
Мы, программисты, привыкли по умолчанию использовать SQLite, когда приходится работать в локальных средах со встроенной базой данных. Хотя в большинстве случаев эта библиотека нас не подводит, ее использование все равно, что поездка на велосипеде за 100 км — явно не лучший вариант.
Знакомьтесь: DuckDB
Впервые я узнал о DuckDB в сентябре 2022 года, во время PyCon — конференции для разработчиков Python, проходившей в испанском городе Гранада. Теперь, после полугода использовани DuckDB, я уже не могу обходиться без этой аналитической системы баз данных. Стремясь внести свой вклад в развитие сообщества, хочу познакомить с ней своих коллег-программистов и специалистов, связанных с данными.
Предлагаю рассмотреть наиболее важные аспекты.
- Введение в DuckDB: что это такое, почему и когда стоит использовать эту систему.
- Интеграция DuckDB в Python.
Что такое DuckDB?
На главной странице сайта DuckDB дается следующее определение: “DuckDB — это SQL-встраиваемая OLAP-система управления базами данных”.
Разберем это определение по частям, потому что в каждой из них содержится важная информация.
- SQL-встраиваемая означает, что функции DuckDB будут работать в приложении, а не во внешнем процессе, к которому подключается приложение. Другими словами: нет ни клиента, посылающего инструкции, ни сервера для их чтения и обработки. SQLite работает таким же образом, а PostgreSQL и MySQL — нет.
- OLAP расшифровывается как Online analytical processing (аналитический онлайн-процесс). Microsoft определяет OLAP как технологию, которая организует большие базы бизнес-данных и поддерживает сложный анализ. Она может использоваться для выполнения сложных аналитических запросов без негативного влияния на транзакционные системы. Другим примером OLAP-системы управления базами данных является Terradata.
В общем, DuckDB — это отличный вариант, если вы ищете бессерверную систему управления аналитической базой данных.
Кроме того, это реляционная система управления базами данных (СУБД), поддерживающая SQL. Именно поэтому можно сравнивать ее с другими СУБД, имеющими те же характеристики, такими как SQLite и PostgreSQL.
Почему именно DuckDB?
Итак, мы выяснили роль DuckDB в индустрии баз данных. Но почему стоит выбрать именно ее из множества других вариантов, приемлемых для конкретного проекта?
Когда речь идет о системах управления базами данных, универсальных решений не существует, и DuckDB не является исключением. Рассмотрение некоторых особенностей этой системы поможет решить, стоит ли ее использовать.
Если охарактеризовать DuckDB в двух словах, то это высокопроизводительный инструмент. Вот что написано о нем на GitHub: “Он разработан, чтобы быть быстрым, надежным и простым в использовании”. Теперь поговорим о его преимуществах более детально.
- DuckDB создана для поддержки рабочих нагрузок аналитических запросов (OLAP). Это достигается за счет векторизации выполнения запросов (ориентации на столбцы). Другие СУБД, упомянутые ранее (SQLite, PostgreSQL и др.), обрабатывают каждую строку последовательно. Именно за счет этого производительность DuckDB увеличивается.
- Система DuckDB унаследовала главное преимущество SQLite — простоту. Легкость установки и встроенность в процесс — вот что выбрали разработчики DuckDB для этой СУБД, проанализировав успешность SQLite благодаря этим особенностям. Более того, DuckDB не имеет внешних зависимостей и серверного программного обеспечения, которое нужно устанавливать, обновлять и поддерживать. Как уже было сказано, DuckDB — полностью встроенная система, что обеспечивает дополнительное преимущество — высокоскоростную передачу данных в базу данных и из нее.
- Квалифицированные создатели. Исследовательская группа разработала DuckDB с целью создания стабильной и зрелой системы баз данных. Для этого понадобилось интенсивное и тщательное тестирование. В настоящее время тестовый набор DuckDB содержит миллионы запросов, адаптированных из тестовых наборов SQLite, PostgreSQL и MonetDB.
- DuckDB — полнофункциональная система. Она поддерживает сложные запросы в SQL, обеспечивает транзакционные гарантии (свойства ACID, о которых вы наверняка слышали), поддерживает вторичные индексы для ускорения запросов. И, что самое важное, глубоко интегрирована в Python и R для эффективного интерактивного анализа данных. Она также предоставляет API для C, C++, Java и других языков.
- DuckDB — бесплатное ПО с открытым исходным кодом. Лучше и быть не может.
Это официальные преимущества.
Но их больше. Лично мне хочется выделить еще одно: DuckDB не обязательно должен заменять Pandas. Они способны работать рука об руку, и вы можете создавать эффективный SQL на Pandas с помощью DuckDB.
Более подробные разъяснения ищите на сайте DuckDB.
Когда использовать DuckDB?
Это зависит от ваших предпочтений. Обратимся к документу, выпущенному разработчиками DuckDB.
В этом документе говорится о назревшей потребности во встраиваемом управлении аналитическими данными. SQLite является встроенной базой данных, но при выполнении исчерпывающего анализа работает слишком медленно. Далее создатели DuckDB поясняют: “В удовлетворении этой потребности нуждаются две основные сферы: интерактивный анализ данных и “граничные” вычисления”.
Итак, вот два основных направления использования DuckDB.
- Интерактивный анализ данных. Большинство дата-сайентистов сейчас используют библиотеки R и Python, такие как dplyr и Pandas, в своих локальных средах для работы с данными, которые они получают из базы данных. DuckDB предлагает возможность прибегнуть к эффективности SQL для локальной разработки без риска для производительности. Вы можете воспользоваться этими преимуществами без необходимости отказываться от любимого языка программирования (подробнее об этом позже).
- Граничные вычисления. Согласно определению английской Википедии, “граничные вычисления — это парадигма распределенных вычислений, которая приближает вычисления и хранение данных к источникам данных”. Учитывая использование встроенной СУБД, ближе и быть не может!
DuckDB можно устанавливать и применять в различных средах, включая Python, R, Java, node.js, Julia и C++. Здесь мы сосредоточимся на Python, и вы убедитесь в простоте использования DuckDB.
Применение DuckDB с Python: введение
Для начала откройте терминал и перейдите в нужный каталог. Создайте новую виртуальную среду, если это необходимо, и установите DuckDB:
pip install duckdb==0.7.1
Удалите или обновите версию, если вам нужна другая.
Теперь перейдем к самому интересному. Воспользуемся реальными данными, найденными мной на Kaggle, — ”Самые просматриваемые песни Spotify за все время”. Я буду работать в Jupyter Notebook.
Поскольку полученные данные представлены в виде двух CSV-файлов (Features.csv и Streams.csv), нужно создать новую базу данных и загрузить их в нее:
import duckdb
# Создание БД (встроенная СУБД)
conn = duckdb.connect('spotiStats.duckdb')
c = conn.cursor()
# Создание таблиц путем импорта содержимого из CSV-файлов
c.execute(
"CREATE TABLE features AS SELECT * FROM read_csv_auto('Features.csv');"
)
c.execute(
"CREATE TABLE streams AS SELECT * FROM read_csv_auto('Streams.csv');"
)
Вот так просто получилось создать совершенно новую базу данных, добавить две новые таблицы и заполнить их всеми данными. И все это с помощью 4 простых строк кода (5, если учесть импорт).
Визуализируем содержимое таблицы потока данных:
c.sql("SELECT * FROM streams")
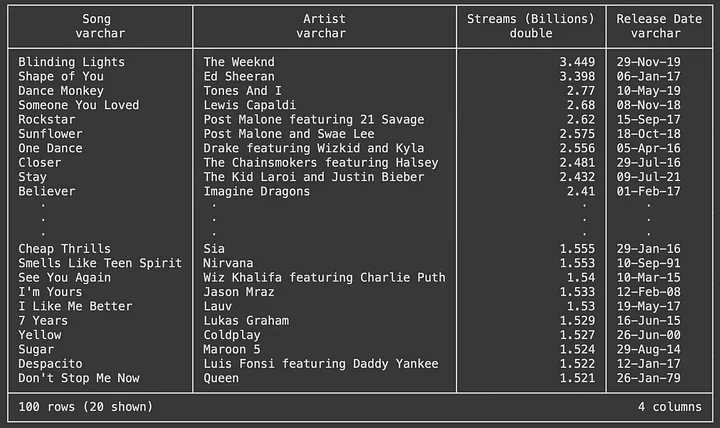
Приступим к выполнению аналитических задач. Например, узнаем, сколько в топ-100 песен, созданных до 2000 года. Вот один из способов сделать это:
c.sql('''
SELECT *
FROM streams
WHERE regexp_extract("Release Date", '\d{2}$') > '23'
''')

Я уже упоминал, как легко работать с DuckDB и Pandas одновременно. Вот как можно сделать то же самое, но с использованием Pandas:
df = c.sql('SELECT * FROM streams').df()
df[df['Release Date'].apply(lambda x: x[-2:] > '23')]
Нам понадобилось лишь преобразовать в DataFrame исходный запрос, а затем применить фильтр методом Pandas. Результат тот же, но как насчет производительности?
>>> %timeit df[df['Release Date'].apply(lambda x: x[-2:] > '23')]
434 µs ± 25.6 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> %timeit c.sql('SELECT * FROM streams WHERE regexp_extract("Release Date", \'\d{2}$\') > \'23\'')
112 µs ± 25.3 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Операция по применению простого фильтра к таблице из 100 строк была совершенно несложной. Но время выполнения с помощью Pandas почти в 4 раза больше, если сравнивать с DuckDB.
А что если бы потребовалось выполнить более исчерпывающую аналитическую операцию? Оптимизация была бы впечатляющей.
Думаю, что нет смысла приводить больше примеров, потому что тогда введение в DuckDB превратится во введение в SQL. А это не входит в наши планы.
Но вы можете поэкспериментировать с любым набором данных, который у вас есть, и начинать использовать SQL в своей базе данных DuckDB. Вы быстро оцените ее преимущества.
Чтобы закончить это краткое введение, экспортируем последний результат (песни до 2000 года) в файл parquet: файлы этого типа всегда являются лучшей альтернативой традиционным CSV. Опять же, это будет чрезвычайно просто:
c.execute('''
COPY (
SELECT
*
FROM
streams
WHERE
regexp_extract("Release Date", '\d{2}$') > '23'
)
TO 'old_songs.parquet' (FORMAT PARQUET);
''')
Нужно только поместить предыдущий запрос в скобки, а DuckDB просто скопировал результат запроса в файл old_songs.parquet.
Заключение
Система DuckDB изменила мою жизнь. Думаю, она может стать таким же необходимым инструментом для многих из вас.
Читайте также:
- Руководство по наиболее востребованным базовым командам SQL
- Как дата-аналитику стать дата-сайентистом в 2023 году
- SQL для Data Science: альтернатива обмену через Google Disk и Slack
Читайте нас в Telegram, VK и Дзен
Перевод статьи Pol Marin: Forget about SQLite, Use DuckDB Instead — And Thank Me Later





