svc-airflow-db-76c744b454-m7lcl 1/1 Running 0 3m24s
svc-airflow-master-7dcbbcc86d-8dtrb 0/1 Running 0 10s
test1–49c3bb06 1/1 Running 0 20s
testk8spodoptestk8s1-e792... 1/1 Running 0 24sобе задачи продолжают выполняться, пока мастер Airflow перезапускается. Спустя мгновение мы убеждаемся, что мастер готов и снова выполняется
> kubectl get pods
NAME READY STATUS RESTARTS AGE
svc-airflow-db-76c744b454-m7lcl 1/1 Running 0 4m59s
svc-airflow-master-7dcbbcc86d-8dtrb 0/1 Running 0 105s
test1–49c3bb06 1/1 Running 0 115s
testk8spodoptestk8s1-e792... 1/1 Running 0 119sвместе с ожидаемым выполнением DAG’ом.

Спустя несколько секунд в инструменте CLI появляется отметка о завершении одной задачи, при этом вторая еще находится на стадии выполнения.
> kubectl get pods
svc-airflow-db-76c744b454-m7lcl 1/1 Running 0 5m21s
svc-airflow-master-7dcbbcc86d-8dtrb 1/1 Running 0 2m7s
test1–49c3bb06 0/1 Completed 0 2m17s
testk8spodoptestk8s2–95aa449764814a9b84bfd2bf9bf5dd9f 1/1 Running 0 11s
Главное отличие от LocalExecutor состоит в том, что состояние задачи извлекается через вышеуказанное имя хоста, которое после перезапуска мастера остается доступным, поскольку Airflow сохраняет под контроллера до тех пор, пока он не проверит статус.
После выполнения второй задачи Airflow отображает успешное завершение DAG’а.

Напрашивается пиратский клич “Йо-хо-хо”, ведь мы почти достигли Острова обезьян, став свидетелями того, как KubernetesExecutor справился с нашей проблемой №1. Теперь у нас есть возможность безбоязненно развертывать новые функциональности. Чествуя нового исполнителя, наша команда приступает к очередному испытанию: решение вопроса зависимостей.
KubernetesPodOperator
При описании примеров уже упоминалось, что мы работаем с KubernetesPodOperator. Кроме того, оставалась нерешенная проблема из-за отсутствия гибкого подхода в отношении зависимостей. Напряжение в команде возрастало, назревал “бунт”, и вот уже во всю мощь зазвучали призывы обновить библиотеку Pandas до более новой версии.
KubernetesPodOperator создает новую задачу, т. е. под, запуская docker-образ после его извлечения из репозитория. Этот вид оператора предоставляет в наше распоряжение разные образы для разных задач, чтобы эти задачи применяли разные версии одной библиотеки. Благодаря этому также появляется возможность “выполнять” на Airflow несколько языков. Более того, открываются перспективы запуска нескольких процессов CI/CD — по одному на образ/задачу — что позволяет более гибко решать вопросы, а также задействовать наилучшие библиотеки или даже языки программирования, исходя из решаемой задачи.
Другое преимущество, хотя также и небольшой недостаток, заключается в том, что DAG’и становятся легче, проще и несут меньший объем кода, извлекаемого в код самой задачи, сохраняя Airflow в качестве планировщика конвейера данных. Недостаток же заключается в том, что создаваемые образы должны будут обрабатывать все подключения к внешним источникам данных внутри себя, не используя преимущества самого Airflow.
Как бы то ни было, мы достигли этапа, на котором каждый сможет для себя решить, работать ли с Airflow, его операторами, хуками, всеми функциональностями или избрать другой подход, соответствующий решаемой задачей. Мы нашли способ обрести гибкие возможности и преодолеть ограничения в отношении зависимостей/языка.
Заключение
Спустя несколько месяцев, проведенных в поисках лучшего подхода для сборки конвейеров данных, было принято решение в пользу Airflow на Kubernetes и KubernetesExecutor, а также KubernetesPodOperator применительно к особым случаям, когда необходимо выполнить то, что описано в репозитории, без привлечения Airflow и/или его зависимостей. Избранный подход позволил охватить все виды технологий/языков благодаря docker-образам, упростить жизнь команды и раскрыть ее потенциал для создания новых и улучшенных функциональностей.
Читайте также:
- Устранение неполадок в Kubernetes - стратегический подход
- Kubernetes: сэкономьте до 50% с вытесняемыми объектами
- Практичные Canary-релизы в Kubernetes с Argo Rollouts
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Mario Fernández Martínez: Data Pipelines at Geoblink: Productivizing Airflow with Kubernetes





