
Что такое Elasticsearch?
Elasticsearch(ES) — это распространенная поисковая система с открытым исходным кодом, основанная на индексе Lucene. Написана она на языке Java и доступна для многих платформ. Все неструктурированные данные хранятся в формате JSON, что автоматически делает ES базой данных NoSQL. Но в отличие от других баз данных NoSQL, ES предоставляет возможности поиска и другие, не менее интересные функции.Варианты использования Elasticsearch
ES- многозадачная система. Некоторые из ее возможностей мы приведем ниже:- Например, вы владеете сайтом, на котором предоставлено множество динамического контента: будь то интернет-магазин или ваш личный блог. Внедрив ES, вы сможете обеспечить не только многопоточную и надежную поисковую систему для вашего веб-сайта, но и предоставите пользователям функции автозаполнения в вашем приложении.
- У вас появится возможность просматривать данные журнала события, чтобы в дальнейшем составлять графики тенденций и статистики.
Настройка и запуск
Самый простой способ установить Elasticsearch — просто скачать его и запустить исполняемый файл. Единственное, перед запуском вы должны убедиться, что используете Java 7 или более позднюю версию. После загрузки файла, распакуйте его и запустите бинарный файл:elasticsearch-6.2.4 bin/elasticsearchВ окне прокрутки будет тонна текста и вам вряд ли удастся проследить весь процесс. Но если вы увидите что-то похожее на то, что на картинке снизу, значит все идет по плану.
[2018-05-27T17:36:11,744][INFO ][o.e.h.n.Netty4HttpServerTransport] [c6hEGv4] publish_address {127.0.0.1:9200}, bound_addresses {[::1]:9200}, {127.0.0.1:9200}
После установки и запуска, проверьте сервер. Добавьте URL http://localhost:9200 в ваш браузер или через cURL. Если все пройдет гладко, вам должен прийти вот такой ответ:
{
"name" : "c6hEGv4",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "HkRyTYXvSkGvkvHX2Q1-oQ",
"version" : {
"number" : "6.2.4",
"build_hash" : "ccec39f",
"build_date" : "2018-04-12T20:37:28.497551Z",
"build_snapshot" : false,
"lucene_version" : "7.2.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}Простые примеры
Неважно что вам скажут другие, первым делом нужно создать индекс. Все хранится в индексе. Эквивалент RDBMS в индексе является базой данных, поэтому не путайте его с типичной концепцией индексирования, которую вы когда-то выучили в RDBMS. Я использую PostMan для запуска REST API.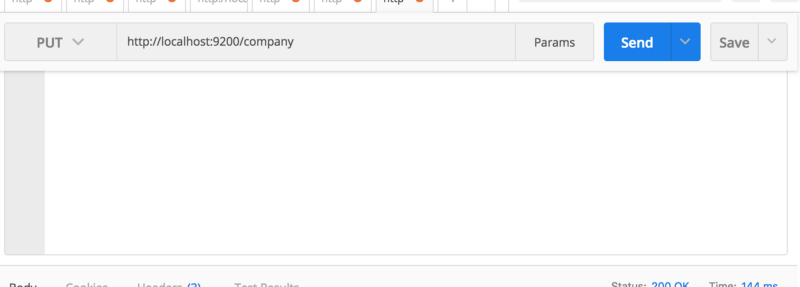
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "company"
}
Мы создали базу данных с названием company. Другими словами, мы создали индекс под названием company. Если вы перейдете по адресу http://localhost:9200/company из вашего браузера, тогда вы увидите что-то вроде этого:
{
"company": {
"aliases": {
},
"mappings": {
},
"settings": {
"index": {
"creation_date": "1527638692850",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "RnT-gXISSxKchyowgjZOkQ",
"version": {
"created": "6020499"
},
"provided_name": "company"
}
}
}
}➜ elasticsearch-6.2.4 curl -X PUT localhost:9200/company
{"acknowledged":true,"shards_acknowledged":true,"index":"company"}%
Вы также можете выполнить за один раз, как создание индекса, так и внесение отчета. Все, что вам нужно сделать, это передать свою запись в формате JSON. В PostMan для этого нужно будет проделать нехитрые действия:
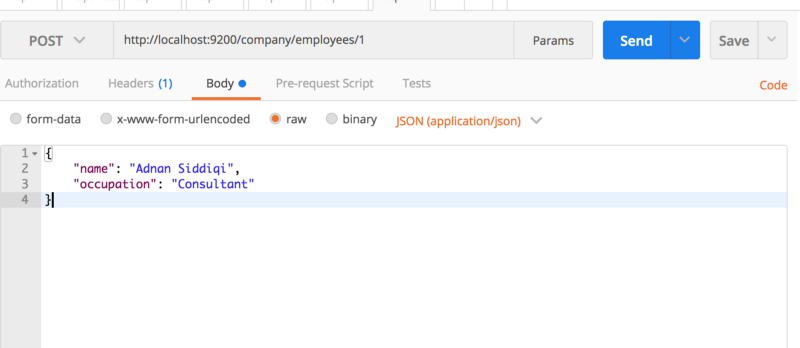
{
"_index": "company",
"_type": "employees",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}{"_index":"company","_type":"employees","_id":"1","_version":1,"found":true,"_source":{
"name": "Adnan Siddiqi",
"occupation": "Consultant"
}}
Вы можете посмотреть фактическую запись вместе с метаданными. Если хотите, то можете изменить свой запрос на http://localhost:9200/company/employees/1_source и вы увидите только структуру JSON.
Версия cURL будет следующая:
➜ elasticsearch-6.2.4 curl -X POST \
> http://localhost:9200/company/employees/1 \
> -H 'content-type: application/json' \
> -d '{
quote> "name": "Adnan Siddiqi",
quote> "occupation": "Consultant"
quote> }'
{"_index":"company","_type":"employees","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1}%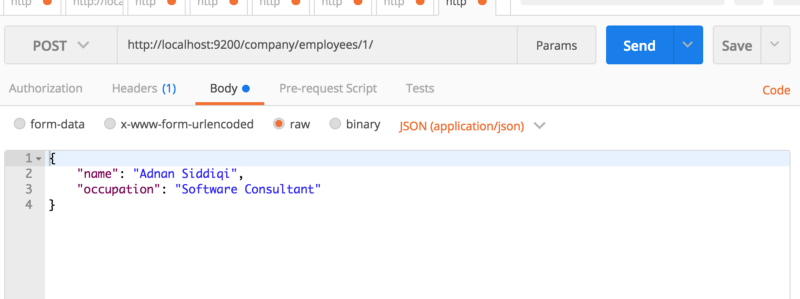
{
"_index": "company",
"_type": "employees",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
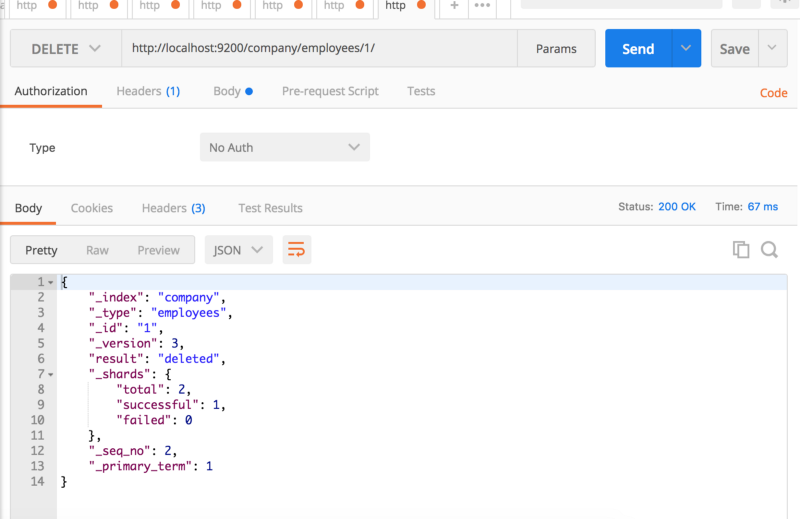
}
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.2876821,
"hits": [
{
"_index": "company",
"_type": "employees",
"_id": "1",
"_score": 0.2876821,
"_source": {
"name": "Adnan Siddiqi",
"occupation": "Software Consultant"
}
}
]
}
}SELECT * from table where name='Adnan'.
Таким образом, сегодня я рассмотрел самое основное по работе с ES. Система многое умеет, вы можете продолжить ее изучение, прочитав документацию и включив в Python доступ к ES.
Доступ к ElasticSearch в Python
Если быть честным, то REST API ES достаточно хорош, чтобы вы могли использовать библиотеку запросов для выполнения всех ваших задач. Тем не менее, вы также можете использовать библиотеку Python для ElasticSearch, чтобы в дальнейшем не беспокоиться о том, как создавать те или иные запросы, а сосредоточиться на работе. Библиотеку Python вы можете установить через pip, после чего вам останется получить к ней доступ в своих Python программах.pip install elasticsearch
Чтобы убедиться, что библиотека установлена правильно, запустите следующее в вашей командной строке:
➜ elasticsearch-6.2.4 python
Python 3.6.4 |Anaconda custom (64-bit)| (default, Jan 16 2018, 12:04:33)
[GCC 4.2.1 Compatible Clang 4.0.1 (tags/RELEASE_401/final)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from elasticsearch import Elasticsearch
>>> es = Elasticsearch([{'host': 'localhost', 'port': 9200}])
>>> es
<Elasticsearch([{'host': 'localhost', 'port': 9200}])>Web Scraping и Elasticsearch
Web Scraping (парсинг контента или парсинга сайтов). Теперь давайте рассмотрим небольшой пример использования Elasticsearch на практике. Наша цель состоит в том, чтобы получить доступ к онлайн-рецептам с сайта и сохранить их в Elasticsearch для проведения дальнейшего поиска и аналитики. Сначала мы очистим данные от всех рецептов, так как все рецепты нам не нужны, и сохраним. Также мы создадим схему, с помощью которой мы убедимся, что наши данные индексируются в правильном формате и типе данных. Затем я просто выбираю рецепты салатов и сохраняю полный список себе.Полученный контент
import json
from time import sleep
import requests
from bs4 import BeautifulSoup
def parse(u):
title = '-'
submit_by = '-'
description = '-'
calories = 0
ingredients = []
rec = {}
try:
r = requests.get(u, headers=headers)
if r.status_code == 200:
html = r.text
soup = BeautifulSoup(html, 'lxml')
# title
title_section = soup.select('.recipe-summary__h1')
# submitter
submitter_section = soup.select('.submitter__name')
# description
description_section = soup.select('.submitter__description')
# ingredients
ingredients_section = soup.select('.recipe-ingred_txt')
# calories
calories_section = soup.select('.calorie-count')
if calories_section:
calories = calories_section[0].text.replace('cals', '').strip()
if ingredients_section:
for ingredient in ingredients_section:
ingredient_text = ingredient.text.strip()
if 'Add all ingredients to list' not in ingredient_text and ingredient_text != '':
ingredients.append({'step': ingredient.text.strip()})
if description_section:
description = description_section[0].text.strip().replace('"', '')
if submitter_section:
submit_by = submitter_section[0].text.strip()
if title_section:
title = title_section[0].text
rec = {'title': title, 'submitter': submit_by, 'description': description, 'calories': calories,
'ingredients': ingredients}
except Exception as ex:
print('Exception while parsing')
print(str(ex))
finally:
return json.dumps(rec)
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
'Pragma': 'no-cache'
}
url = 'https://www.allrecipes.com/recipes/96/salad/'
r = requests.get(url, headers=headers)
if r.status_code == 200:
html = r.text
soup = BeautifulSoup(html, 'lxml')
links = soup.select('.fixed-recipe-card__h3 a')
for link in links:
sleep(2)
result = parse(link['href'])
print(result)
print('=================================')
Таким образом, это основная программа, которая может парсить данные. Так как нам нужны данные в формате JSON — мне пришлось дополнительно их преобразовать.
Создаем индексы
Окей, мы с вами получили нужные данные и теперь должны их где-то хранить. Самое первое, что нам нужно сделать, это создать индекс. Назовем его recipes. Тип (type) будет называться salads. Далее нам нужно создать мэппинг нашей структуры документа.
Прежде чем создавать индекс, подключитесь к серверу Elasticsearch.
import logging
def connect_elasticsearch():
_es = None
_es = Elasticsearch([{'host': 'localhost', 'port': 9200}])
if _es.ping():
print('Yay Connect')
else:
print('Awww it could not connect!')
return _es
if __name__ == '__main__':
logging.basicConfig(level=logging.ERROR)
_es.ping() фактически пингует сервер и выводит в консоль True, если удалось совершить подключение. Мне потребовалось некоторое время, чтобы выяснить как поймать стек-трейс, в итоге выяснилось, что он просто регистрируется.
def create_index(es_object, index_name='recipes'):
created = False
# index settings
settings = {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"members": {
"dynamic": "strict",
"properties": {
"title": {
"type": "text"
},
"submitter": {
"type": "text"
},
"description": {
"type": "text"
},
"calories": {
"type": "integer"
},
}
}
}
}
try:
if not es_object.indices.exists(index_name):
# Ignore 400 means to ignore "Index Already Exist" error.
es_object.indices.create(index=index_name, ignore=400, body=settings)
print('Created Index')
created = True
except Exception as ex:
print(str(ex))
finally:
return created
На верхнем скриншоте много чего происходит. Во-первых, мы передали конфигурационную переменную, которая отображает всю структуры документа. Мэппинг -это термин в Elasticsearch, обозначающий микроразметку. Подобно тому, как мы устанавливаем определенный тип данных поля в таблицах, мы делаем что-то похожее и здесь. Но чтобы лучше во всем этом разобраться — читайте официальную документацию. Все поля имеют тип text, но у calories тип integer.
Следующий шаг — удостовериться, что индекса вообще не существует и затем создать его. Параметр ignore = 400 можно удалить после проверки. Но в случае, если вы не проверили существование индекса, данный параметр может спровоцировать ошибку и перезаписать индекс. Это будет тоже самое, что перезаписать базу данных. Когда индекс будет успешно создан, вы можете убедиться в этом, посетив страницу http://localhost:9200/recipes/_mappings. Должно получиться примерно следующее сообщение:
{
"recipes": {
"mappings": {
"salads": {
"dynamic": "strict",
"properties": {
"calories": {
"type": "integer"
},
"description": {
"type": "text"
},
"submitter": {
"type": "text"
},
"title": {
"type": "text"
}
}
}
}
}
}
Передавая dynamic:strict, мы заставляем Elasticsearch выполнять строгую проверку любого входящего документа. Здесь salads является типомdocument. Тип (type) в Elasticsearch это ответ на таблицы в RDBMS.
Документация индексов
Следующим шагом является хранение фактических данных или документов.
def store_record(elastic_object, index_name, record):
try:
outcome = elastic_object.index(index=index_name, doc_type='salads', body=record)
except Exception as ex:
print('Error in indexing data')
print(str(ex))
Запускаем и вот что мы увидим:
Error in indexing data TransportError(400, 'strict_dynamic_mapping_exception', 'mapping set to strict, dynamic introduction of [ingredients] within [salads] is not allowed')
Знаете, почему это происходит? Так как мы не добавляли в наш мэппинг компонентов, ES решил не разрешать нам хранить документ, не содержащий, по сути, ничего. Если вы не назначите компоненты мэппингу — произойдет повреждение данных. Теперь давайте немного подправим наш мэппинг и посмотрим, что произойдет:
"mappings": {
"salads": {
"dynamic": "strict",
"properties": {
"title": {
"type": "text"
},
"submitter": {
"type": "text"
},
"description": {
"type": "text"
},
"calories": {
"type": "integer"
},
"ingredients": {
"type": "nested",
"properties": {
"step": {"type": "text"}
}
},
}
}
}
Мы добавили ingredients типу nested, а затем назначили тип данных внутреннему полю. В нашем случае это text.
Вложенный тип данных (nested) позволяет установить тип вложенных объектов JSON. Запустите снова и взгляните на результат:
{
'_index': 'recipes',
'_type': 'salads',
'_id': 'OvL7s2MBaBpTDjqIPY4m',
'_version': 1,
'result': 'created',
'_shards': {
'total': 1,
'successful': 1,
'failed': 0
},
'_seq_no': 0,
'_primary_term': 1
}
Так как вы не передали _id вообще, ES сам назначил динамический идентификатор сохраненному документу. Я использую браузер Chrome и ES data viewer с помощью инструмента Elasticsearch Toolbox для просмотра данных.
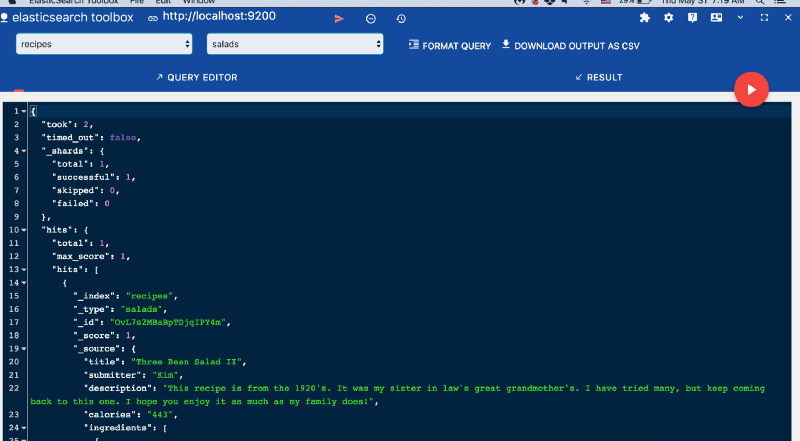
Прежде чем двигаться дальше, отправим строку в поле calories и посмотрим, как развернутся события. Вспомним тот факт, что мы присвоили ему тип integer. Учитывая это, при индексировании он выдаст следующую ошибку:
TransportError(400, ‘mapper_parsing_exception’, ‘failed to parse [calories]’)
Итак, теперь вы знаете преимущества назначения мэппинга для ваших документов. Если вы этого не сделаете, все равно все будет работать, поскольку Elasticsearch назначит свой собственный мэппинг во время среды выполнения.
Запрос записей
Теперь, когда записи индексируются, пришло время их запросить, в соответствии с нашими потребностями. Я собираюсь создать функцию и назвать ее search(). Она будет выводить на экран результаты наших запросов:
def search(es_object, index_name, search):
res = es_object.search(index=index_name, body=search)
Все предельно просто. Вы передаете индекс и критерии поиска в него. Попробуем задать несколько запросов:
if __name__ == '__main__':
es = connect_elasticsearch()
if es is not None:
search_object = {'query': {'match': {'calories': '102'}}}
search(es, 'recipes', json.dumps(search_object))
В приведенном выше запросе вернутся все записи, в которых calories равны 102. В нашем случае вывод будет:
{'_shards': {'failed': 0, 'skipped': 0, 'successful': 1, 'total': 1},
'hits': {'hits': [{'_id': 'YkTAuGMBzBKRviZYEDdu',
'_index': 'recipes',
'_score': 1.0,
'_source': {'calories': '102',
'description': "I've been making variations of "
'this salad for years. I '
'recently learned how to '
'massage the kale and it makes '
'a huge difference. I had a '
'friend ask for my recipe and I '
"realized I don't have one. "
'This is my first attempt at '
'writing a recipe, so please '
'let me know how it works out! '
'I like to change up the '
'ingredients: sometimes a pear '
'instead of an apple, '
'cranberries instead of '
'currants, Parmesan instead of '
'feta, etc. Great as a side '
'dish or by itself the next day '
'for lunch!',
'ingredients': [{'step': '1 bunch kale, large '
'stems discarded, '
'leaves finely '
'chopped'},
{'step': '1/2 teaspoon salt'},
{'step': '1 tablespoon apple '
'cider vinegar'},
{'step': '1 apple, diced'},
{'step': '1/3 cup feta cheese'},
{'step': '1/4 cup currants'},
{'step': '1/4 cup toasted pine '
'nuts'}],
'submitter': 'Leslie',
'title': 'Kale and Feta Salad'},
'_type': 'salads'}],
'max_score': 1.0,
'total': 1},
'timed_out': False,
'took': 2}
А что делать, если вы хотите получить записи, в которых calories больше, чем 20?
'_source': ['title'], 'query': {'range': {'calories': {'gte': 20}}}}
Вы также можете указать, какие столбцы или поля вам хотелось бы вернуть. Приведенный выше запрос вернет все записи, в которых calories больше, чем 20. Кроме того, он будет отображать поле title только под _source.
Заключение
Elasticsearch — это мощный инструмент, который поможет сделать уже существующие или грядущие приложения доступными для поиска, предоставляя надежные функции для возврата наиболее точного набора результатов. Читайте официальные документы, мануалы и инструкции. Позвольте Elasticsearch упростить вашу жизнь. По традиции, весь код доступен на Github.
Перевод статьи Adnan Siddiqi: Getting started with Elasticsearch in Python





