
О чем эта статья
На основе содержимого сайта компании по продаже автозапчастей Sterling Parts создадим приложение вопросов и ответов, для интеллектуальности которых используем GPT-3, для кода — Ruby.
Вопросы ИИ задают пользователи, ответы берутся со страниц FAQ, About Us и Terms and Conditions.
Необходимые условия
- Средний уровень знаний Ruby.
- Понимание, как интегрировать Ruby с Openai.
Github
Код доступен на Github.
Описание процесса
Чтобы подготовить базу знаний для задаваемых по ней в GPT-3 вопросов, создадим два скрипта на Ruby. В отличие от ChatGPT, обучим модель ответам по конкретному содержимому сайта.
Для этого используем массивы, известные в машинном обучении как векторные вложения. Вложение — это процесс преобразования фрагмента текста в массив чисел.
Вот вектор — числовое представление значения, которое содержится в тексте:
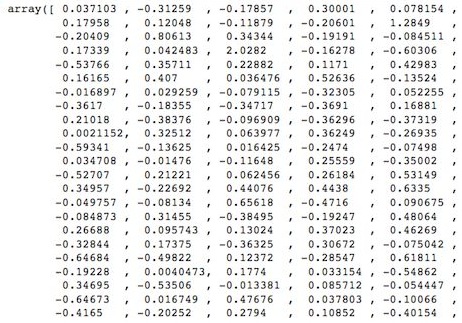
С помощью этих векторов при проведении семантического поиска в базе знаний отыскивается наиболее релевантная информация, затем применяется GPT-3 и на вопрос пользователя дается содержательный ответ.
Слово «семантический» относится к смысловому значению языка. Если при поиске по ключевым словам в базе данных выявляются точные или частичные совпадения, то при семантическом поиске — совпадения по смысловому значению или сути вопроса.
Пример:
Вопрос: «Как резать яблоки?»
Статья базы знаний 1: «Чтобы очистить апельсин, сначала нужно взять машинку для очистки апельсинов».
Статья базы знаний 2: «Чтобы нарезать яблоко, сначала нужно взять острый нож».
При семантическом поиске как наиболее релевантная вернется статья базы знаний 2. Такой поиск достаточно интеллектуален, чтобы «понимать», что «резать» и «нарезать» семантически близки. В основе этого понимания — довольно сложная математика.
Чтобы реализовать семантический поиск в приложении, нужно преобразовать текст в векторные вложения.
В GPT-3 имеется конечная точка вложения, ею текст преобразуется в вектор из 1500 значений, каждое из которых — какой-то признак текста.
Вот признаки, которые могут быть в векторном вложении:
- Семантическое значение.
- Части речи.
- Частота использования.
- Ассоциации с другими словами.
- Грамматическая структура.
- Тональность.
- Длина текста.
В GPT-3 имеются ограничения по токенам, поэтому базу знаний разбиваем на фрагменты всего не более 3000 токенов или 2000 слов. Каждый фрагмент преобразуется в вектор и сохраняется в БД доступным для поиска.
Задаваемый пользователем вопрос тоже преобразуется в вектор, который в ходе определенного математического процесса задействуется для поиска в БД фрагмента базы знаний с наиболее релевантным значением.
Этот фрагмент и вопрос отправляются в GPT-3, откуда выдается содержательный ответ.
Описание процесса
В базе знаний вопросов и ответов будет два скрипта на Ruby: embeddings.rb для подготовки векторных вложений и скрипт ИИ questions.rb.
Вот этапы создания ИИ вопросов и ответов:
- Разбиваем данные базы знаний на фрагменты по 2000 слов каждом и сохраняем в текстовом файле.
- Преобразуем каждый текстовый файл в векторное вложение с помощью конечной точки вложений OpenAI. [embeddings.rb]
- Сохраняем в БД для последующих запросов вложения и исходный текст базы знаний. Базой данных будет CSV-файл. [embeddings.rb]
- Получаем пользовательский вопрос и преобразуем в его векторное вложение. [questions.rb]
- Сравниваем вектор вопроса по базе данных и находим текст базы знаний с ближайшим к вопросу семантическим значением. [questions.rb]
- Специальной подсказкой передаем пользовательский вопрос и текст базы знаний в конечную точку GPT-3
completions. [questions.rb] - Получаем от GPT-3 ответ и показываем его пользователю. [questions.rb]
Этап 1. Подготовка данных
В GPT-3 подсказка и ответ вместе ограничены 4096 токенами, поэтому важно преобразовать данные базы знаний на фрагменты по 2000 слов. Нужно достаточно места для токенов вопроса и ответа.
По возможности создаем фрагменты с близким значением. На страницах FAQ, About Us и Terms and Conditions сайта Sterling Parts менее 1000-2000 слов, поэтому семантически имеет смысл поместить каждую из них в отдельный текстовый файл.
В приложении на Ruby создаем папку training-data, в ней будет текст базы знаний для приложения:
Эти страницы сайта Sterling Parts сохранятся в стандартных файлах .txt:
- https://www.sterlingparts.com.au/faqs;
- https://www.sterlingparts.com.au/about-us;
- https://www.sterlingparts.com.au/Terms-and-Conditions.
Страница Terms and Conditions — самая большая, 2008 слов. Скопируйте и вставьте свой контент в текстовые файлы папки training-data. Названия неважны, главное — чтобы файлы были .txt:
Этап 2. Преобразование данных в векторные вложения
Для работы с API OpenAI потребуется ruby-openai, устанавливаем нужные библиотеки:
gem install ruby-openai dotenv
Сохраняем API-ключ OpenAI в файле .env.
Импортируем библиотеку openai и API-ключом создаем новый экземпляр:
# embeddings.rb
require 'dotenv'
require 'ruby/openai'
Dotenv.load()
openai = OpenAI::Client.new(access_token: ENV['OPENAI_API_KEY'])
Далее — процесс извлечения всех данных из текстовых файлов. В Ruby проходится папка training-data, данные каждого текстового файла считываются и сохраняются в массиве:
# embeddings.rb
# Данные каждого файла сохраняются в массиве
text_array = []
# В папке /training-data перебираются все файлы .txt
Dir.glob("training-data/*.txt") do |file|
# Данные каждого файла считываются и добавляются в массив
# В методе dump пробелы преобразуются в символы новой строки \n
text = File.read(file).dump()
text_array << text
end
Все данные для обучения сохранены в text_array, преобразуем каждое тело текста в векторное вложение конечной точкой OpenAI embeddings, которой принимается два параметра: model в виде text-embedding-ada-002 и input в виде текста каждого файла:
# embeddings.rb
# Вложения сохраняются в этом массиве
embedding_array = []
# Перебирается каждый элемент массива
text_array.each do |text|
# Текст передается в API вложений, откуда возвращается вектор и
# сохраняется в переменной response.
response = openai.embeddings(
parameters: {
model: "text-embedding-ada-002",
input: text
}
)
# Из объекта response извлекается вложение
embedding = response['data'][0]['embedding']
# Создается хеш Ruby, в котором содержатся вектор и исходный текст
embedding_hash = {embedding: embedding, text: text}
# Хеш сохраняется в массиве.
embedding_array << embedding_hash
end
Выводим переменную embedding и видим вектор из 1500 значений. Это векторное вложение.
В embedding_array сохраняются значения векторных вложений и исходного текста, впоследствии сохраняемые в БД для целей семантического поиска.
Этап 3. Сохранение вложений в CSV, т. е. в БД
Для целей этой статьи база данных заменяется CSV-файлом. У специализированных векторных БД очень эффективные алгоритмы семантического поиска. Для Ruby оптимальный инструмент — Redis с его векторным поиском.
На этом этапе создается CSV-файл с двумя столбцами — embedding и text — для сохранения из каждого файла исходного текста с его векторным вложением.
Импортируем библиотеку csv:
# embeddings.rb
require 'dotenv'
require 'ruby/openai'
require 'csv'
Вот окончательный код для скрипта embeddings.rb, в нем создается CSV-файл с заголовками embedding и text, перебирается embedding_array, а соответствующие векторные вложения и текст сохраняются в CSV:
embeddings.rb
CSV.open("embeddings.csv", "w") do |csv|
# Так задаются заголовки
csv << [:embedding, :text]
embedding_array.each do |obj|
# Чтобы избежать ошибок с разделением запятыми между значениями в CSV,
# вектор вложения сохраняется в виде строки
csv << [obj[:embedding], obj[:text]]
end
end
Дальше скрипт embeddings.rb запускается, CSV-файл заполняется данными:
ruby embeddings.rb
Вот файловая структура после запуска:
Этап 4. Получение вопроса пользователя
Переходим к Ruby-скрипту questions.rb. Это основной файл для запроса в CSV векторов вопроса пользователя. При выполнении возвращается исходный текст с наибольшим семантическим сходством и интеллектуальный ответ от GPT-3.
Он запускается в приложении Rails, и вопрос пользователя получается из текстового поля представления. Для простоты выполним все в CLI.
Создаем файл questions.rb и импортируем нужную библиотеку:
# questions.rb
require 'dotenv'
require 'ruby/openai'
require 'csv'
Dotenv.load()
openai = OpenAI::Client.new(access_token: ENV['OPENAI_API_KEY'])
Вопрос пользователя будет в запросе к базе знаний, поэтому:
# questions.rb
puts "Welcome to the Sterling Parts AI Knowledge Base. How can I help you?"
question = gets
С помощью конечной точки OpenAI embeddings преобразуем вопрос пользователя в векторное вложение, чтобы потом математической формулой найти в файле embeddings.csv ближайший по сути и значению текст:
# questions.rb
# Вопрос преобразуется в векторное вложение
response = openai.embeddings(
parameters: {
model: "text-embedding-ada-002",
input: question
}
)
# Значение вложения извлекается
question_embedding = response['data'][0]['embedding']
Выводя вложение, увидим массив из 1500 значений. Это векторное вложение.
Этап 5. Поиск в CSV текста с ближайшим к вопросу семантическим значением
Здесь применяется косинусное сходство, им в машинном обучении определяется близость двух векторов. Это легко изобразить в двух измерениях на графике, поскольку у вектора два значения:
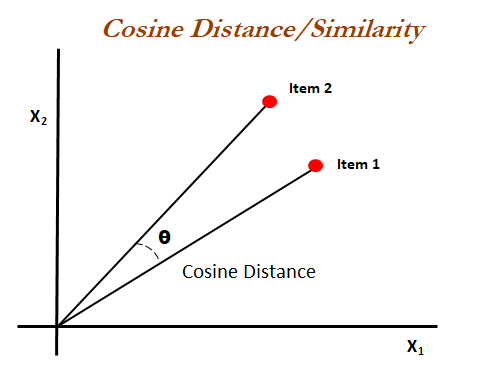
Косинусным сходством определяется отношение двух векторов. Его значение варьируется между 0 и 1, где 1 — идентичные векторы.
В векторных вложениях у векторов 1500 значений. Визуально представить это невозможно, тем не менее по косинусному сходству компьютером определяется, в каком текстовом файле содержатся ближайшие к вопросу пользователя смысловые значения.
С библиотекой Ruby cosine-similarity нет необходимости понимать внутренние механизмы выполняемых вычислений:
gem install cosine-similarity
Импортируем библиотеку вверху файла questions.rb:
# questions.rb
require 'dotenv'
require 'ruby/openai'
require 'csv'
require 'cosine-similarity'
Дальше перебираем все строки CSV-файла и сравниваем вектор вопроса с векторами исходного текста. В методе cosine_similarity вопрос сравнивается с каждым исходным текстом, возвращается число от 0 до 1.
Интересует сходство с наибольшим значением. Это текст, ближайший к вопросу по сути и значению:
# questions.rb
# По мере прохождения CSV в коде, показатели сходства сохраняются
similarity_array = []
# Проходится CSV, вычисляется косинусное сходство между
# вектором вопроса и вложением каждого текста
CSV.foreach("embeddings.csv", headers: true) do |row|
# Вложение извлекается из столбца, выполняется его парсинг в массив
text_embedding = JSON.parse(row['embedding'])
# В массив добавляется показатель сходства
similarity_array << cosine_similarity(question_embedding, text_embedding)
end
# Возвращается индекс наивысшего показателя сходства
index_of_max = similarity_array.index(similarity_array.max)
В переменной index_of_max теперь содержится индекс наивысшего показателя сходства. Им из CSV извлекается текст, который с вопросом пользователя отправляется в GPT-3:
# questions.rb
# Так сохраняется исходный текст
original_text = ""
# Проходится CSV, находится текст с наивысшим
# показателем сходства
CSV.foreach("embeddings.csv", headers: true).with_index do |row, rowno|
if rowno == index_of_max
original_text = row['text']
end
end
Этап 6. Передача пользовательского вопроса и текста базы знаний в конечную точку GPT-3 completions
Остаемся с файлом questions.rb. В скрипте теперь хранятся вопрос пользователя question и исходный текст original_text, ближайшие друг к другу по значению. Чтобы получить на вопрос пользователя интеллектуальный ответ, передадим эту информацию в конечную точку GPT-3 completions.
Специальной подсказкой GPT-3 подводится к тому, чтобы отвечать должным образом, соответственно вопросу пользователя и назначению базы знаний. Это делается в рамках структуры подсказки:
prompt =
"You are an AI assistant. You work for Sterling Parts which is a car parts
online store located in Australia. You will be asked questions from a
customer and will answer in a helpful and friendly manner.
You will be provided company information from Sterline Parts under the
[Article] section. The customer question will be provided unders the
[Question] section. You will answer the customers questions based on the
article.
If the users question is not answered by the article you will respond with
'I'm sorry I don't know.'
[Article]
#{original_text}
[Question]
#{question}"
В хорошей подсказке достаточно информации для формирования шаблона ответа. В первом абзаце GPT подводится к тому, как отвечать на вопрос пользователя, а во втором — дается контекст для определения информации, используемой GPT в ответе. В нижней части из предыдущих этапов вставляются original_text и question.
Если от GPT лучшего ответа не поступает, стоит поменять подсказку и поэкспериментировать с ней в интерактивной среде OpenAI.
Дальше, чтобы получить интеллектуальный ответ, подсказка передается в конечную точку GPT completions:
response = openai.completions(
parameters: {
model: "text-davinci-003",
prompt: prompt,
temperature: 0.2,
max_tokens: 500,
}
)
Температура в коде низкая, а значит, от GPT вернется наиболее вероятный ответ. Хотите от GPT более творческого подхода к ответам? Увеличьте ее до 0,9.
Ответ в этой конечной точке сгенерируется за секунды — в зависимости от нагрузки сервера.
Этап 7. Получение ответа от GPT-3 и отображение его для пользователя
В конце выводим ответ GPT для пользователя:
puts "\nAI response:\n"
puts response['choices'][0]['text'].lstrip
Скрипт завершен.
Отладка ответа
Почему от GPT возвращается неудовлетворительный ответ. Три фактора:
- Подготовка данных.
- Структура подсказки.
- Параметр температуры.
Подготовка данных
По возможности создавайте каждый файл содержащим близкое значение. Если файл обрывается в середине предложения и следующий возобновляется на полпути, это чревато проблемой поиска точного текста для передачи в GPT.
Чтобы доработать поиск сходства, разбейте их на мелкие, сгруппированные по значению тексты.
Структура подсказки
Здесь нужна практика, метод проб и ошибок вне конкуренции.
Чем яснее и однозначнее подсказка, тем адекватнее вашим задачам генерируемые в GPT результаты.
Параметр температуры
Если вкратце, температурой определяется случайность или «креативность» модели: при низкой температуре ответы ожидаемые, при высокой к ним более творческий подход. Чтобы получить результаты под свои задачи, поэкспериментируйте с этим параметром.
Доработка модели
В специфических ситуациях, чтобы получать адекватные базе знаний и пользователям ответы, требуется дообучение модели.
Имеется ряд подходов, которые сводятся к встроенной подводке и тонкой настройке.
Встроенная подводка заключается в приведении в подсказке примеров вопросов и ответов, например, для получения от GPT ответов в конкретном формате или определенным способом. Я часто применяю этот подход, когда нужен ответ в JSON.
Тонкая настройка — совершенно иной подход, применяемый для обучения собственной GPT-модели задачам, которым она ранее не обучалась. Например, задавать ей вопросы, нацеленные на извлечение конкретной информации.
Читайте также:
- Как я создал расширение браузера и обучил ChatGPT обращаться к внешним сайтам за информацией о текущих событиях
- Как работает GPT3
- Раскройте потенциал VS Code для программирования на Ruby
Читайте нас в Telegram, VK и Дзен
Перевод статьи Kane Hooper: Creating an Intelligent Knowledge Base Q&A App with GPT-3 and Ruby





