
Обзор
Сеть Kubernetes — это сложная, увлекательная тема со множеством подвижных частей. Kube-Proxy и CNI — два важных компонента сети Kubernetes, которыми совместно обеспечивается превосходное взаимодействие различных компонентов.
Kube-Proxy — сетевой посредник, запускаемый на каждом узле кластера Kubernetes. За счет преобразования определений служб в действующие сетевые правила им поддерживается сетевая связность служб и подов.
CNI или Container Network Interface — это спецификация для настройки сетевых ресурсов в Kubernetes. В CNI имеется динамическая платформа для выделения IP-адресов, установки межхостового подключения и настройки оверлейных или андерлейных сетей.
Рассмотрим внутренние механизмы Kube-Proxy и CNI, их интегрирование с Kubernetes, а также различные сетевые плагины Kubernetes.
Kube-Proxy — сетевой посредник Kubernetes
В Kubernetes временным характером подов обусловливается изменяемость их IP-адресов, поэтому установление устойчивых соединений затруднительно. Здесь приходятся кстати объекты Service с единым IP-адресом для доступа к подам. Они связаны с группой подов. При поступлении в Service трафик направляется в соответственные поды бэкенда.
Но как это сопоставление Service с подом осуществляется на уровне сети? Через Kube-Proxy.
Kube-Proxy — важный агент Kubernetes, который есть в каждом узле кластера. Основная его роль — отслеживание изменений в объектах Service и соответственных им конечных точках. Затем эти изменения преобразуются им в значимые сетевые правила внутри узла.
Обычно Kube-Proxy находится в кластере в роли DaemonSet. Но в зависимости от типа установки кластера он устанавливается непосредственно и как процесс Linux в узле. Какие бы ни были настройки, с Kube-Proxy сетевой трафик неизменно добирается до нужных адресатов в кластере Kubernetes.
Функционирование Kube-Proxy
После того как Kube-Proxy установлен, организуется аутентификация с сервером API. Когда появляются или удаляются новые Services или конечные точки, эти изменения сразу передаются сервером API в Kube-Proxy, где они принимаются и преобразуются в правила преобразования сетевых адресов NAT внутри узла. Правила NAT — это сопоставления IP-адресов этих Service с IP-адресами подов.
Направляемый к Service трафик придерживается этих правил и приводится к соответственному поду бэкенда.
Проиллюстрируем этот процесс на примере.
Когда создается Service SVC01 с типом ClusterIP, сервером API проверяется — сопоставлением меток с селектором меток Service, — какие поды должны относиться к этому Service. Назовем эти поды Pod01 и Pod02. Впоследствии сервером API создается абстракция — конечная точка с IP-адресом каждого из этих подов, так что SVC01 увязывается с двумя конечными точками — EP01 и EP02.
На заключительном этапе IP-адрес SVC01 сопоставляется сервером API с IP-адресами EP01 и EP02, и соединение между Service и связанными с ним конечными точками закрепляется.
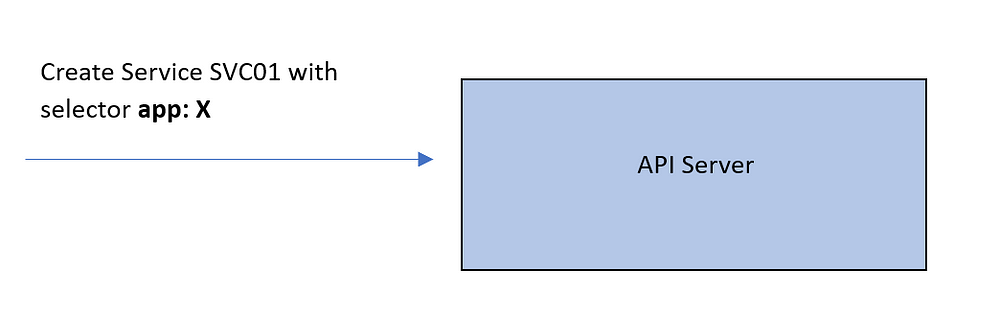
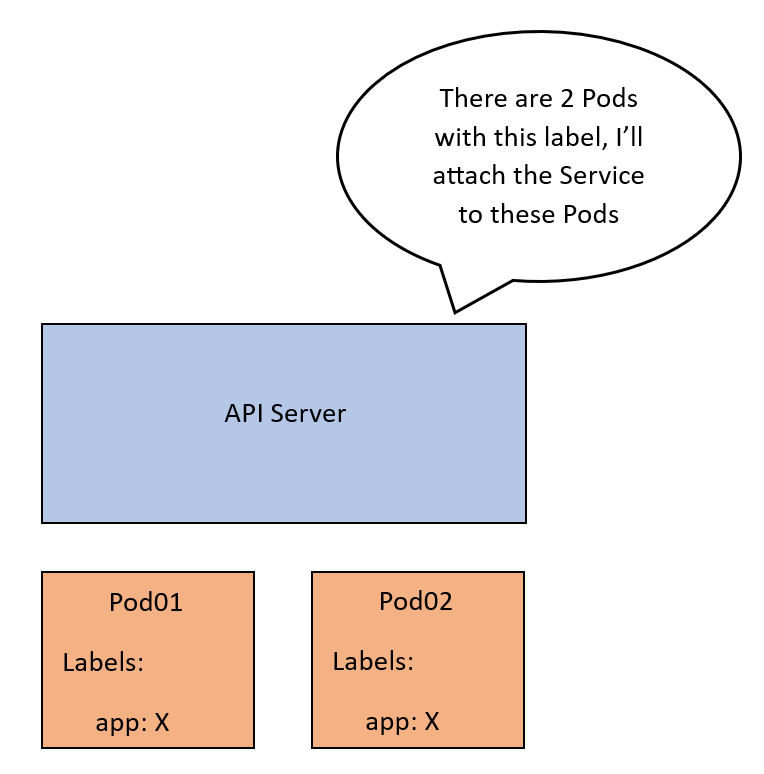
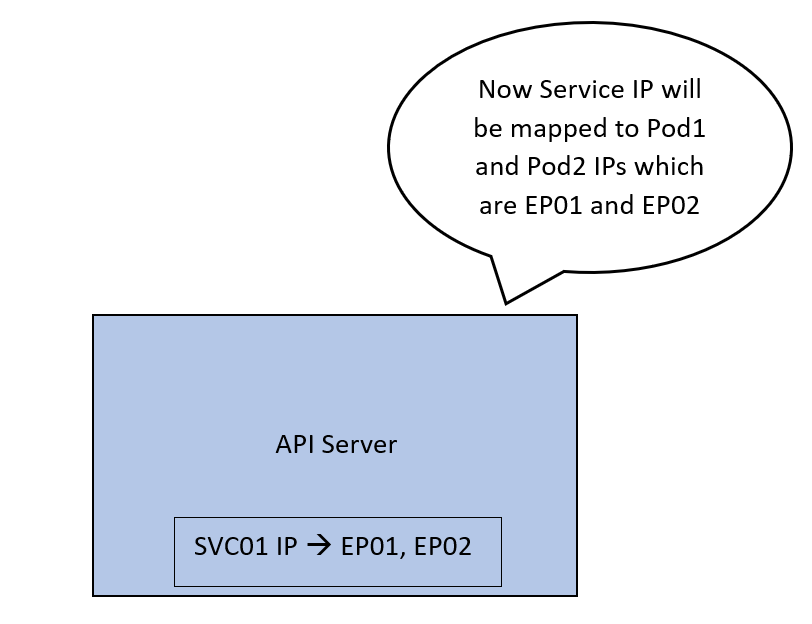
Вся эта конфигурация сейчас лишь часть плоскости управления. Это сопоставление нужно реализовать в сети фактически. Тогда при поступлении в IP-адрес SVC01 трафик перенаправится в EP01 или EP02 и встретится здесь с Kube-Proxy, который сервером API оповещается об этих обновлениях на каждом узле. В узле они применяются как внутренние правила.
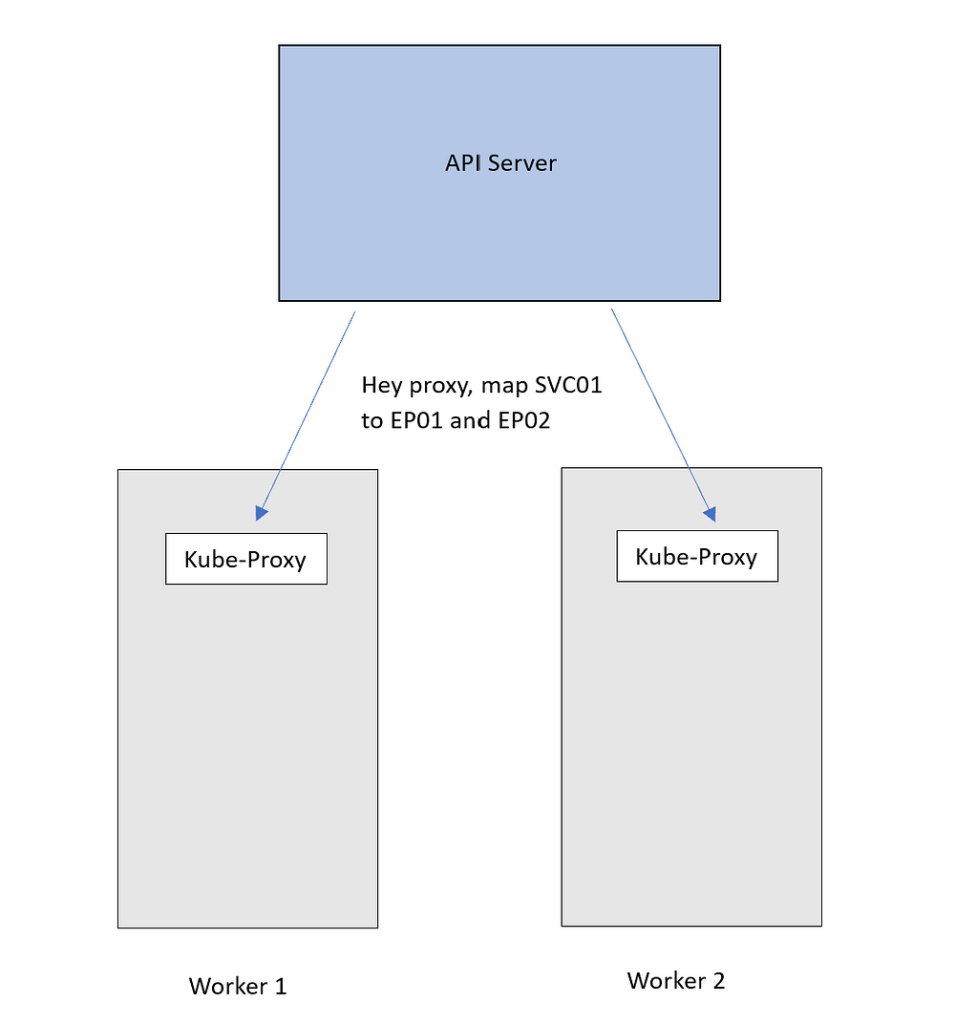
Теперь предназначенный для IP-адреса SVC01 трафик, следуя этому правилу DNAT, перенаправляется в поды. Не забываем, что EP01 и EP02 — это IP-адреса подов.
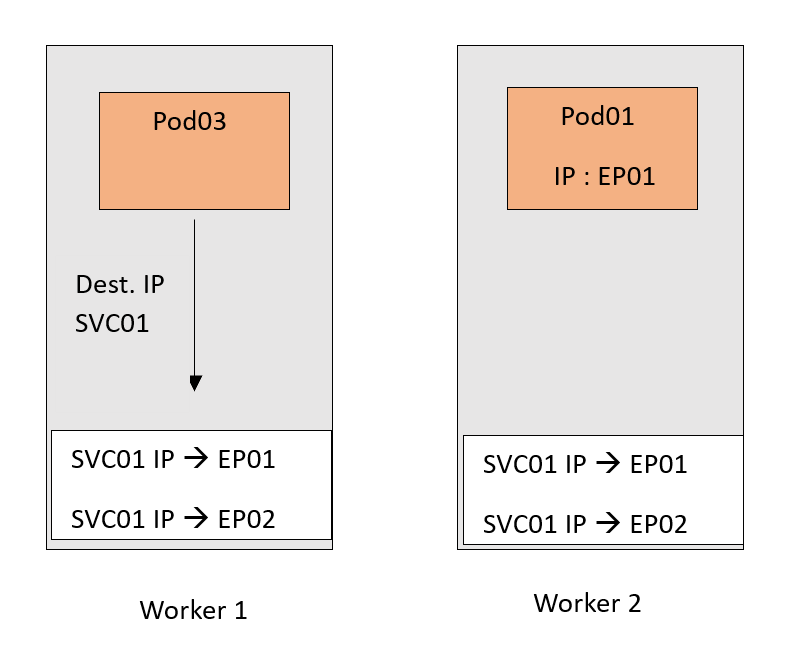
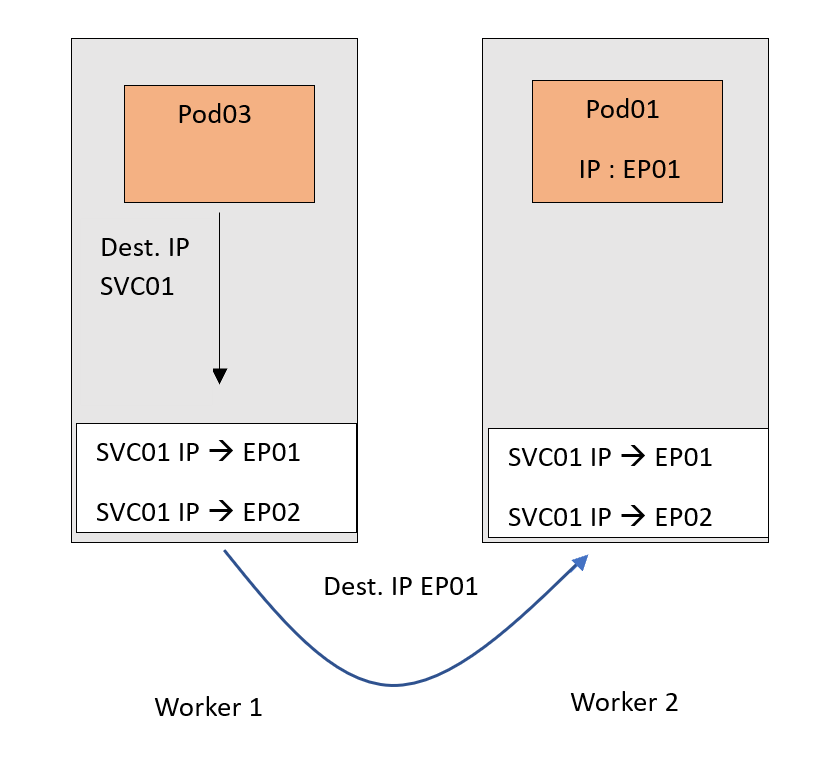
Сценарий упрощен ради важной части Kube-Proxy.
Здесь стоит упомянуть вот о чем:
- Этими Services и конечными точками — сопоставлениями IP-адресов и портов — в Kubernetes обеспечивается корректная маршрутизация трафика к определенным сочетаниям IP-адресов и портов внутри кластера.
- ClusterIP и преобразование DNAT: службами ClusterIP в исходном узле применяется преобразование сетевых адресов назначения DNAT, IP-адреса скрыты от внешнего доступа. Это внутренние правила NAT, доступные исключительно внутри кластера.
- Типы служб и правила узлов: различные типы служб чреваты установкой неодинаковых правил внутри узлов. Эти правила организованы в цепочки, конкретные наборы правил с определенным порядком в пути трафика.
- Случайный выбор подов: для обработки входящего трафика правилами NAT по умолчанию выбирается случайный под. Однако это поведение варьируется в зависимости от выбранного режима Kube-Proxy, которым определяется стратегия балансировки нагрузки для маршрутизации трафика в поды.
Режимы Kube-Proxy
У Kube-Proxy имеются разные режимы, каждый со своим подходом к реализации правил NAT. Разберем нюансы этих режимов:
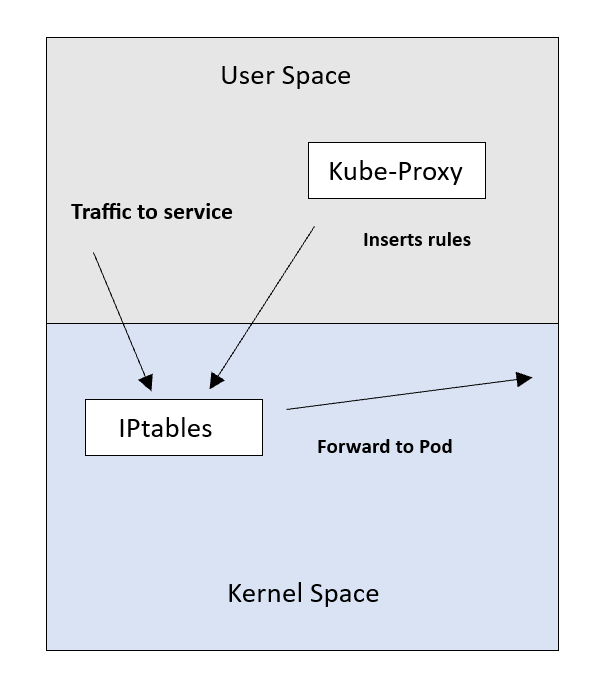
Режим IPtables
Это популярный режим по умолчанию, функционал Linux для обработки и фильтрации пакетов. Здесь правила NAT Service-под вставляются в IPtables, трафик перенаправляется с IP-адреса Service на IP-адрес пода.
Но при большом количестве правил режим IPtables менее эффективен, производительность его последовательного алгоритма становится O(n). Отсутствуют в нем и специальные алгоритмы балансировки нагрузки, где применяется случайное распределение с равной стоимостью.
Роль Kube-Proxy описывается теперь, скорее, как «установщик» правил.
Режим IPVS
IPVS или IP Virtual Server предназначен для балансировки нагрузки с эффективным поиском со сложностью O(1), им обеспечивается стабильная производительность независимо от количества правил. Правила вставляются в этом режиме Kube-Proxy не в IPtables, а в IPVS.
В IPVS поддерживаются различные алгоритмы балансировки нагрузки, такие как циклический перебор round robin и наименьшие соединения. Внимание: в отличие от IPtables, IPVS доступен не во всех системах Linux.
Режим KernelSpace
Этот режим доступен только для Windows nodes. В Kube-Proxy правила фильтрации пакетов вставляются с помощью платформы виртуальной фильтрации Windows.
Аналогичная IPtables на Linux, она ответственна за инкапсуляцию пакетов и замену IP-адреса назначения. Знакомы с виртуальными машинами на платформе Windows? Тогда для вас это расширение коммутатора Hyper-V.
Режим Userspace
Этот режим применялся в Kube-Proxy с самого начала, когда соединения управлялись проксированием их через процесс на уровне пользователя. Несмотря на простоту, этот режим менее эффективен, чем другие: это как ездить на детском велосипеде с поддерживающими колесиками.
У каждого режима Kube-Proxy имеются преимущества и ограничения, при его выборе учитываются задачи и инфраструктура конкретного кластера.
Проверка режима Kube-Proxy
Режим, в котором запущен Kube-Proxy, определяется конечной точкой /proxyMode для запроса информации:
- Подключаемся по SSH к Cluster Node, то есть к одному из узлов кластера Kubernetes.
- Подключившись, запрашиваем режим Kube-Proxy такой командой
curl:
curl -v localhost:10249/proxyMode
Так извлекается информация о Kube-Proxy и проверяется, в каком он сейчас режиме:
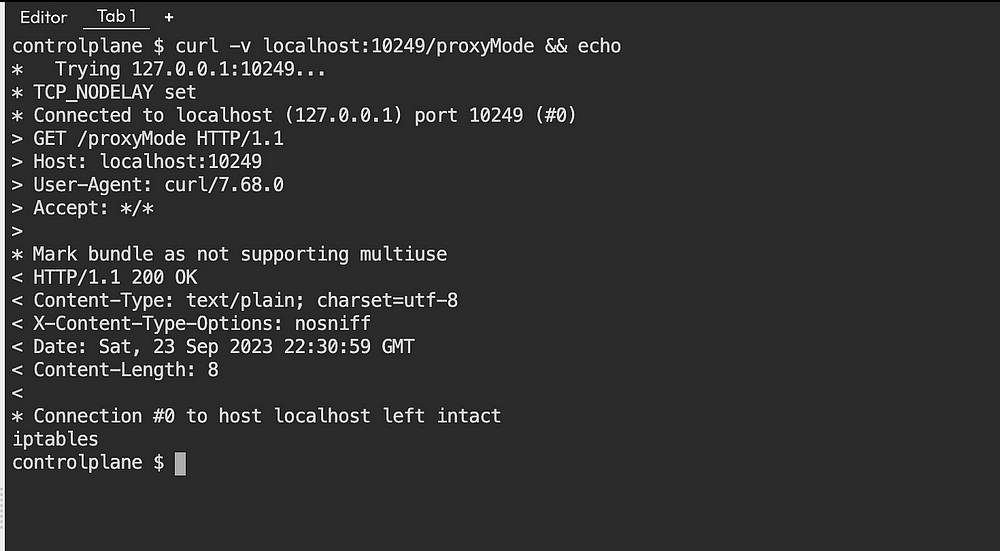
Здесь в последней строке обозначен применяемый Kube-Proxy режим — iptables.
Кратко подытожим: Service и Kube-Proxy в Kubernetes
- Service в Kubernetes аналогичен посреднику: им предоставляется стабильный IP-адрес для клиентских подключений, полученный по этому IP-адресу трафик направляется на соответственный IP-адрес пода бэкенда, чем фактически решается проблема изменений динамических IP-адресов подов.
- Балансировка нагрузки зависит от того, какой рассматривается аспект Kube-Proxy. Самим агентом Kube-Proxy трафик не обрабатывается, не выполняется им и балансировка нагрузки; это прерогатива исключительно плоскости управления, ответственной за создание правил Service. Однако в Kube-Proxy посредством этих правил балансировка нагрузки упрощается: трафик распределяется между несколькими идентичными подами, связанными с конкретным Service. Входящие запросы обрабатываются всеми этими подами-репликами.
Что такое Container Network Interface?
Это фреймворк для динамической настройки сетевых ресурсов в кластерах Kubernetes. Благодаря архитектуре плагинов здесь можно подобрать оптимальные для конкретных задач плагины.
CNI применяется для настройки оверлейных и андерлейных сетей:
- Оверлейными сетями сетевой трафик инкапсулируется с помощью виртуального интерфейса, такого как виртуальная расширяемая локальная сеть
VXLAN. - Андерлейные сети работают на физическом уровне, состоят из коммутаторов и маршрутизаторов.
Как только выбран тип сетевой конфигурации, средой запуска контейнеров определяется сеть, к которой присоединяются контейнеры. В среде запуска интерфейс добавляется к пространству имен контейнера вызовом плагина CNI, подключенные маршруты подсети распределяются вызовом плагина службы управления IP-адресами IPAM.
CNI применяется с Kubernetes и другими платформами контейнерной оркестрации на основе Kubernetes, такими как OpenShift. Взаимодействие контейнеров во всех кластерах унифицируется здесь с помощью технологии программно-определяемых сетей.
Сеть Kubernetes
В Kubernetes имеется сеть для контейнерных приложений с плоской сетевой структурой. С этой сетью не нужно сопоставлять порты хоста и контейнера, а работа распределенной системы возможна без динамического выделения портов.
Сетевая архитектура в Kubernetes основана на спецификации плагина CNI — единого интерфейса среды запуска Kubernetes и базовой сети с поддержкой различных сетевых решений: Flannel, Calico, Weave Net и Cilium.
Работа сети Kubernetes
Когда создается под Kubernetes, плагином CNI настраивается сетевой интерфейс с присвоением поду IP-адреса. Этим облегчается взаимодействие внутри сети подов Kubernetes — плоской сети, доступной всем подам кластера. Кроме того, поды взаимодействуют с внешними приложениями через виртуальную сеть Service Kubernetes с предоставлением подов внешним сущностям.
Преимущества сети Kubernetes:
- Переносимость: кластеры Kubernetes разворачиваются в различных облачных и необлачных средах.
- Масштабируемость: с поддержкой большого количества подов в кластере Kubernetes.
- Надежность: в кластере Kubernetes обеспечивается стабильное подключение подов.
Linux-контейнер и технология контейнерных сетей неуклонно развиваются, чтобы соответствовать задачам запускаемых в различных средах приложений. CNI — это инициатива Cloud-Native Computing Foundation, которым определяется конфигурация сетевых интерфейсов контейнеров Linux.
CNI призван сделать сетевые решения интегрируемыми с разными системами оркестрации и средами запуска контейнеров. Вместо того чтобы делать сетевые решения подключаемыми, им определяется стандарт единого интерфейса как для сетевого уровня, так и для уровня запуска контейнера.
CNI — неродной для Kubernetes фреймворк. Для взаимодействия с различными средами запуска контейнеров разработчики, которыми применяется стандарт CNI, создают сетевые плагины. В сетях CNI используется инкапсулированная сетевая модель, такая как виртуальная расширяемая локальная сеть VXLAN, или неинкапсулированная — называемая также декапсулированной — сетевая модель, такая как протокол граничного шлюза BGP.
Работа CNI
В CNI, чтобы настроить сеть кластера Kubernetes, применяется архитектура плагинов. Плагин CNI занимается созданием и настройкой сетевого интерфейса каждого контейнера. Помимо этого, вызываемым с помощью kubelet плагином CNI при создании контейнера присваивается и добавляется в сеть Kubernetes IP-адрес.
Кроме того, для выделения IP-адресов контейнерам плагин CNI взаимодействует с плагином службы управления IP-адресами IPAM. Сюда относится при необходимости управление пулом доступных IP-адресов и их присвоение. Как только сетевой интерфейс установлен, контейнер с помощью kubelet запускается и может взаимодействовать с другими контейнерами в сети Kubernetes.
CNI фокусируется на связности сети контейнеров и удалении выделенных ресурсов после завершения работы контейнеров. Таким фокусом спецификации CNI упрощаются, их применяемость увеличивается.
Подробнее о спецификациях CNI, сторонних плагинах и средах запуска — в проекте на GitHub.
Необходимость в разных сетевых плагинах Kubernetes
В Kubernetes имеется богатая экосистема сетевых плагинов, многие из которых включены и активно применяются основными платформами оркестрации контейнеров.
Все эти плагины соответствуют строгим стандартам спецификации CNI и важны в обеспечении различных функций сети контейнеров. Учитывая свойственную сетям сложность и широкий диапазон требований пользователей, в CNI предусмотрительно выделили спецификации для нескольких плагинов.
В CNI сети инстанцируются с двумя основными моделями: инкапсулированной и неинкапсулированной.
Инкапсулированная, оверлейная сетевая модель
Эта модель представлена технологиями вроде VXLAN и IPsec, накладывается логической сетью уровня 2 поверх имеющейся топологии сети уровня 3. Таким подходом упрощается маршрутизация, минимизируются затраты.
Данные инкапсуляции распространяются через UDP-порты среди воркеров Kubernetes, для соединения которых с подами создается мост. Дальнейшее взаимодействие внутри подов контролируется при помощи Docker или других контейнерных движков.
Эта инкапсулированная сетевая модель оказывается вполне пригодной в сценариях с мостом уровня 2, особенно чувствительных к временны́м задержкам воркеров Kubernetes в среде уровня 3. В распределенных ЦОД, которыми охватываются различные географические регионы, минимизация задержки важна для предотвращения сегментации сети.
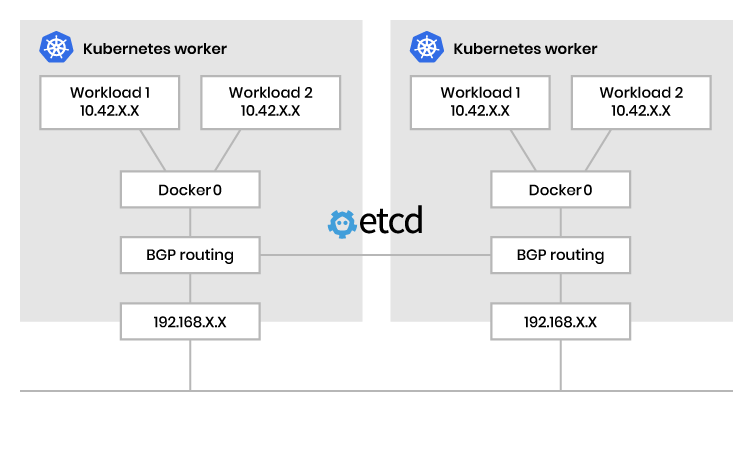
Неинкапсулированная, андерлейная сетевая модель
Этой моделью расширяется сеть уровня 3, облегчается маршрутизация пакетов между контейнерами. В отличие от инкапсулированной модели, здесь не вводится изолированная сеть уровня 2 или связанные с ней затраты. Однако бремя управления необходимым распределением маршрутов полностью возлагается на плечи воркеров Kubernetes.
Чтобы это сработало и информация о маршрутизации эффективно передавалась в поды, вводится сетевой протокол соединения воркеров Kubernetes и применения протокола граничного шлюза BGP. Внутри этих подов контроль взаимодействия с рабочими нагрузками осуществляется с помощью Docker или аналогичного контейнерного движка. Неинкапсулированная сетевая модель идеальна для сценариев с маршрутизируемой сетью уровня 3.
Здесь маршруты для воркеров Kubernetes подвергаются динамическим обновлениям на уровне операционной системы, чем фактически нивелируются проблемы с задержкой. По сути, сеть Kubernetes разворачивается как многоаспектный ландшафт со множеством вариантов плагинов и разнообразными сетевыми моделями, адаптированными к конкретным задачам контейнерных рабочих нагрузок.
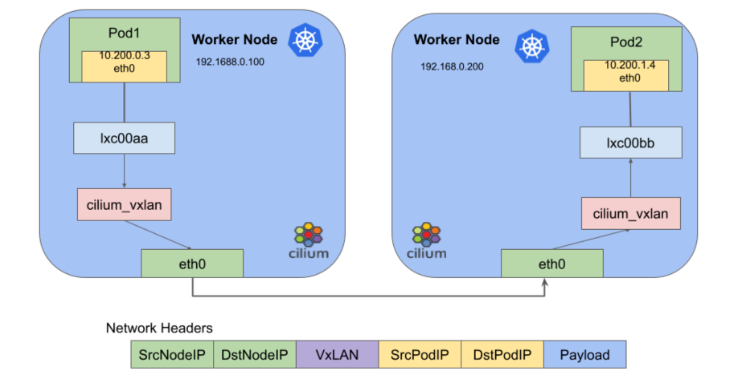
CNI с Cilium

Cilium — проект с открытым исходным кодом для сетевого взаимодействия, безопасности, наблюдаемости кластеров Kubernetes и других контейнеризированных сред.
Он основан на технологии eBPF внедрения прямо в ядро Linux логики сетевого управления, средств контроля безопасности и функционала наблюдаемости.
CNI Cilium — мощный сетевой плагин для Kubernetes, которым обеспечивается повышенная безопасность и сетевые возможности контейнерных приложений. Для сквозной сетевой безопасности и мониторинга трафика им задействуется мощь высокоэффективной программируемой технологии уровня ядра eBPF, сокр. от extended Berkeley Packet Filter.
Для формирования оверлейной сети в Cilium используется VXLAN, для управления сетевой связностью и правилами приложений — этот расширенный пакетный фильтр Беркли, для неинкапсулированной маршрутизации — BGP. А еще поддерживаются адресация по IPv4 и IPv6, несколько кластеров Kubernetes и, подобно Multus, предоставляются возможности нескольких CNI.
В Cilium работают над аспектами сетевого управления, такими как сетевые политики, через фильтры HTTP-запросов. Политики записываются в файлы YAML или JSON, которыми обеспечивается контроль сетевого трафика — входящего и исходящего.
Cilium запускается с VXLAN как оверлейной сетью для инкапсуляции и маршрутизации, а с маршрутизацией BGP — как андерлейной. Раньше для функционала BGP в Cilium применялся metallb, но с версией Cilium 1.3 появилась собственная реализация на GoBGP.
Cilium — единственный CNI с политиками седьмого уровня L7, то есть с возможностью написать сетевые политики Kubernetes для DNS, HTTP и даже Kafka.
Например, напишем сетевую политику DNS L7 для:
Ограничения DNS-разрешения подмножеством
apiVersion: cilium.io/v2
kind: CiliumClusterwideNetworkPolicy
metadata:
name: dns-allow-list
spec:
endpointSelector: {}
egress:
- toEndpoints:
- matchLabels:
io.kubernetes.pod.namespace: kube-system
k8s-app: kube-dns
toPorts:
- ports:
- port: "53"
protocol: UDP
rules:
dns:
- matchPattern: "*.abc.xyz"
Разрешения HTTP-запросов методом «POST» на abc.xyz
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: http-post-abc-xyz
spec:
endpointSelector: {}
egress:
- toPorts:
- ports:
- port: "443"
protocol: TCP
rules:
http:
- method: POST
- toFQDNs:
- matchPattern: "*.abc.xyz"
Ограничения доступа к теме Kafka такими подами
Обычно сетевые политики пишутся так: “Allow any application with the label kafka-consumer” to speak to Kafka («Разрешить взаимодействовать с Kafka любому приложению с меткой kafka-consumer»). Так сеть раскидывается широковато.
А с политиками L7 доступ к отдельным темам ограничивается в зависимости от меток. Так уже только пивовар beer-brewer публикует в теме хмеля hops:
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: beer-brewers
spec:
ingress:
- fromEndpoints:
- matchLabels:
role: beer-brewer
toPorts:
- ports:
- port: 9092
protocol: TCP
rules:
kafka:
- role: produce
topic: hops
Глазами разработчика
Ресурсы выглядят сложновато? В Cilium учли и это. Все эти сетевые политики визуализируются, мидифицируются и даже конструируются простейшим визуальным построителем.
Убедитесь сами.
Установка Cilium
Cilium устанавливается в виде чарта Helm, сначала делаем репозиторий доступным:
helm repo add cilium https://helm.cilium.io/
Затем настраиваем значения по умолчанию для требуемой установки:
Режим IPAM
В Cilium для управления IPAM имеются разные режимы:
--set global.ipam.mode=cluster-pool
--set global.ipam.operator.clusterPoolIPv4PodCIDR=192.168.0.0/16
--set global.ipam.operator.clusterPoolIPv4MaskSize=23
А еще предварительный просмотр, где для динамического выделения узлов CIDR на основе использования ресурсов режим IPAM устанавливается на cluster-pool-v2beta.
eBPF и XDP
eBPF — относительно новая технология ядра Linux для выполнения программ eBPF, запускаемых в «песочнице». Этими программами код в пространстве пользователя запускается в ядре с беспрецедентной производительностью, возможности ядра расширяются.
XDP для высокопроизводительного конвейера обработки пакетов, запускаемого после получения сетевым драйвером пакета, задействуется eBPF. Что это означает? В Cilium с помощью XDP проще предотвратить последствия DDOS-атак: пакеты отбрасываются еще до их попадания в традиционный сетевой стек.
Kube Proxy
С eBPF и XDP в Cilium мы не зависим от iptables, поэтому можем отключить kube-proxy с помощью kubeadm и через развертывание Cilium:
--set kubeProxyReplacement=probe
Нативная маршрутизация
Включим ее, ведь для работы с маршрутизацией пакетов внутри кластера инкапсуляция в Cilium не нужна:
--nativeRoutingCIDR=192.168.0.0/16
Hubble
Наблюдаемость Hubble и Cilium очень важна, включаем ее:
--set global.hubble.relay.enabled=true
--set global.hubble.enabled=true
--set global.hubble.listenAddress=":4244"
--set global.hubble.ui.enabled=true
Завершаем установку
helm repo add cilium https://helm.cilium.io/
helm upgrade --install cilium/cilium cilium \
--version 1.13.4 \
--namespace kube-system \
--set image.repository=quay.io/cilium/cilium \
--set global.ipam.mode=cluster-pool \
--set global.ipam.operator.clusterPoolIPv4PodCIDR=192.168.0.0/16 \
--set global.ipam.operator.clusterPoolIPv4MaskSize=23 \
--set global.nativeRoutingCIDR=192.168.0.0/16 \
--set global.endpointRoutes.enabled=true \
--set global.hubble.relay.enabled=true \
--set global.hubble.enabled=true \
--set global.hubble.listenAddress=":4244" \
--set global.hubble.ui.enabled=true \
--set kubeProxyReplacement=probe \
--set k8sServiceHost=${PUBLIC_IPv4} \
--set k8sServicePort=6443
Хотя Cilium в ландшафте CNI без году неделю, за короткое время он стал золотым стандартом для сетей Kubernetes. Calico тоже отличный вариант, но за счет внедрения eBPF и XDP, лучшего из доступных инструмента отладки Hubble, простоты и скорости разработки его редактора Cilium становится перспективным решением.
Заключение
Сеть Kubernetes состоит из Kube-Proxy и CNI: в Kube-Proxy поддерживаются сетевые правила, трафик перенаправляется в поды; в CNI для базовой сети обеспечивается единый интерфейс. Эти компоненты необходимы для запуска контейнерных приложений в Kubernetes.
Читайте также:
- Использование Kubernetes для развертывания 3-уровневой инфраструктуры контейнерных приложений
- Kubernetes: установка MicroK8s на локальном компьютере за 5 минут
- Как автоматизировать операции Kubernetes посредством Python
Читайте нас в Telegram, VK и Дзен
Перевод статьи Seifeddine Rajhi: Kube-Proxy and CNI: The Hidden Components of Kubernetes Networking




