
Приветствую всех, кто заинтересовался данной статьей! Приготовьтесь к созданию веб-приложения для преобразования речи в текст. Для этой цели воспользуемся Node.js и API OpenAI. В частности, от API OpenAI потребуется модель распознавания речи Whisper, которая загружает аудиофайлы в формате mp3 и транскрибирует их. Помимо этого, она может переводить звукозаписи с разных языков в текст на английском.
Работа над приложением начинается с нового проекта Node.js. Для этого создаем папку проекта, переходим в нее посредством командной строки и выполняем следующую команду:
npm init
После выполнения команды последует несколько вопросов об имени приложения, точке входа и т.д. Пока оставляем их по умолчанию. Команда npm init создает файл package.json. Он содержит информацию о приложении и его пакетах.
На следующем этапе устанавливаем необходимые для создания приложения модули Node.js, т.е. пакеты. Для этого применяем команду:
npm install express multer openai cors --save
Устанавливаем указанные 4 пакета и с помощью --save добавляем их в файл package.json. Тем, кто клонирует репозиторий, становится проще устанавливать все требуемые пакеты, поскольку достаточно только один раз выполнить команду npm install.
Приложению также требуется пакет nodemon. Он помогает автоматически обновлять и перезагружать сервер при обнаружении изменений в коде, избавляя от необходимости каждый раз перезапускать сервер вручную. Пакет nodemon добавляется как зависимость разработки. Дело в том, что он задействуется только в качестве вспомогательного средства разработки и непосредственно в коде не используется. Устанавливаем его следующей командой:
npm install --save-dev nodemon
Теперь у нас есть все необходимые пакеты для начала разработки. Файл package.json содержит все модули и установленные пакеты, а также некоторые сведения о приложении. Выглядит он так:
{
"name": "speechtext",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"dependencies": {
"cors": "^2.8.5",
"express": "^4.18.2",
"multer": "^1.4.5-lts.1",
"openai": "^3.2.1"
},
"devDependencies": {
"nodemon": "^2.0.22"
}
}
Как видно, index.js записан в свойство main. Это говорит о том, что файл index.js является точкой входа для приложения. Если помните, нас об этом спрашивали на этапе настройки проекта при выполнении команды npm init. Если вы установили на этот вопрос ответ по умолчанию, то получаете такую же точку входа. Если нет, будет точка, которую вы тогда определили.
Далее создаем новый файл с именем index.js. Вы можете назвать его на свое усмотрение в соответствии с определенной точкой входа. В данном же случае файл называется index.js.
index.js
Приступаем к созданию файла index.js. Сначала импортируем в приложение нужные модули. Для index.js требуются express и cors:
const express = require('express');
const cors = require('cors');
Затем создаем новый экземпляр приложения express. Кроме того, настраиваем приложение на работу с cors, обработку данных JSON и снабжаем папку public статическими файлами, доступными для стороны клиента или фронтенда:
const app = express();
app.use(express.static('public'));
app.use(express.json());
app.use(cors());
Далее следует обзавестись отдельным файлом для определения API. Создаем папку routes с файлом api.js, в котором будут определяться необходимые методы API GET и POST. Чтобы сообщить об этом приложению, добавляем строку кода, в которой определяем базовый URL и местоположение файла со всеми обозначенными API. Это промежуточное ПО (англ. middleware), позволяющее настроить маршрутизацию для приложения:
app.use('/', require('./routes/api'));
После этого используем функцию промежуточной обработки для обработки ошибок, возникающих в приложении:
app.use(function(err,req,res,next){
res.status(422).send({error: err.message});
});
И наконец, настраиваем приложение для прослушивания входящих запросов на указанный номер порта, который задается с помощью переменных окружения или простым определением:
app.listen(process.env.PORT || 4000, function(){
console.log('Ready to Go!');
});
Для данного приложения задействуется порт 4000. Кроме того, внутри есть простой метод console.log. Он выводит сообщение в консоль, когда приложение готово принимать запросы.
Полный вариант кода файла index.js:
const express = require('express');
const cors = require('cors');
const app = express();
app.use(express.static('public'));
app.use(express.json());
app.use(cors());
app.use('/', require('./routes/api'));
app.use(function(err,req,res,next){
res.status(422).send({error: err.message});
});
app.listen(process.env.PORT || 4000, function(){
console.log('Ready to Go!');
});
В следующем разделе уделим внимание файлу api.js, созданному в папке routes.
api.js
Начинаем работу над файлом api.js. Прежде всего, импортируем в него нужные модули, а именно библиотеки express, multer и openai:
const express = require("express");
const multer = require("multer");
const { Configuration, OpenAIApi } = require("openai");
Multer, промежуточное ПО, требуется для обработки multipart/form-data, поскольку мы имеем дело с загрузкой аудиофайлов.
Модули Configuration и OpenAIApi из библиотеки openai нужны для отправки API-запросов к модели Whisper.
Настраиваем маршрутизатор express и создаем экземпляр промежуточного ПО multer:
const router = express.Router();
const upload = multer();
Задаем конфигурацию OpenAI и создаем экземпляр new Configuration. Потребуется секретный ключ OpenAI, который указывается здесь как API-ключ. Секретный ключ можно получить по ссылке:
const configuration = new Configuration({
apiKey: process.env.OPENAI_KEY,
});
Создаем асинхронную функцию async, которая принимает буфер с данными песни и возвращает ответ, полученный от модели OpenAI Whisper при вызове ее API:
async function transcribe(buffer) {
const openai = new OpenAIApi(configuration);
const response = await openai.createTranscription(
buffer, // Аудиофайл, подлежащий транскрибации.
"whisper-1", // Модель, применяемая для транскрипции.
undefined, // Пояснительная инструкция для транскрипции.
'json', // Формат транскрипции.
1, // Температура
'en' // Язык
)
return response;
}
Как видно, сначала создаем новый экземпляр класса OpenAI посредством конфигурации, ранее определенной в коде. Затем вызываем функцию OpenAI createTranscription и используем ключевое слово await, чтобы получить ответ перед переходом к следующему этапу работы.
В функцию передаем необходимые параметры: буфер с данными песни и модель для транскрипции whisper-1. Оставляем пояснительную инструкцию (англ. prompt) неопределенной undefined. При желании ее можно и задать. Она помогает модели улучшать качество транскрибации аудиозаписи, предоставляя образец выполнения. Определяем тип получаемых данных как json, устанавливаем для температуры temperature значение 1 и задаем язык language, на котором будут выводиться данные.
Далее определяем запрос GET. С помощью sendFile отправляем файл HTML, содержащий форму, в которую пользователи загружают аудиофайлы. Созданием файлов HTML займемся чуть позже. Отправляем запрос по базовому URL:
router.get("/", (req, res) => {
res.sendFile(path.join(__dirname, "../public", "index.html"));
});
Теперь определяем запрос POST, который займется загрузкой аудиофайлов. Применяем multer для управления частью загрузки. Создаем буфер из аудиофайла, который будет содержать данные аудиофайла в формате, подходящим для отправки в OpenAI API. И называем буфер, присваивая ему оригинальное имя загруженного аудиофайла.
После этого вызываем функцию transcribe, и, получив ответ, отправляем JSON обратно клиенту. Во фронтенд обратно отсылаются транскрипция и имя аудиофайла. Кроме того, имеется метод catch для обработки ошибок:
router.post("/", upload.any('file'), (req, res) => {
audio_file = req.files[0];
buffer = audio_file.buffer;
buffer.name = audio_file.originalname;
const response = transcribe(buffer);
response.then((data) => {
res.send({
type: "POST",
transcription: data.data.text,
audioFileName: buffer.name
});
}).catch((err) => {
res.send({ type: "POST", message: err });
});
});
Под конец экспортируем модули router. В дальнейшем это позволит другим файлам их импортировать:
module.exports = router;
Ниже представлен полный вариант кода для файла api.js:
const express = require("express");
const multer = require("multer");
const { Configuration, OpenAIApi } = require("openai");
const router = express.Router();
const upload = multer();
const configuration = new Configuration({
apiKey: process.env.OPENAI_KEY,
});
async function transcribe(buffer) {
const openai = new OpenAIApi(configuration);
const response = await openai.createTranscription(
buffer, // Аудиофайл, подлежащий транскрибации.
"whisper-1", // Модель, применяемая для транскрипции.
undefined, // Пояснительная инструкция для транскрипции.
'json', // Формат транскрипции.
1, // Температура
'en' // Язык
)
return response;
}
router.get("/", (req, res) => {
res.sendFile(path.join(__dirname, "../public", "index.html"));
});
router.post("/", upload.any('file'), (req, res) => {
audio_file = req.files[0];
buffer = audio_file.buffer;
buffer.name = audio_file.originalname;
const response = transcribe(buffer);
response.then((data) => {
res.send({
type: "POST",
transcription: data.data.text,
audioFileName: buffer.name
});
}).catch((err) => {
res.send({ type: "POST", message: err });
});
});
module.exports = router;
Работа над всеми частями бэкенда завершена. Переходим к написанию файлов HTML и фронтенд-кода JavaScript для обработки отправки форм, сохранения данных в локальном хранилище и извлечения их оттуда.
Создаем папку public с двумя файлами HTML: index.html и transcribe.html.
Следующий раздел посвятим файлу index.html.
index.html
В этом файле создаем страницу, отображающую форму для загрузки аудиофайла. С помощью Bootstrap CSS импортируем ее через CDN. Кроме того, вставляем Bootstrap JS через CDN в конец файла HTML.
Затем создаем простую карточку Bootstrap, где просим пользователя загрузить аудиофайл. Убеждаемся, что отправляемый файл в формате .mp3, поскольку это единственно допустимый формат для OpenAI API. Отображаем кнопку, которая при нажатии отправляет форму.
У нас есть код JavaScript для обработки отправки формы. Сначала приостанавливаем обновление страницы, предотвращая предустановленное поведение события отправки формы. Затем принимаем данные формы, т.е. аудиофайл, и отправляем их бэкенду в виде запроса POST. После этого ждем ответ и сохраняем его в переменной данных.
При наличии у данных транскрипции сохраняем ее и имя аудиофайла в локальном хранилище Local Storage. Таким образом мы обеспечиваем к ним доступ на следующей странице, на которой должна отобразиться транскрипция. Существует множество способов передачи информации, например через URI, но здесь для этой цели применяется локальное хранилище.
Сохранив данные в локальном хранилище, меняем расположение окна для загрузки файла transcribe.html:
<!DOCTYPE html>
<html>
<head>
<title>Speech to Text</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-GLhlTQ8iRABdZLl6O3oVMWSktQOp6b7In1Zl3/Jr59b6EGGoI1aFkw7cmDA6j6gD" crossorigin="anonymous">
</head>
<body style="background-color: #f2f2f2;">
<div class="container mt-5">
<div class="row justify-content-center">
<div class="col-md-6">
<div class="card">
<div class="card-header">
Upload Audio File
</div>
<div class="card-body">
<form id="transcription-form" enctype="multipart/form-data">
<div class="form-group">
<label for="file-upload"><b>Select file:</b></label>
<input id="file-upload" type="file" name="file" class="form-control-file" accept=".mp3" style="margin-bottom: 20px">
</div>
<input type="submit" value="Transcribe" class="btn btn-primary"></input>
</form>
</div>
</div>
</div>
</div>
</div>
<script>
document.getElementById("transcription-form").addEventListener("submit", async function (event) {
event.preventDefault();
const formData = new FormData(event.target);
const response = await fetch("/", {
method: "POST",
body: formData,
});
const data = await response.json();
if (data.transcription) {
localStorage.setItem("transcription", data.transcription);
localStorage.setItem("audioFileName", data.audioFileName);
window.location.href = "/transcribe.html";
}
else {
console.error("Error:", data.message);
}
});
</script>
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/js/bootstrap.bundle.min.js" integrity="sha384-w76AqPfDkMBDXo30jS1Sgez6pr3x5MlQ1ZAGC+nuZB+EYdgRZgiwxhTBTkF7CXvN" crossorigin="anonymous"></script>
</body>
</html>
Данный код создает файл index.html, который отображает пользователю форму для загрузки аудиофайла.
Ниже представлен скриншот страницы загрузки аудиофайла — index.html:
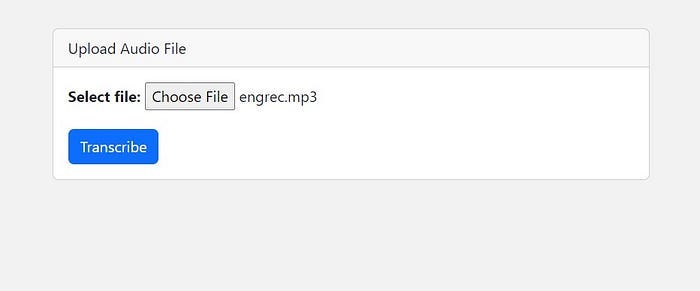
В следующем разделе рассмотрим процесс создания файла transcribe.html.
transcribe.html
В этом файле отображается транскрипция аудиофайла, загруженного пользователем. Снова воспользуемся Bootstrap CSS и JS, чтобы вставить их через CDN.
Определяем пользовательские стили CSS для стилизации элементов, тем самым улучшая их внешний вид. Затем отображаем имя аудиофайла и его транскрипцию в контейнере.
В коде JavaScript в нижней части страницы получаем имя аудиофайла, транскрипцию из локального хранилища и с помощью id отправляем эти данные в соответствующие элементы HTML:
<!DOCTYPE html>
<html>
<head>
<title>Transcription</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-GLhlTQ8iRABdZLl6O3oVMWSktQOp6b7In1Zl3/Jr59b6EGGoI1aFkw7cmDA6j6gD" crossorigin="anonymous">
<style>
h1 {
margin-top: 20px;
margin-bottom: 10px;
font-size: 2.5rem;
font-weight: bold;
color: #333;
}
p {
font-size: 1.2rem;
color: #333;
margin-bottom: 30px;
}
.container {
margin-top: 50px;
margin-bottom: 50px;
max-width: 600px;
padding: 30px;
background-color: #fff;
box-shadow: 0 0 10px rgba(0,0,0,0.2);
border-radius: 5px;
}
</style>
</head>
<body style="background-color: #f2f2f2;">
<div class="container">
<h1>Audio File:</h1>
<p id="audioFileName"></p>
<h1>Transcription:</h1>
<p id="transcription"></p>
</div>
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/js/bootstrap.bundle.min.js" integrity="sha384-w76AqPfDkMBDXo30jS1Sgez6pr3x5MlQ1ZAGC+nuZB+EYdgRZgiwxhTBTkF7CXvN" crossorigin="anonymous"></script>
<script>
const audioFileName = localStorage.getItem("audioFileName");
const transcription = localStorage.getItem("transcription");
document.getElementById("audioFileName").innerHTML = audioFileName;
document.getElementById("transcription").innerHTML = transcription;
</script>
</body>
</html>
Я самолично записал и попробовал протранскрибировать два небольших аудиофайла: один на английском, другой на хинди. Хотя второй аудиофайл был записан на хинди, мне хотелось получить результат на английском, чтобы заодно проверить переводческие способности приложения. Оно очень точно протранскрибировало оба аудиофайла. Хотя при многократных запусках приложение выдавало неточную ошибочную транскрипцию, но во многих случаях транскрипция оказывалась в основном правильной.
Ниже прилагаю скриншоты транскрипций. Они не отличаются абсолютной точностью. В данном случае точность транскрибации записанной речи в аудиофайлах составляет 85–90%.
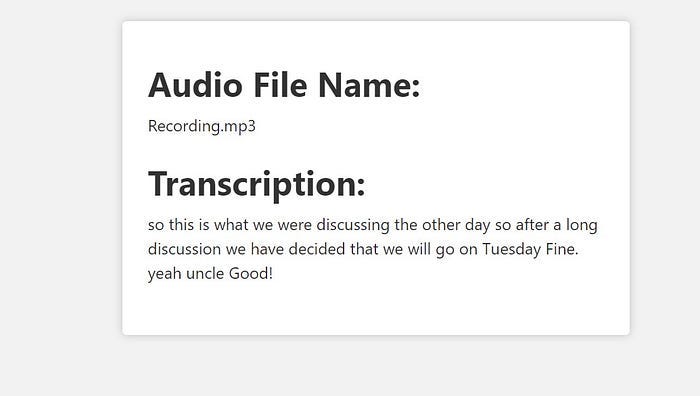
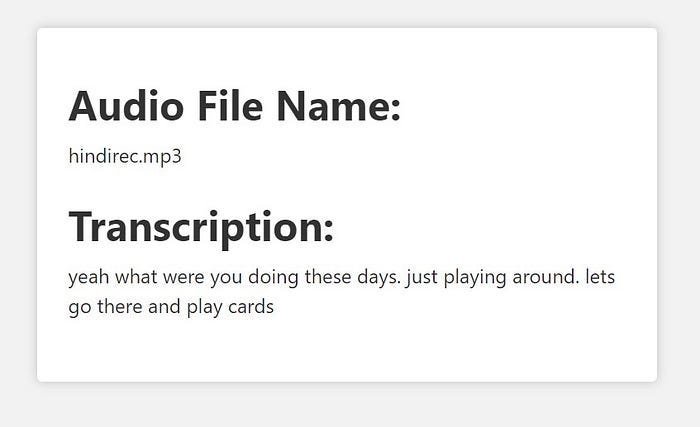
Итак, мы успешно создали веб-приложение для преобразования речи в текст, используя OpenAI API и Node.js. Надеюсь, процесс работы был интересным, и вы узнали для себя что-то новое. Ради эксперимента можно изменить параметры, а потом сравнить результаты. Так вы поймете, что именно и при каком сценарии работает наилучшим образом.
Читайте также:
- Как сделать интеллектуальное приложение вопросов и ответов базы знаний с GPT-3 и Ruby
- Как создать бота Discord с Node.js, Discord.js и OpenAI GPT-3
- Почему стоит использовать обратные вызовы и асинхронный код на NodeJS
Читайте нас в Telegram, VK и Дзен
Перевод статьи Kumar Shubham: Build a Speech-to-Text Web App Using Node.js





