
При идеальных обстоятельствах пользователь всегда обеспечит себе хорошее интернет-соединение, но в жизни редко что бывает идеальным. К счастью, при сборке веб-приложения у нас есть service worker, способный кэшировать сетевые ответы.
В случае потери сетевого соединения или слишком длительного ожидания мы можем использовать эти кэшированные ответы, чтобы отобразить запрашиваемую пользователем страницу и позволить ему продолжить работу с приложением, несмотря на отсутствие подключения. К сожалению, наш кэш не всегда совершенен. Иногда пользователь будет пытаться перейти на страницу, которая еще не кэшировалась.
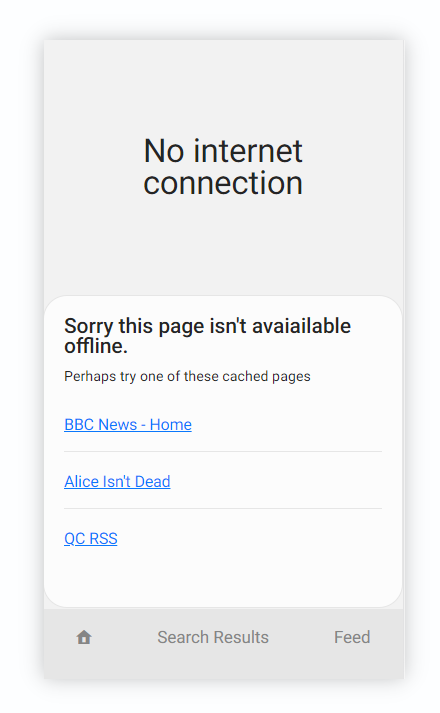
Если мы не предусмотрели это обстоятельство, то можем увидеть сообщение об отсутствии подключения к интернету.
К счастью, мы, разработчики, люди толковые и можем показать фирменную офлайн-страницу. Таким образом, у пользователя все еще сохраняется впечатление, что он использует наше веб-приложение, даже когда соединение потеряно. Приведем примеры:
Этот принцип позволяет сохранить последовательность пользовательского опыта во время сетевых сбоев и является предпочтительным вариантом реагирования на них нативных приложений.
Но возможности подобных страниц этим не ограничиваются. С их помощью также можно предложить пользователю какое-нибудь увлекательное занятие, например разгадывание кроссворда. Именно так вам предстоит провести время на офлайн-странице блога разработчиков “The Guardian” в момент потери соединения.
Создание полезной офлайн-страницы для большинства веб-приложений
В данной статье мы создадим функциональность, полезную для многих приложений и веб-сайтов, которая позволит частично использовать ваше приложение даже в офлайн-режиме. Ее цель — показать пользователю список подходящих кэшированных страниц.
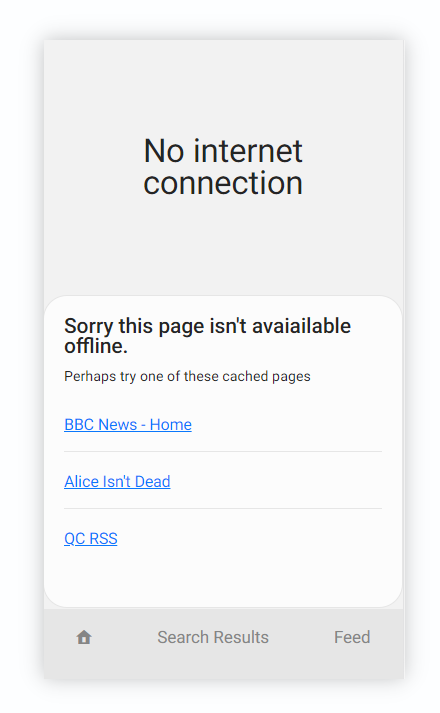
Здесь в качестве примера приложения приводится FeedReader, программа для чтения формата RSS, благодаря которой пользователь может прочитать текстовый контент RSS-канала по URL-адресу, например вот такому:
/feed/?url=https://ada.is/feed
Это приложение обрабатывается на сервере и возвращает все данные в формате HTML-страниц, которые кэшируются при помощи сервис-воркера. Если же ваше приложение использует для заполнения страниц на стороне клиента формат JSON, то этот метод по-прежнему будет работать при условии кэширования и JSON-ответов, и отображающих их страниц.
Этот шаблон применяется во многих веб-приложениях и будет работать до тех пор, пока есть кэшированные страницы.
Шаг 1. Предварительное кэширование офлайн-страницы
Прежде всего, нам нужно сохранить офлайн-страницу при запуске приложения. С этой целью при старте были кэшированы HTML-файл /offline/ и его ресурсы /offline.js через заполнение кэша во время события install, выполняемого сервис-воркером.
const CACHE_NAME = "DENORSS-v1.0.0";
self.addEventListener("install", (event) => {
event.waitUntil(
caches
.open(CACHE_NAME)
.then((cache) =>
cache.addAll(["/", "/offline/", "/offline.js"])
)
.then(self.skipWaiting())
);
});Шаг 2. Показ офлайн-страницы
Далее, когда пользователь пытается перейти на страницу, которой у нас нет, мы можем показать кэшированную страницу /offline/.
Сначала существующий код попытается ответить загрузкой реальной страницы. В случае же неудачи он постарается извлечь страницу из кэша. Если и эта попытка окажется безрезультатной, то вместо прекращения работы и отображения сообщения об ошибке будет показана офлайн-страница.
// Попытаться отобразить офлайн-страницу при навигации
if (event.request.mode === "navigate") {
const offlinePage = await caches.match("/offline/");
if (offlinePage) return offlinePage;
}Шаг 3. Получение списка кэшированных страниц
Если не сработал ни один из рассмотренных вариантов, то на этом этапе показывается офлайн-страница. Теперь в качестве альтернативы предоставим пользователю список кэшированных страниц, которые могли бы его заинтересовать.
Сначала необходимо открыть кэши веб-приложений для поиска страниц, к которым нужно получить доступ:
const cacheKeys = await window.caches.keys();
const caches = await Promise.all(
cacheKeys.map((cacheName) => window.caches.open(cacheName))
);Так мы получаем массив кэшей.
После этого требуется найти все кэшированные страницы из этого массива. С помощью cache.matchAll и ignoreSearch: true получим все результаты кэша в конечной точке /feed/.
const results = await Promise.all(
caches.map((cache) =>
cache.matchAll("/feed/", {
ignoreSearch: true,
})
)
);Я просмотрела лишь конечную точку /feed/, поскольку, по моим ощущениям, такие страницы, как /search/ с результатами поиска или /404.html с сообщениями об ошибках, не будут представлять практической ценности для пользователя. Что касается главных страниц, таких как домашняя страница /, то они уже привязаны ссылками в навигационной панели.
Инструкция results возвращает массив массивов, отражая результаты, полученные из каждого кэша. Далее мы произведем уплощение и обработаем каждый кэшированный ответ.
results.flat().forEach(async (response) => {
// Здесь размещается код
});Поскольку нашей единственной целью является предоставление пользователю нужных страниц, мы будем обращать внимание на параметры запросов для поиска только самых интересных из них. В следующем примере они запрашивают RSS-канал через параметр url:
const params = new URLSearchParams(new URL(response.url).search);
const urlParam = params.get('url');
if (!urlParam) return;Без параметра запроса url страница не представляет интереса, поэтому мы ее не показываем.
Шаг 4. Отображение списка
На данном этапе мы располагаем URL-адресами страниц и необработанными параметрами запросов, но в таком виде они могут не понравиться пользователю. Можно показать более привлекательные ярлыки, если обратиться к самому кэшированному содержимому.
Для извлечения данных из ответа нам необходимо получить его текст:
const dataAsString = await response.text();
Если ваши данные хранятся в формате JSON, то JSON.parse будет достаточно для извлечения любой интересной информации, например заголовка хорошей страницы.
const data = JSON.parse(dataAsString);
const title = data.title;Учитывая, что наш веб-сайт отображается на стороне сервера и использует HTML, я выполню парсинг HTML. К счастью, веб-браузеры прекрасно справляются с этой задачей. Мы преобразуем необработанный текст в фрагмент документа, который можно запросить с помощью обычных методов DOM.
В следующем примере прочитаем текст в теге <title>. Другими подходящими элементами для запроса были бы <h1> или <h2>, позволяющие получить первый заголовок в документе.
const html = document
.createRange()
.createContextualFragment(dataAsString);
const title = html
.querySelector("title")
.textContent.trim();С помощью заголовка и ответа URL создаем ссылку, которую можно добавить к элементу списка, чтобы получить список страниц.
el.insertAdjacentHTML(
"beforeend",
`<li><a href="${response.url}">${title}</a></li>`
);Анимация ниже отражает принцип работы нашей офлайн-страницы и был создан при помощи Chrome, имитирующего отсутствие сетевого соединения.
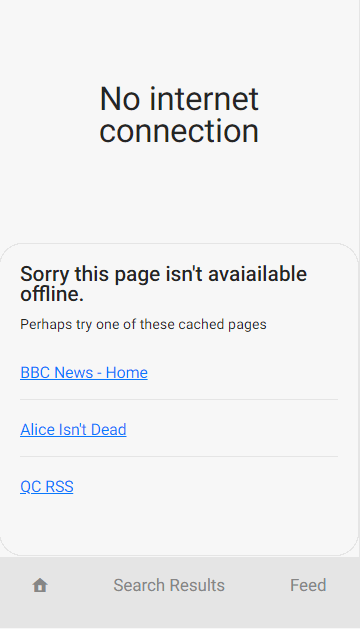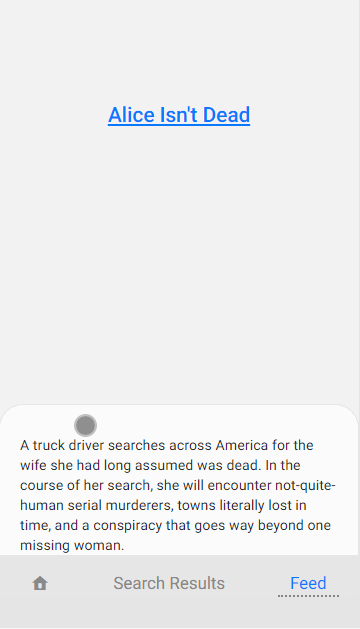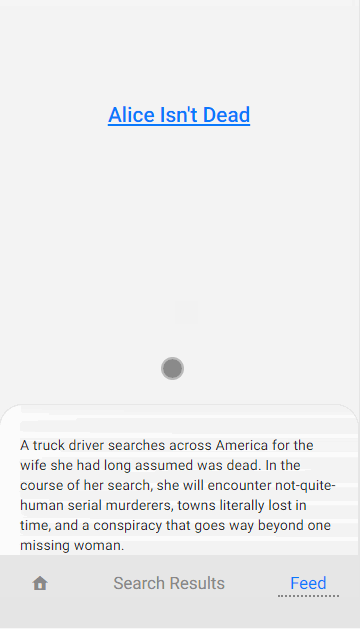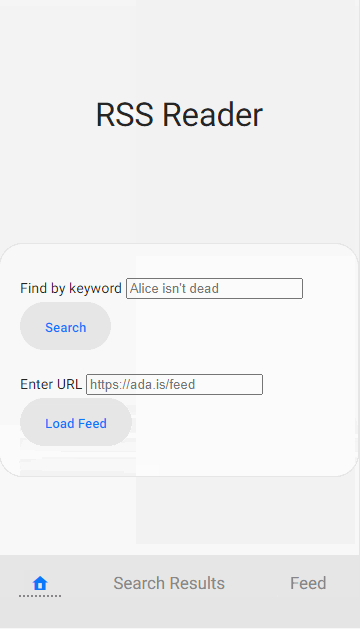
Благодарю за внимание и надеюсь, что материал статьи будет вам полезен!
Читайте также:
- Обработка ошибок в React Hooks
- Дизайн для всех: подробное руководство по созданию интерфейсов для людей с ограниченными возможностями
- EST API для приложения со Spring Boot, Kotlin и Gradle
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Ada Rose Cannon: Making a useful ‘offline’ page for your web app





